pytorch a2c ppo acktr gail
1.0.0
PPO很棒,但是軟演員評論家對於許多連續的控制任務可以更好。請在JAX中查看我的新RL存儲庫。
這是Pytorch的實現
另請參閱OpenAI帖子:A2C/ACKTR和PPO以獲取更多信息。
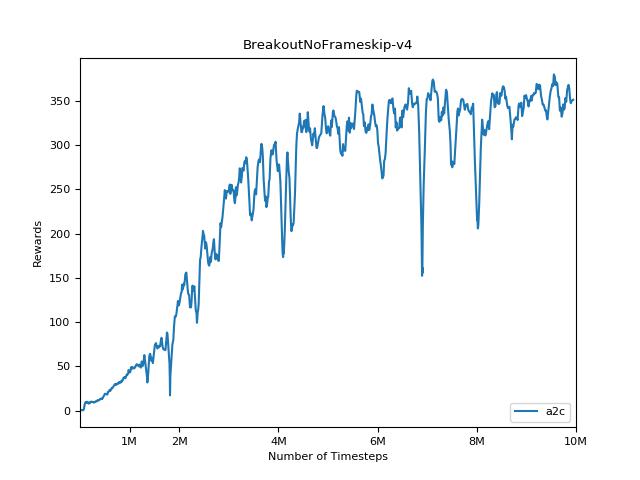
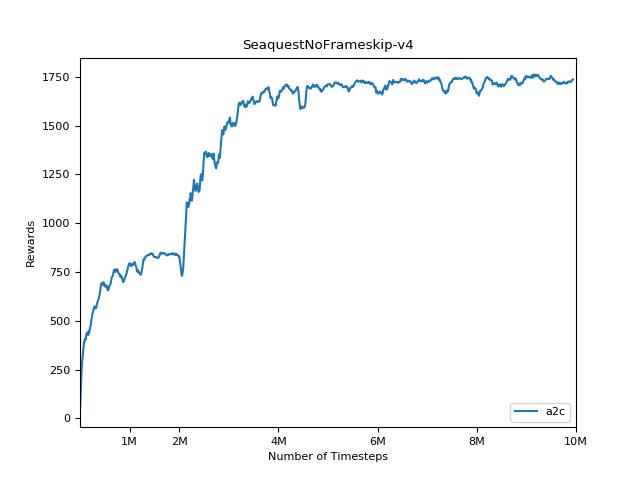
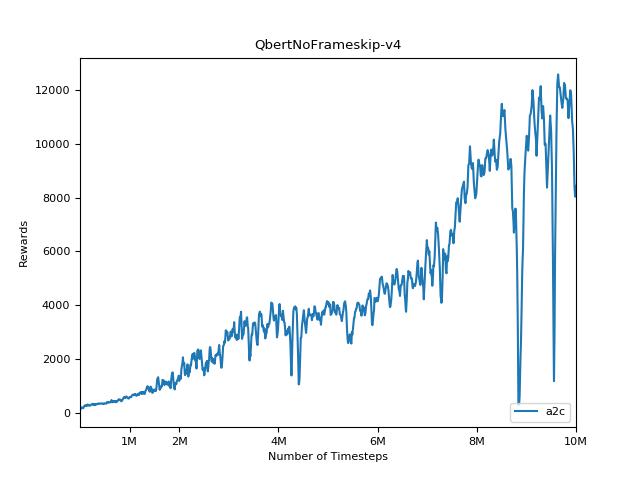
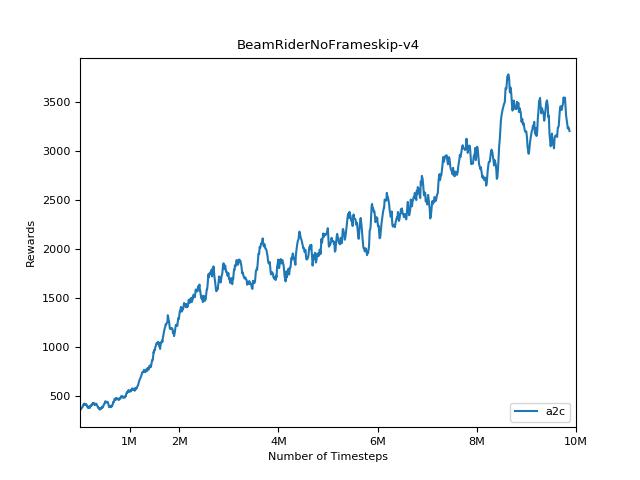
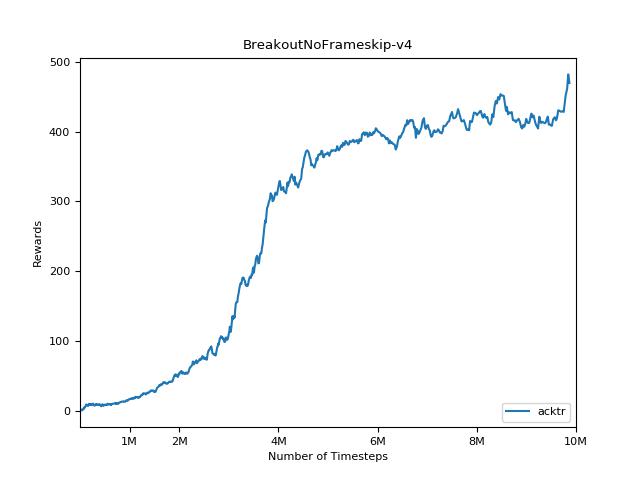
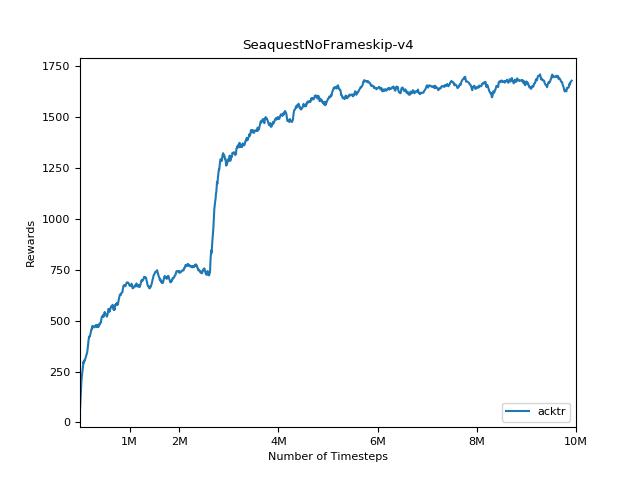
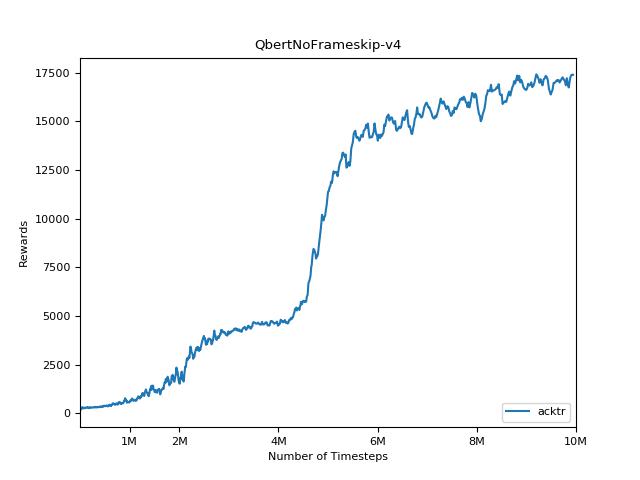
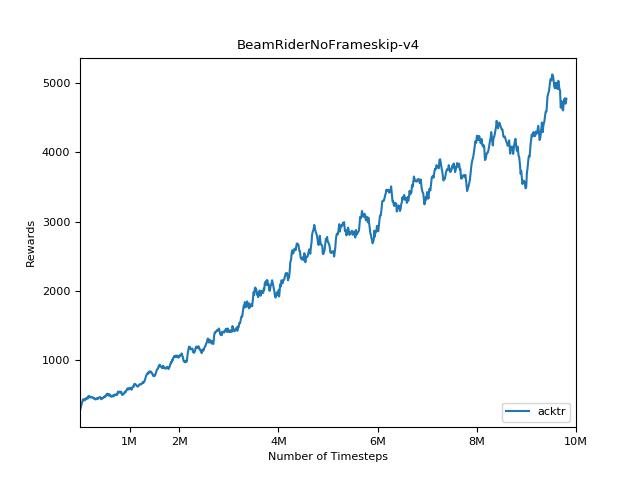
該實現的靈感來自A2C,ACKTR和PPO的OpenAI基準。它使用相同的超級參數和模型,因為它們在Atari遊戲中進行了很好的調整。
如果您想在出版物中引用此存儲庫,請使用此Bibtex:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
我強烈建議Pybullet作為持續控制任務的Mujoco的免費開源替代品。
所有環境均使用完全相同的健身房接口進行操作。請參閱他們的文檔以獲取全面列表。
要使用DeepMind Control Suite環境,請設置標誌--env-name dm.<domain_name>.<task_name> ,其中domain_name和task_name是域名(例如hopper stand和該域中的任務(例如,來自DeepMind Control Suite)。請參閱他們的回購及其技術報告,以獲取可用域和任務的完整列表。除了設置任務外,與DM_Control2Gym相互交互的API與所有健身房環境完全相同。
為了安裝要求,請參見:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atari貢獻非常歡迎。如果您知道如何使此代碼更好,請打開問題。如果您想提交拉動請求,請首先打開問題。另請參閱下面的待辦事項列表。
另外,我正在尋找志願者在Atari和Mujoco上運行所有實驗(帶有多個隨機種子)。
重現增強學習方法的結果非常困難。有關更多信息,請參見“重要的強化學習”。我試圖盡可能地重現OpenAI結果。但是,即使是由於Tensorflow和Pytorch庫的較小差異,績效的大滿貫差異也可能引起。
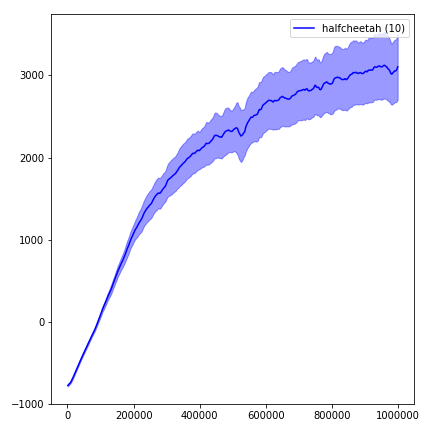
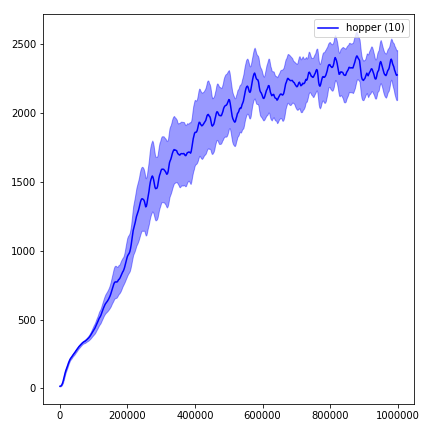
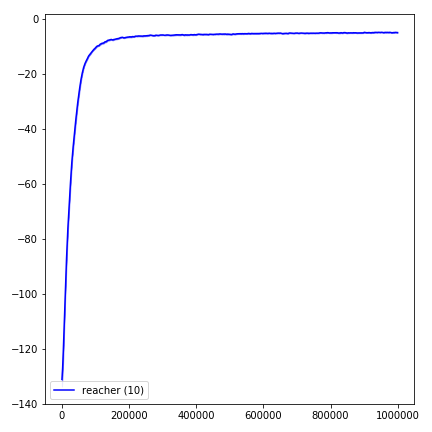
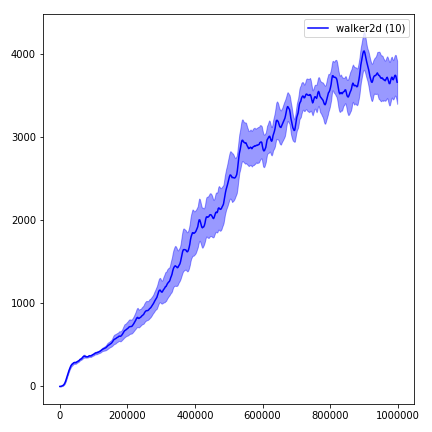
為了可視化結果,請使用visualize.ipynb 。
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20請始終嘗試使用--use-proper-time-limits標誌。它正確處理部分軌跡(請參閱https://github.com/sfujim/td3/blob/master/mains.py.py#l123)。
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR需要專門為Mujoco進行一些修改。但是目前,我想保持此代碼盡可能統一。因此,我將採用更好的方法將其集成到代碼庫中。
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "