pytorch a2c ppo acktr gail
1.0.0
PPO는 훌륭하지만 부드러운 배우 비평가는 많은 지속적인 제어 작업에서 더 나을 수 있습니다. JAX의 새로운 RL 저장소를 확인하십시오.
이것은 Pytorch 구현입니다
자세한 내용은 OpenAI 게시물 : A2C/ACKTR 및 PPO를 참조하십시오.
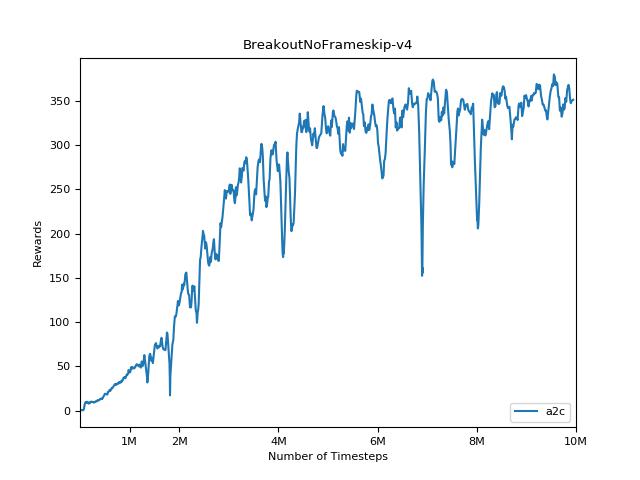
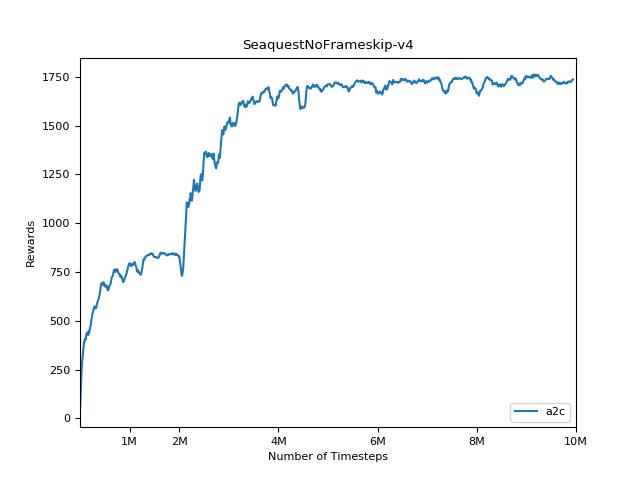
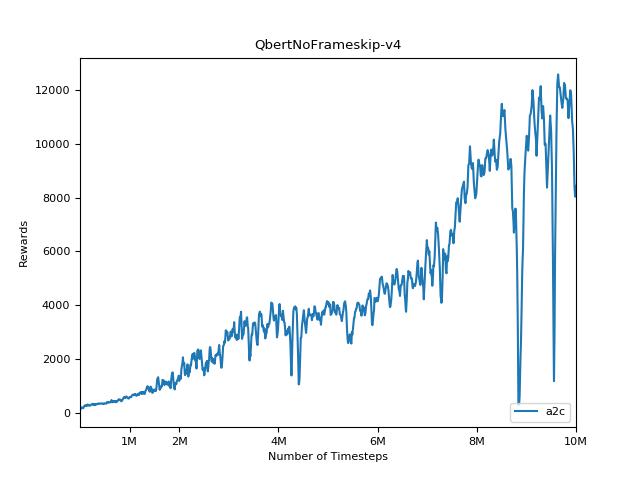
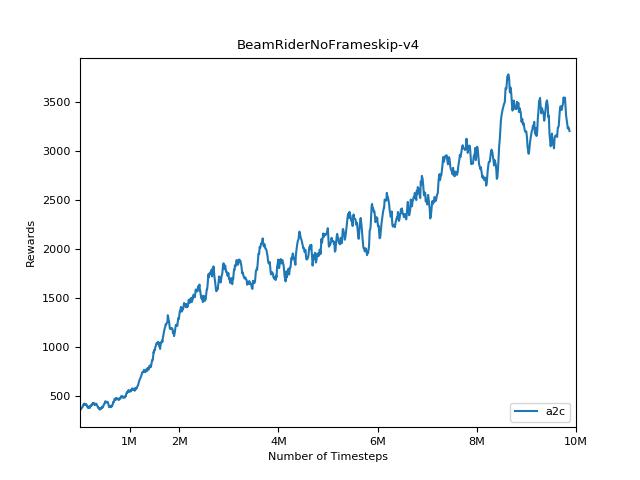
이 구현은 A2C, ACKTR 및 PPO의 OpenAI 기준에서 영감을 얻었습니다. Atari 게임을 잘 조정되었으므로 동일한 하이퍼 매개 변수와 모델을 사용합니다.
출판물 에서이 저장소를 인용하려면이 Bibtex를 사용하십시오.
@misc{pytorchrl,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Reinforcement Learning Algorithms},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail}},
}
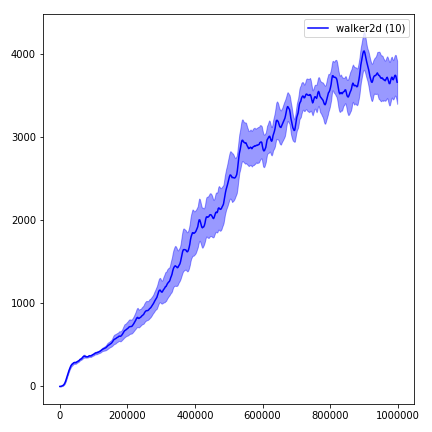
지속적인 제어 작업을위한 Mujoco의 무료 오픈 소스 대안으로 Pybullet을 강력히 추천합니다.
모든 환경은 정확히 동일한 체육관 인터페이스를 사용하여 작동합니다. 포괄적 인 목록은 문서를 참조하십시오.
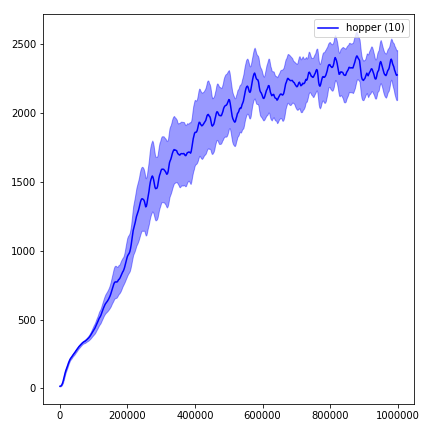
hopper Control Suite Environments stand 사용하려면 플래그 -env domain_name task_name --env-name dm.<domain_name>.<task_name> 사용 가능한 도메인 및 작업의 전체 목록은 Repo 및 Tech Report를 참조하십시오. 작업을 설정하는 것 외에도 환경과 상호 작용하기위한 API는 DM_Control2Gym 덕분에 모든 체육관 환경과 정확히 동일합니다.
요구 사항을 설치하려면 다음을 수행하십시오.
# PyTorch
conda install pytorch torchvision -c soumith
# Other requirements
pip install -r requirements.txt
# Gym Atari
conda install -c conda-forge gym-atari기부금은 매우 환영합니다. 이 코드를 더 좋게 만드는 방법을 알고 있다면 문제를여십시오. 풀 요청을 제출하려면 먼저 문제를여십시오. 또한 아래의 TODO 목록을 참조하십시오.
또한 Atari와 Mujoco (여러 개의 임의의 씨앗)에서 모든 실험을 실행하기위한 자원 봉사자를 찾고 있습니다.
강화 학습 방법에 대한 결과를 재현하는 것은 매우 어렵습니다. 자세한 내용은 "중요한 강화 학습"을 참조하십시오. 나는 가능한 한 열린 결과를 가깝게 재현하려고 노력했다. 그러나 전공 성능 차이는 텐서 플로 및 Pytorch 라이브러리의 사소한 차이로 인해 발생할 수 있습니다.
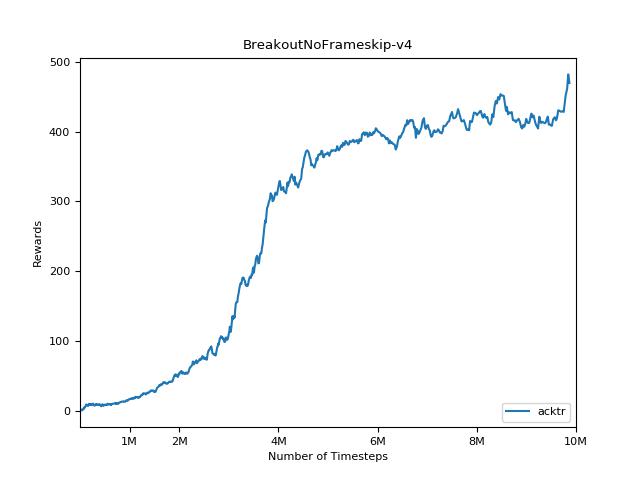
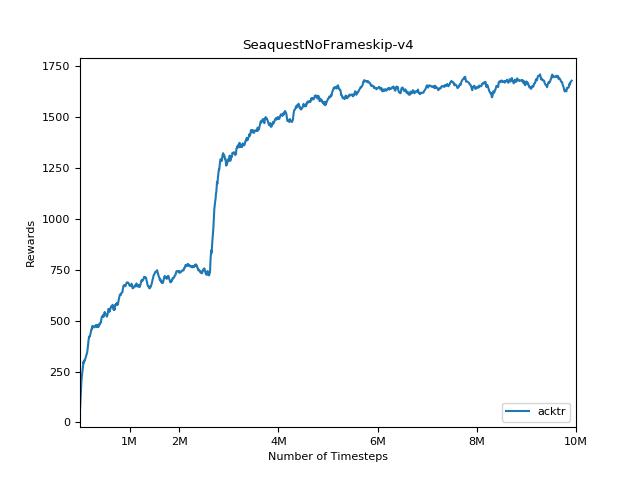
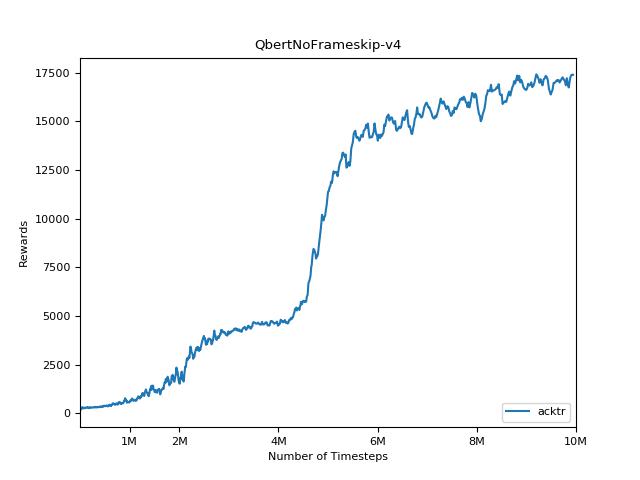
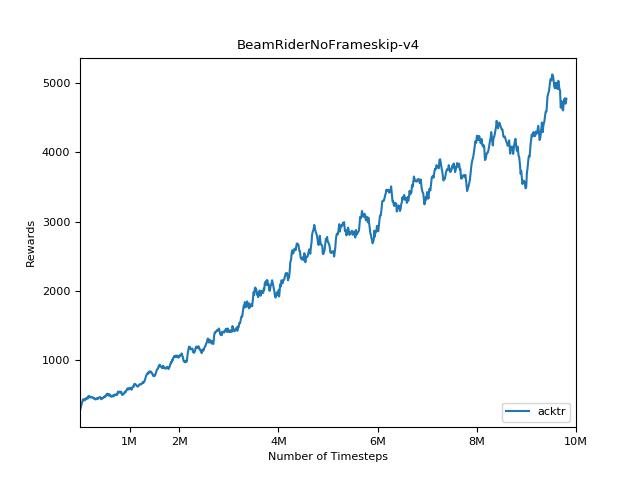
결과를 시각화하려면 visualize.ipynb 사용하십시오.
python main.py --env-name " PongNoFrameskip-v4 " python main.py --env-name " PongNoFrameskip-v4 " --algo ppo --use-gae --lr 2.5e-4 --clip-param 0.1 --value-loss-coef 0.5 --num-processes 8 --num-steps 128 --num-mini-batch 4 --log-interval 1 --use-linear-lr-decay --entropy-coef 0.01python main.py --env-name " PongNoFrameskip-v4 " --algo acktr --num-processes 32 --num-steps 20 항상 사용해보십시오 --use-proper-time-limits 플래그. 부분 궤적을 올바르게 처리합니다 (https://github.com/sfujim/td3/blob/master/main.py#123 참조).
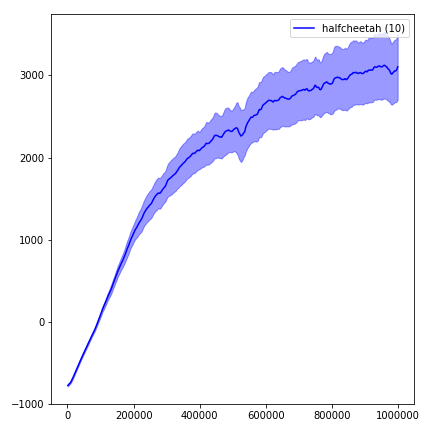
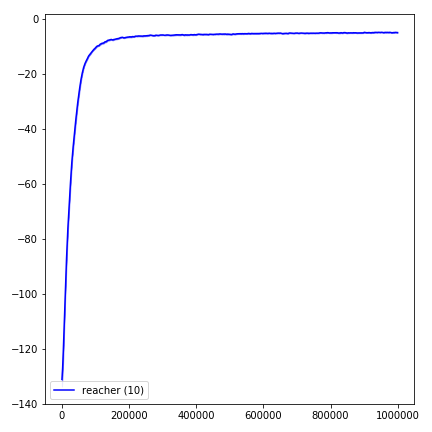
python main.py --env-name " Reacher-v2 " --num-env-steps 1000000python main.py --env-name " Reacher-v2 " --algo ppo --use-gae --log-interval 1 --num-steps 2048 --num-processes 1 --lr 3e-4 --entropy-coef 0 --value-loss-coef 0.5 --ppo-epoch 10 --num-mini-batch 32 --gamma 0.99 --gae-lambda 0.95 --num-env-steps 1000000 --use-linear-lr-decay --use-proper-time-limitsACKTR은 Mujoco를 위해 특별히 수정해야합니다. 그러나 현재이 코드를 가능한 한 통합하고 싶습니다. 따라서 코드베이스에 통합하는 더 나은 방법을 원합니다.
python enjoy.py --load-dir trained_models/a2c --env-name " PongNoFrameskip-v4 "python enjoy.py --load-dir trained_models/ppo --env-name " Reacher-v2 "