byteps
v0.2
BYTEPS เป็นกรอบการฝึกอบรมที่มีประสิทธิภาพสูงและกระจายทั่วไป รองรับ Tensorflow, Keras, Pytorch และ MxNet และสามารถทำงานบนเครือข่าย TCP หรือ RDMA
BYTEPS มีประสิทธิภาพสูงกว่ากรอบการฝึกอบรมแบบกระจายแบบเปิดที่มีอยู่โดยมีอัตรากำไรขั้นต้นขนาดใหญ่ ตัวอย่างเช่นในการฝึกอบรม Bert-Large BYTEPS สามารถบรรลุประสิทธิภาพการปรับขนาด ~ 90% ด้วย 256 GPU (ดูด้านล่าง) ซึ่งสูงกว่า Horovod+NCCL มาก ในบางสถานการณ์ BYTEP สามารถเพิ่มความเร็วในการฝึกอบรมเป็นสองเท่าเมื่อเทียบกับ Horovod+NCCL
bpslaunch เป็นคำสั่งเพื่อเรียกใช้งานpip3 install byteps เราแสดงการทดลองของเราเกี่ยวกับการฝึกอบรม Bert-Large ซึ่งขึ้นอยู่กับชุดเครื่องมือ Gluonnlp แบบจำลองใช้ความแม่นยำผสม
เราใช้ TESLA V100 32GB GPU และตั้งค่าขนาดแบทช์เท่ากับ 64 ต่อ GPU แต่ละเครื่องมี 8 V100 GPU (หน่วยความจำ 32GB) พร้อม NVLINK ที่เปิดใช้งาน เครื่องจักรเชื่อมต่อระหว่างกันกับเครือข่าย RDMA 100 Gbps นี่คือการตั้งค่าฮาร์ดแวร์เดียวกับที่คุณสามารถรับได้ใน AWS
BYTEPS ได้รับประสิทธิภาพการปรับขนาด ~ 90% สำหรับ Bert-Large ที่มี 256 GPU รหัสมีอยู่ที่นี่ จากการเปรียบเทียบ Horovod+NCCL มีประสิทธิภาพในการปรับขนาด ~ 70% แม้หลังจากการปรับพารามิเตอร์ของผู้เชี่ยวชาญ
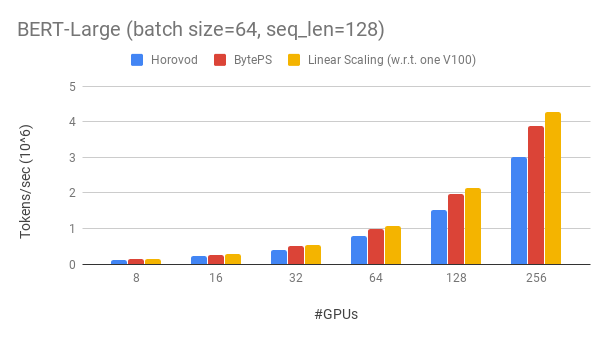
ด้วยเครือข่ายที่ช้าลง BYTEPS ให้ข้อได้เปรียบด้านประสิทธิภาพมากขึ้น - สูงถึง 2x ของ Horovod+NCCL คุณสามารถค้นหาผลการประเมินเพิ่มเติมได้ที่ Performance.md
BYTEP จะดีกว่า Horovod ได้อย่างไร? หนึ่งในเหตุผลหลักคือ BYTEP ได้รับการออกแบบมาสำหรับคลาวด์และกลุ่มที่ใช้ร่วมกันและทิ้ง MPI
MPI เกิดใน HPC World และเป็นสิ่งที่ดีสำหรับกลุ่มที่สร้างขึ้นด้วยฮาร์ดแวร์ที่เป็นเนื้อเดียวกันและสำหรับการทำงานเดียว อย่างไรก็ตามคลาวด์ (หรือกลุ่มที่ใช้ร่วมกันในบ้าน) แตกต่างกัน
สิ่งนี้ทำให้เราคิดใหม่เกี่ยวกับกลยุทธ์การสื่อสารที่ดีที่สุดดังที่อธิบายไว้ในที่นี่ ในระยะสั้น BYTEPs ใช้ NCCL ภายในเครื่องเท่านั้น
BYTEPS ยังรวมเอาเทคนิคการเร่งความเร็วมากมายเช่นกลยุทธ์ลำดับชั้นการจัดท่อการแบ่งเทนเซอร์การสื่อสารในท้องถิ่นที่รู้ตัวเป็น NUMA การกำหนดเวลาตามลำดับความสำคัญ ฯลฯ
เราให้การสอนทีละขั้นตอนสำหรับคุณในการทำงานการฝึกอบรมมาตรฐาน วิธีที่ง่ายที่สุดในการเริ่มต้นคือการใช้ภาพนักเทียบท่าของเรา อ้างถึงเอกสารเกี่ยวกับวิธีการเปิดงานแบบกระจายและการกำหนดค่าโดยละเอียดเพิ่มเติม หลังจากที่คุณสามารถเริ่ม BYTEP ได้แล้วอ่านแนวปฏิบัติที่ดีที่สุดเพื่อให้ได้ประสิทธิภาพที่ดีที่สุด
ด้านล่างเราอธิบายวิธีการติดตั้ง BYTEP ด้วยตัวเอง มีสองตัวเลือก
pip3 install byteps
คุณสามารถลองใช้คุณสมบัติล่าสุดโดยการติดตั้งโดยตรงจาก Master Branch:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
หมายเหตุสำหรับสองตัวเลือกข้างต้น:
export BYTEPS_NCCL_HOME=/path/to/nccl โดยค่าเริ่มต้นจะชี้ไปที่ /usr/local/ncclyum install devtoolset-7 ก่อนทุกอย่างอื่น โดยทั่วไปเราขอแนะนำให้ใช้ GCC 4.9 เพื่อความเข้ากันได้ที่ดีที่สุด (วิธี PIN GCC)ตัวอย่างพื้นฐานมีให้ภายใต้โฟลเดอร์ตัวอย่าง
ในการทำซ้ำการประเมินแบบ end-to-end ในกระดาษ OSDI'20 ของเราค้นหารหัสที่ repo นี้
แม้ว่าจะแตกต่างกันโดยสิ้นเชิงในหลักของมัน แต่ BYTEPS นั้นเข้ากันได้อย่างมากกับอินเตอร์เฟส Horovod (ขอบคุณชุมชน Horovod!) เราเลือกอินเทอร์เฟซ Horovod เพื่อลดความพยายามในการทดสอบ BYTEPS
หากงานของคุณขึ้นอยู่กับการออกอากาศและการออกอากาศของ Horovod เท่านั้นคุณควรจะเปลี่ยนเป็น BYTEP ใน 1 นาที เพียงแทนที่ import horovod.tensorflow as hvd โดย import byteps.tensorflow as bps จากนั้นแทนที่ hvd ทั้งหมดในรหัสของคุณด้วย bps หากรหัสของคุณเรียกใช้ hvd.allreduce โดยตรงคุณควรแทนที่ด้วย bps.push_pull
ตัวอย่างของเราจำนวนมากถูกคัดลอกมาจาก Horovod และแก้ไขด้วยวิธีนี้ ตัวอย่างเช่นเปรียบเทียบตัวอย่าง MNIST สำหรับ BYTEPS และ Horovod
BYTEPS ยังรองรับ API ดั้งเดิมอื่น ๆ เช่น Pytorch Distributed Data Data Parallel และ Tensorflow Mirrored ดู distributedDataparallel.md และ mirroredstrategy.md สำหรับการใช้งาน
BYTEPS ไม่สนับสนุนการฝึกอบรม CPU บริสุทธิ์ในตอนนี้ เหตุผลหนึ่งคือข้อสันนิษฐาน PS ราคาถูกของ BYTEP ไม่ได้ถือสำหรับการฝึกอบรม CPU ดังนั้นคุณต้องใช้ CUDA และ NCCL เพื่อสร้างและเรียกใช้ BYTEPS
เราต้องการมีคุณสมบัติด้านล่างและไม่มีปัญหาพื้นฐานที่จะนำไปใช้ในสถาปัตยกรรม BYTEPS อย่างไรก็ตามพวกเขายังไม่ได้ดำเนินการ:
[OSDI'20] "สถาปัตยกรรมแบบครบวงจรสำหรับการเร่งการฝึกอบรม DNN แบบกระจายในกลุ่ม GPU/CPU ที่แตกต่างกัน" Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo
[SOSP'19] "ตัวกำหนดเวลาการสื่อสารทั่วไปสำหรับการเร่งการฝึกอบรม DNN แบบกระจาย" Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo (รหัสอยู่ที่ Bytescheduler Branch)


