byteps
v0.2
바이트는 고성능 및 일반적인 분산 교육 프레임 워크입니다. Tensorflow, Keras, Pytorch 및 MXnet을 지원하며 TCP 또는 RDMA 네트워크에서 실행할 수 있습니다.
바이트는 기존 오픈 소스 분산 교육 프레임 워크보다 큰 마진으로 성능이 우수합니다. 예를 들어, Bert-Large 교육에서 BYTEPS는 256 GPU (아래 참조)로 ~ 90% 스케일링 효율을 달성 할 수 있으며, 이는 Horovod+NCCl보다 훨씬 높습니다. 특정 시나리오에서 바이트는 Horovod+NCCL에 비해 훈련 속도를 두 배로 늘릴 수 있습니다.
bpslaunch 명령으로 추가하십시오.pip3 install byteps 우리는 Gluonnlp 툴킷을 기반으로하는 Bert-Large 교육에 대한 실험을 보여줍니다. 이 모델은 혼합 정밀도를 사용합니다.
우리는 Tesla V100 32GB GPU를 사용하고 GPU 당 64에 해당하는 배치 크기를 설정합니다. 각 기계에는 NVlink 개정 기능이있는 8 V100 GPU (32GB 메모리)가 있습니다. 기계는 100GBPS RDMA 네트워크와 상호 연결됩니다. 이것은 AWS에서 얻을 수있는 것과 동일한 하드웨어 설정입니다.
바이트는 256 gpus로 Bert-Large의 ~ 90% 스케일링 효율을 달성합니다. 코드는 여기에서 사용할 수 있습니다. 이에 비해 Horovod+NCCL은 전문가 매개 변수 튜닝 후에도 ~ 70% 스케일링 효율을 가지고 있습니다.
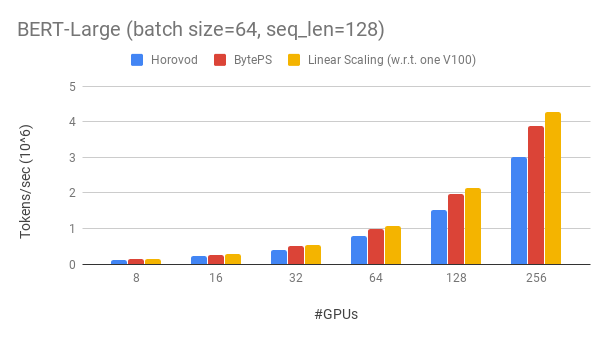
BYTEPS는 느린 네트워크를 통해 최대 2 배의 Horovod+NCCL의 성능 이점을 제공합니다. Performance.md에서 더 많은 평가 결과를 찾을 수 있습니다.
Byteps가 어떻게 Horovod를 능가 할 수 있습니까? 주된 이유 중 하나는 바이트가 클라우드 및 공유 클러스터 용으로 설계되어 MPI를 버리기 때문입니다.
MPI는 HPC 세계에서 태어 났으며 균질 한 하드웨어로 제작 된 클러스터와 단일 작업에 적합합니다. 그러나 클라우드 (또는 사내 공유 클러스터)는 다릅니다.
이것은 우리가 여기에서 설명한대로 최고의 커뮤니케이션 전략을 다시 생각하게합니다. 요컨대, Byteps는 기계 내부에서 NCCL 만 사용하는 반면, 기계 간 통신을 재 형성합니다.
Byteps는 또한 계층 적 전략, 파이프 라인, 텐서 파티셔닝, NUMA 인식 로컬 커뮤니케이션, 우선 순위 기반 스케줄링 등과 같은 많은 가속 기술을 통합합니다.
벤치 마크 교육 작업을 실행할 수있는 단계별 자습서를 제공합니다. 가장 간단한 시작 방법은 Docker 이미지를 사용하는 것입니다. 분산 작업을 시작하는 방법 및보다 자세한 구성 방법은 문서를 참조하십시오. 바이 테프를 시작한 후에는 모범 사례를 읽고 최상의 성능을 얻으십시오.
아래에서는 직접 바이트를 설치하는 방법을 설명합니다. 두 가지 옵션이 있습니다.
pip3 install byteps
마스터 브랜치에서 직접 설치하여 최신 기능을 시도 할 수 있습니다.
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
위의 두 가지 옵션에 대한 참고 사항 :
export BYTEPS_NCCL_HOME=/path/to/nccl 로 NCCL 경로를 지정해야합니다. 기본적으로 /usr/local/nccl 을 가리 킵니다.yum install devtoolset-7 사용해 볼 수 있습니다. 일반적으로 최상의 호환성 (GCC를 고정하는 방법)을 위해 GCC 4.9를 사용하는 것이 좋습니다.기본 예제는 예제 폴더 아래에 제공됩니다.
OSDI'20 논문의 엔드 투 엔드 평가를 재현하려면이 리포지어에서 코드를 찾으십시오.
Byteps는 핵심이 완전히 다르지만 Horovod 인터페이스와 호환됩니다 (감사합니다, Horovod 커뮤니티!). 우리는 바닥 테스트를위한 노력을 최소화하기 위해 Horovod 인터페이스를 선택했습니다.
작업이 Horovod의 Allreduce 및 Broadcast에만 의존하는 경우 1 분 안에 Byteps로 전환 할 수 있어야합니다. import byteps.tensorflow as bps 를 통해 import horovod.tensorflow as hvd 교체 한 다음 bps 로 코드의 모든 hvd 교체하십시오. 코드가 hvd.allreduce 직접 호출하면 bps.push_pull 로 교체해야합니다.
우리의 많은 사례는 Horovod에서 복사되어 이런 식으로 수정되었습니다. 예를 들어, Byteps 및 Horovod의 MNIST 예제를 비교하십시오.
Byteps는 또한 Pytorch 분산 데이터 병렬 및 텐서 플로 미러 전략을 지원합니다. 사용에 대해서는 DistributedDataparAllel.md 및 MirroredStrategy.md를 참조하십시오.
바이트는 현재 순수한 CPU 교육을 지원하지 않습니다. 한 가지 이유는 BYTEPS의 저렴한 PS 가정이 CPU 훈련을 위해 유지되지 않기 때문입니다. 결과적으로, 당신은 byteps를 구축하고 실행하려면 cuda와 nccl이 필요합니다.
우리는 아래 기능을 갖추고 싶습니다. 바이트 아키텍처에서이를 구현하는 데 기본적인 어려움이 없습니다. 그러나 아직 구현되지 않았습니다.
[OSDI'20] "이종 GPU/CPU 클러스터에서 분산 된 DNN 훈련을 가속화하기위한 통합 아키텍처". Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo.
[SOSP'19] "분산 DNN 훈련 가속을위한 일반적인 통신 스케줄러". Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo. (코드는 Bytescheduler Branch에 있습니다)


