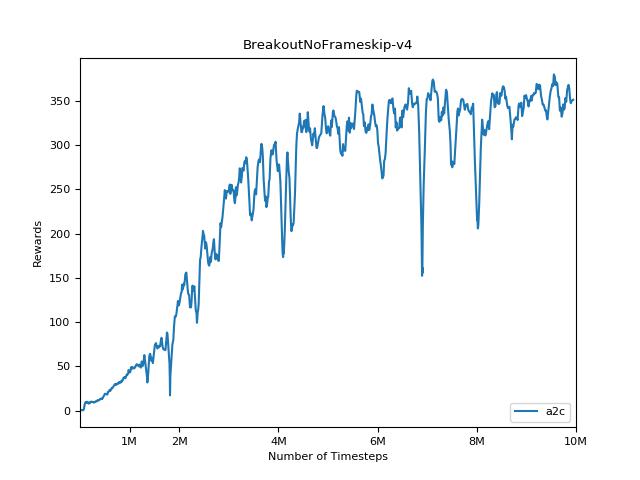
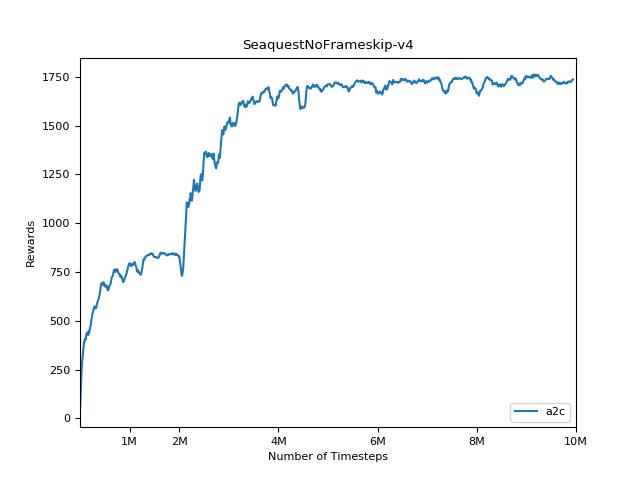
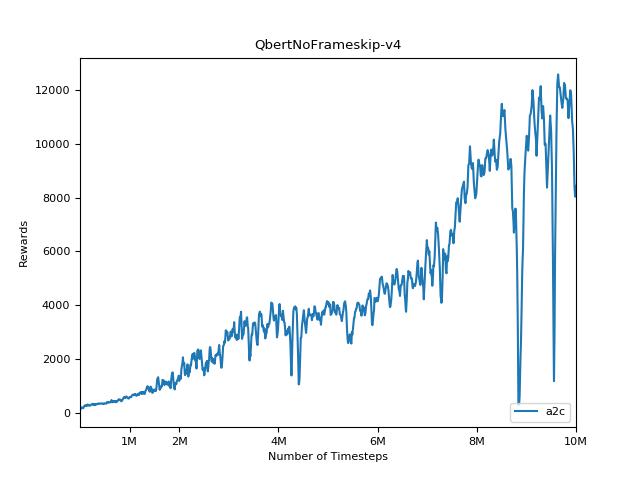
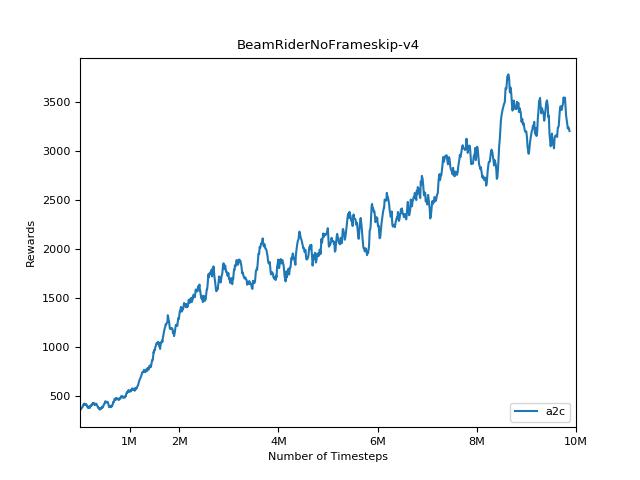
pytorch a2c ppo acktr gail
1.0.0
O PPO é ótimo, mas o crítico de atores suave pode ser melhor para muitas tarefas de controle contínuo. Confira meu novo repositório RL em Jax.
Esta é uma implementação de Pytorch de
Consulte também as postagens do OpenAI: A2C/ACKTR e PPO para obter mais informações.
Esta implementação é inspirada nas linhas de base do Openai para A2C, ACKTR e PPO. Ele usa os mesmos parâmetros hiper e o modelo, pois eles estavam bem sintonizados para os jogos Atari.
Por favor, use este Bibtex se você deseja citar este repositório em suas publicações:
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
Eu recomendo o Pybullet como uma alternativa gratuita de código aberto ao Mujoco para tarefas de controle contínuo.
Todos os ambientes são operados usando exatamente a mesma interface de ginástica. Veja suas documentações para uma lista abrangente.
Para usar os ambientes hopper stand Control Suite, defina task_name sinalizador --env domain_name --env-name dm.<domain_name>.<task_name> Consulte o repositório e o relatório técnico para obter uma lista completa de domínios e tarefas disponíveis. Além de definir a tarefa, a API para interagir com o ambiente é exatamente a mesma que para todos os ambientes de academia graças ao DM_Control2GYM.
Para instalar os requisitos, siga:
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atariAs contribuições são muito bem -vindas. Se você souber melhorar esse código, abra um problema. Se você deseja enviar uma solicitação de tração, abra um problema primeiro. Veja também uma lista de TODO abaixo.
Também estou procurando voluntários para executar todas as experiências em Atari e Mujoco (com várias sementes aleatórias).
É extremamente difícil reproduzir resultados para métodos de aprendizado de reforço. Consulte "Aprendizagem de reforço profundo que importa" para obter mais informações. Tentei reproduzir os resultados do OpenAI o mais próximo possível. No entanto, as diferenças de desempenho no desempenho podem ser causadas mesmo por pequenas diferenças nas bibliotecas Tensorflow e Pytorch.
Para visualizar os resultados, use visualize.ipynb .
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 Por favor, tente sempre usar o sinalizador --use-proper-time-limits . Ele lida adequadamente trajetórias parciais (consulte https://github.com/sfujim/td3/blob/master/main.py#l123).
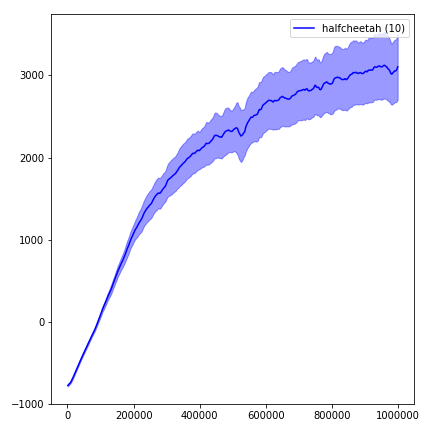
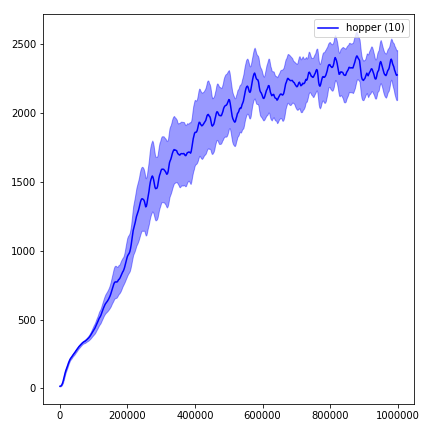
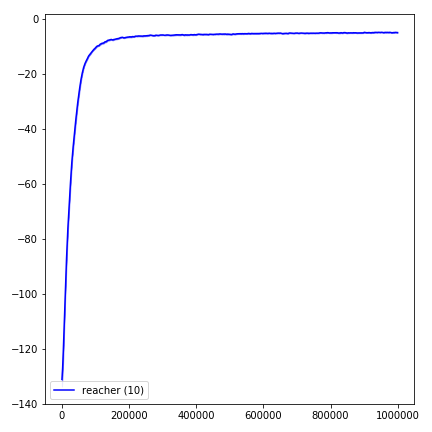
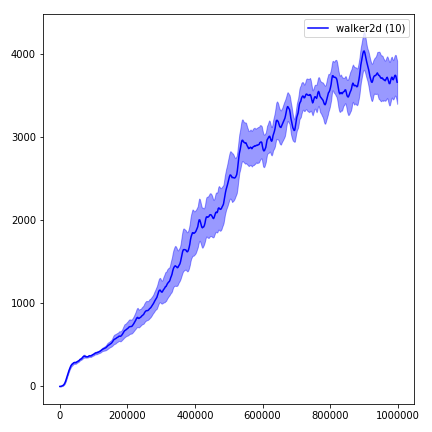
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsO ACKTR exige que algumas modificações sejam feitas especificamente para Mujoco. Mas, no momento, quero manter esse código o mais unificado possível. Assim, vou para obter melhores maneiras de integrá -lo à base de código.
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "