pytorch a2c ppo acktr gail
1.0.0
PPO es excelente, pero el crítico de actores suaves puede ser mejor para muchas tareas de control continuo. Echa un vistazo a mi nuevo repositorio RL en Jax.
Esta es una implementación de Pytorch de
Consulte también las publicaciones de OpenAI: A2C/ACKTR y PPO para obtener más información.
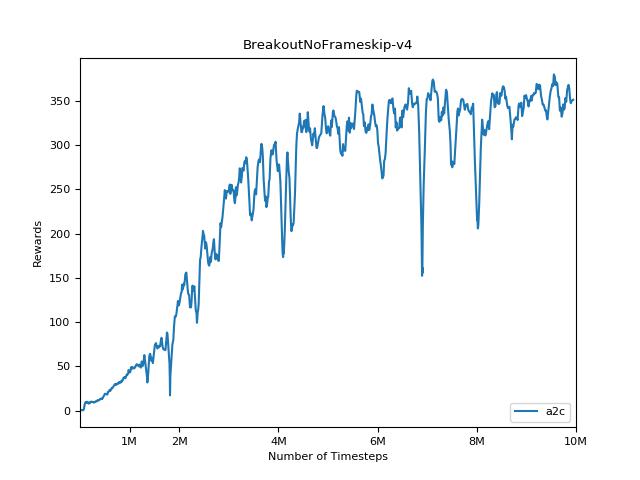
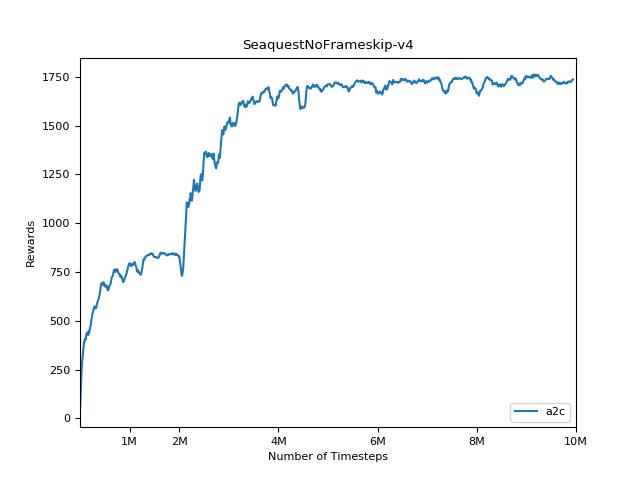
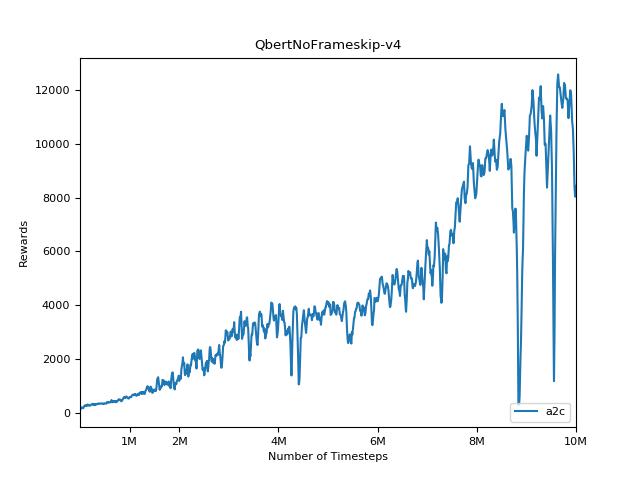
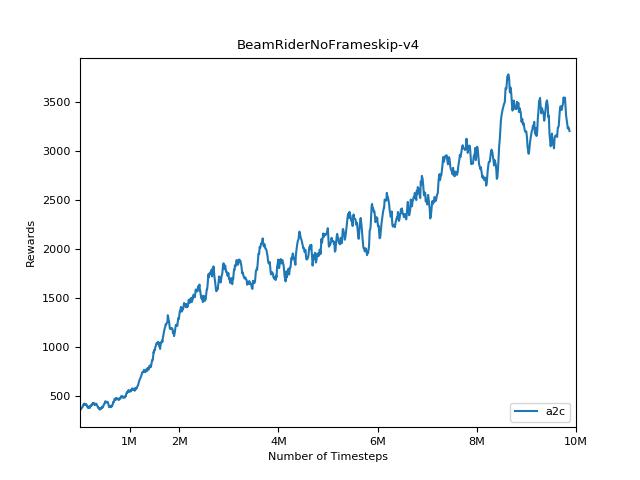
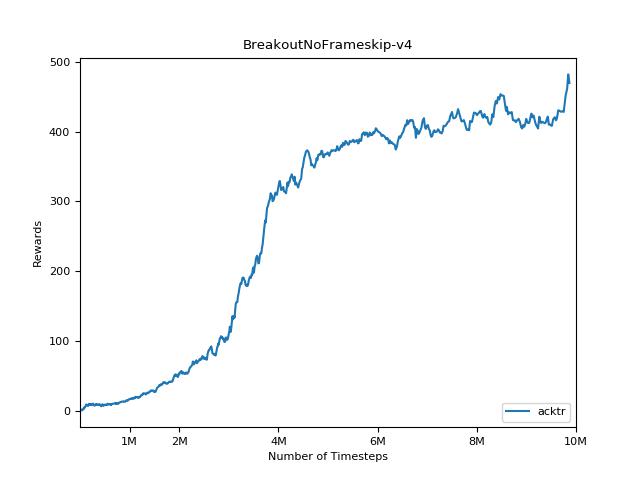
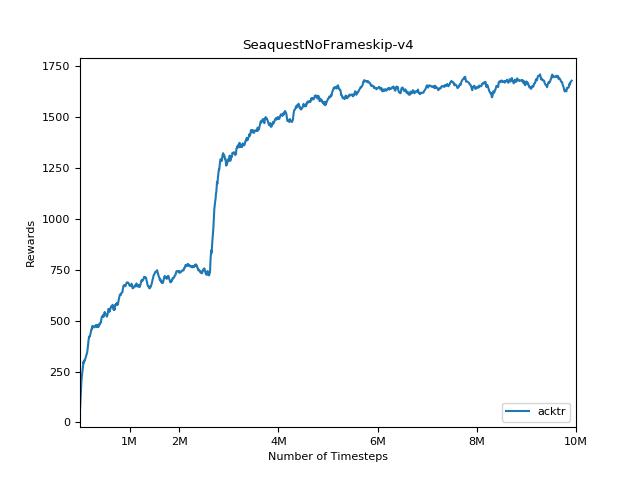
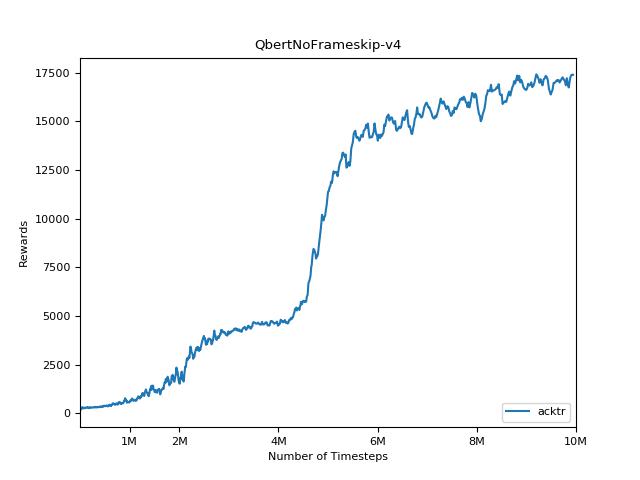
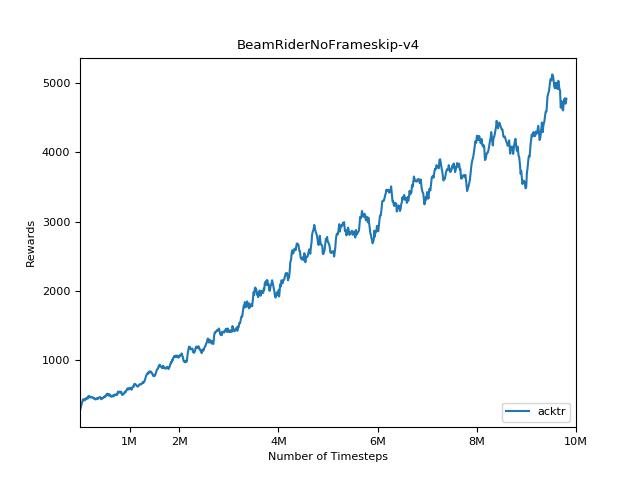
Esta implementación está inspirada en las líneas de base Operai para A2C, ACKTR y PPO. Utiliza los mismos parámetros hiper y el modelo, ya que estaban bien sintonizados para los juegos de Atari.
Utilice este bibtex si desea citar este repositorio en sus publicaciones:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
Recomiendo encarecidamente Pybullet como una alternativa de código abierto gratuita a Mujoco para tareas de control continuo.
Todos los entornos se operan utilizando exactamente la misma interfaz de gimnasio. Vea sus documentos para una lista completa.
Para usar los entornos de suite de control DeepMind, establezca el indicador --env-name dm.<domain_name>.<task_name> , donde domain_name y task_name son el nombre de un dominio (por ejemplo, hopper ) y una tarea dentro de ese dominio ( stand ) desde el suite de control profundo. Consulte su repositorio y su informe técnico para obtener una lista completa de dominios y tareas disponibles. Además de establecer la tarea, la API para interactuar con el entorno es exactamente la misma que para todos los entornos de gimnasio gracias a DM_Control2Gym.
Para instalar requisitos, siga:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atariLas contribuciones son muy bienvenidas. Si sabe cómo mejorar este código, abra un problema. Si desea enviar una solicitud de extracción, primero abra un problema. También vea una lista de TODO a continuación.
También estoy buscando voluntarios para ejecutar todos los experimentos en Atari y Mujoco (con múltiples semillas aleatorias).
Es extremadamente difícil reproducir resultados para los métodos de aprendizaje de refuerzo. Consulte "Aprendizaje de refuerzo profundo que importa" para obtener más información. Traté de reproducir los resultados de Operai lo más cerca posible. Sin embargo, las diferencias de especialización en el rendimiento pueden ser causadas incluso por diferencias menores en las bibliotecas de TensorFlow y Pytorch.
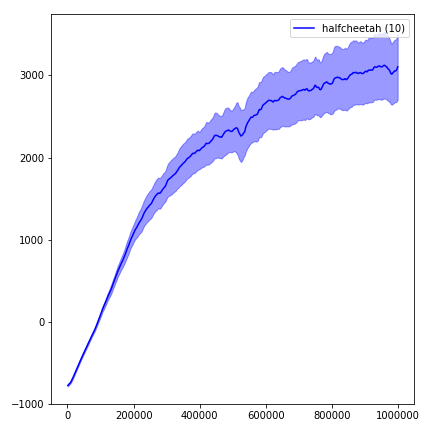
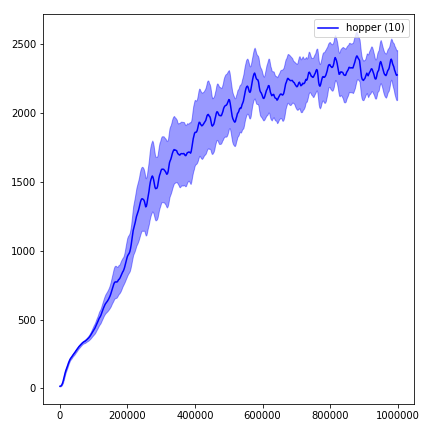
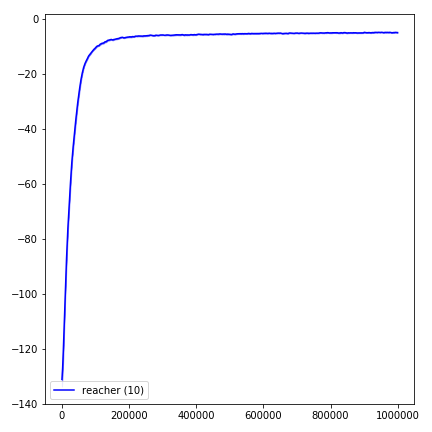
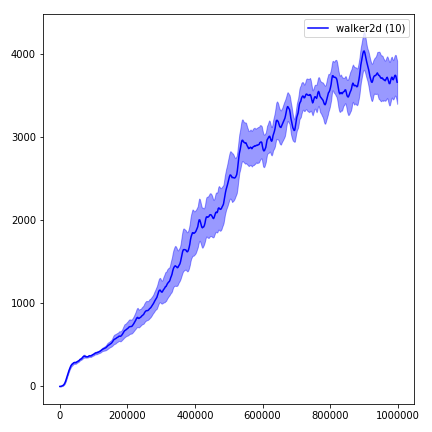
Para visualizar los resultados, use visualize.ipynb .
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 Siempre intente usar la bandera --use-proper-time-limits . Se maneja correctamente trayectorias parciales (ver https://github.com/sfujim/td3/blob/master/main.py#l123).
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR requiere que se realicen algunas modificaciones específicamente para Mujoco. Pero en este momento, quiero mantener este código lo más unificado posible. Por lo tanto, busco mejores formas de integrarlo en la base de código.
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "