pytorch a2c ppo acktr gail
1.0.0
PPO отличный, но критик мягкого актера может быть лучше для многих задач непрерывного управления. Пожалуйста, ознакомьтесь с моим новым хранилищем RL в JAX.
Это реализация Pytorch
Также см. Посты OpenAI: A2C/ACKTR и PPO для получения дополнительной информации.
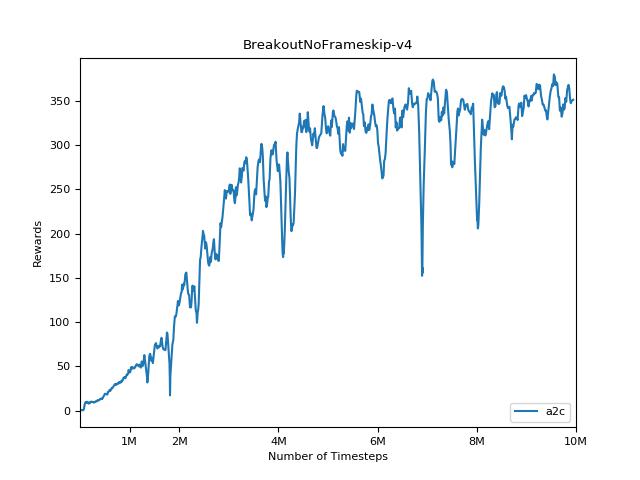
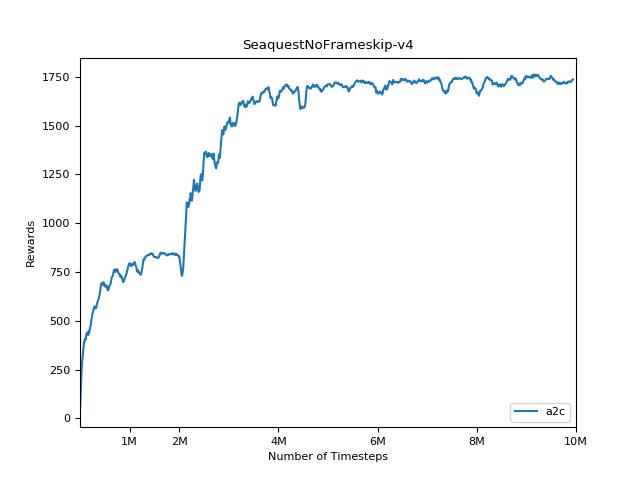
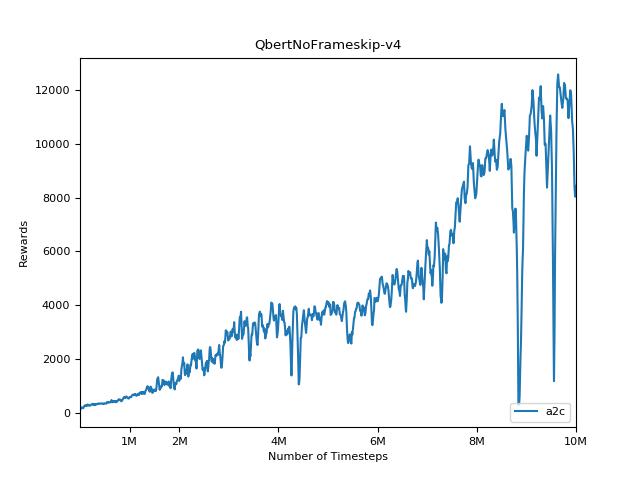
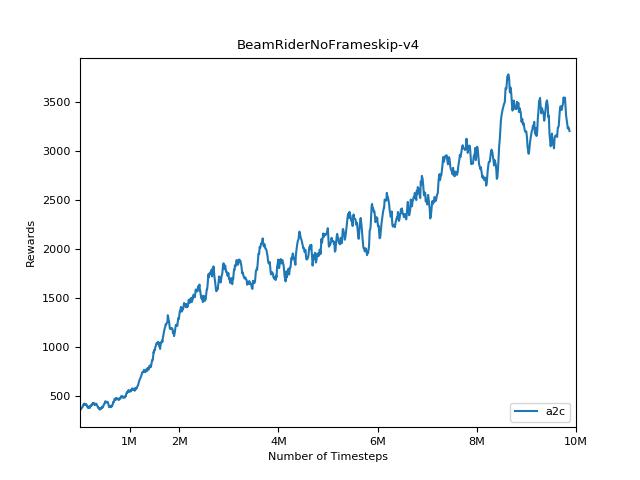
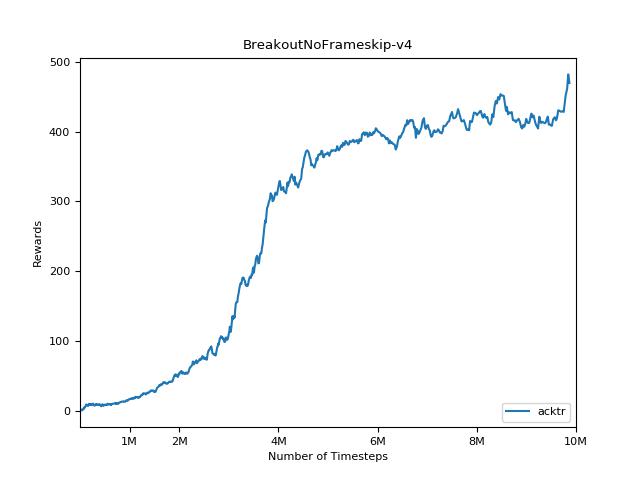
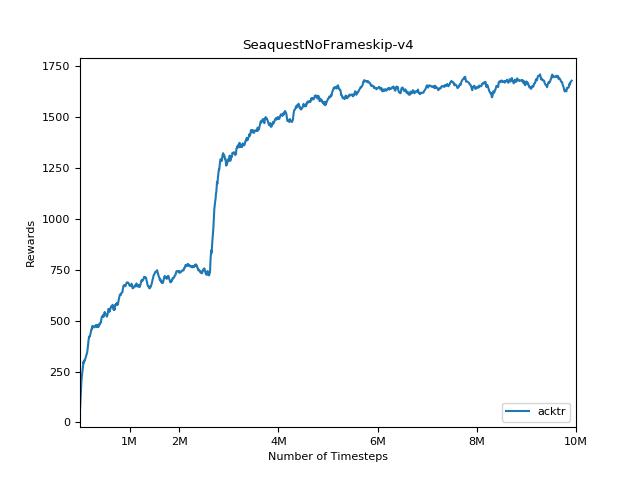
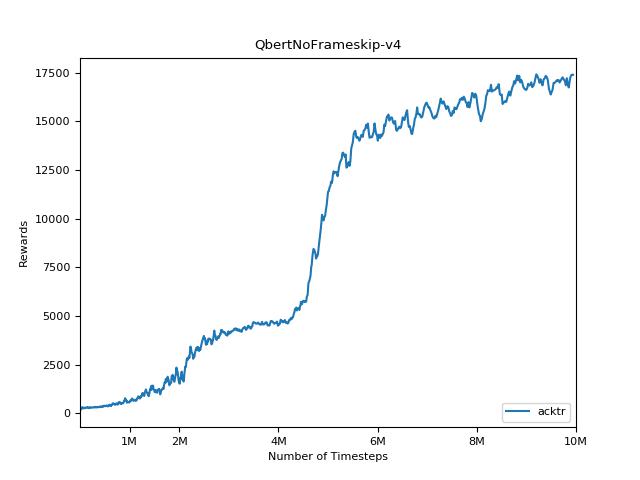
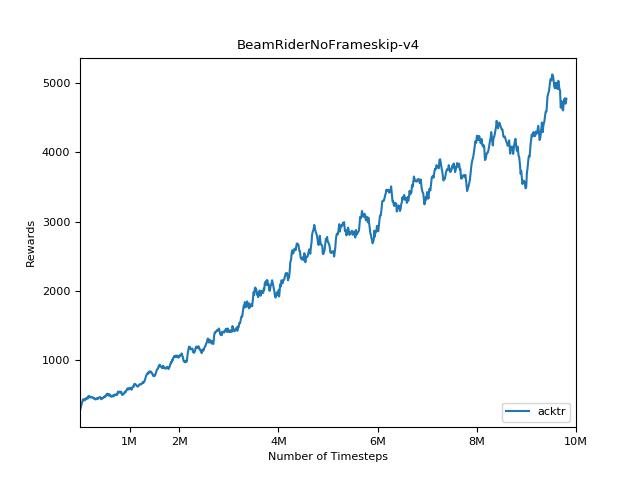
Эта реализация вдохновлена базовыми показателями OpenAI для A2C, ACKTR и PPO. Он использует те же гипер -парамеры и модель, так как они были хорошо настроены для игр Atari.
Пожалуйста, используйте этот Bibtex, если вы хотите привести этот репозиторий в своих публикациях:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
Я настоятельно рекомендую Pybullet в качестве бесплатной альтернативы с открытым исходным кодом Mujoco для задач непрерывного управления.
Все среды работают с использованием точно одного и того же интерфейса спортзала. Смотрите их документации для комплексного списка.
Чтобы использовать среды управления DeepMind, установите флаг --env-name dm.<domain_name>.<task_name> , где domain_name и task_name являются именем домена (например, hopper ) и задачи в этом домене (например, stand ) из панели управления DeepMind. Обратитесь к их репо и их техническому отчету для полного списка доступных доменов и задач. Помимо установки задачи, API для взаимодействия с окружающей средой точно такой же, как и для всех средств спортзала благодаря DM_CONTROL2GYM.
Чтобы установить требования, следуйте:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atariВзносы очень приветствуются. Если вы знаете, как сделать этот код лучше, откройте проблему. Если вы хотите подать запрос на привлечение, сначала откройте проблему. Также см. Список Тодо ниже.
Кроме того, я ищу добровольцев, чтобы провести все эксперименты на Atari и Mujoco (с несколькими случайными семенами).
Чрезвычайно сложно воспроизвести результаты для методов обучения подкрепления. См. «Обучение глубокому подкреплению, которое имеет значение» для получения дополнительной информации. Я пытался воспроизвести результаты Openai как можно ближе. Тем не менее, различия в мастерских в производительности могут быть вызваны даже незначительными различиями в библиотеках Tensorflow и Pytorch.
Чтобы визуализировать результаты, используйте visualize.ipynb .
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 Пожалуйста, всегда старайтесь использовать флаг --use-proper-time-limits . Он правильно обрабатывает частичные траектории (см. Https://github.com/sfujim/td3/blob/master/main.py#l123).
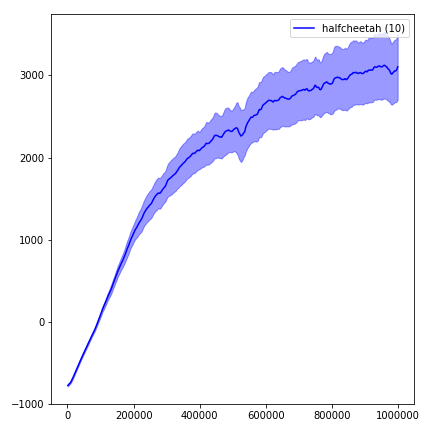
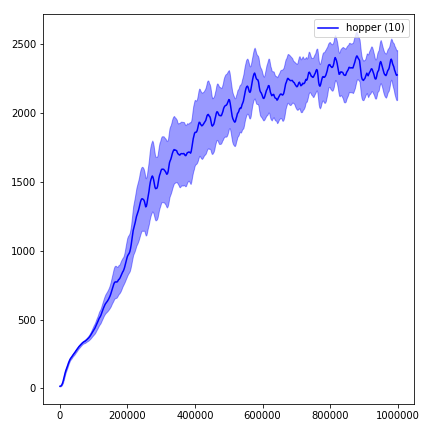
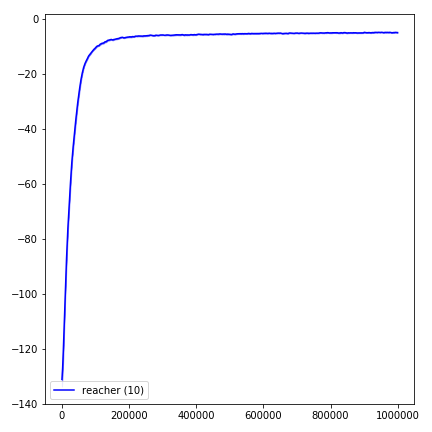
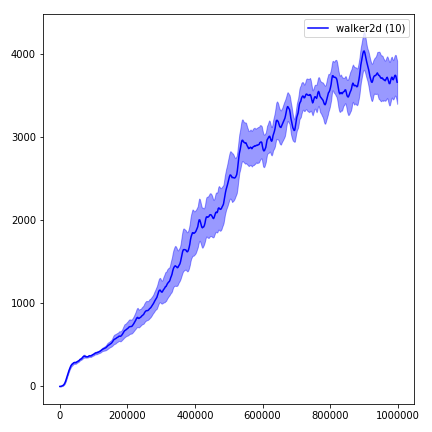
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR требует некоторых модификаций, которые должны быть сделаны специально для Mujoco. Но на данный момент я хочу сохранить этот код как можно более единым. Таким образом, я иду за лучшими способами интеграции в кодовую базу.
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "