pytorch a2c ppo acktr gail
1.0.0
PPOは優れていますが、ソフト俳優評論家は多くの継続的な制御タスクに適しています。 JAXの新しいRLリポジトリをご覧ください。
これは、のPytorchの実装です
詳細については、OpenAIの投稿:A2C/ACKTRおよびPPOも参照してください。
この実装は、A2C、ACKTR、PPOのOpenaiベースラインに触発されています。同じハイパーパラメーターとモデルを使用して、Atari Gamesに合わせて調整されていたためです。
出版物でこのリポジトリを引用したい場合は、このbibtexを使用してください。
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
Pybulletは、継続的な制御タスクのためにMujocoに代わる無料のオープンソースとして強くお勧めします。
すべての環境は、まったく同じジムインターフェイスを使用して操作されます。包括的なリストについては、ドキュメントを参照してください。
DeepMind Control Suite環境を使用するには、flag --env-name dm.<domain_name>.<task_name>を設定します。ここで、 domain_nameとtask_nameはドメインの名前( hopperなど)とそのドメイン内のタスク( stand )のタスクです。利用可能なドメインとタスクの完全なリストについては、リポジトリと技術レポートを参照してください。タスクを設定する以外に、環境と対話するためのAPIは、DM_CONTROL2GYMのおかげですべてのジム環境とまったく同じです。
要件をインストールするために、次のことをフォローしてください。
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atari貢献は大歓迎です。このコードを改善する方法がわかっている場合は、問題を開いてください。プルリクエストを送信する場合は、最初に問題を開きます。以下のTODOリストも参照してください。
また、AtariとMujocoですべての実験を実行するボランティアを探しています(複数のランダムシードを使用)。
強化学習方法の結果を再現することは非常に困難です。詳細については、「重要な深い補強学習」を参照してください。 Openaiの結果をできるだけ密接に再現しようとしました。ただし、テンソルフローとPytorchライブラリのわずかな違いによっても、パフォーマンスの主要な違いが生じる可能性があります。
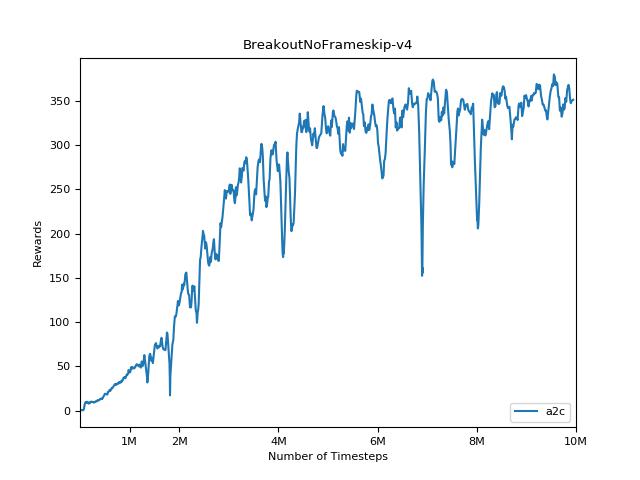
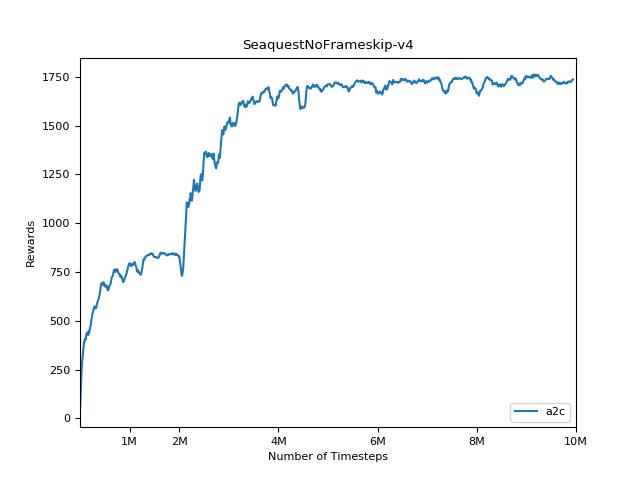
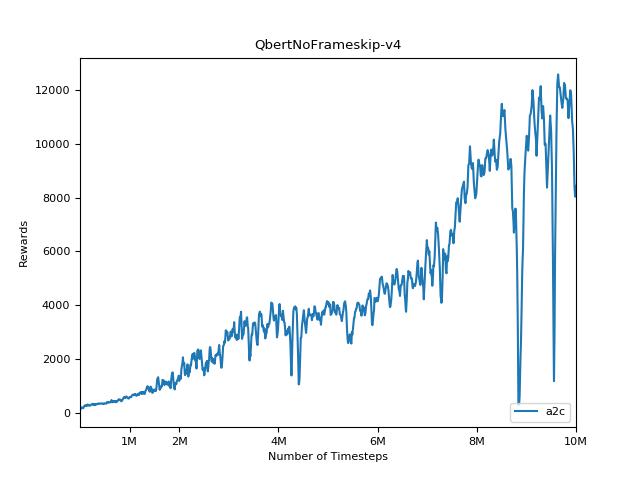
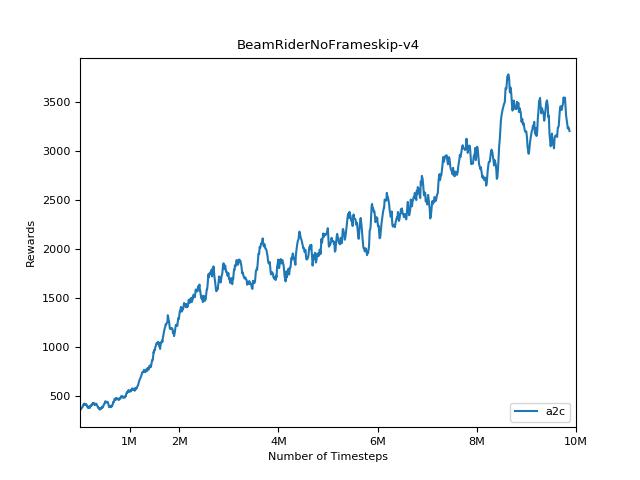
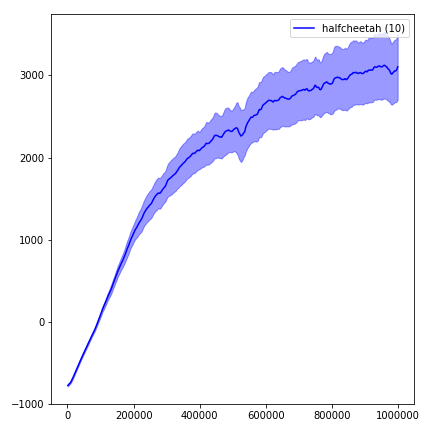
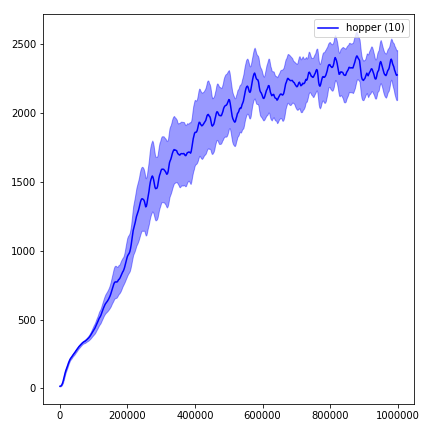
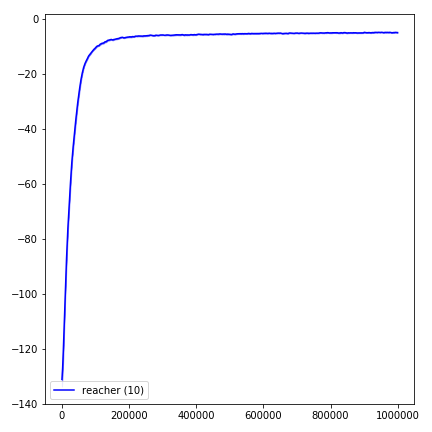
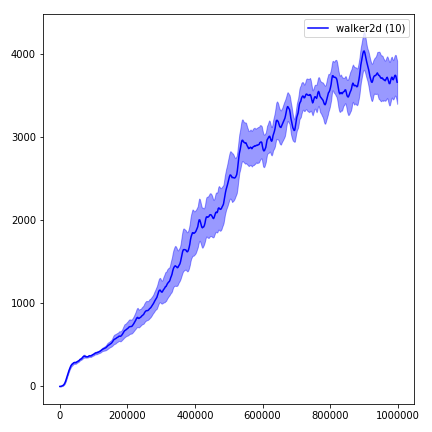
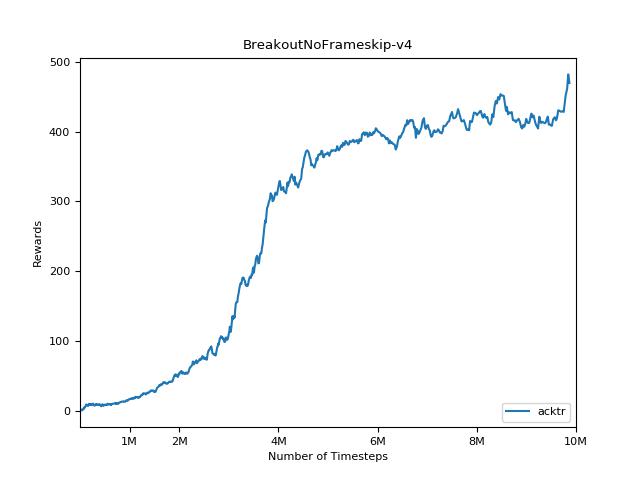
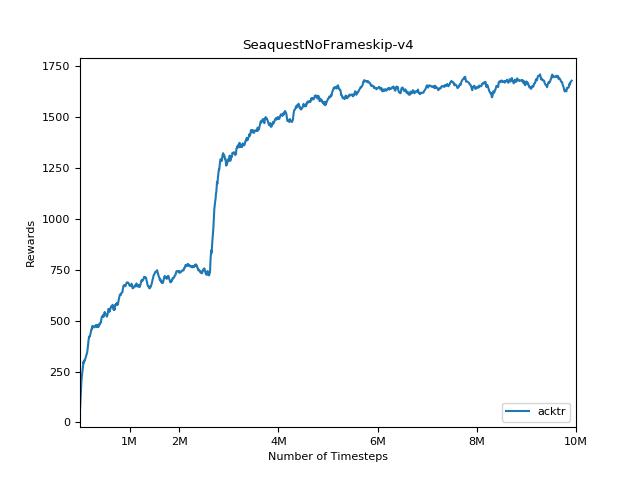
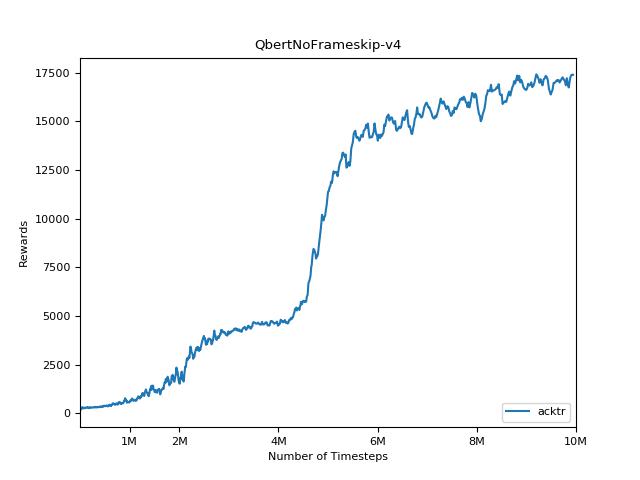
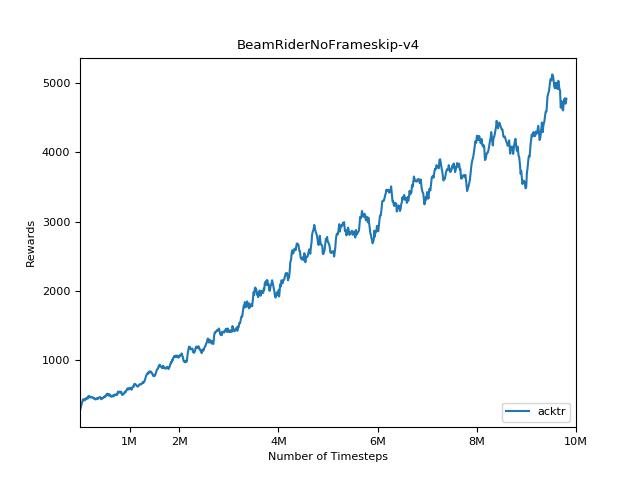
結果を視覚化するには、 visualize.ipynbを使用してください。
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20常に使用してください--use-proper-time-limitsフラグをお試しください。部分的な軌跡を適切に処理します(https://github.com/sfujim/td3/blob/master/main.py#l123を参照)。
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTRでは、Mujoco専用に変更する必要があります。しかし、現時点では、このコードを可能な限り統一しておきたいと思っています。したがって、私はそれをコードベースに統合するためのより良い方法を求めています。
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "