a PyTorch Tutorial to Image Captioning
1.0.0
這是圖像字幕的Pytorch教程。
這是我正在寫的一系列教程中的第一個,內容涉及出色的Pytorch圖書館獨自實施酷模型。
假定Pytorch,卷積和經常性神經網絡的基礎知識。
如果您是Pytorch的新手,請首先使用Pytorch閱讀深度學習:60分鐘的閃電戰和學習示例的Pytorch。
問題,建議或更正可以作為問題發布。
我在Python 3.6中使用PyTorch 0.4 。
2020年1月27日:添加了兩個新教程的工作代碼 - 超分辨率和機器翻譯
客觀的
概念
概述
執行
訓練
推理
常見問題
為了構建可以為圖像生成描述性標題的模型,我們提供了圖像。
為了使事情保持簡單,讓我們實施演出,參加並告訴論文。這絕不是當前的最新最新,但仍然非常驚人。作者的原始實現可以在此處找到。
該模型學會了看哪裡。
當您生成字幕,單詞時,您會看到模型的目光在整個圖像上轉移。
這是可能的,因為它的注意機制使其可以專注於與接下來要說的一詞最相關的圖像的一部分。
以下是在訓練或驗證期間看不到的測試圖像上生成的一些字幕:




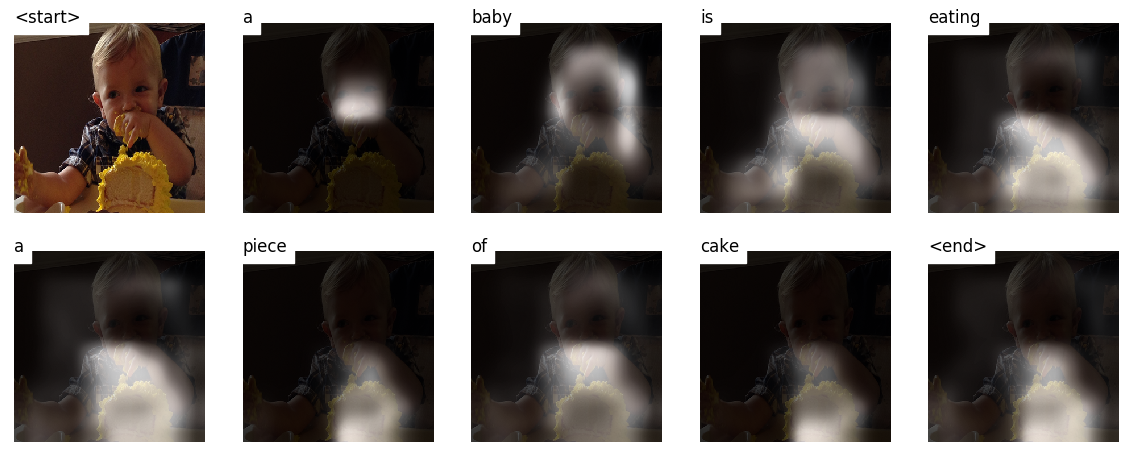

教程結束時還有更多示例。
圖像字幕。 du。
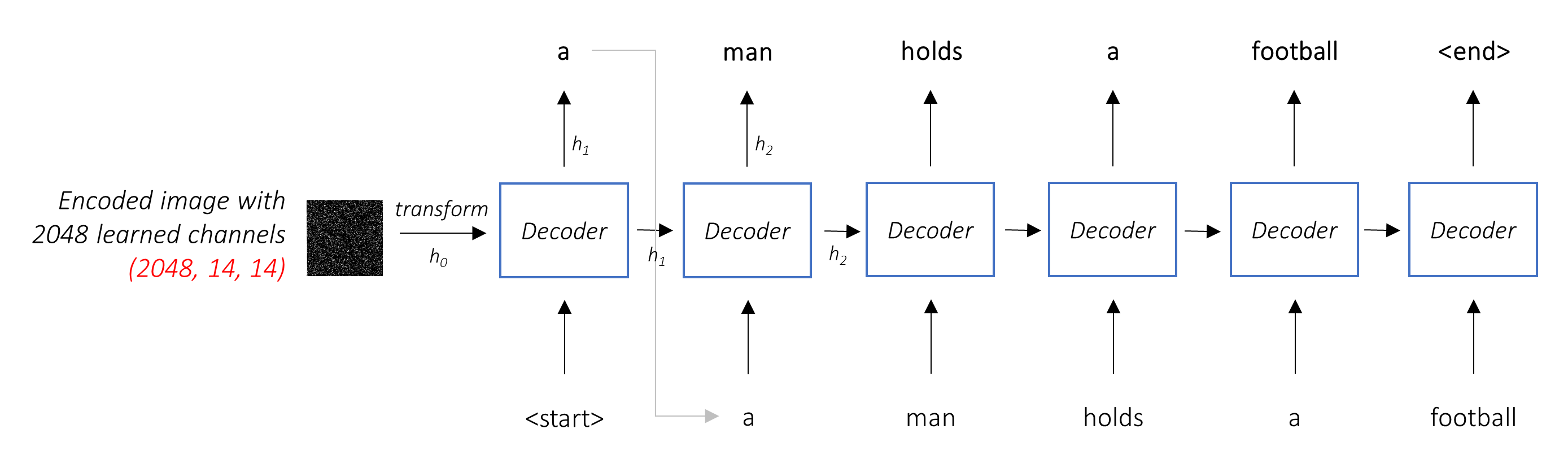
編碼器架構。通常,生成序列的模型將使用編碼器將輸入編碼為固定的形式和解碼器,將其通過單詞將其解碼為序列。
注意力。注意網絡的使用在深度學習中廣泛存在,並且有充分的理由。這是模型僅選擇其認為與手頭任務相關的編碼部分的一種方式。您在此處看到的相同機制可以在任何模型中使用編碼器的輸出具有多個空間或時間點。在圖像字幕中,您認為有些像素比其他像素更重要。按照機器翻譯等序列任務的順序,您認為一些單詞比其他單詞更重要。
轉移學習。這是您通過在新模型中使用其部分從現有模型借用的時候。這幾乎總是比從頭開始訓練新模型更好(即一無所知)。如您所見,您始終可以將這些二手知識調整為手頭的特定任務。使用驗證的單詞嵌入是一個愚蠢但有效的例子。對於我們的圖像字幕問題,我們將使用驗證的編碼器,然後根據需要對其進行微調。
梁搜索。在這裡,您不讓解碼器懶惰,只需在每個解碼步驟中選擇最佳分數的單詞即可。光束搜索對於任何語言建模問題都是有用的,因為它找到了最佳的序列。
在本節中,我將介紹此模型。如果您已經熟悉它,則可以直接跳到實施部分或註釋代碼。
編碼器將帶有3個顏色通道的輸入圖像編碼為帶有“學習”通道的較小圖像。
這個較小的編碼圖像是原始圖像中所有有用的所有內容的摘要表示。
由於我們想編碼圖像,因此我們使用卷積神經網絡(CNN)。
我們不需要從頭開始訓練編碼器。為什麼?因為已經有CNN訓練來表示圖像。
多年來,人們一直在建立非常擅長將圖像分為一千個類別之一的模型。可以很好地理解這些模型很好地捕獲了圖像的本質。
我選擇使用在Pytorch中已經可用的ImageNet分類任務的101個分層殘差網絡。如前所述,這是轉移學習的一個例子。您可以選擇對其進行微調以提高性能。

這些模型逐漸創建了原始圖像的越來越小的表示形式,並且每個後續表示形式更加“學到”,並具有更多的渠道。我們的Resnet-101編碼器生產的最終編碼的大小為14x14,具有2048個通道,即2048, 14, 14尺寸張量。
我鼓勵您嘗試其他預訓練的架構。該論文使用VGGNET,也可以在ImageNet上預處理,但沒有進行微調。無論哪種方式,都需要修改。由於其中的最後一層或兩個模型是線性層以及用於分類的SoftMax激活,因此我們將其剝離。
解碼器的工作是查看編碼的圖像並通過單詞生成字幕。
由於它正在生成一個序列,因此需要是複發性神經網絡(RNN)。我們將使用LSTM。
在典型的環境中,無需注意,您可以簡單地平均所有像素上的編碼圖像。然後,您可以將其作為第一個隱藏狀態以或不用線性轉換為單位,並生成標題。每個預測的單詞用於生成下一個單詞。
在引起注意的環境中,我們希望解碼器能夠在序列的不同點上查看圖像的不同部分。例如,在a man holds a football中產生football一詞時,解碼器會注意到 - 您猜對了 - 足球!
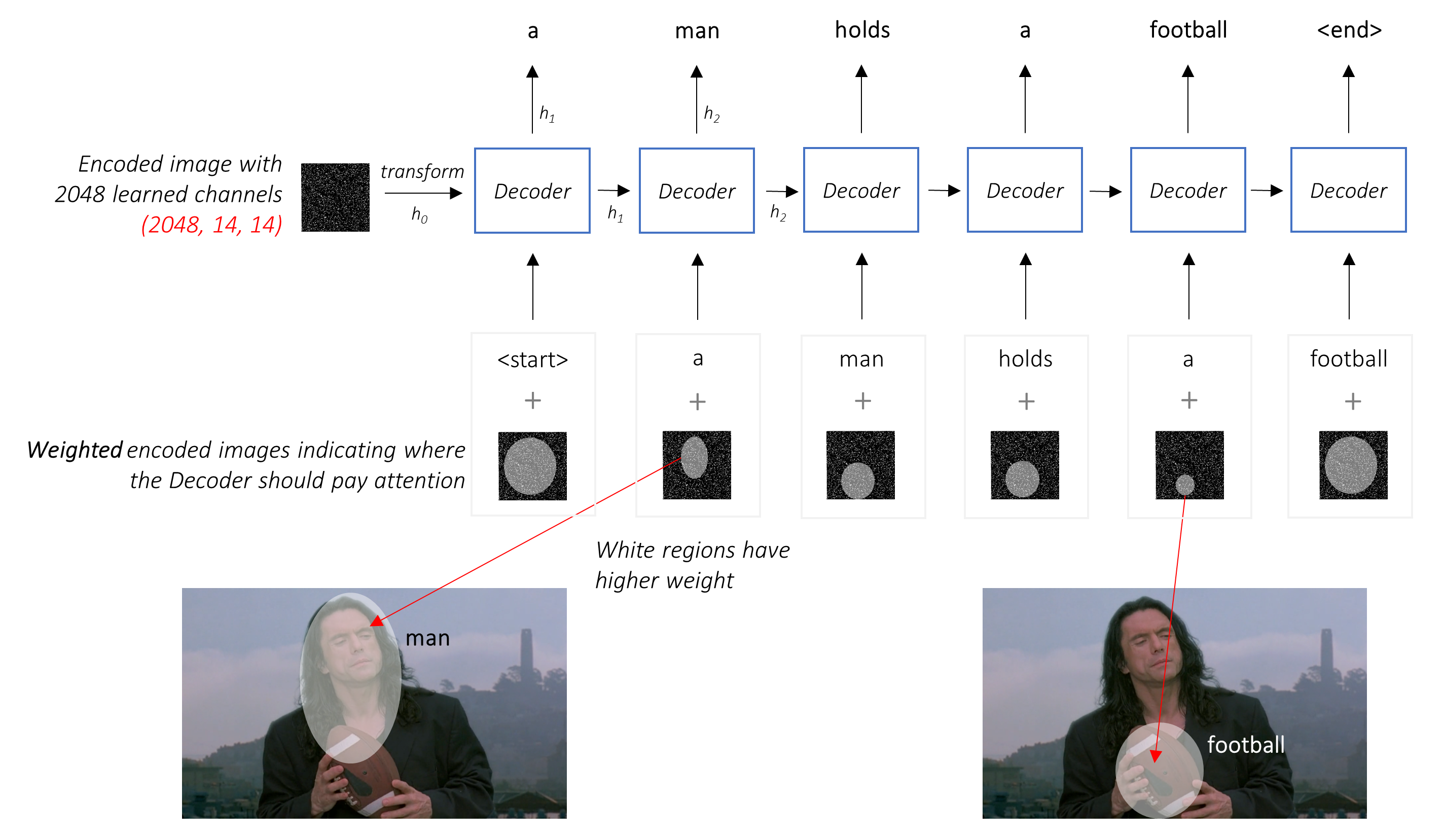
我們使用所有像素的加權平均值,而不是簡單的平均值,重要的像素的權重更大。圖像的加權表示可以與先前生成的單詞在每個步驟中串聯以生成下一個單詞。
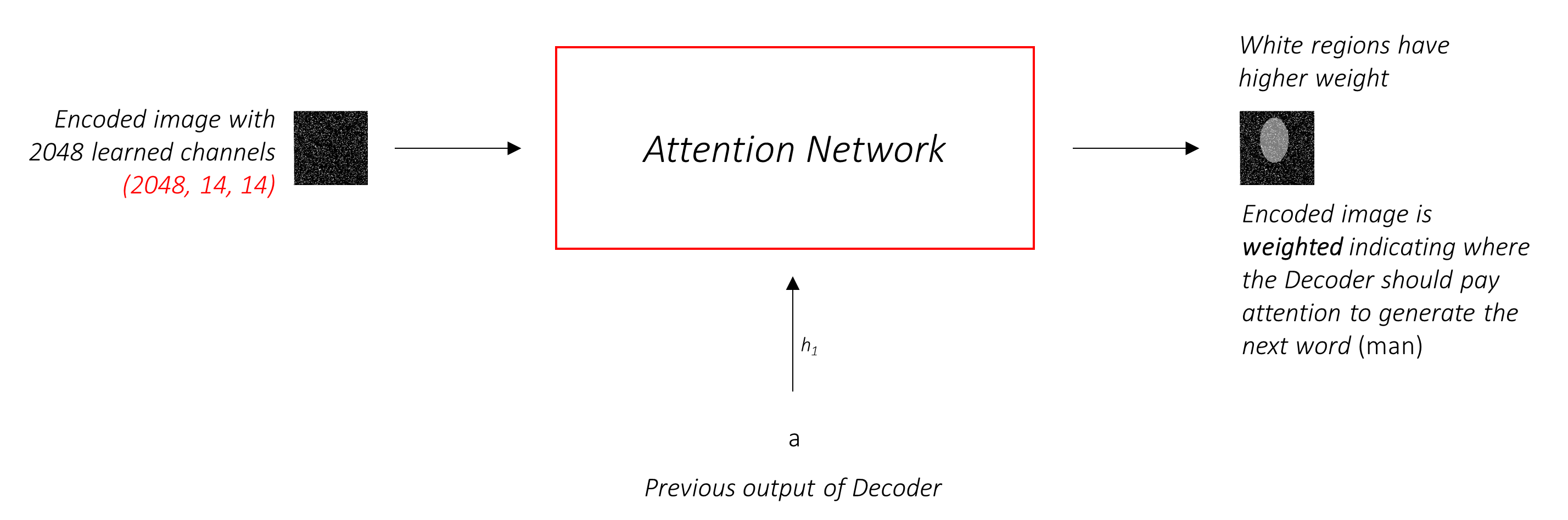
注意網絡計算這些權重。
直觀地,您如何估計圖像某個部分的重要性?您需要了解到目前為止生成的序列,因此您可以查看圖像並確定接下來描述的需求。例如,在提到a man之後,宣布他在holding a football是合乎邏輯的。
這正是注意機制所做的 - 它考慮到迄今為止生成的序列,並參與了下一描述的圖像部分。
我們將使用柔和的注意,其中像素P重量加起來t 1。
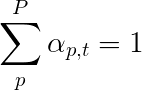
您可以將整個過程解釋為計算像素是要生成下一個單詞的地方的概率。
到目前為止,我們的組合網絡的外觀可能很清楚。
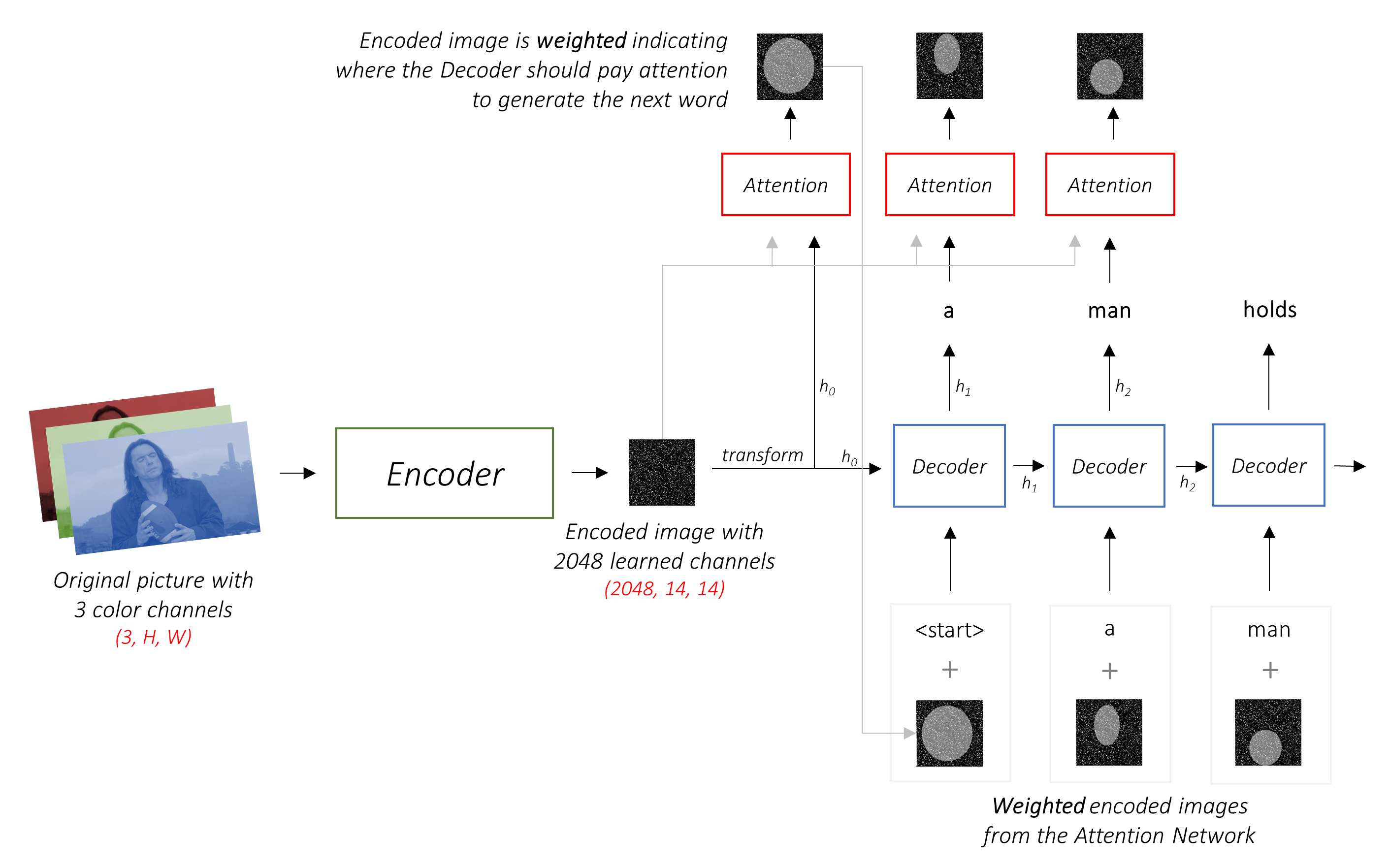
h (和單元格狀態C )。我們使用線性層將解碼器的輸出轉換為詞彙中每個單詞的分數。
直接和貪婪的選項是選擇具有最高分數的單詞,並使用它來預測下一個單詞。但這不是最佳的,因為序列的其餘部分取決於您選擇的第一個單詞。如果這種選擇不是最好的,那麼隨後的一切都是最佳的。這不僅是第一個單詞 - 順序中的每個單詞都會對成功的後果產生後果。
如果您在第一步中選擇了第三個最佳單詞,而在第二步中選擇了第二個最佳單詞,那麼……這將是您可以生成的最好的序列。
最好只有以某種方式不能以某種方式決定,直到我們完全解碼並選擇從一籃子候選序列中總分最高得分的序列。
光束搜索是這樣做的。
k候選人。k的第一個單詞生成k第二個單詞。k [第一個單詞,第二個單詞]組合考慮加法分數。k第二個單詞,請選擇k第三個單詞,選擇頂部k [第一個單詞,第二個單詞,第三個單詞]組合。k序列終止之後,選擇具有最佳總分的序列。 
如您所見,某些序列(擊中)可能會更早失敗,因為它們在下一步中沒有進入頂部k一旦k序列(帶下劃線)生成<end>令牌,我們就會選擇分數最高的一個。
以下各節簡要描述了實現。
它們的目的是提供一些背景,但是最好直接從代碼中理解細節,這是非常重大評論的。
我正在使用MSCOCO '14數據集。您需要下載培訓(13GB)和驗證(6GB)圖像。
我們將使用Andrej Karpathy的培訓,驗證和測試拆分。該郵政編碼包含字幕。您還將找到Flicker8K和Flicker30k數據集的拆分和字幕,因此,如果對於您的計算機來說太大,請隨時使用這些拆分和字幕而不是MSCOCO。
我們將需要三個輸入。
由於我們使用了驗證的編碼器,因此我們需要將圖像處理為習慣的驗證編碼器的形式。
預處理的成像網模型是Pytorch的torchvision模塊的一部分。此頁面詳細介紹了我們需要執行的預處理或轉換 - 像素值必須在[0,1]範圍內,然後我們必須通過Imagenet圖像的RGB通道的平均值和標準偏差來歸一化圖像。
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]另外,Pytorch遵循NCHW慣例,這意味著通道維度(C)必須先於大小尺寸。
我們將使所有Mscoco圖像的大小調整到256x256,以保持均勻性。
因此,饋送到模型的圖像必須是尺寸N, 3, 256, 256的Float張量,並且必須通過上述平均值和標準偏差進行標準化。 N是批處理大小。
字幕既是解碼器的目標又是輸入,因為每個單詞都用於生成下一個單詞。
但是,要生成第一個單詞,我們需要一個zeroth單詞<start> 。
在最後一句話中,我們應該預測<end>解碼器必須學會預測標題的結尾。這是必要的,因為我們需要知道何時在推理過程中停止解碼。
<start> a man holds a football <end>
由於我們將字幕傳遞為固定尺寸張量,因此我們需要用<pad>令牌將標題(自然的長度變化)添加到相同的長度。
<start> a man holds a football <end> <pad> <pad> <pad>....
此外,我們創建一個word_map ,它是語料庫中每個單詞的索引映射,包括<start> , <end>和<pad>令牌。與其他庫一樣,Pytorch需要編碼單詞作為索引來查找它們的嵌入或在預測的單詞分數中識別其位置。
9876 1 5 120 1 5406 9877 9878 9878 9878....
因此,饋送到模型的字幕必須是尺寸為N, L的Int張量,其中L是填充長度。
由於標題是填充的,因此我們需要跟踪每個字幕的長度。這是實際的長度 + 2(對於<start>和<end>令牌)。
字幕長度也很重要,因為您可以使用Pytorch構建動態圖。我們僅處理一個序列,直到其長度,並且不會浪費在<pad> s上的計算。
因此,饋送到模型的字幕長度必須是維數N的Int張量。
請參閱utils.py中的create_input_files() 。
這會讀取下載的數據並保存以下文件 -
I, 3, 256, 256張量中的每個拆分的圖像,其中I是拆分中的圖像數。像素值仍在[0,255]範圍內,並存儲為未簽名的8位Int s。N_c * I編碼字幕的列表,其中N_c是每個圖像採樣的字幕數。這些字幕與HDF5文件中的圖像的順序相同。因此, i字幕將對應於i // N_c th圖像。N_c * I字幕長度的列表。 i th值是i字幕的長度,與i // N_c th圖像相對應。word_map的JSON文件,單詞到索引字典。在保存這些文件之前,我們可以選擇僅使用比閾值短的字幕,而將頻率較低的單詞放入<unk>中。
我們將HDF5文件用於圖像,因為我們將在培訓 /驗證過程中直接從磁盤中讀取它們。它們太大了,無法一次適合RAM。但是我們確實將所有字幕及其長度加載到內存中。
請參閱datasets.py中的CaptionDataset 。
這是Pytorch Dataset集的子類。它需要定義的__len__方法,該方法返回數據集的大小,以及一個返回i th映像,標題和字幕長度的__getitem__方法。
我們讀取來自磁盤的圖像,將像素轉換為[0,255],並在此類中將其歸一化。
該Dataset將在train.py中的pytorch DataLoader器使用,以創建和將數據批量饋送到模型中以進行培訓或驗證。
請參閱models.py中的Encoder 。
我們使用Pytorch的torchvision模塊中已經可用的預處理的RESNET-101。丟棄最後兩層(池和線性層),因為我們只需要編碼圖像,而不是對其進行分類。
我們確實添加了一個AdaptiveAvgPool2d()層,以將編碼大小調整到固定尺寸。這使得可以將可變大小的圖像饋送到編碼器。 (但是,我們確實將輸入圖像大小調整到256, 256因為我們必須將它們作為單個張量存儲在一起。)
由於我們可能想微調編碼器,因此添加了一個fine_tune()方法,該方法可以啟用或禁用編碼器參數的梯度計算。我們僅在Resnet中微調卷積區塊2到4 ,因為第一個卷積塊通常會學到對圖像處理非常基本的東西,例如檢測線,邊緣,曲線等。我們不會對基礎感到煩惱。
請參閱models.py中的Attention 。
注意網絡很簡單 - 它僅由線性層和幾個激活組成。
單獨的線性層將編碼的圖像(扁平為N, 14 * 14, 2048 )和隱藏狀態(輸出)從解碼器到相同的尺寸,即。注意力大小。然後添加它們並激活。第三個線性層將此結果轉換為1的尺寸,因此我們應用SoftMax來生成權重alpha 。
參見models.py中的DecoderWithAttention 。
在此處接收編碼器的輸出,並扁平到N, 14 * 14, 2048 。這只是方便的,並且可以防止多次重塑張量。
我們使用init_hidden_state()方法使用編碼圖像初始化LSTM的隱藏和單元格狀態,該圖像使用了兩個單獨的線性層。
從一開始,我們通過減小字幕長度來對N圖像和字幕進行排序。這樣我們才能僅處理有效的時間段,即,而不是處理<pad> s。
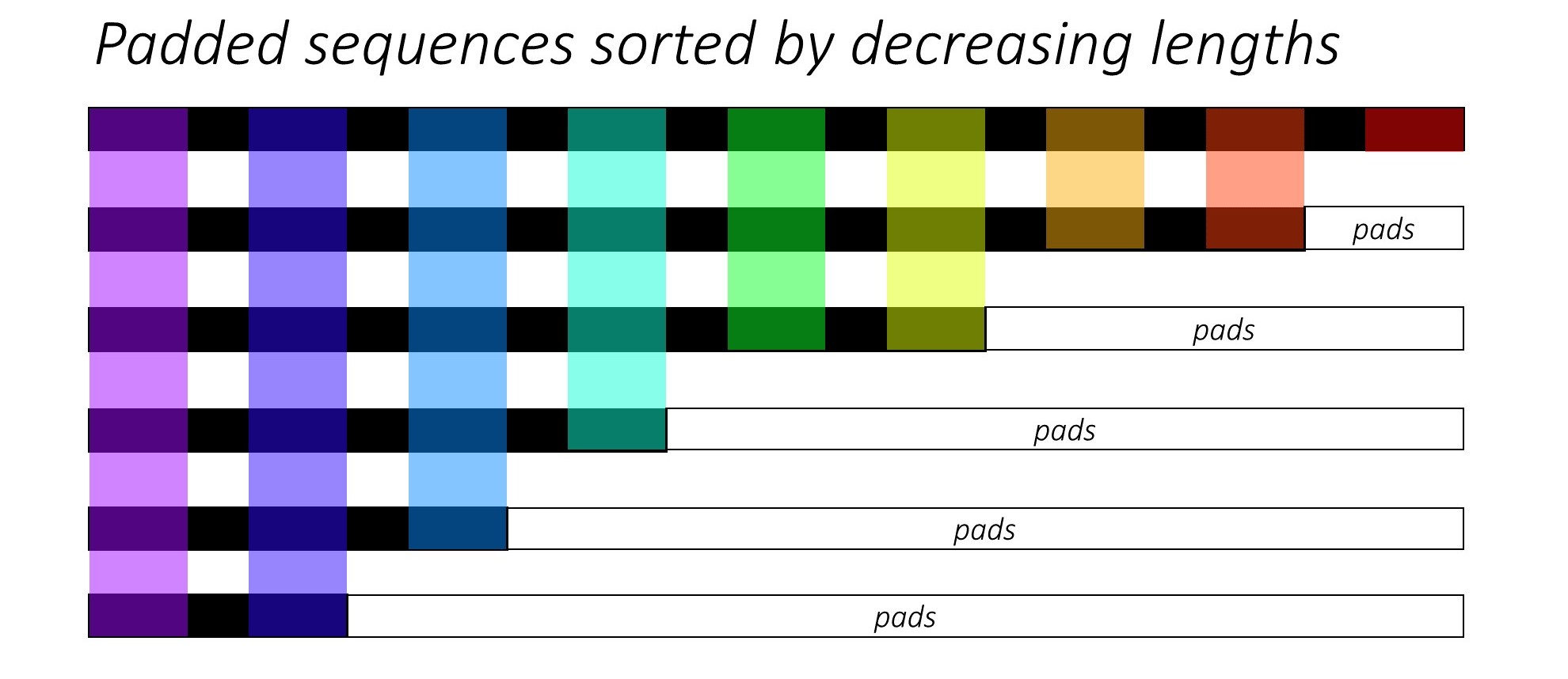
我們可以在每個時間段上迭代,只處理彩色區域,這是該時間步中有效的批量N_t 。排序允許在任何時間步上的頂部N_t與上一步的輸出對齊。例如,在第三個時間步中,我們僅使用上一步的前5個輸出來處理前5個圖像。
此迭代是用Pytorch LSTMCell手動進行的for而不是在沒有帶有Pytorch LSTM循環的情況下自動迭代。這是因為我們需要在每個解碼步驟之間執行注意機制。 LSTMCell是一個單個時間步操作,而LSTM會持續在多個時間步上迭代並立即提供所有輸出。
我們通過注意網絡計算每個時間步上的權重和注意力加權編碼。在論文的4.2.1節中,他們建議通過過濾器或門傳遞編碼的注意力加權。該門是解碼器先前隱藏狀態的Sigmoid激活線性變換。作者指出,這有助於注意力網絡更加強調圖像中的對象。
我們將這種過濾的注意力加權編碼與上一個單詞的嵌入( <start>開始)相連,然後運行LSTMCell以生成新的隱藏狀態(或輸出) 。線性層將這個新的隱藏狀態轉換為詞彙中每個單詞的得分,該單詞存儲。
我們還將注意力網絡返回的權重在每個時間步段返回。您會明白為什麼很快。
在開始之前,請確保保存所需的數據文件進行培訓,驗證和測試。為此,將其指向到karpathy文件和包含提取的train2014和val2014文件夾的圖像文件夾後,運行create_input_files.py的內容。
參見train.py 。
模型的參數(和培訓)在文件的開頭,因此您可以在願意的情況下輕鬆檢查或修改它們。
要從頭開始訓練您的模型,只需運行此文件 -
python train.py
要在檢查點恢復培訓,請指向代碼開頭的checkpoint參數的相應文件。
請注意,我們在每個培訓時期結束時執行驗證。
由於我們正在生成一系列單詞,因此我們使用CrossEntropyLoss 。您只需要從解碼器中的最後一層提交原始分數,損耗函數將執行SoftMax和日誌操作。
本文的作者建議使用第二次損失 - “雙隨機正則化”。我們知道在給定時間步長的權重總和至1。但是我們也鼓勵單個像素p的重量在所有時間段T中總和為1 -
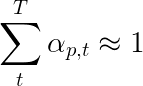
這意味著我們希望該模型在生成整個序列的過程中關注每個像素。因此,我們試圖最大程度地減少所有時間步中1與像素權重的總和之間的差異。
我們不計算填充區域上的損失。消除墊子的一種簡單方法是使用pytorch的pack_padded_sequence() ,它通過時間段來平移張量,同時忽略填充區域。現在,您可以匯總此扁平張量的損失。
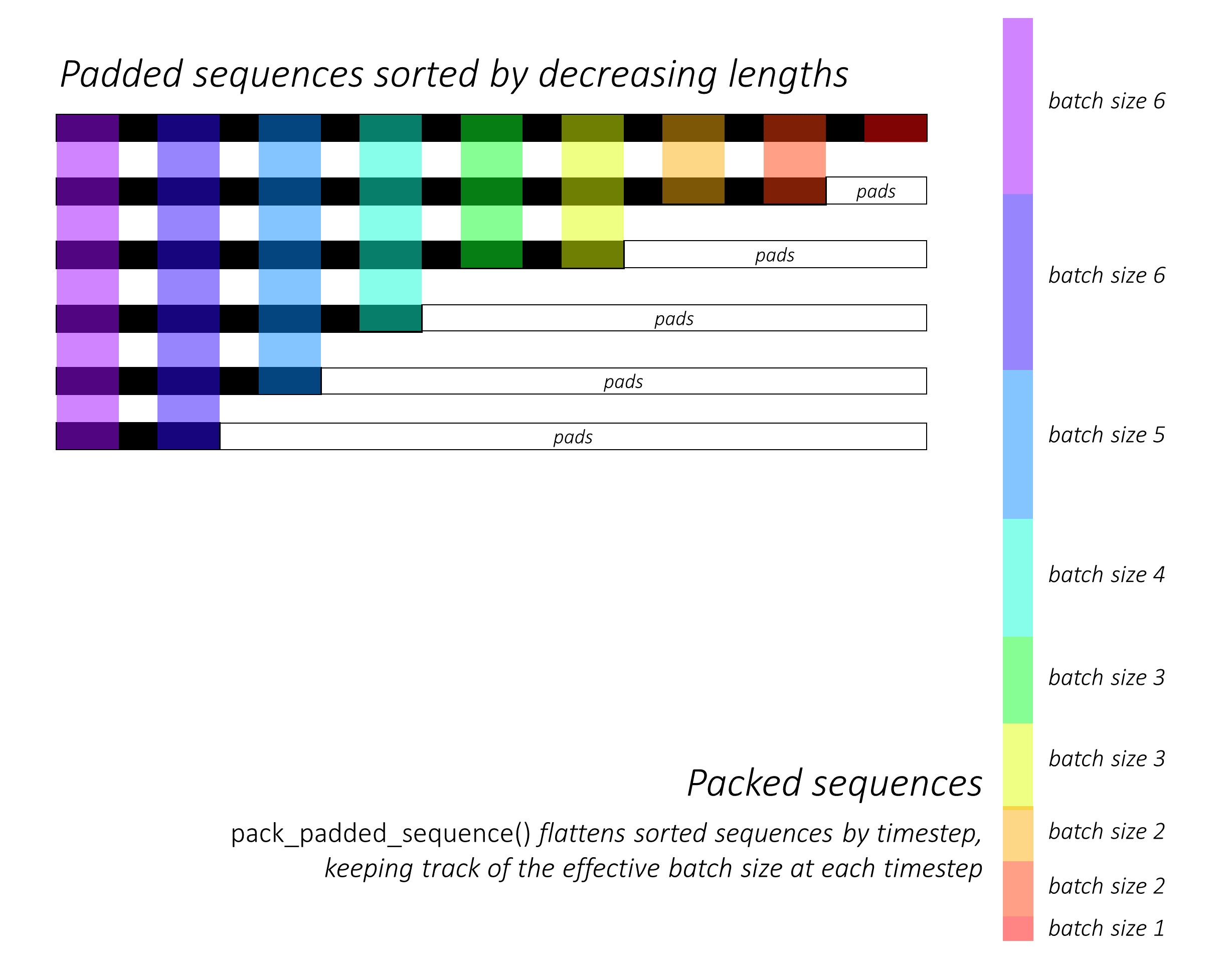
注意- 實際上,此功能用於執行相同的動態批處理(即,在每個時間步中僅處理有效的批處理大小),當時我們在解碼器中使用Pytorch中的RNN或LSTM時執行。在這種情況下,Pytorch內部處理動態變量長度圖。您可以在我的其他序列標籤教程中在dynamic_rnn.py中看到一個示例。如果由於注意力網絡而沒有手動迭代,我們將在LSTM中使用此功能。
為了評估模型在驗證集上的性能,我們將使用自動化的雙語評估研究(BLEU)評估度量指標。這評估了針對參考標題的生成字幕。對於每個生成的字幕,我們將使用該圖像可用的所有N_c字幕作為參考字幕。
演出的作者參加並告訴Paper觀察到,損失與BLEU分數之間的相關性在點之後分解,因此他們建議在BLEU分數何時開始降級,即使損失繼續下降,也建議停止訓練。
我使用了NLTK模塊中可用的BLEU工具。
請注意,對BLEU分數有相當大的批評,因為它並不總是與人類判斷良好相關。作者還報告了流星得分,因此我尚未實施此指標。
我建議您分階段訓練。
我首先僅培訓了解碼器,即沒有微調編碼器,批量大小為80 。我訓練了20個時代,而BLEU-4的得分在第13個時代達到了約23.25 。我使用的是Adam()優化器的初始學習率為4e-4 。
我從第13個時期檢查點繼續進行,允許對編碼器進行微調,批量大小為32 。較小的批量大小是因為該模型現在更大,因為它包含編碼器的梯度。通過微調,得分僅在大約3個時代上升到24.29 。繼續訓練可能會使分數略高,但我不得不在其他地方提出GPU。
在這裡做出的一個重要區別是,無論最後生成的單詞如何,我仍在驗證過程中每個解碼步驟中的輸入作為輸入。這稱為老師強迫。儘管這在培訓期間通常用於加速過程,但就像我們正在訓練一樣,驗證期間的條件必須盡可能地模仿實際的推理條件。我尚未實現批處理推斷 - 標題中的每個單詞都是從先前生成的單詞生成的,並在擊中<end>令牌時終止。
由於我在驗證期間對教師進行了努力,因此上面在結果字幕上測得的BLEU得分並不能反映實際的性能。實際上,BLEU評分是一個旨在將自然產生的字幕與不同長度不同的基本字幕進行比較的度量。一旦實施了批處理推斷,即沒有老師強迫,與BLEU分數的早期停滯將是真正的“適當”。
考慮到這一點,我使用eval.py來計算驗證和測試集的此模型檢查點的正確BLEU-4分數,而無需老師強迫,在不同的光束尺寸 -
| 梁尺寸 | 驗證bleu-4 | 測試BLEU-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
測試分數高於論文的結果,可能是因為我們的BLEU計算器的參數化,我使用了Resnet Encoder的事實,並且實際上對編碼器進行了微調 - 即使只是一點。
另外,請記住 - 在轉移學習過程中進行微調時,使用學習率比最初用於訓練借用模型的學習率要比最初要小得多。這是因為該模型已經非常優化,我們不想太快更改任何內容。我也將Adam()用於編碼器,但是學習率為1e-4 ,這是該優化器的默認值的十分之一。
在泰坦X(Pascal)上,每個時期花費了55分鐘,而無需微調,而在規定的批處理大小上進行了2.5小時。
您可以在此處下載此驗證的模型和相應的word_map 。
請注意,該檢查點應直接與Pytorch一起加載,或將其傳遞到caption.py - 請參見下文。
請參閱caption.py 。
在推論期間,我們無法在解碼器中直接使用forward()方法,因為它使用了教師強迫。相反,我們實際上需要在每個時間步中將先前生成的單詞饋送到LSTM 。
caption_image_beam_search()讀取圖像,對其進行編碼,並按照正確的順序應用解碼器中的層,同時使用先前生成的單詞作為每個時間段的LSTM的輸入。它還結合了光束搜索。
如示例所示,可視visualize_att()生成的字幕以及每個時間步中的權重來可視化生成的字幕。
要在命令行中標記圖像,指向圖像,模型檢查點,單詞映射(以及可選的,光束大小)如下 -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
或者,根據需要使用文件中的功能。
另請參見eval.py ,該過程實現此過程,用於計算驗證集上的BLEU分數,無論是否沒有光束搜索。





Turing Tommy測試- 您知道AI並不是真正的AI,因為它沒有看過房間,並且在看到它時也不認識到偉大。

你說的是輕鬆的關注。嗯,有一個艱難的關注嗎?
是的,節目,參加和告訴紙張使用兩種變體,而“硬”注意的解碼器的表現略有差異。
在我們在這裡使用的柔和注意力中,您正在計算權重alpha ,並使用所有像素上功能的加權平均值。這是一個確定性的,可區分的操作。
在急需的關注下,您選擇僅從alpha定義的分佈中採樣一些像素。請注意,任何此類概率採樣都是非確定性或隨機的,即特定輸入不會始終產生相同的輸出。但是,由於梯度下降以確定性(因此可以差異化)為前提,因此對採樣進行了重新設計以消除其隨機性。在這一點上,我對此的了解相當膚淺 - 當我有更詳細的理解時,我將更新此答案。
如何將注意力網絡用於NLP任務,例如序列進行序列模型?
就像您使用CNN在每個像素處生成具有功能的編碼一樣,您將使用RNN在輸入中的每個時間步中生成編碼的功能。
沒有註意力,您將在最後一個時間步長將編碼器的輸出用作整個句子的編碼,因為它還包含了先前的時間步中的信息。現在,編碼器的最後一個輸出承擔了必須有意義地編碼整個句子的負擔,這並不容易,尤其是對於更長的句子。
注意,您將參加編碼器輸出中的時間段,為每個時間步/單詞產生權重,並以加權平均值表示句子。在諸如機器翻譯之類的序列任務的序列中,您將在輸出中生成每個單詞時在輸入中的相關單詞。
您也可以在沒有解碼器的情況下使用注意力。例如,如果您想對文本進行分類,則可以僅一次輸入中的重要單詞來執行分類。
我們可以在訓練期間使用梁搜索嗎?
不是當前的損失功能,而是。這根本不常見。
什麼是老師強迫?
老師的強迫是,當我們使用地面真相字幕作為每個時間步中解碼器的輸入時,而不是它在上一個時間步中生成的單詞。在培訓期間,教師力量很常見,因為這可能意味著模型的融合更快。但是,它也可以學會依靠被告知正確的答案,並在實踐中表現出一些不穩定。
根據概率,使用老師在某些時候訓練是理想的選擇。這稱為計劃採樣。
(我計劃添加選項)。
我可以使用預驗證的單詞嵌入(手套,cbow,skipgram等),而不是從頭開始學習它們嗎?
是的,您可以在Decoder類中使用load_pretrained_embeddings()方法。您也可以選擇使用fine_tune_embeddings()方法微調(或不)。
在train.py中創建解碼器後,您應該為load_pretrained_embeddings()以與word_map中相同的順序堆疊。對於您沒有預估計的向量的單詞,例如<start> ,您可以像在init_weights()中一樣隨機初始化嵌入式。我建議您進行微調,以了解這些隨機初始化的向量的更多有意義的向量。
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False另外,請確保將emb_dim參數從其當前值的512更改為預訓練的嵌入式的大小。這應該自動調整解碼器LSTM的輸入大小以適應它們。
如何跟踪哪些張量允許計算梯度?
隨著pytorch 0.4的釋放,不再需要包裝張量作為Variable S。取而代之的是,張量具有requires_grad屬性,該屬性決定是否由autograd跟踪,因此是否在反向傳播過程中為其計算梯度。
requires_grad設置為False 。requires_grad設置為True 。torch.nn層的參數,已經將需要requires_grad設置為True 。在評估過程中,如何計算所有BLEU(IE BLEU-1至BLEU-4)得分?
您需要修改eval.py中的代碼才能執行此操作。請參閱KMARIO23的這一出色答案,以進行清晰而詳細的解釋。


