pytorch a2c ppo acktr gail
1.0.0
PPO很棒,但是软演员评论家对于许多连续的控制任务可以更好。请在JAX中查看我的新RL存储库。
这是Pytorch的实现
另请参阅OpenAI帖子:A2C/ACKTR和PPO以获取更多信息。
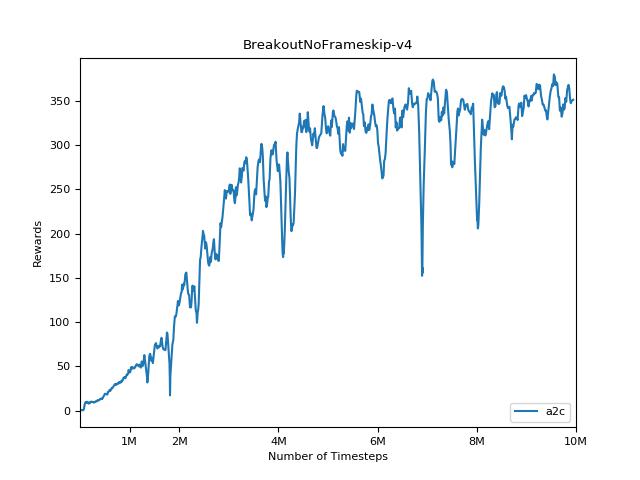
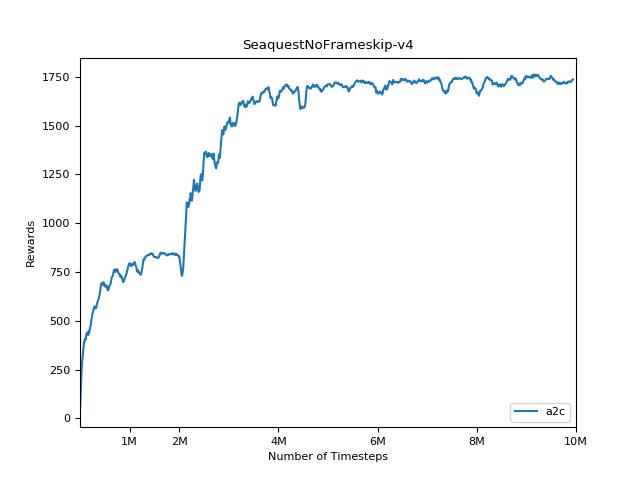
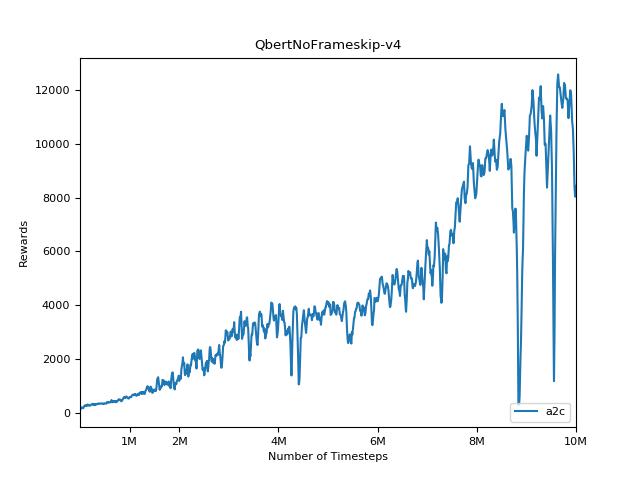
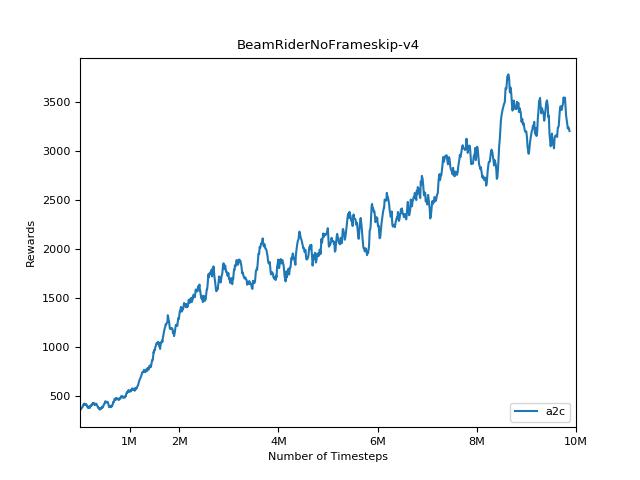
该实现的灵感来自A2C,ACKTR和PPO的OpenAI基准。它使用相同的超级参数和模型,因为它们在Atari游戏中进行了很好的调整。
如果您想在出版物中引用此存储库,请使用此Bibtex:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
我强烈建议Pybullet作为持续控制任务的Mujoco的免费开源替代品。
所有环境均使用完全相同的健身房接口进行操作。请参阅他们的文档以获取全面列表。
要使用DeepMind Control Suite环境,请设置标志--env-name dm.<domain_name>.<task_name> ,其中domain_name和task_name是域名(例如hopper stand和该域中的任务(例如,来自DeepMind Control Suite)。请参阅他们的回购及其技术报告,以获取可用域和任务的完整列表。除了设置任务外,与DM_Control2Gym相互交互的API与所有健身房环境完全相同。
为了安装要求,请参见:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atari贡献非常欢迎。如果您知道如何使此代码更好,请打开问题。如果您想提交拉动请求,请首先打开问题。另请参阅下面的待办事项列表。
另外,我正在寻找志愿者在Atari和Mujoco上运行所有实验(带有多个随机种子)。
重现增强学习方法的结果非常困难。有关更多信息,请参见“重要的强化学习”。我试图尽可能地重现OpenAI结果。但是,即使是由于Tensorflow和Pytorch库的较小差异,绩效的大满贯差异也可能引起。
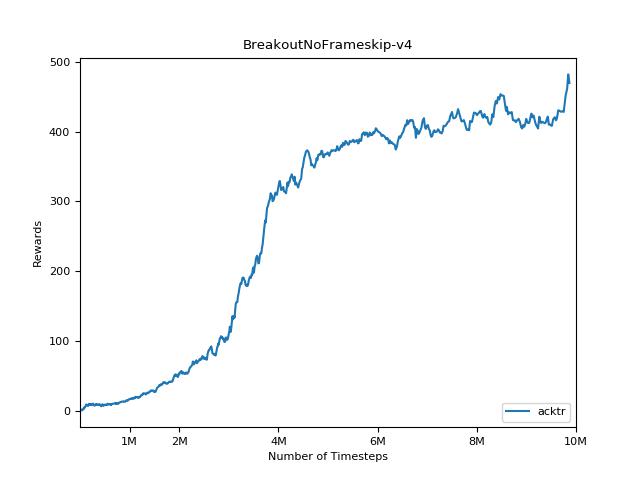
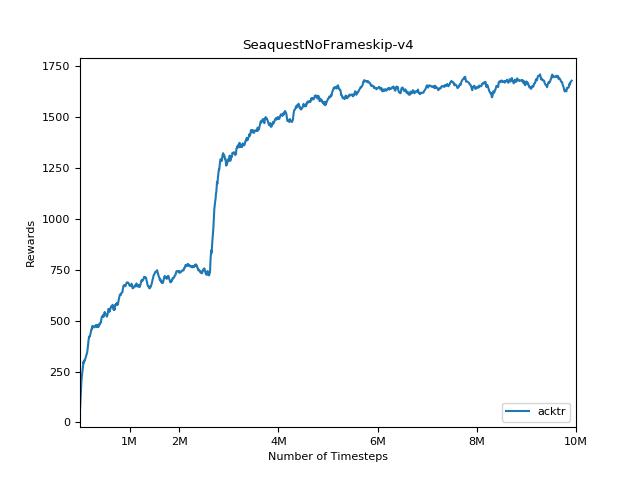
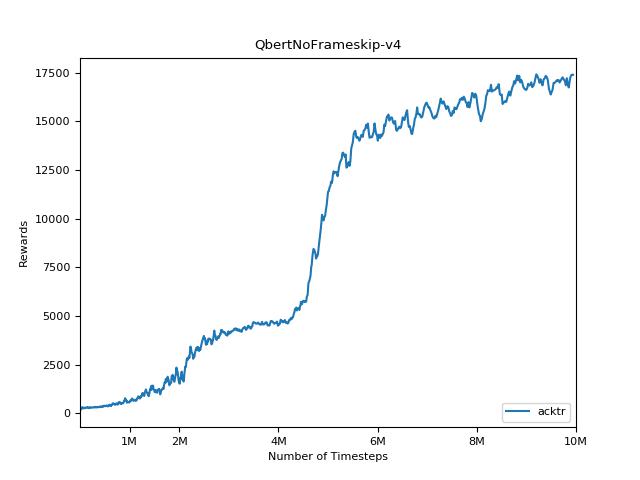
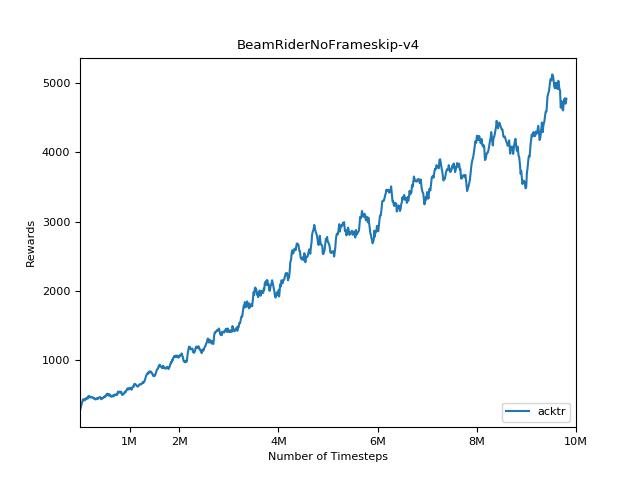
为了可视化结果,请使用visualize.ipynb 。
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20请始终尝试使用--use-proper-time-limits标志。它正确处理部分轨迹(请参阅https://github.com/sfujim/td3/blob/master/mains.py.py#l123)。
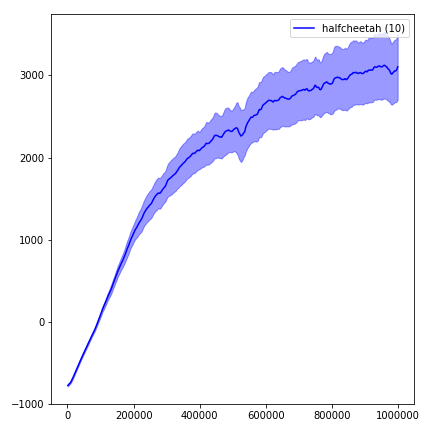
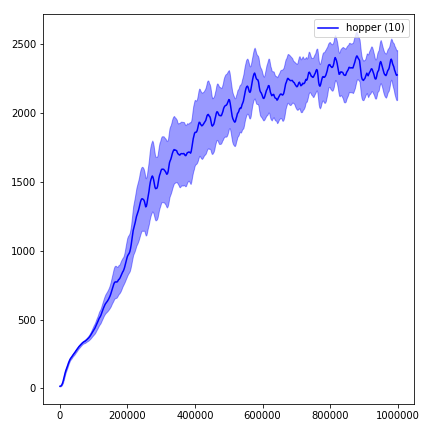
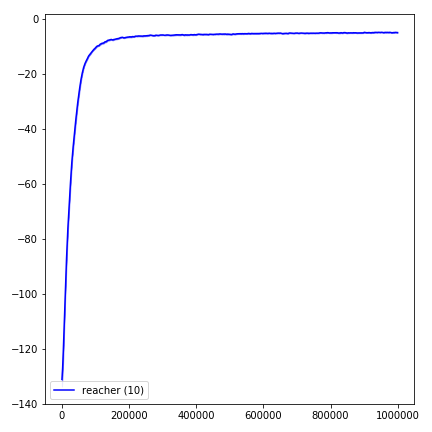
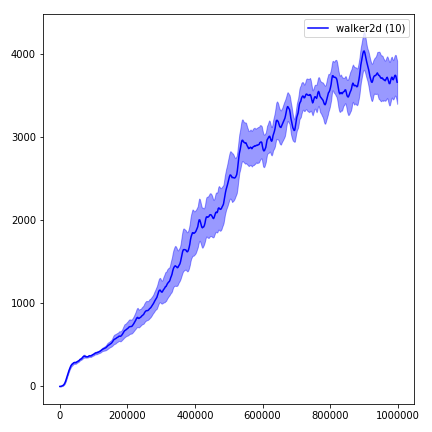
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR需要专门为Mujoco进行一些修改。但是目前,我想保持此代码尽可能统一。因此,我将采用更好的方法将其集成到代码库中。
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "