pytorch a2c ppo acktr gail
1.0.0
PPO hebat, tetapi kritikus aktor lunak bisa lebih baik untuk banyak tugas kontrol yang berkelanjutan. Silakan periksa repositori RL baru saya di Jax.
Ini adalah implementasi Pytorch
Juga lihat posting OpenAI: A2C/ACKTR dan PPO untuk informasi lebih lanjut.
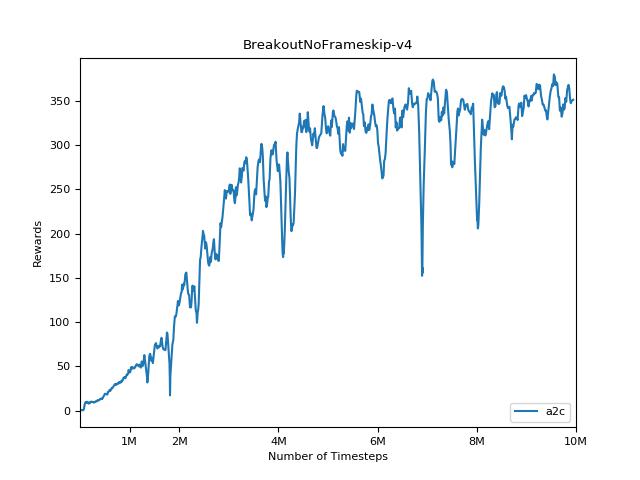
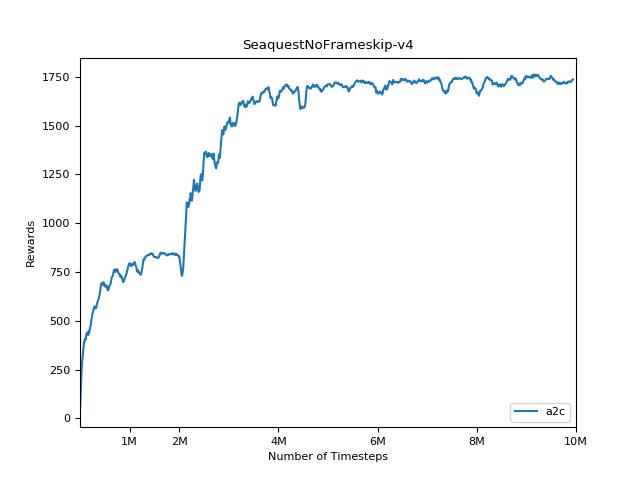
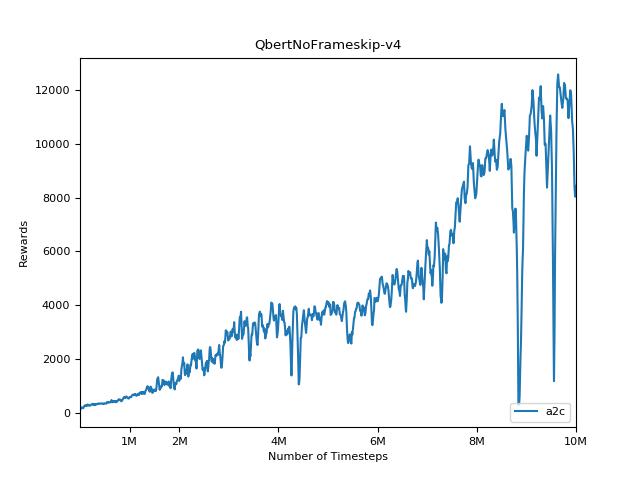
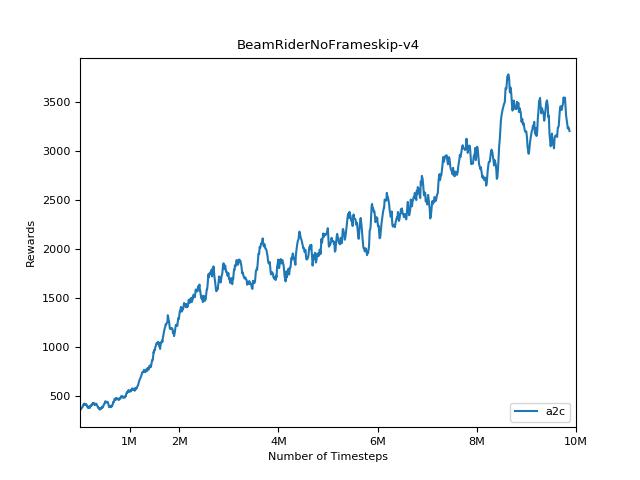
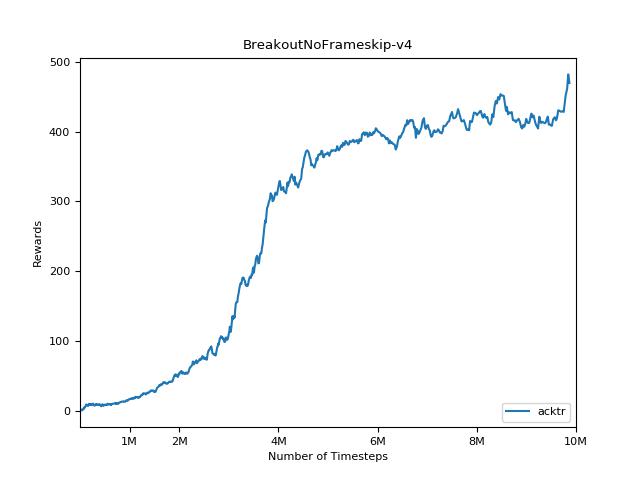
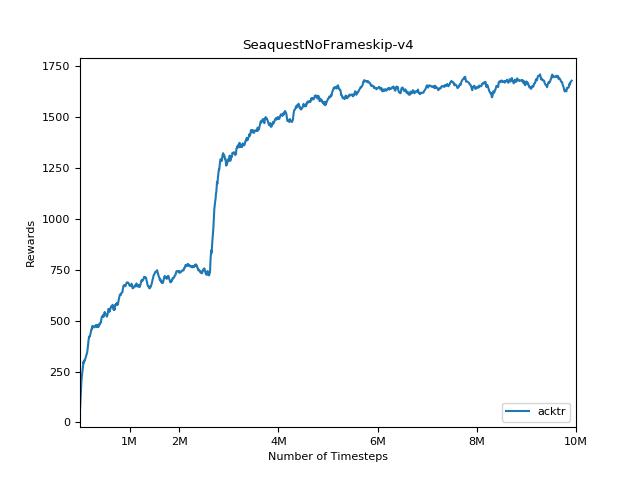
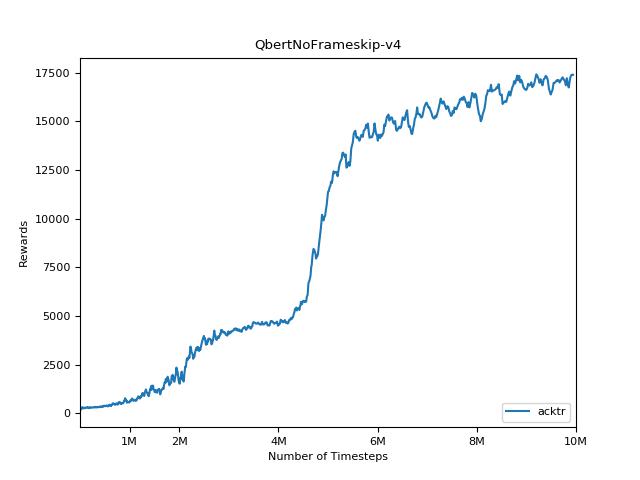
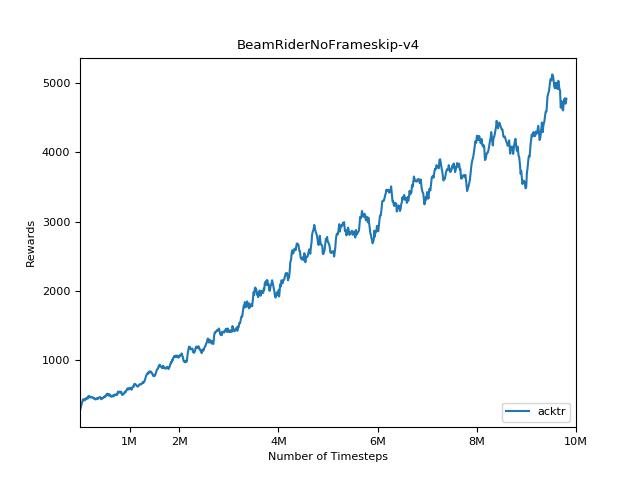
Implementasi ini terinspirasi oleh Baselines OpenAI untuk A2C, ACKTR dan PPO. Ini menggunakan parameter hiper yang sama dan model karena mereka disetel dengan baik untuk game atari.
Silakan gunakan Bibtex ini jika Anda ingin mengutip repositori ini di publikasi Anda:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
Saya sangat merekomendasikan Pybullet sebagai alternatif open source gratis untuk Mujoco untuk tugas kontrol berkelanjutan.
Semua lingkungan dioperasikan menggunakan antarmuka gym yang persis sama. Lihat dokumentasi mereka untuk daftar komprehensif.
Untuk menggunakan lingkungan suite kontrol DeepMind, atur bendera --env-name dm.<domain_name>.<task_name> , di mana domain_name dan task_name adalah nama domain (misalnya hopper ) dan tugas di dalam domain itu (misalnya stand ) dari DeepMind Control Suite. Lihat repo mereka dan laporan teknologi mereka untuk daftar lengkap domain dan tugas yang tersedia. Selain menetapkan tugas, API untuk berinteraksi dengan lingkungan persis sama dengan semua lingkungan gym berkat DM_CONTROL2GYM.
Untuk memasang persyaratan, ikuti:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atariKontribusi sangat disambut. Jika Anda tahu cara membuat kode ini lebih baik, buka masalah. Jika Anda ingin mengirimkan permintaan tarik, silakan buka masalah terlebih dahulu. Lihat juga daftar TODO di bawah ini.
Saya juga mencari sukarelawan untuk menjalankan semua percobaan di Atari dan Mujoco (dengan beberapa biji acak).
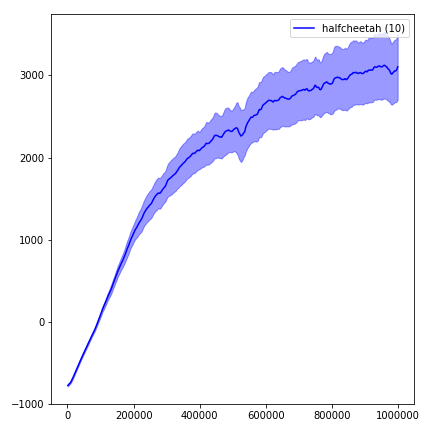
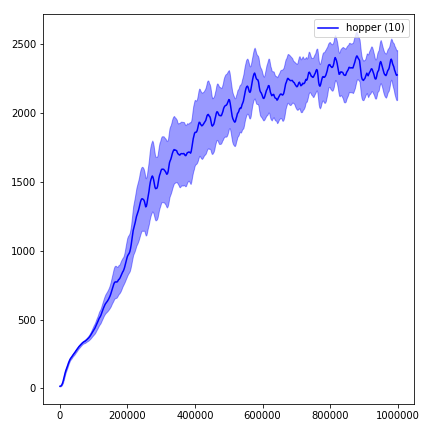
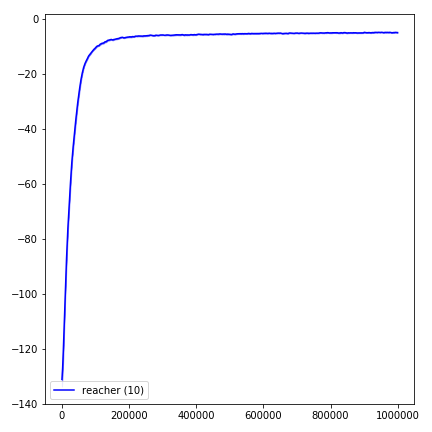
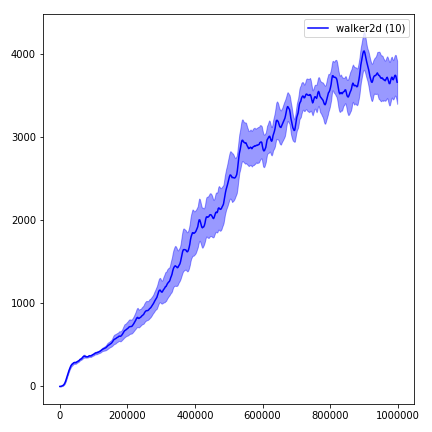
Sangat sulit untuk mereproduksi hasil untuk metode pembelajaran penguatan. Lihat "Pembelajaran Penguatan mendalam yang penting" untuk informasi lebih lanjut. Saya mencoba mereproduksi hasil openai sedekat mungkin. Namun, jurusan perbedaan dalam kinerja dapat disebabkan bahkan oleh perbedaan kecil dalam perpustakaan TensorFlow dan Pytorch.
Untuk memvisualisasikan hasil, gunakan visualize.ipynb .
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 Harap selalu coba gunakan --use-proper-time-limits . Ini menangani lintasan parsial dengan benar (lihat https://github.com/sfujim/td3/blob/master/main.py#l123).
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR membutuhkan beberapa modifikasi untuk dibuat khusus untuk Mujoco. Tetapi saat ini, saya ingin menjaga kode ini sebersih mungkin. Jadi, saya mencari cara yang lebih baik untuk mengintegrasikannya ke dalam basis kode.
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "