pytorch a2c ppo acktr gail
1.0.0
PPO رائع ، ولكن الناقد الممثل الناعم يمكن أن يكون أفضل للعديد من مهام التحكم المستمر. يرجى التحقق من مستودع RL الجديد في Jax.
هذا هو تطبيق Pytorch
انظر أيضًا منشورات Openai: A2C/ACKTR و PPO لمزيد من المعلومات.
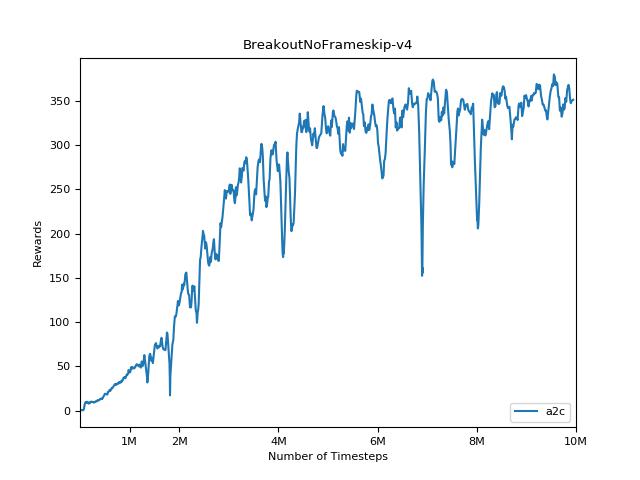
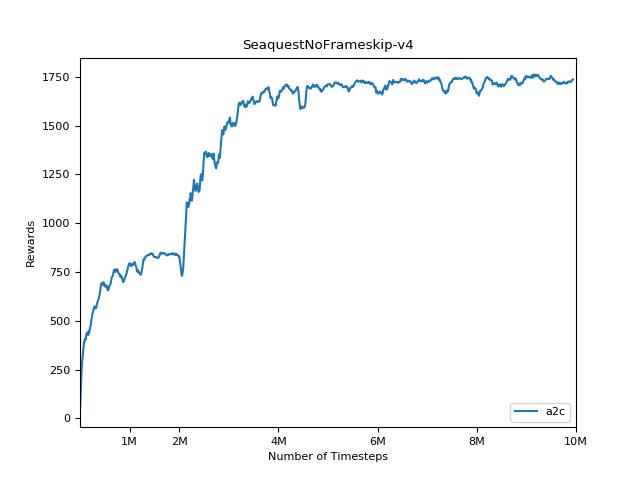
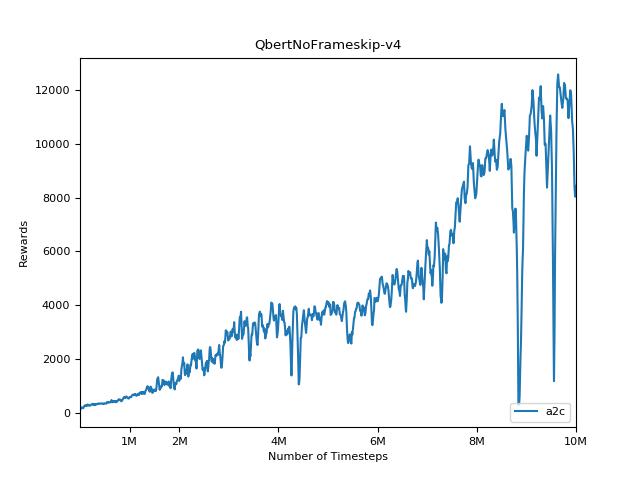
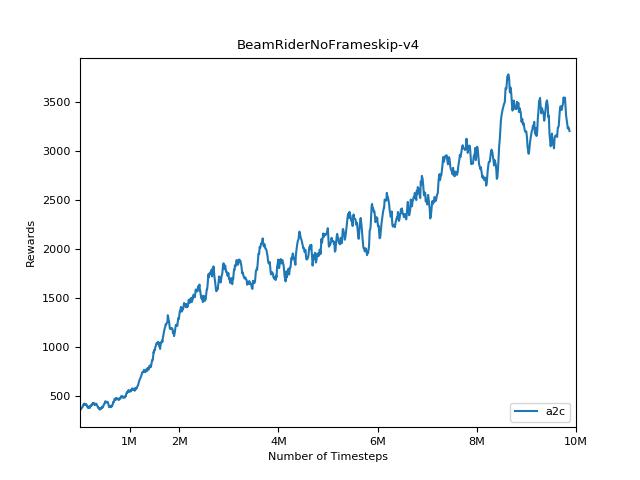
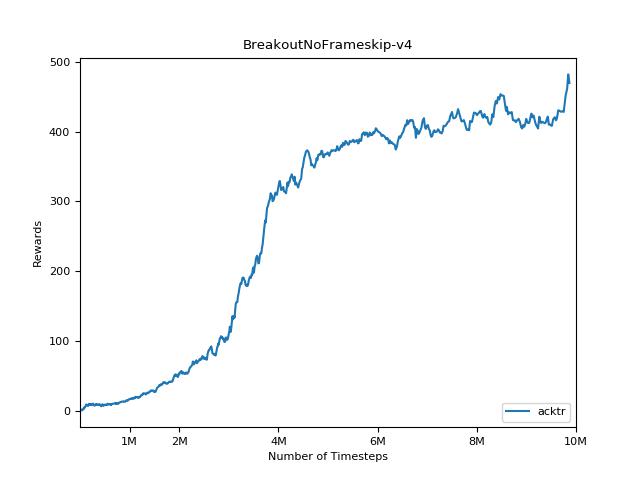
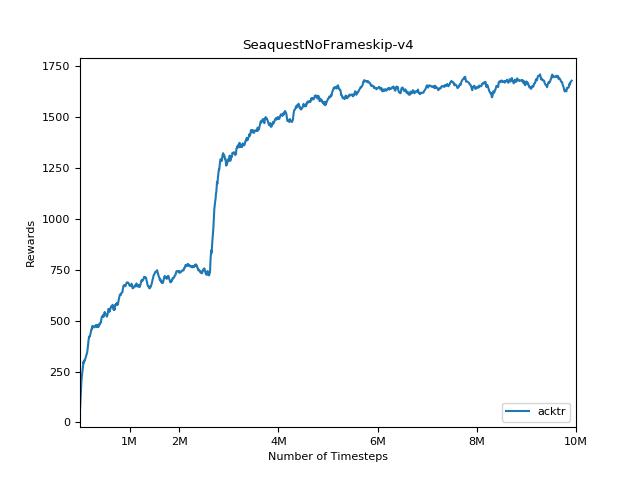
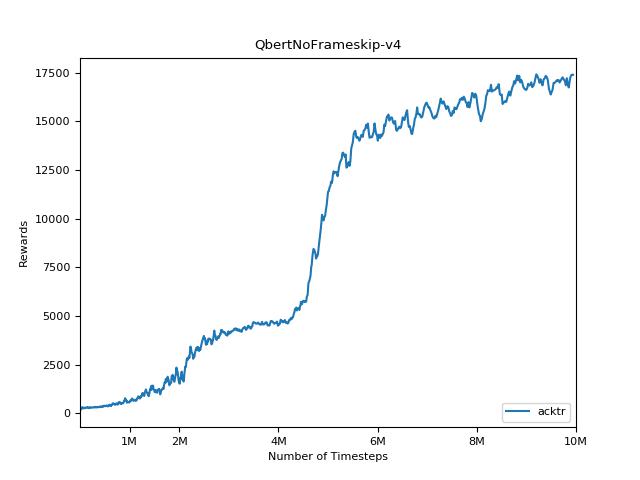
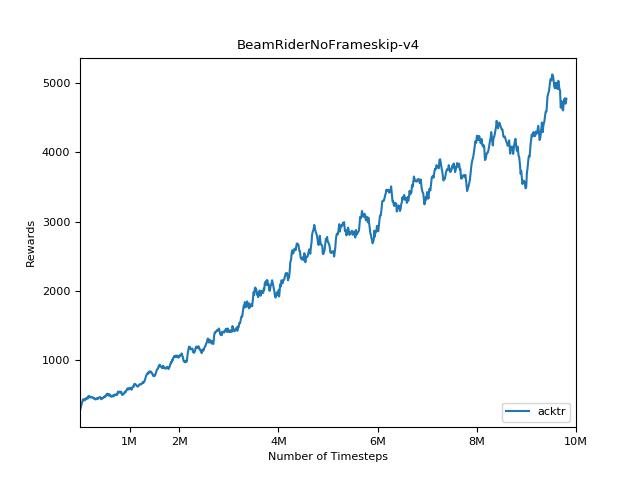
هذا التنفيذ مستوحى من خطوط الأساس Openai لـ A2C و ACKTR و PPO. يستخدم نفس المعلمات المفرطة والنموذج نظرًا لأنها تم ضبطها جيدًا لألعاب Atari.
يرجى استخدام هذا bibtex إذا كنت تريد الاستشهاد بهذا المستودع في منشوراتك:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
أوصي بشدة Pybullet كبديل مجاني مفتوح المصدر لـ Mujoco لمهام التحكم المستمرة.
يتم تشغيل جميع البيئات باستخدام واجهة الصالة الرياضية نفسها بالضبط. انظر وثائقهم للحصول على قائمة شاملة.
task_name بيئات جناح التحكم hopper DeepMind domain_name stand بتعيين العلامة --env-name dm.<domain_name>.<task_name> ارجع إلى Repo الخاصة بهم وتقريرهم التقني للحصول على قائمة كاملة من المجالات والمهام المتاحة. بخلاف تعيين المهمة ، فإن واجهة برمجة التطبيقات للتفاعل مع البيئة هي نفسها تمامًا كما هو الحال بالنسبة لجميع بيئات الصالة الرياضية بفضل DM_Control2gym.
من أجل تثبيت المتطلبات ، اتبع:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atariالمساهمات مرحب بها للغاية. إذا كنت تعرف كيفية جعل هذا الرمز أفضل ، فيرجى فتح مشكلة. إذا كنت ترغب في إرسال طلب سحب ، فيرجى فتح مشكلة أولاً. انظر أيضا قائمة TODO أدناه.
كما أنني أبحث عن متطوعين لإجراء جميع التجارب على Atari و Mujoco (مع بذور عشوائية متعددة).
من الصعب للغاية إعادة إنتاج النتائج لأساليب التعلم التعزيز. راجع "تعلم التعزيز العميق الذي يهم" لمزيد من المعلومات. حاولت إعادة إنتاج نتائج Openai بأكبر قدر ممكن. ومع ذلك ، يمكن أن تحدث اختلافات التخصصات في الأداء حتى بسبب الاختلافات الطفيفة في مكتبات Tensorflow و Pytorch.
من أجل تصور النتائج ، استخدم visualize.ipynb .
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 يرجى دائمًا محاولة استخدام العلم --use-proper-time-limits . إنه يتعامل بشكل صحيح مع المسارات الجزئية (انظر https://github.com/sfujim/td3/blob/master/main.py#l123).
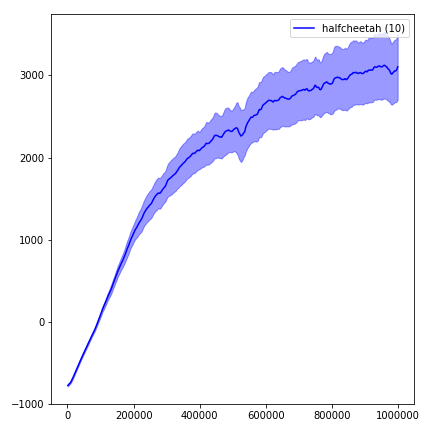
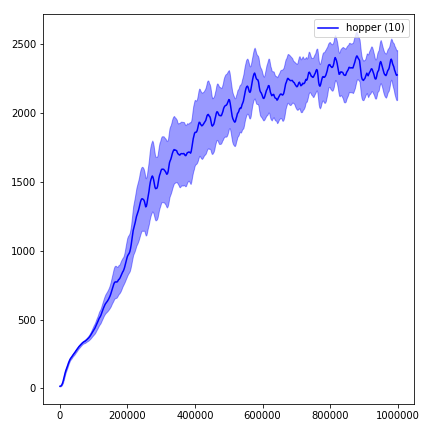
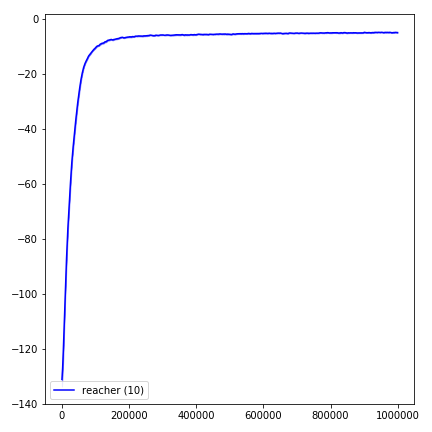
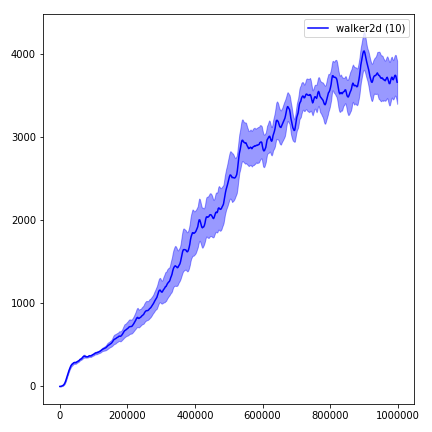
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsيتطلب ACKTR إجراء بعض التعديلات خصيصًا لـ Mujoco. لكن في الوقت الحالي ، أريد أن أبقي هذا الرمز موحد قدر الإمكان. وبالتالي ، سأذهب لطرق أفضل لدمجها في قاعدة الشفرة.
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "