pytorch a2c ppo acktr gail
1.0.0
PPO ist großartig, aber ein weicher Schauspielerkritiker kann für viele kontinuierliche Kontrollaufgaben besser sein. Bitte schauen Sie sich mein neues RL -Repository in JAX an.
Dies ist eine Pytorch -Implementierung von
Weitere Informationen finden Sie in den OpenAI -Posts: A2C/ACKTR und PPO.
Diese Implementierung ist von den OpenAI -Baselines für A2C, ACKTR und PPO inspiriert. Es verwendet die gleichen Hyperparameter und das Modell, da sie für Atari -Spiele gut abgestimmt waren.
Bitte verwenden Sie dieses Bibtex, wenn Sie dieses Repository in Ihren Veröffentlichungen zitieren möchten:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
Ich empfehle Pybullet als kostenlose Open -Source -Alternative zu Mujoco für kontinuierliche Kontrollaufgaben.
Alle Umgebungen werden mit genau derselben Fitnessoberfläche betrieben. Eine umfassende Liste finden Sie in ihren Dokumentationen.
Um die DeepMind Control Suite-Umgebungen zu verwenden, setzen Sie das Flag --env-name dm.<domain_name>.<task_name> , wobei domain_name und task_name der Name einer Domäne (z. B. hopper ) und eine Aufgabe innerhalb dieser Domäne (z. B. stand ) aus der DeepMind Control Suite sind. In ihrem Repo und ihrem Tech -Bericht finden Sie eine vollständige Liste der verfügbaren Domänen und Aufgaben. Abgesehen von der Aufgabe ist die API für die Interaktion mit der Umgebung genau das gleiche wie für alle Fitnessumgebungen dank DM_CONTROL2GYM.
Um Anforderungen zu installieren, folgen Sie:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atariBeiträge sind sehr willkommen. Wenn Sie wissen, wie Sie diesen Code besser machen können, öffnen Sie bitte ein Problem. Wenn Sie eine Pull -Anfrage einreichen möchten, öffnen Sie bitte zuerst ein Problem. Siehe auch eine Todo -Liste unten.
Außerdem suche ich nach Freiwilligen, um alle Experimente auf Atari und Mujoco (mit mehreren zufälligen Samen) durchzuführen.
Es ist äußerst schwierig, Ergebnisse für Verstärkungslernen zu reproduzieren. Weitere Informationen finden Sie in "Deep verstärktes Lernen, das zählt". Ich habe versucht, OpenAI -Ergebnisse so genau wie möglich zu reproduzieren. Die Leistungsunterschiede in den Hauptfächern können jedoch auch durch geringfügige Unterschiede in den Tensorflow- und Pytorch -Bibliotheken verursacht werden.
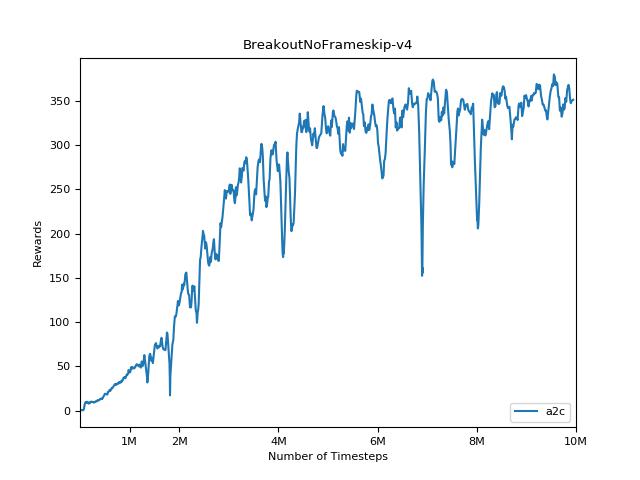
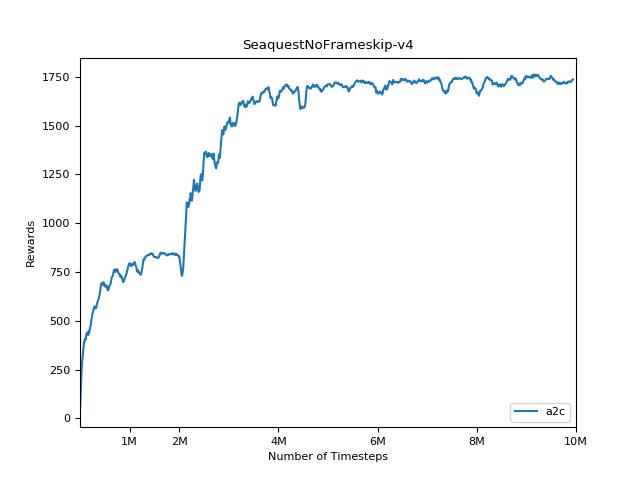
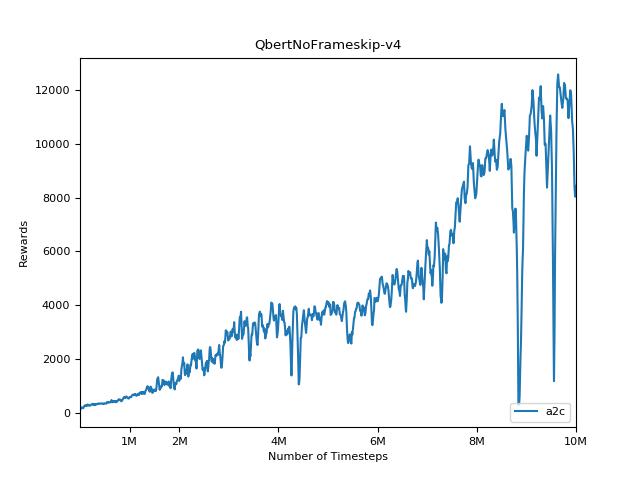
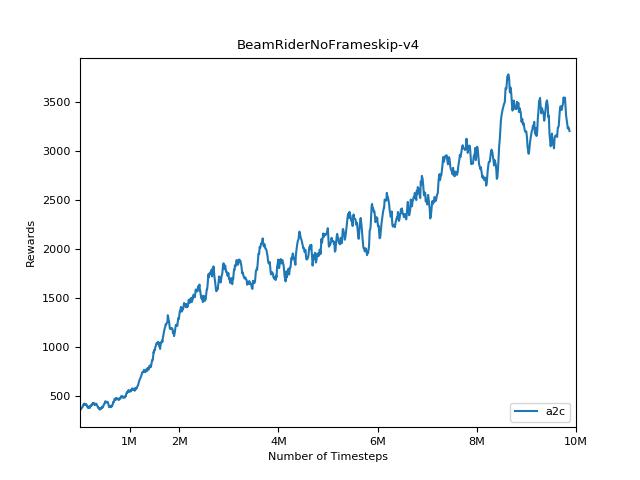
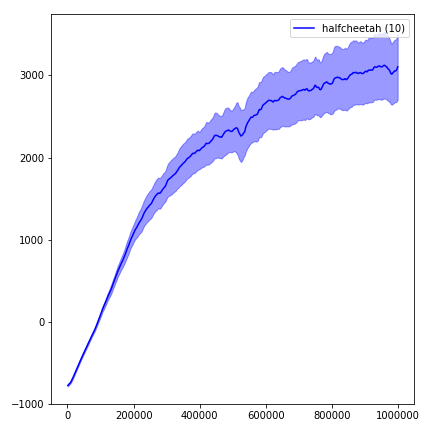
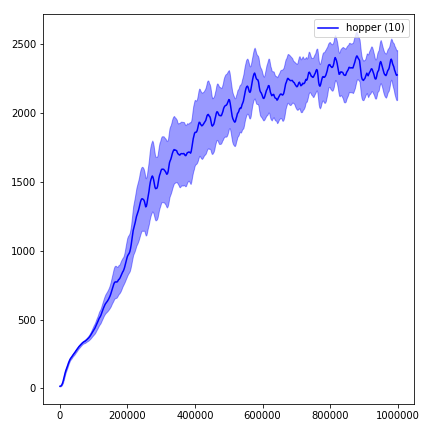
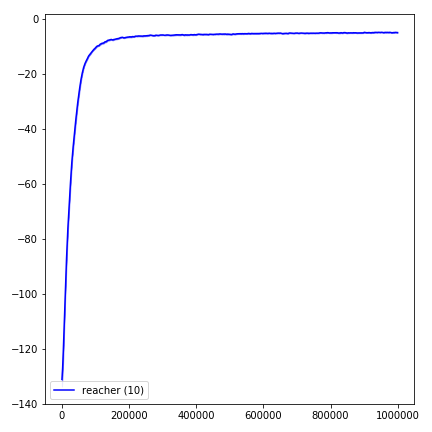
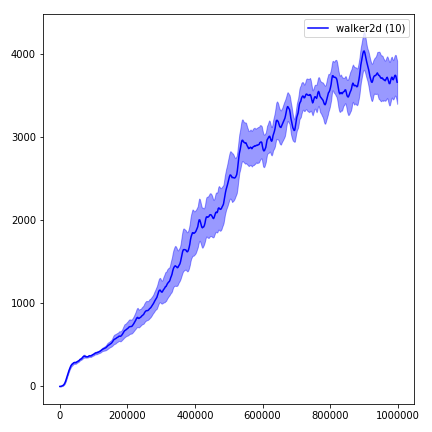
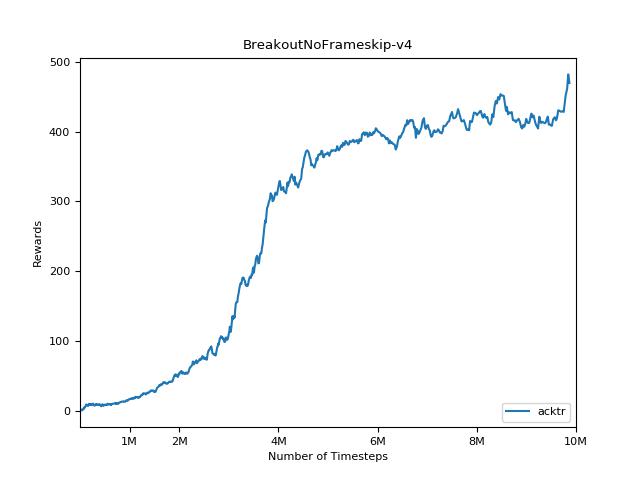
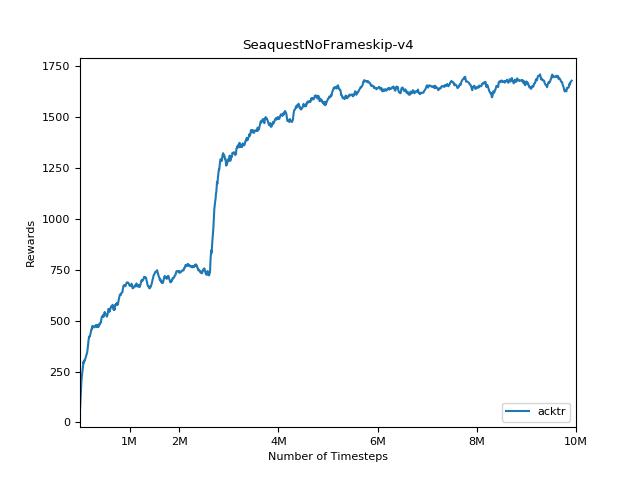
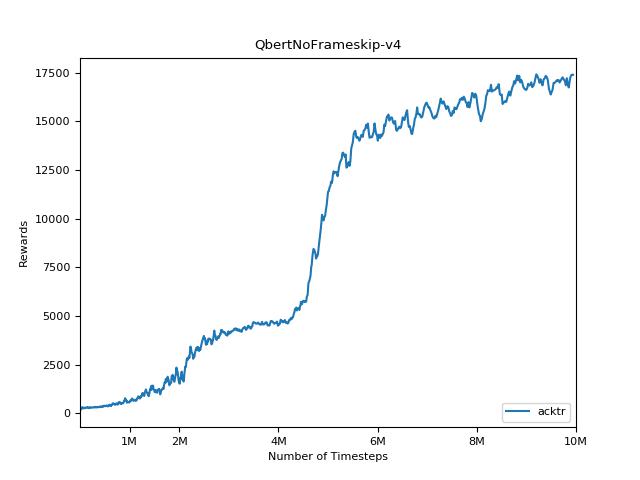
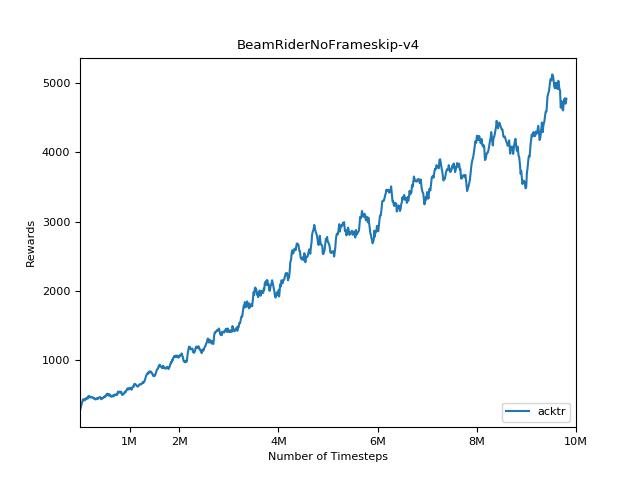
Um die Ergebnisse zu visualisieren, verwenden Sie visualize.ipynb .
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 Bitte versuchen Sie immer --use-proper-time-limits die Flagge zu verwenden. Es behandelt die teilweisen Trajektorien ordnungsgemäß (siehe https://github.com/sfujim/td3/blob/master/main.py#l123).
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR erfordert einige Änderungen, die speziell für MUJOCO vorgenommen werden können. Aber im Moment möchte ich diesen Code so einig wie möglich halten. Daher gehe ich bessere Möglichkeiten, um es in die Codebasis zu integrieren.
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "