pytorch a2c ppo acktr gail
1.0.0
PPO นั้นยอดเยี่ยม แต่นักวิจารณ์นักแสดงที่อ่อนนุ่มสามารถดีกว่าสำหรับงานควบคุมอย่างต่อเนื่องจำนวนมาก โปรดตรวจสอบที่เก็บ RL ใหม่ของฉันใน JAX
นี่คือการใช้งาน pytorch ของ
ดูโพสต์ OpenAI: A2C/ACKTR และ PPO สำหรับข้อมูลเพิ่มเติม
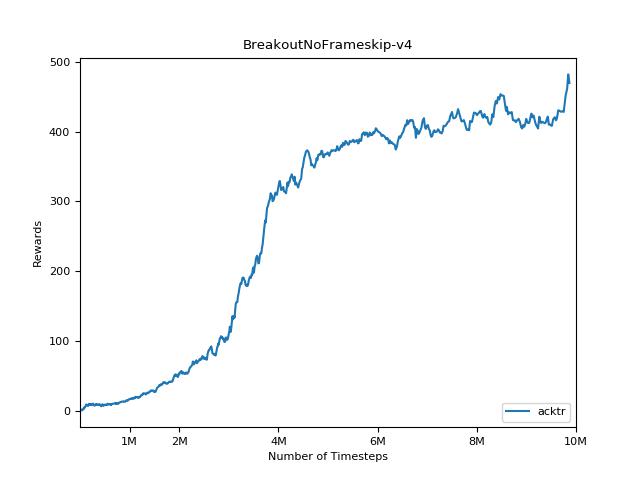
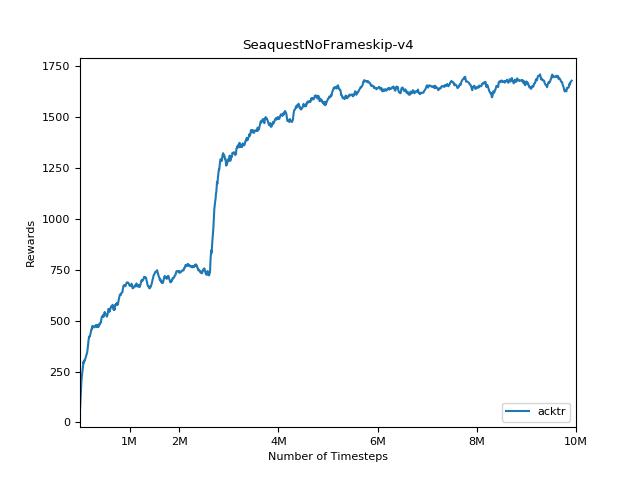
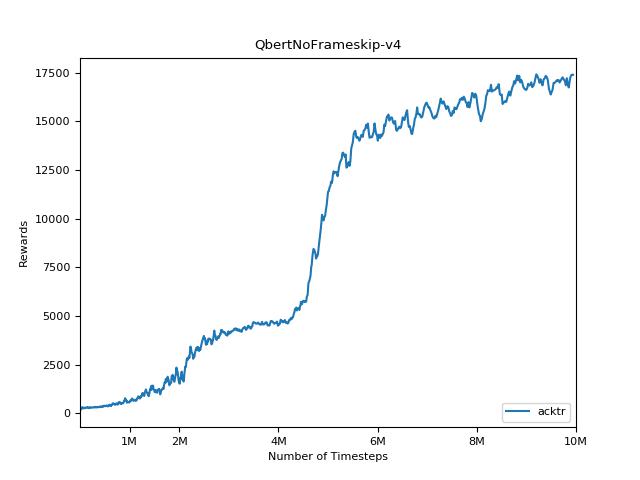
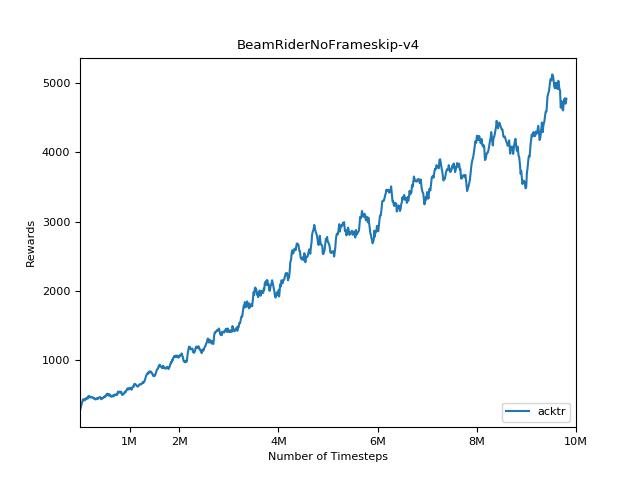
การใช้งานนี้ได้รับแรงบันดาลใจจาก OpenAI baselines สำหรับ A2C, ACKTR และ PPO มันใช้พารามิเตอร์ไฮเปอร์เดียวกันและโมเดลเนื่องจากพวกเขาได้รับการปรับแต่งอย่างดีสำหรับเกมอาตาริ
โปรดใช้ bibtex นี้หากคุณต้องการอ้างถึงที่เก็บนี้ในสิ่งพิมพ์ของคุณ:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
ฉันขอแนะนำ Pybullet เป็นทางเลือกโอเพ่นซอร์สฟรีสำหรับ Mujoco สำหรับงานควบคุมอย่างต่อเนื่อง
สภาพแวดล้อมทั้งหมดดำเนินการโดยใช้อินเทอร์เฟซยิมเดียวกัน ดูเอกสารของพวกเขาสำหรับรายการที่ครอบคลุม
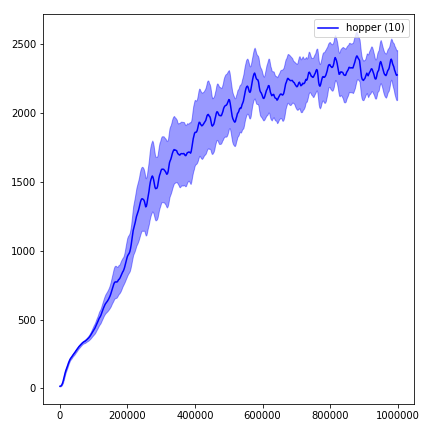
หากต้องการใช้สภาพแวดล้อมชุดควบคุม DeepMind ให้ตั้งค่าสถานะ --env-name dm.<domain_name>.<task_name> โดยที่ domain_name และ task_name เป็นชื่อของโดเมน (เช่น hopper ) และงานภายในโดเมนนั้น (เช่น stand ) จากห้องควบคุม DeepMind อ้างถึง Repo และรายงานเทคโนโลยีของพวกเขาสำหรับรายการเต็มรูปแบบของโดเมนและงานที่มีอยู่ นอกเหนือจากการตั้งค่างาน API สำหรับการโต้ตอบกับสภาพแวดล้อมนั้นเหมือนกับสภาพแวดล้อมในโรงยิมทั้งหมดด้วย DM_CONTROL2GYM
ในการติดตั้งข้อกำหนดให้ติดตาม:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atariยินดีต้อนรับการมีส่วนร่วมอย่างมาก หากคุณรู้วิธีทำให้รหัสนี้ดีขึ้นโปรดเปิดปัญหา หากคุณต้องการส่งคำขอดึงโปรดเปิดปัญหาก่อน ดูรายการสิ่งที่ต้องทำด้านล่าง
นอกจากนี้ฉันกำลังค้นหาอาสาสมัครเพื่อทำการทดลองทั้งหมดใน Atari และ Mujoco (มีเมล็ดสุ่มหลายชนิด)
เป็นเรื่องยากมากที่จะทำซ้ำผลลัพธ์สำหรับวิธีการเรียนรู้การเสริมแรง ดู "การเรียนรู้การเสริมแรงอย่างลึกซึ้งที่สำคัญ" สำหรับข้อมูลเพิ่มเติม ฉันพยายามทำซ้ำผลลัพธ์ของ OpenAI ให้ใกล้เคียงที่สุด อย่างไรก็ตามความแตกต่างของวิชาเอกในการแสดงอาจเกิดขึ้นได้แม้จะมีความแตกต่างเล็กน้อยในห้องสมุด Tensorflow และ Pytorch
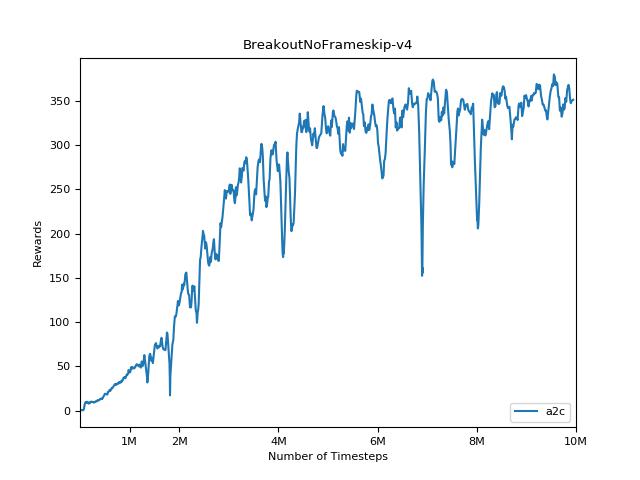
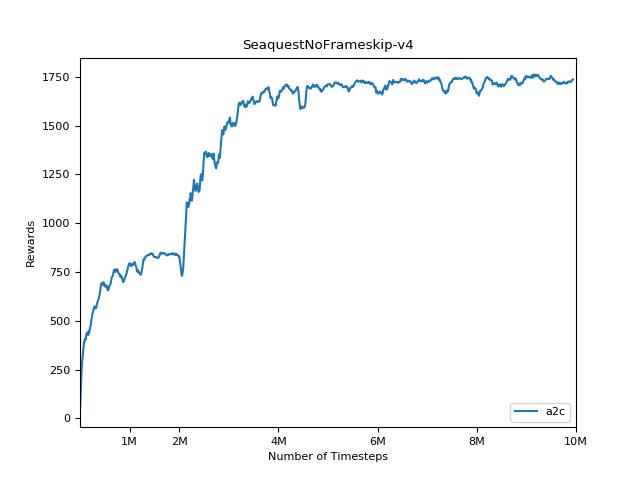
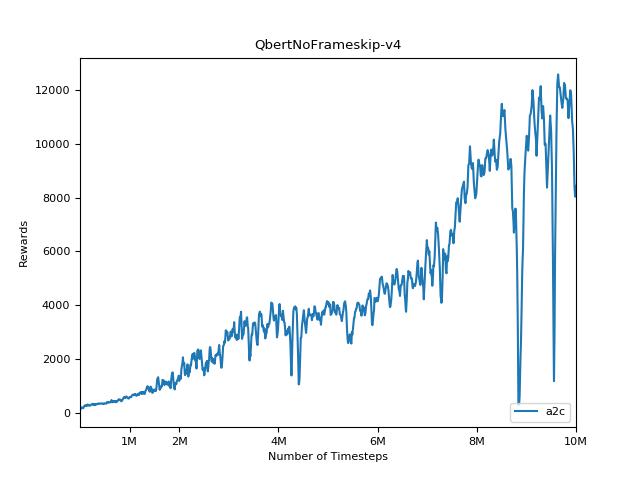
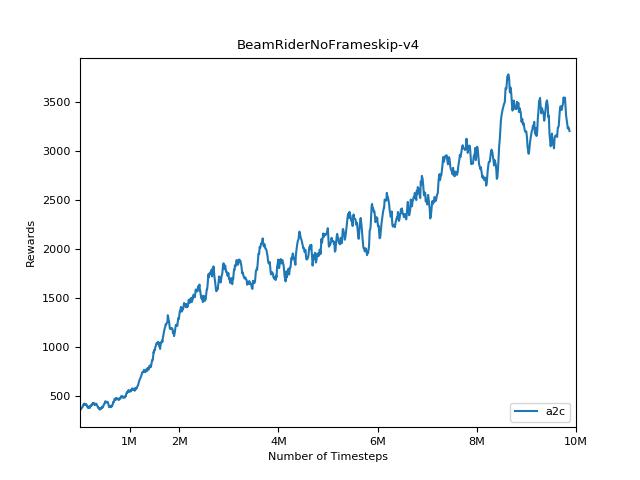
เพื่อให้เห็นภาพผลลัพธ์ให้ใช้ visualize.ipynb
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 โปรดลองใช้เสมอ --use-proper-time-limits เวลา มันจัดการวิถีบางส่วนอย่างถูกต้อง (ดู https://github.com/sfujim/td3/blob/master/main.py#l123)
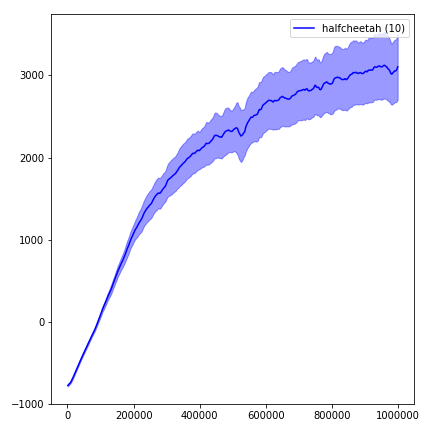
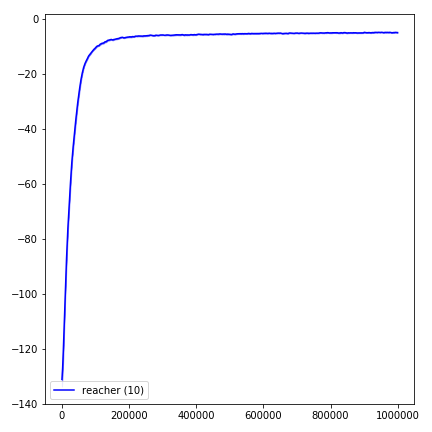
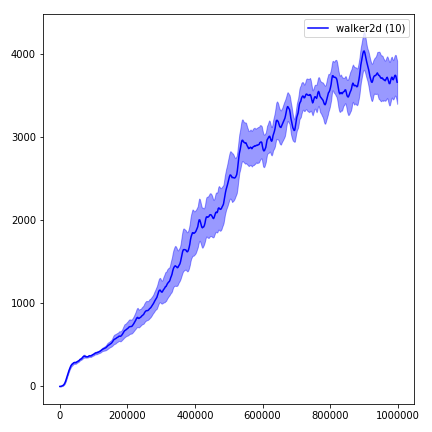
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR ต้องการการดัดแปลงบางอย่างที่จะทำโดยเฉพาะสำหรับ Mujoco แต่ในขณะนี้ฉันต้องการให้รหัสนี้เป็นแบบครบวงจรมากที่สุด ดังนั้นฉันจะหาวิธีที่ดีกว่าในการรวมเข้ากับ codebase
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "