byteps
v0.2
Byteps هو إطار تدريب عالي الأداء وتوزيعه العام. وهو يدعم TensorFlow و Keras و Pytorch و Mxnet ، ويمكنه تشغيله على شبكة TCP أو RDMA.
يتفوق Byteps على الأداء الموجود على أطر التدريب الموزعة المفتوحة من خلال هامش كبير. على سبيل المثال ، في تدريب Bert-large ، يمكن أن تحقق BYTEPs حوالي 90 ٪ من كفاءة التحجيم مع 256 وحدات معالجة الرسومات (انظر أدناه) ، وهو أعلى بكثير من Horovod+NCCL. في سيناريوهات معينة ، يمكن أن تضاعف Byteps سرعة التدريب مقارنةً بـ Horovod+NCCL.
bpslaunch كأمر لإطلاق المهام.pip3 install byteps نعرض تجربتنا على تدريب Bert-Large ، والذي يعتمد على مجموعة أدوات Gluonnlp. يستخدم النموذج الدقة المختلطة.
نحن نستخدم Tesla V100 32GB وحدات معالجة الرسومات وضبط حجم الدُفعة تساوي 64 لكل وحدة معالجة الرسومات. يحتوي كل جهاز على 8 V100 GPU (ذاكرة 32 جيجابايت) مع NVLink الممكّن. الآلات متصلة بشبكة RDMA 100 جيجابت في الثانية. هذا هو نفس إعداد الأجهزة التي يمكنك الحصول عليها على AWS.
يحقق Byteps ~ 90 ٪ من كفاءة التحجيم لـ Bert-Large مع 256 وحدات معالجة الرسومات. الرمز متاح هنا. على سبيل المقارنة ، لدى Horovod+NCCL كفاءة التحجيم بنسبة 70 ٪ فقط حتى بعد نفق المعلمة الخبراء.
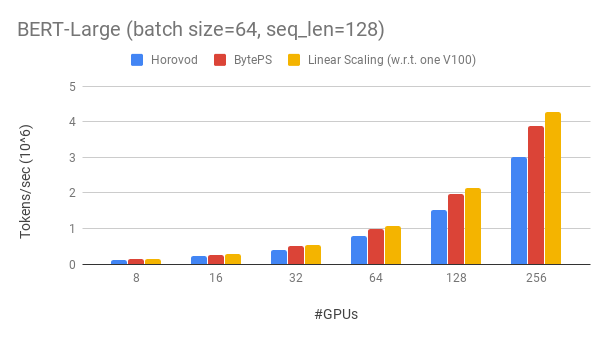
مع شبكة أبطأ ، يوفر Byteps المزيد من مزايا الأداء - ما يصل إلى 2x من Horovod+NCCL. يمكنك العثور على المزيد من نتائج التقييم في الأداء.
كيف يمكن أن يتفوق Byteps على Horovod من خلال الكثير؟ أحد الأسباب الرئيسية هو أن byteps مصممة للتجمعات السحابة والمشتركة ، ويرمي MPI.
وُلد MPI في عالم HPC وهو جيد لمجموعة مصممة بأجهزة متجانسة وتشغيل وظيفة واحدة. ومع ذلك ، فإن السحابة (أو المجموعات المشتركة الداخلية) مختلفة.
هذا يقودنا إلى إعادة التفكير في أفضل استراتيجية اتصال ، كما هو موضح هنا. باختصار ، يستخدم Byteps NCCL فقط داخل الجهاز ، في حين يعيد وضع اتصال بين الآلة.
تتضمن BYTEPs أيضًا العديد من تقنيات التسارع مثل الاستراتيجية الهرمية ، وخليط الأنابيب ، وتقسيم الموتر ، والاتصالات المحلية الوحيدة ، والجدولة القائمة على الأولوية ، وما إلى ذلك.
نحن نقدم برنامجًا تعليميًا خطوة بخطوة لتشغيل مهام التدريب القياسية. أبسط طريقة للبدء هي استخدام صور Docker الخاصة بنا. ارجع إلى الوثائق الخاصة بكيفية تشغيل الوظائف الموزعة والتكوينات الأكثر تفصيلاً. بعد أن تتمكن من بدء byteps ، اقرأ أفضل الممارسات للحصول على أفضل أداء.
أدناه ، نوضح كيفية تثبيت byteps بنفسك. هناك خياران.
pip3 install byteps
يمكنك تجربة أحدث الميزات عن طريق التثبيت مباشرة من Master Branch:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
ملاحظات لخيارين أعلاه:
export BYTEPS_NCCL_HOME=/path/to/nccl . بشكل افتراضي ، يشير إلى /usr/local/nccl .yum install devtoolset-7 قبل كل شيء آخر. بشكل عام ، نوصي باستخدام GCC 4.9 للحصول على أفضل توافق (كيفية تثبيت GCC).يتم توفير الأمثلة الأساسية تحت المجلد المثال.
لإعادة إنتاج التقييم الشامل في ورقة OSDI'20 الخاصة بنا ، ابحث عن الرمز في هذا الريبو.
على الرغم من كونه مختلفًا تمامًا في جوهره ، إلا أن Byteps متوافق للغاية مع واجهات Horovod (شكرًا لك ، مجتمع Horovod!). لقد اخترنا واجهات Horovod من أجل تقليل جهودك لاختبار BYTEPs.
إذا كانت مهامك تعتمد فقط على Allreduce من Horovod ، فيجب أن تكون قادرًا على التبديل إلى BYTEPs في دقيقة واحدة. ما عليك سوى استبدال import horovod.tensorflow as hvd بواسطة import byteps.tensorflow as bps ، ثم استبدال جميع hvd في الكود الخاص بك بواسطة bps . إذا استدعى الرمز الخاص بك hvd.allreduce مباشرة ، فيجب عليك أيضًا استبداله بـ bps.push_pull .
تم نسخ العديد من أمثلةنا من Horovod وتعديلها بهذه الطريقة. على سبيل المثال ، قارن مثال MNIST لل BYTEPs و Horovod.
يدعم BYTEPS أيضًا واجهات برمجة التطبيقات الأصلية الأخرى ، على سبيل المثال ، Pytorch الموزعة للبيانات الموازية واستراتيجية متطابقة Tensorflow. انظر DistributedDataparaldallay.md و mirrorrrategy.md للاستخدام.
لا يدعم Byteps تدريب وحدة المعالجة المركزية الخالصة في الوقت الحالي. أحد الأسباب هو أن افتراض PS الرخيصة لل BYTEPs لا يحتفظ بتدريب وحدة المعالجة المركزية. وبالتالي ، تحتاج إلى CUDA و NCCL لبناء وتشغيل byteps.
نود أن نحصل على الميزات أدناه ، وليس هناك صعوبة أساسية في تنفيذها في بنية Byteps. ومع ذلك ، لم يتم تنفيذها بعد:
[OSDI'20] "بنية موحدة لتسريع تدريب DNN الموزع في مجموعات GPU/CPU غير المتجانسة". Yimin Jiang ، Yibo Zhu ، Chang Lan ، Bairen Yi ، Yong Cui ، Chuanxiong Guo.
[SOSP'19] "جدولة اتصال عامة لتسارع التدريب DNN الموزع". Yanghua Peng ، Yibo Zhu ، Yangrui Chen ، Yixin Bao ، Bairen Yi ، Chang Lan ، Chuan Wu ، Chuanxiong Guo. (الكود في فرع Bytescheduler)


