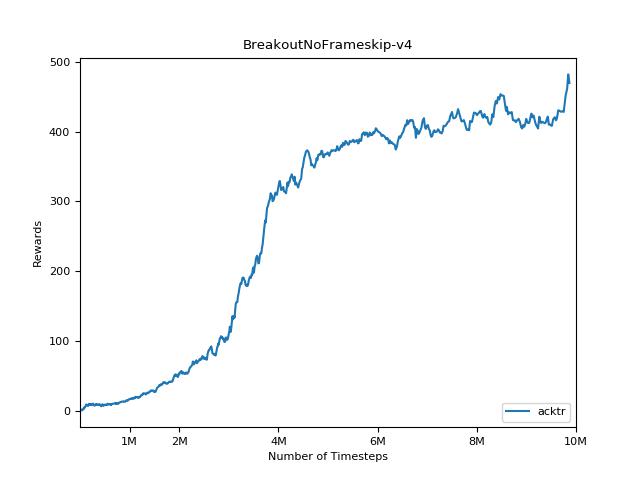
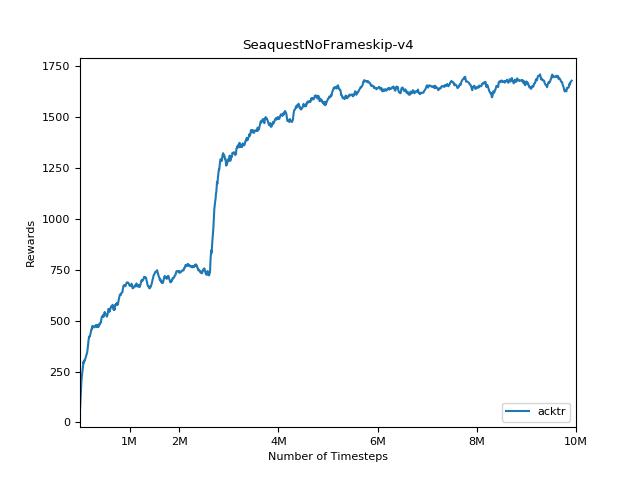
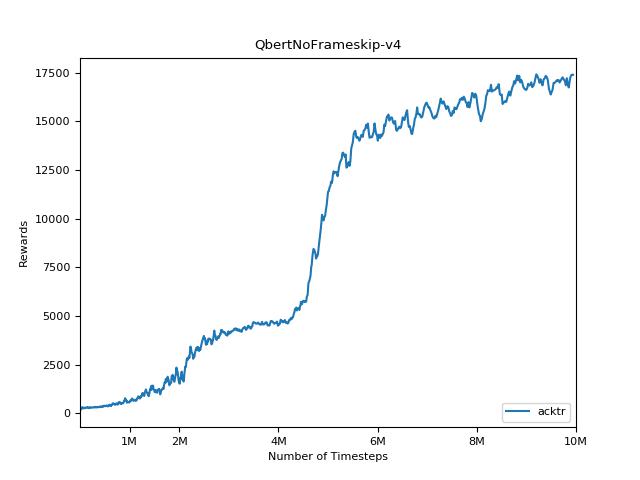
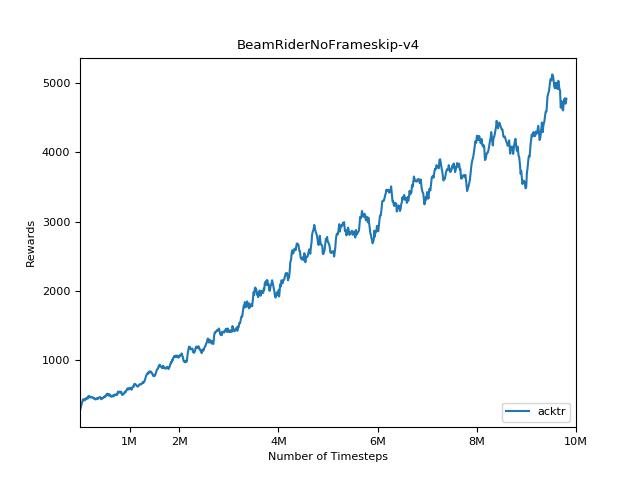
pytorch a2c ppo acktr gail
1.0.0
Le PPO est génial, mais le critique d'acteur doux peut être meilleur pour de nombreuses tâches de contrôle continu. Veuillez consulter mon nouveau référentiel RL à Jax.
Il s'agit d'une implémentation pytorch de
Voir également les messages OpenAI: A2C / ACKTR et PPO pour plus d'informations.
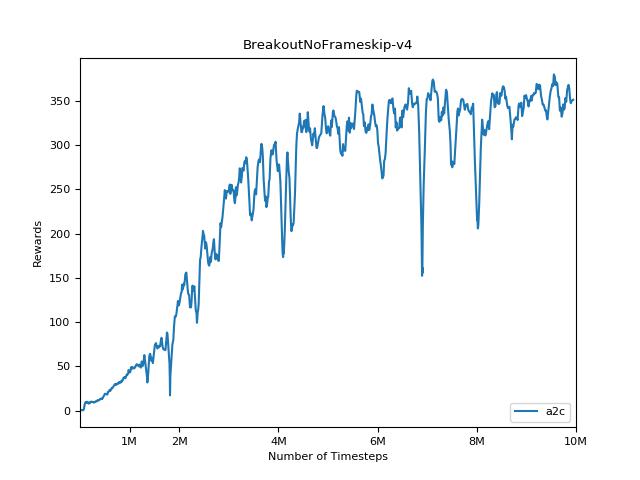
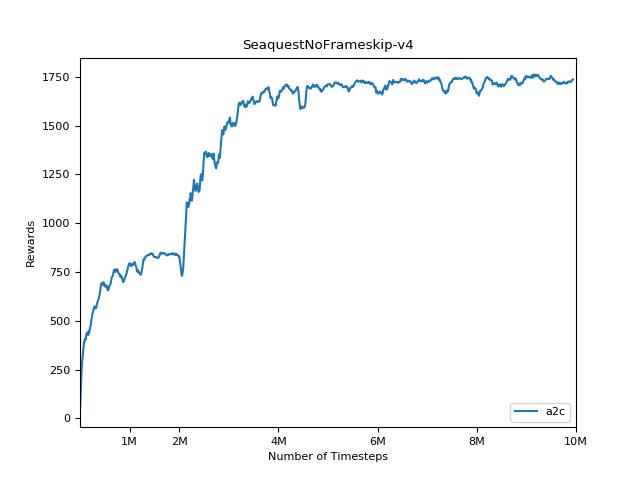
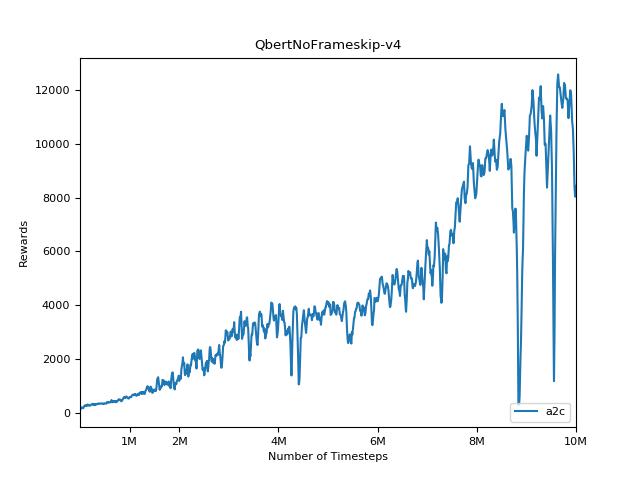
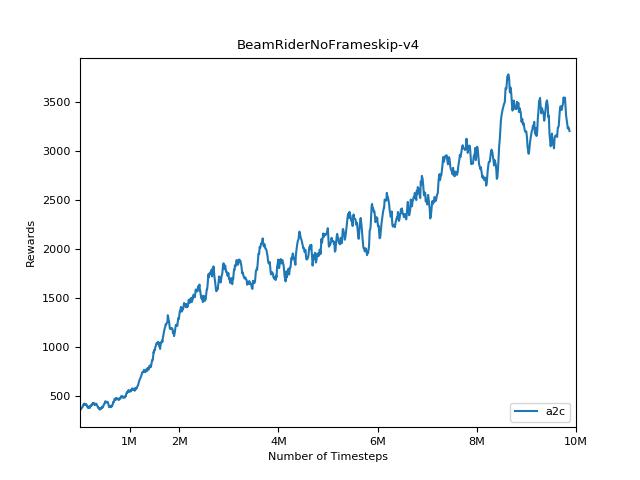
Cette implémentation est inspirée par les lignes de base Openai pour A2C, ACKTR et PPO. Il utilise les mêmes paramètres hyper et le modèle car ils ont été bien réglés pour les jeux Atari.
Veuillez utiliser ce bibtex si vous souhaitez citer ce référentiel dans vos publications:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
Je recommande fortement Pybullet comme alternative open source gratuite à Mujoco pour les tâches de contrôle continu.
Tous les environnements sont exploités en utilisant exactement la même interface de gym. Voir leurs documentations pour une liste complète.
Pour utiliser les environnements DeepMind Control Suite, définissez le Flag --env-name dm.<domain_name>.<task_name> , où domain_name et task_name sont le nom d'un domaine (par exemple hopper ) et une tâche dans ce domaine (par stand ) de la suite de contrôle DeepMind. Reportez-vous à leur dépôt et à leur rapport technologique pour une liste complète des domaines et tâches disponibles. En plus de définir la tâche, l'API pour interagir avec l'environnement est exactement la même que pour tous les environnements de gym grâce à DM_Control2Gym.
Afin d'installer les exigences, suivez:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atariLes contributions sont les bienvenues. Si vous savez comment améliorer ce code, veuillez ouvrir un problème. Si vous souhaitez soumettre une demande de traction, veuillez d'abord ouvrir un problème. Voir également une liste de TODO ci-dessous.
Je cherche également des bénévoles pour exécuter toutes les expériences sur Atari et Mujoco (avec plusieurs graines aléatoires).
Il est extrêmement difficile de reproduire des résultats pour les méthodes d'apprentissage du renforcement. Voir «Apprentissage en renforcement profond qui compte» pour plus d'informations. J'ai essayé de reproduire les résultats ouverts aussi étroitement que possible. Cependant, les différences de performance des majors peuvent être causées même par des différences mineures dans les bibliothèques Tensorflow et Pytorch.
Afin de visualiser les résultats, utilisez visualize.ipynb .
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 Veuillez toujours essayer d'utiliser le drapeau --use-proper-time-limits . Il gère correctement les trajectoires partielles (voir https://github.com/sfujim/td3/blob/master/main.py#l123).
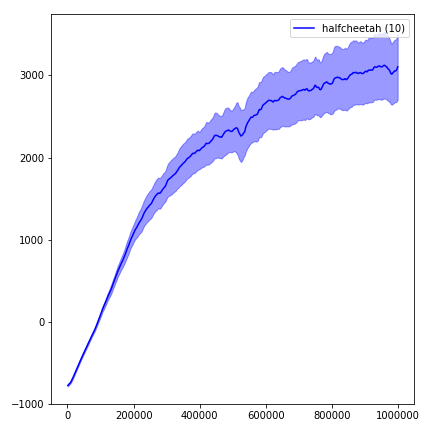
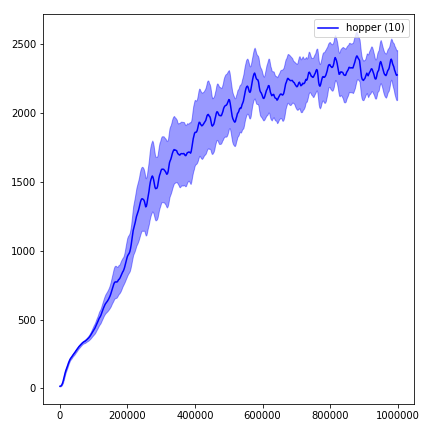
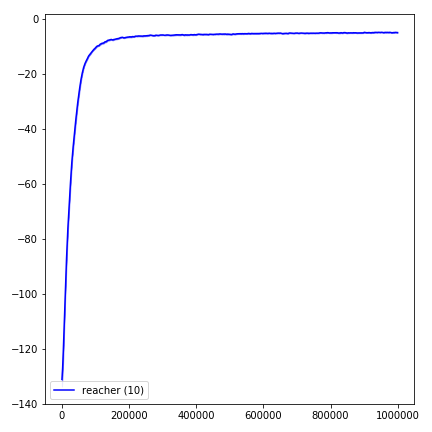
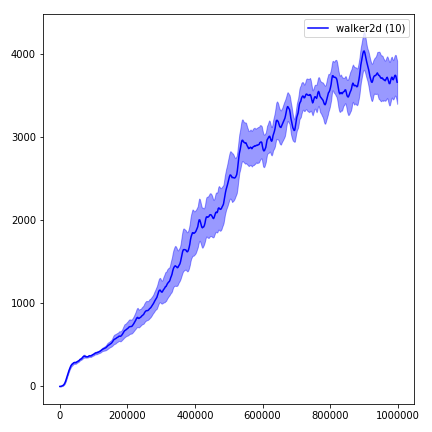
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR nécessite que certaines modifications soient apportées spécifiquement pour Mujoco. Mais pour le moment, je veux garder ce code aussi unifié que possible. Ainsi, je vais pour de meilleures façons de l'intégrer dans la base de code.
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "