a PyTorch Tutorial to Image Captioning
1.0.0
Este é um tutorial de Pytorch para a legenda da imagem .
Este é o primeiro de uma série de tutoriais que estou escrevendo sobre a implementação de modelos legais por conta própria com a incrível biblioteca Pytorch.
É assumido o conhecimento básico das redes neurais convolucionais e recorrentes.
Se você é novo no Pytorch, primeiro leia o Deep Learning com Pytorch: uma blitz de 60 minutos e aprendendo Pytorch com exemplos.
Perguntas, sugestões ou correções podem ser publicadas como questões.
Estou usando PyTorch 0.4 no Python 3.6 .
27 de janeiro de 2020 : Código de trabalho para dois novos tutoriais foi adicionado-Super-resolução e tradução para a máquina
Objetivo
Conceitos
Visão geral
Implementação
Treinamento
Inferência
Perguntas frequentes
Para construir um modelo que possa gerar uma legenda descritiva para uma imagem que o fornecemos.
No interesse de manter as coisas simples, vamos implementar o programa, assistir e contar a Paper. Isso não é de forma alguma o atual estado da arte, mas ainda é incrível. A implementação original dos autores pode ser encontrada aqui.
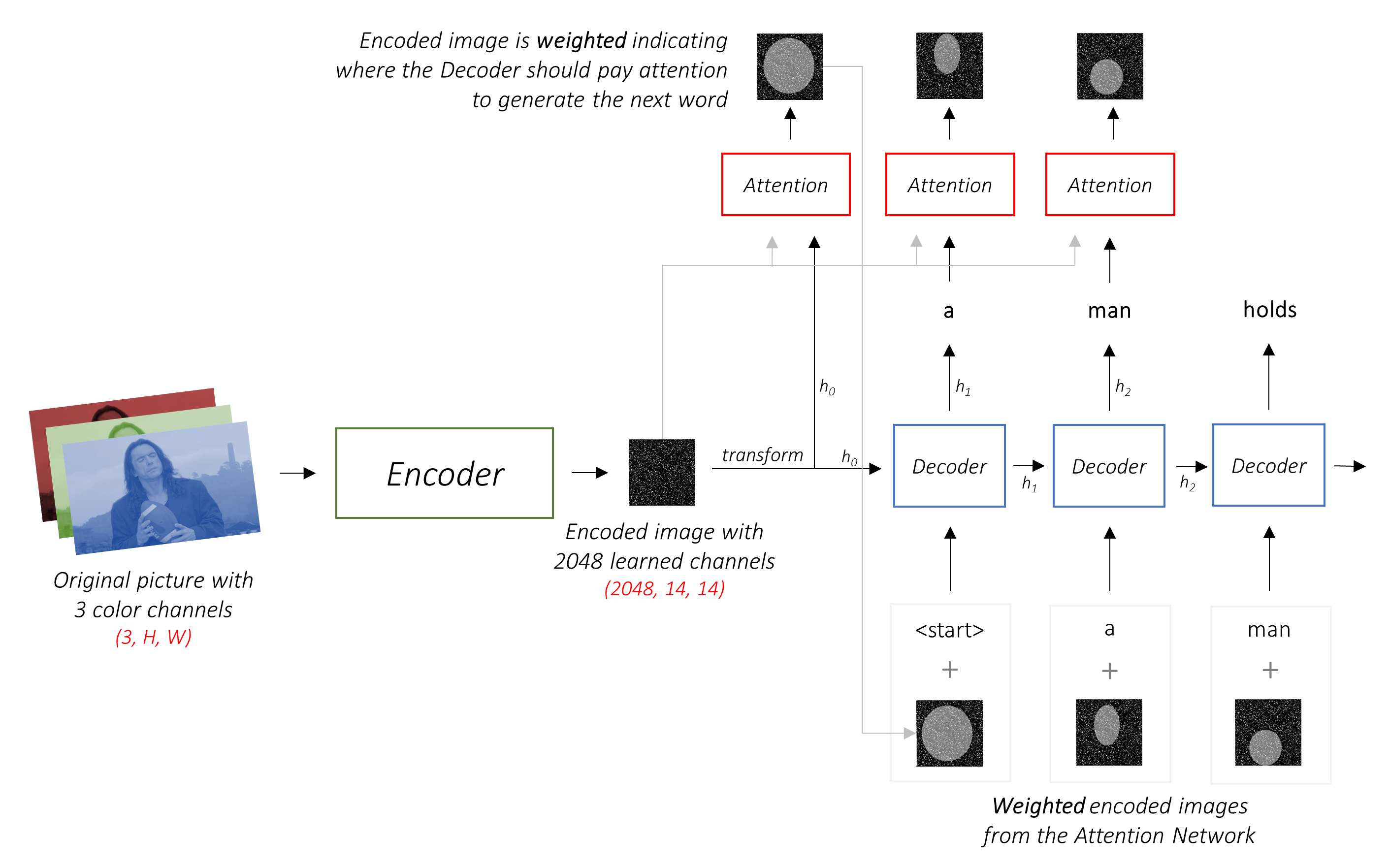
Este modelo aprende onde procurar.
Ao gerar uma legenda, palavra por palavra, você pode ver o olhar do modelo mudando pela imagem.
Isso é possível devido ao seu mecanismo de atenção , o que permite se concentrar na parte da imagem mais relevante para a palavra que será proferida a seguir.
Aqui estão algumas legendas geradas em imagens de teste não vistas durante o treinamento ou validação:




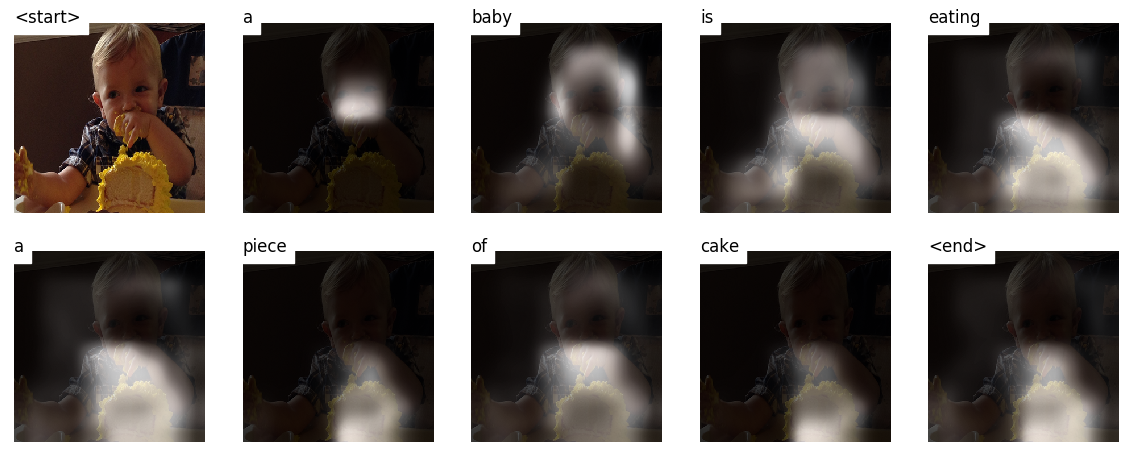

Existem mais exemplos no final do tutorial.
Legenda da imagem . duh.
Arquitetura do Encoder-Decoder . Normalmente, um modelo que gera seqüências usará um codificador para codificar a entrada em um formulário fixo e um decodificador para decodificá -lo, palavra por palavra, em uma sequência.
Atenção . O uso de redes de atenção é generalizado no aprendizado profundo e por boas razões. Essa é uma maneira de um modelo escolher apenas as partes da codificação que acha relevante para a tarefa em questão. O mesmo mecanismo que você vê empregado aqui pode ser usado em qualquer modelo em que a saída do codificador tenha vários pontos no espaço ou no tempo. Na legenda da imagem, você considera alguns pixels mais importantes que outros. Em sequência a tarefas de sequência como a tradução da máquina, você considera algumas palavras mais importantes que outras.
Transferência de aprendizado . É quando você empresta de um modelo existente usando partes dele em um novo modelo. Isso é quase sempre melhor do que treinar um novo modelo do zero (ou seja, não sabendo nada). Como você verá, você sempre pode ajustar esse conhecimento de segunda mão para a tarefa específica em questão. O uso de incorporação de palavras pré -ridadas é um exemplo idiota, mas válido. Para o nosso problema de legenda de imagem, usaremos um codificador pré-treinamento e, em seguida, ajustaremos-o conforme necessário.
Pesquisa de feixe . É aqui que você não deixa seu decodificador ser preguiçoso e simplesmente escolher as palavras com a melhor pontuação a cada passo decodificador. A pesquisa de feixe é útil para qualquer problema de modelagem de idiomas, pois encontra a sequência mais ideal.
Nesta seção, apresentarei uma visão geral deste modelo. Se você já está familiarizado com isso, pode pular direto para a seção de implementação ou o código comentado.
O codificador codifica a imagem de entrada com 3 canais de cores em uma imagem menor com canais "aprendidos" .
Esta imagem codificada menor é uma representação resumida de tudo o que é útil na imagem original.
Como queremos codificar imagens, usamos redes neurais convolucionais (CNNs).
Não precisamos treinar um codificador do zero. Por que? Porque já existem CNNs treinados para representar imagens.
Durante anos, as pessoas criam modelos extraordinariamente bons em classificar uma imagem em uma das mil categorias. É lógico que esses modelos capturam muito bem a essência de uma imagem.
Eu escolhi usar a rede residual de 101 camadas treinada na tarefa de classificação do ImageNet , já disponível em Pytorch. Como afirmado anteriormente, este é um exemplo de aprendizado de transferência. Você tem a opção de ajustá-lo para melhorar o desempenho.

Esses modelos criam progressivamente representações cada vez menores da imagem original, e cada representação subsequente é mais "aprendida", com um número maior de canais. A codificação final produzida pelo nosso codificador RESNET-101 possui um tamanho de 14x14 com 2048 canais, ou seja, um tensor de tamanho 2048, 14, 14 .
Convido você a experimentar outras arquiteturas pré-treinadas. O papel usa um VGGNET, também pré-terenciado no ImageNet, mas sem ajuste fino. De qualquer maneira, são necessárias modificações. Como a última camada ou duas desses modelos são camadas lineares, juntamente com a ativação do softmax para classificação, nós as retiramos.
O trabalho do decodificador é olhar para a imagem codificada e gerar uma palavra de legenda por palavra .
Como está gerando uma sequência, precisaria ser uma rede neural recorrente (RNN). Usaremos um LSTM.
Em uma configuração típica sem atenção, você pode simplesmente calcular a média da imagem codificada em todos os pixels. Você pode então alimentar isso, com ou sem uma transformação linear, no decodificador como seu primeiro estado oculto e gerar a legenda. Cada palavra prevista é usada para gerar a próxima palavra.
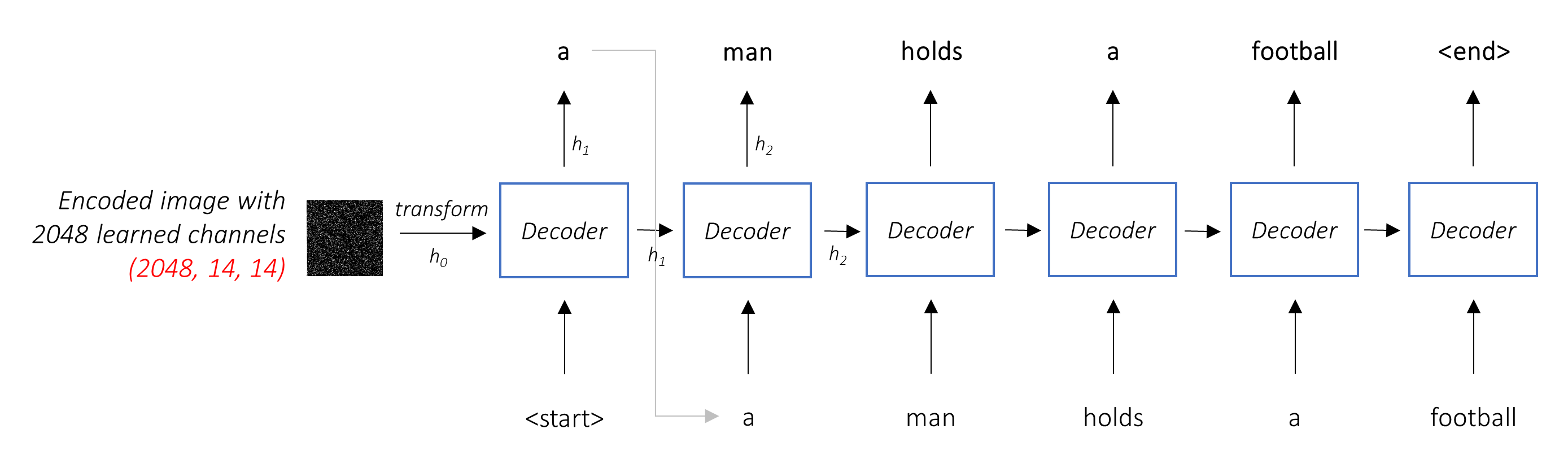
Em um cenário com atenção, queremos que o decodificador possa olhar para diferentes partes da imagem em diferentes pontos da sequência . Por exemplo, enquanto gera a palavra football em a man holds a football , o decodificador saberia se concentrar - você adivinhou - o futebol!
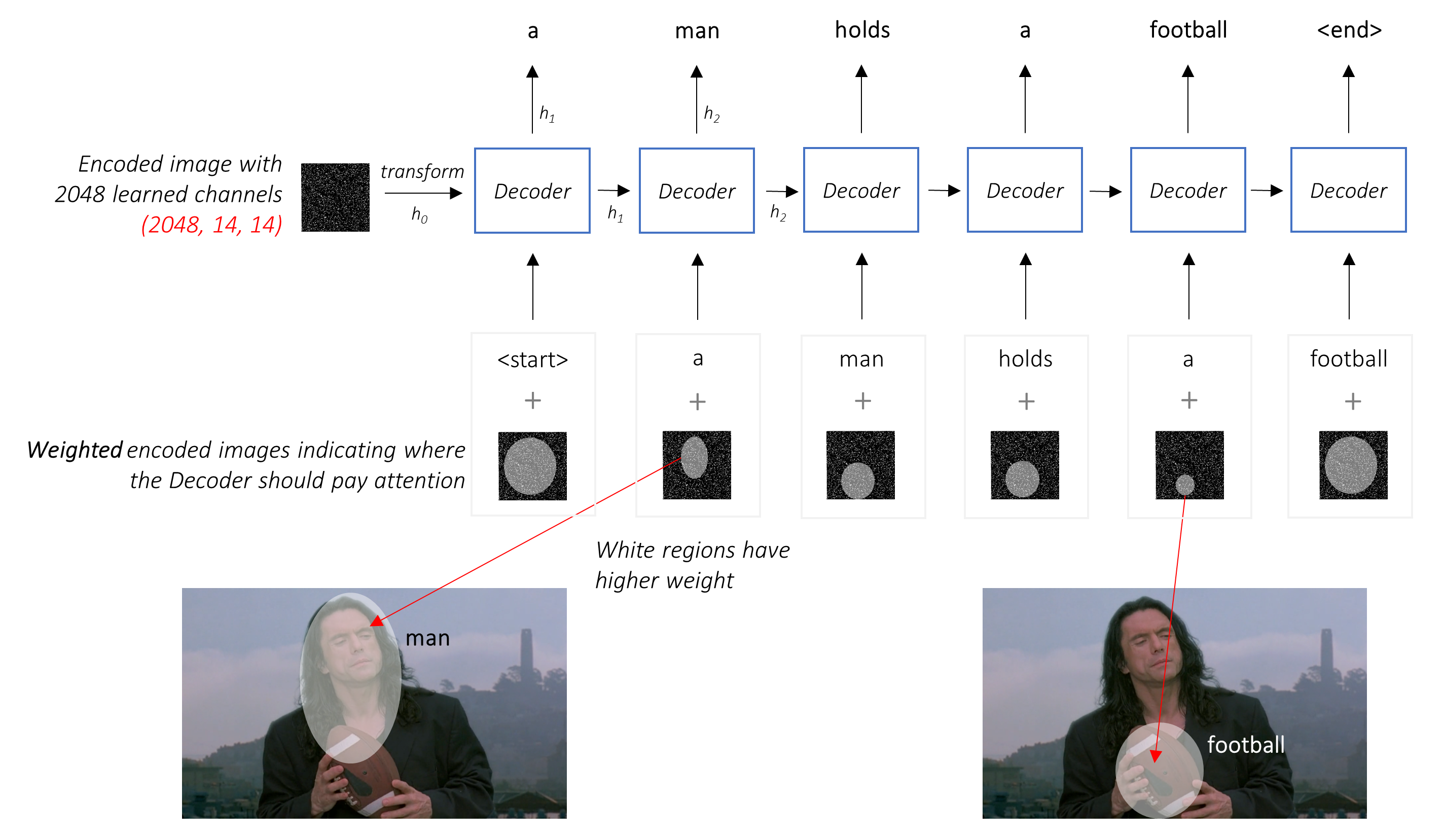
Em vez da média simples, usamos a média ponderada em todos os pixels, com os pesos dos pixels importantes sendo maiores. Esta representação ponderada da imagem pode ser concatenada com a palavra gerada anteriormente em cada etapa para gerar a próxima palavra.
A rede de atenção calcula esses pesos .
Intuitivamente, como você estimaria a importância de uma certa parte de uma imagem? Você precisaria estar ciente da sequência que gerou até agora , para que possa olhar para a imagem e decidir o que precisa descrever a seguir. Por exemplo, depois de mencionar a man , é lógico declarar que ele está holding a football .
É exatamente isso que o mecanismo de atenção faz - considera a sequência gerada até agora e atende a parte da imagem que precisa descrever a seguir.
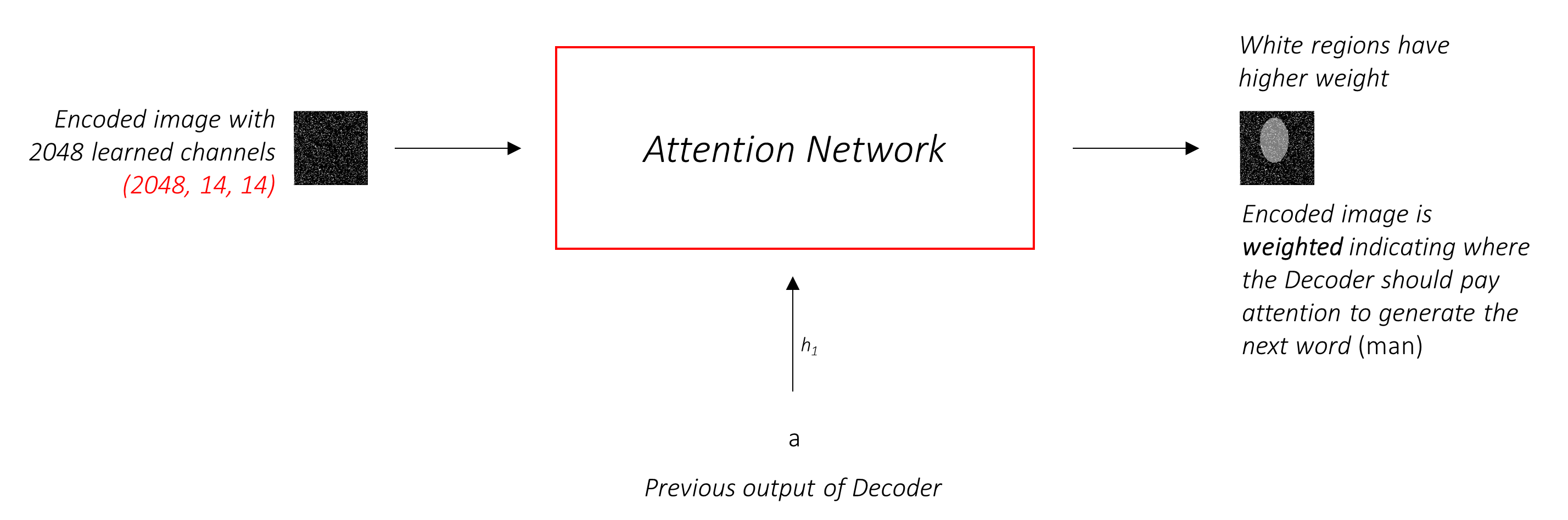
Usaremos a atenção suave , onde os pesos dos pixels somam até 1. Se houver P pixels em nossa imagem codificada, então em cada timestep t -
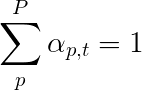
Você pode interpretar todo esse processo como calculando a probabilidade de um pixel ser o local para procurar gerar a próxima palavra .
Pode ficar claro agora como é a nossa rede combinada.
h (e o estado celular C ) para o decodificador LSTM.Usamos uma camada linear para transformar a saída do decodificador em uma pontuação para cada palavra no vocabulário.
A opção direta - e gananciosa - seria escolher a palavra com a pontuação mais alta e usá -la para prever a próxima palavra. Mas isso não é ideal porque o restante da sequência depende da primeira palavra que você escolher. Se essa escolha não for a melhor, tudo o que se segue é subótimo. E não é apenas a primeira palavra - cada palavra na sequência tem consequências para aquelas que o sucedem.
Pode muito bem acontecer que, se você escolhesse a terceira melhor palavra nessa primeira etapa e a segunda melhor palavra na segunda etapa, e assim por diante ... essa seria a melhor sequência que você poderia gerar.
Seria melhor se de alguma forma não decidirmos até terminarmos completamente a decodificação e escolher a sequência que possui a pontuação geral mais alta de uma cesta de sequências candidatas .
A pesquisa de feixe faz exatamente isso.
k candidatos.k Segunda palavras para cada uma dessas k palavras.k [Primeira palavra, segunda palavra], considerando as pontuações de aditivos.k , escolha k Terceiros palavras, escolha as combinações de k [Primeira palavra, segunda palavra, terceira palavra].k , escolha a sequência com a melhor pontuação geral. 
Como você pode ver, algumas seqüências (atacadas) podem falhar mais cedo, pois elas não chegam ao K Top k na próxima etapa. Depois que k sequências (sublinhadas) geram o token <end> , escolhemos aquele com a pontuação mais alta.
As seções abaixo descrevem brevemente a implementação.
Eles são feitos para fornecer algum contexto, mas os detalhes são melhor compreendidos diretamente do código , o que é bastante comentado.
Estou usando o conjunto de dados MSCOCO '14. Você precisaria baixar as imagens de treinamento (13 GB) e validação (6 GB).
Usaremos o treinamento, a validação e as divisões de teste de Andrej Karpathy. Este arquivo zip contém as legendas. Você também encontrará divisões e legendas para os conjuntos de dados Flicker8K e Flicker30K; portanto, fique à vontade para usá -los em vez de MSCOCO se este for muito grande para o seu computador.
Precisaremos de três entradas.
Como estamos usando um codificador pré -treinamento, precisaríamos processar as imagens no formulário que esse codificador pré -treinado está acostumado.
Modelos Imagenet pré -treinados disponíveis como parte do módulo torchvision de Pytorch. Esta página detalha o pré -processamento ou transformação que precisamos executar - os valores de pixel devem estar no intervalo [0,1] e devemos normalizar a imagem pela média e desvio padrão dos canais RGB da ImageNet.
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]Além disso, Pytorch segue a convenção NCHW, que significa que a dimensão dos canais (c) deve preceder as dimensões do tamanho.
Rediaremos todas as imagens do MSCOCO para 256x256 para uniformidade.
Portanto, as imagens alimentadas ao modelo devem ser um tensor Float da dimensão N, 3, 256, 256 e devem ser normalizadas pela média mencionada e desvio padrão. N é o tamanho do lote.
As legendas são o alvo e as entradas do decodificador, pois cada palavra é usada para gerar a próxima palavra.
Para gerar a primeira palavra, no entanto, precisamos de uma palavra de Zeroth , <start> .
Na última palavra, devemos prever <end> O decodificador deve aprender a prever o fim de uma legenda. Isso é necessário porque precisamos saber quando parar de decodificar durante a inferência.
<start> a man holds a football <end>
Como passamos as legendas como tensores de tamanho fixo, precisamos fazer legendas (que são naturalmente de comprimento variável) para o mesmo comprimento com <pad> tokens.
<start> a man holds a football <end> <pad> <pad> <pad>....
Além disso, criamos um word_map que é um mapeamento de índice para cada palavra no corpus, incluindo os tokens <start> , <end> e <pad> . Pytorch, como outras bibliotecas, precisa de palavras codificadas como índices para procurar incorporações para elas ou para identificar seu lugar nas pontuações previstas das palavras.
9876 1 5 120 1 5406 9877 9878 9878 9878....
Portanto, as legendas alimentadas ao modelo devem ser um Int de dimensão N, L onde L é o comprimento acolchoado.
Como as legendas são acolchoadas, precisaríamos acompanhar os comprimentos de cada legenda. Este é o comprimento real + 2 (para os tokens <start> e <end> ).
Os comprimentos de legenda também são importantes porque você pode criar gráficos dinâmicos com Pytorch. Processamos apenas uma sequência até seu comprimento e não desperdiçamos computados nos <pad> s.
Portanto, os comprimentos da legenda alimentados ao modelo devem ser um tensor Int da dimensão N .
Consulte create_input_files() em utils.py .
Isso lê os dados baixados e salva os seguintes arquivos -
I, 3, 256, 256 , onde I é o número de imagens na divisão. Os valores de pixel ainda estão no intervalo [0, 255] e são armazenados como Int s não assinados de 8 bits.N_c * I legendas , onde N_c é o número de legendas amostradas por imagem. Essas legendas estão na mesma ordem que as imagens no arquivo HDF5. Portanto, i legenda corresponderá à imagem i // N_c .N_c * I . i valor é o comprimento da i , que corresponde à imagem i // N_c .word_map , o dicionário de palavra para índice. Antes de salvarmos esses arquivos, temos a opção de usar apenas legendas mais curtas que um limite e para compartilhar palavras menos frequentes em um token <unk> .
Utilizamos arquivos HDF5 para as imagens, porque as leremos diretamente do disco durante o treinamento / validação. Eles são simplesmente grandes demais para se encaixarem em Ram de uma só vez. Mas carregamos todas as legendas e seus comprimentos na memória.
Consulte CaptionDataset em datasets.py .
Esta é uma subclasse do Dataset Pytorch. Ele precisa de um método __len__ definido, que retorna o tamanho do conjunto de dados e um método __getitem__ que retorna i imagem, a legenda e o comprimento da legenda.
Lemos imagens do disco, convertemos pixels para [0,255] e normalizamos -os dentro desta classe.
O Dataset será usado por um Pytorch DataLoader em train.py para criar e alimentar lotes de dados ao modelo para treinamento ou validação.
Consulte Encoder em models.py .
Utilizamos um resnet-101 pré-treinamento já disponível no módulo torchvision da Pytorch. Descarte as duas últimas camadas (camadas lineares e lineares), pois precisamos apenas codificar a imagem e não classificá -la.
Adicionamos uma camada AdaptiveAvgPool2d() para redimensionar a codificação para um tamanho fixo . Isso torna possível alimentar imagens de tamanho variável ao codificador. (No entanto, redimensionamos nossas imagens de entrada para 256, 256 porque tivemos que armazená -las juntas como um único tensor.)
Como podemos querer ajustar o codificador, adicionamos um método fine_tune() que permite ou desativa o cálculo de gradientes para os parâmetros do codificador. Nós apenas ajustamos os blocos convolucionais 2 a 4 na resnet , porque o primeiro bloco convolucional normalmente teria aprendido algo muito fundamental para o processamento de imagens, como detectar linhas, bordas, curvas etc. Não mexemos com as fundações.
Veja Attention em models.py .
A rede de atenção é simples - é composta apenas por camadas lineares e algumas ativações.
Camadas lineares separadas transformam a imagem codificada (achatada em N, 14 * 14, 2048 ) e o estado oculto (saída) do decodificador para a mesma dimensão , viz. o tamanho da atenção. Eles são então adicionados e o RelU ativado. Uma terceira camada linear transforma esse resultado em uma dimensão de 1 , depois que aplicamos o softmax para gerar os pesos alpha .
Consulte DecoderWithAttention in models.py .
A saída do codificador é recebida aqui e achatada para as dimensões N, 14 * 14, 2048 . Isso é apenas conveniente e impede a necessidade de remodelar o tensor várias vezes.
Inicializamos o estado oculto e celular do LSTM usando a imagem codificada com o método init_hidden_state() , que usa duas camadas lineares separadas.
No início, classificamos as N imagens e legendas diminuindo os comprimentos das legendas . Isso é para que possamos processar apenas o Timesteps válido , ou seja, não processar os <pad> s.
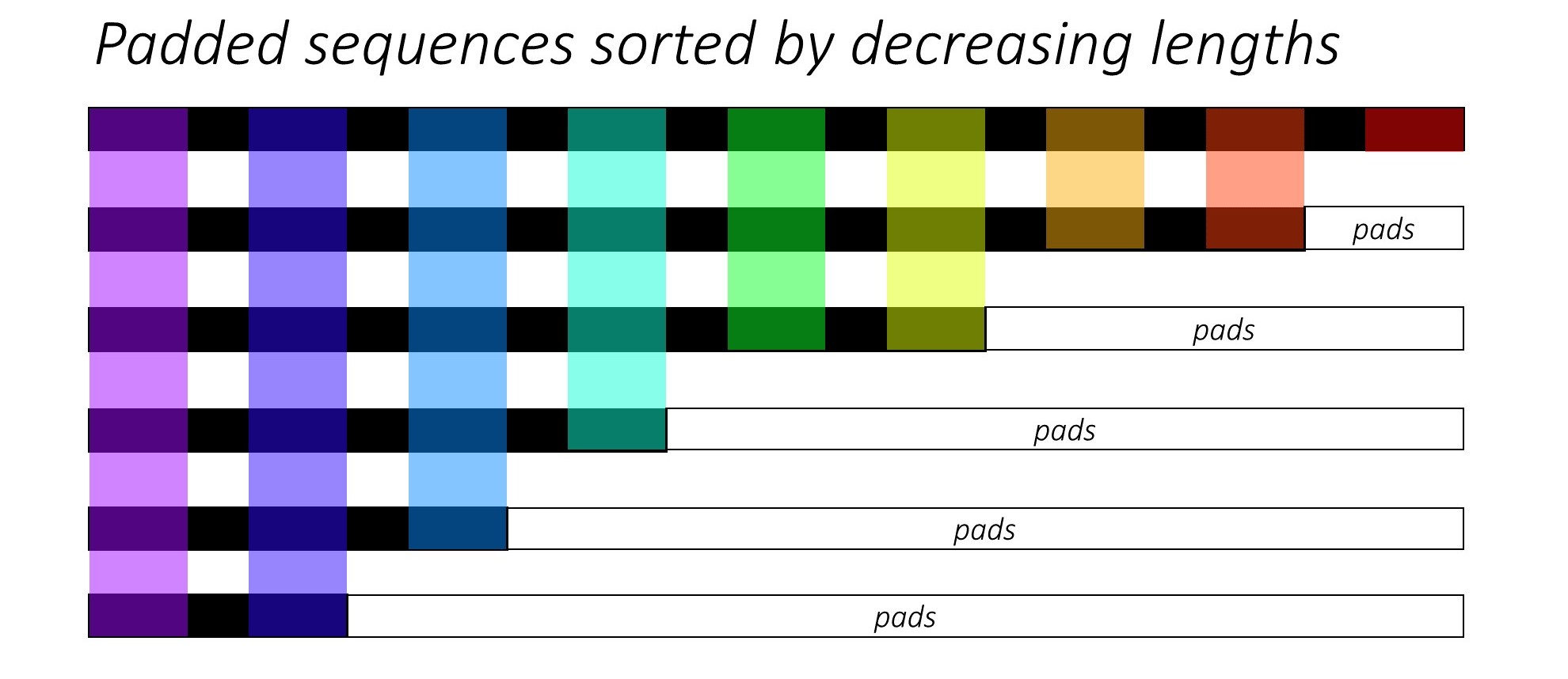
Podemos iterar em cada timestep, processando apenas as regiões coloridas, que são o tamanho eficaz do tamanho do lote N_t nesse timestep. A classificação permite que o Top N_t em qualquer timestep alinhe com as saídas da etapa anterior. No terceiro timestep, por exemplo, processamos apenas as 5 principais imagens, usando as 5 principais saídas da etapa anterior.
Essa iteração é realizada manualmente em um for for pytorch LSTMCell , em vez de iterar automaticamente sem um loop com um pytorch LSTM . Isso ocorre porque precisamos executar o mecanismo de atenção entre cada etapa de decodificação. Um LSTMCell é uma única operação de timestep, enquanto um LSTM iteraria em vários timesteps continuamente e forneceria todas as saídas de uma só vez.
Calculamos os pesos e a codificação ponderada por atenção em cada timestep com a rede de atenção. Na seção 4.2.1 do papel, eles recomendam passar a codificação ponderada pela atenção através de um filtro ou portão . Este portão é uma transformação linear ativada sigmóide do estado oculto anterior do decodificador. Os autores afirmam que isso ajuda a rede de atenção a colocar mais ênfase nos objetos na imagem.
Concatenamos essa codificação filtrada ponderada pela atenção com a incorporação da palavra anterior ( <start> para começar) e executamos o LSTMCell para gerar o novo estado oculto (ou saída) . Uma camada linear transforma esse novo estado oculto em pontuações para cada palavra no vocabulário , que é armazenado.
Também armazenamos os pesos retornados pela rede de atenção a cada timestep. Você verá por que em breve.
Antes de começar, salve os arquivos de dados necessários para treinamento, validação e teste. Para fazer isso, execute o conteúdo de create_input_files.py depois de apontá -lo para o arquivo KarPathy JSON e a pasta de imagens que contém as pastas train2014 e val2014 extraídas dos seus dados baixados.
Veja train.py .
Os parâmetros do modelo (e treinando -o) estão no início do arquivo, para que você possa verificá -los ou modificá -los facilmente, caso deseje.
Para treinar seu modelo do zero , basta executar este arquivo -
python train.py
Para retomar o treinamento em um ponto de verificação , aponte para o arquivo correspondente com o parâmetro de checkpoint no início do código.
Observe que realizamos a validação no final de todas as épocas de treinamento.
Como estamos gerando uma sequência de palavras, usamos CrossEntropyLoss . Você só precisa enviar as pontuações brutas da camada final no decodificador, e a função de perda executará as operações Softmax e log.
Os autores do artigo recomendam usar uma segunda perda - uma " regularização duplamente estocástica ". Sabemos que os pesos somam 1 em um determinado timestep. Mas também incentivamos os pesos em um único pixel p a somar 1 em todos os timesteps T -
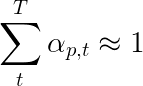
Isso significa que queremos que o modelo atenda a cada pixel ao longo da geração de toda a sequência. Portanto, tentamos minimizar a diferença entre 1 e a soma dos pesos de um pixel em todos os timesteps .
Não calculamos perdas nas regiões acolchoadas . Uma maneira fácil de se livrar das almofadas é usar pack_padded_sequence() do Pytorch, que achate o tensor por timestep enquanto ignora as regiões acolchoadas. Agora você pode agregar a perda sobre esse tensor achatado.
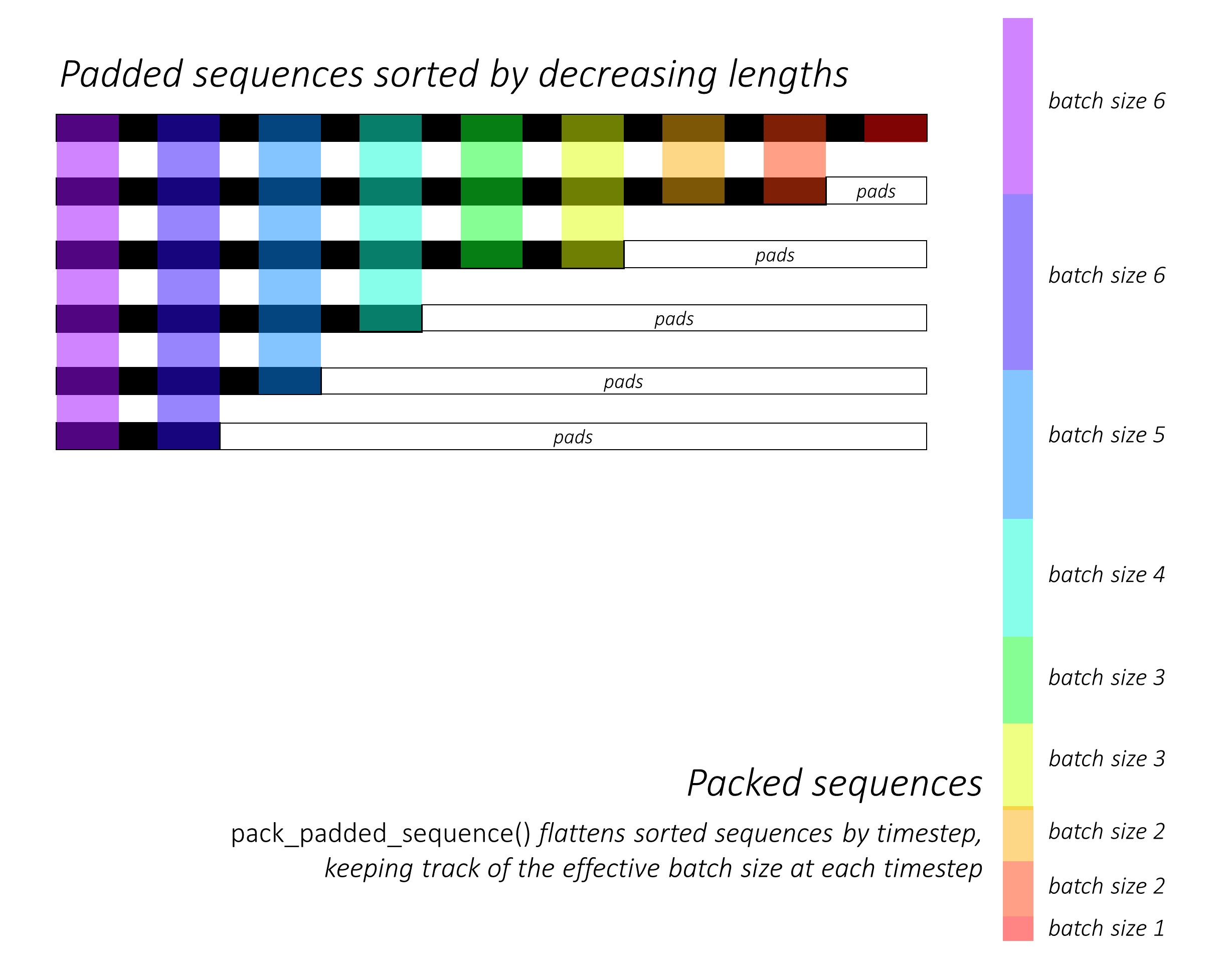
NOTA - Esta função é realmente usada para executar o mesmo lote dinâmico (ou seja, processando apenas o tamanho eficaz do lote em cada timestep) que realizamos em nosso decodificador, ao usar um RNN ou LSTM em Pytorch. Nesse caso, o Pytorch lida com os gráficos dinâmicos de comprimento de variável internamente. Você pode ver um exemplo em dynamic_rnn.py no meu outro tutorial sobre rotulagem de sequência. Teríamos usado essa função junto com um LSTM em nosso decodificador se não estivéssemos iterando manualmente por causa da rede de atenção.
Para avaliar o desempenho do modelo no conjunto de validação, usaremos a métrica de avaliação da Avaliação Bilíngue automatizada (BLEU). Isso avalia uma legenda gerada contra legendas de referência. Para cada legenda gerada, usaremos todas as legendas N_c disponíveis para essa imagem como legendas de referência.
Os autores do programa, participam e dizem que o artigo observa que a correlação entre a perda e a pontuação do bleu se decompõe após um ponto, então eles recomendam parar de treinar cedo quando a pontuação do Bleu começar a se degradar, mesmo que a perda continue a diminuir.
Usei a ferramenta Bleu disponível no módulo NLTK.
Observe que há críticas consideráveis à pontuação Bleu, porque nem sempre se correlaciona bem com o julgamento humano. Os autores também relatam as pontuações dos meteoros por esse motivo, mas não implementei essa métrica.
Eu recomendo que você treine em palcos.
Eu treinei apenas o decodificador, ou seja, sem ajustar o codificador, com um tamanho de lote de 80 . Treinei para 20 épocas, e a pontuação do BLEU-4 atingiu o pico de cerca de 23.25 na 13ª época. Usei o otimizador Adam() com uma taxa de aprendizado inicial de 4e-4 .
Continuei do 13º ponto de verificação da época, permitindo o ajuste fino do codificador com um tamanho de lotes de 32 . O tamanho menor do lote é porque o modelo agora é maior porque contém os gradientes do codificador. Com o ajuste fino, o placar aumentou para 24.29 em apenas 3 épocas. O treinamento contínuo provavelmente teria aumentado a pontuação um pouco maior, mas eu tive que cometer minha GPU em outro lugar.
Uma distinção importante a ser feita aqui é que ainda estou fornecendo a verdade no solo como a entrada em cada retaque decodificado durante a validação, independentemente da palavra gerada pela última vez . Isso é chamado de professor forçando . Embora isso seja comumente usado durante o treinamento para acelerar o processo, como estamos fazendo, as condições durante a validação devem imitar as condições de inferência real o máximo possível. Ainda não implementei a inferência em lotes - onde cada palavra na legenda é gerada a partir da palavra gerada anteriormente e termina ao atingir o token <end> .
Como estou forçando o professor durante a validação, a pontuação Bleu medida acima nas legendas resultantes não reflete o desempenho real. De fato, a pontuação do BLEU é uma métrica projetada para comparar legendas naturalmente geradas com legendas de verdade no solo de comprimento diferente. Depois que a inferência em lotes é implementada, ou seja, nenhum professor forçando, a parada precoce com a pontuação bleu será realmente "adequada".
Com isso em mente, usei eval.py para calcular as pontuações corretas do Bleu-4 deste ponto de verificação do modelo nos conjuntos de validação e teste sem forçar o professor, em diferentes tamanhos de feixe-
| Tamanho do feixe | Validação Bleu-4 | Teste Bleu-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
A pontuação do teste é maior que o resultado no papel e pode ser por causa de como nossas calculadoras Bleu são parametrizadas, o fato de eu ter usado um codificador de resnet e, na verdade, ajustou o codificador-mesmo que apenas um pouco.
Além disso, lembre-se-ao ajustar fino durante o aprendizado de transferência, é sempre melhor usar uma taxa de aprendizado consideravelmente menor do que a usada originalmente para treinar o modelo emprestado. Isso ocorre porque o modelo já está otimizado e não queremos mudar nada muito rapidamente. Também usei Adam() para o codificador, mas com uma taxa de aprendizado de 1e-4 , que é um décimo do valor padrão para este otimizador.
Em um Titan X (Pascal), levou 55 minutos por época sem ajuste fino e 2,5 horas com ajuste fino nos tamanhos de lote declarados.
Você pode baixar este modelo pré -traido e o word_map correspondente aqui.
Observe que esse ponto de verificação deve ser carregado diretamente com Pytorch ou passado para caption.py - veja abaixo.
Veja caption.py .
Durante a inferência, não podemos usar diretamente o método forward() no decodificador porque ele usa forçando o professor. Em vez disso, precisaríamos realmente alimentar a palavra gerada anteriormente para o LSTM em cada timestep .
caption_image_beam_search() lê uma imagem, a codifica e aplica as camadas no decodificador na ordem correta, enquanto usa a palavra gerada anteriormente como entrada para o LSTM em cada timestep. Ele também incorpora pesquisa de feixe.
visualize_att() pode ser usado para visualizar a legenda gerada junto com os pesos em cada timestep, como visto nos exemplos.
Para a legenda uma imagem da linha de comando, aponte para a imagem, modelo de verificação, mapa de palavras (e opcionalmente, o tamanho do feixe) da seguinte maneira -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
Como alternativa, use as funções no arquivo, conforme necessário.
Consulte também eval.py , que implementa esse processo para calcular a pontuação do BLEU no conjunto de validação, com ou sem pesquisa de feixe.





O teste Tommy de Turing - você sabe que a IA não é realmente ai porque não assistiu à sala e não reconhece a grandeza quando a vê.

Você disse atenção suave . Existe uma atenção dura ?
Sim, o programa, comparecer e contar a Paper usa variantes, e o decodificador com atenção "difícil" tem um desempenho marginalmente melhor.
Em atenção suave , que usamos aqui, você está calculando os pesos alpha e usando a média ponderada dos recursos em todos os pixels. Esta é uma operação determinística e diferenciável.
Com muita atenção, você está optando por provar apenas alguns pixels de uma distribuição definida pelo alpha . Observe que qualquer amostragem probabilística não é determinística ou estocástica , ou seja, uma entrada específica nem sempre produzirá a mesma saída. Porém, como a descendência de gradiente pressupõe que a rede seja determinística (e, portanto, diferenciável), a amostragem é reformulada para remover sua estocástica. Meu conhecimento disso é bastante superficial neste momento - atualizarei esta resposta quando tiver um entendimento mais detalhado.
Como uso uma rede de atenção para uma tarefa de PNL como uma sequência para o modelo de sequência?
Assim como você usa uma CNN para gerar uma codificação com os recursos em cada pixel, você usaria um RNN para gerar recursos codificados em cada posição do timestep, ou seja, a posição da palavra na entrada.
Sem atenção, você usaria a saída do codificador no último timestep como a codificação para toda a frase, pois também conteria informações do Timesteps anteriores. A última saída do codificador agora carrega o ônus de ter que codificar a frase inteira de maneira significativa, o que não é fácil, especialmente para frases mais longas.
Com a atenção, você atenderia os timesteps na saída do codificador, gerando pesos para cada timestep/palavra e pegam a média ponderada para representar a frase. Em uma sequência a tarefa de sequência, como a tradução da máquina, você atenderia às palavras relevantes na entrada ao gerar cada palavra na saída.
Você também pode usar atenção sem um decodificador. Por exemplo, se você deseja classificar o texto, poderá atender às palavras importantes na entrada apenas uma vez para executar a classificação.
Podemos usar a pesquisa de feixes durante o treinamento?
Não com a função de perda atual, mas sim. Isso não é comum.
O que o professor está forçando?
A força do professor é quando usamos as legendas da verdade do solo como entrada para o decodificador em cada timestep, e não a palavra que gerou no timestep anterior. É comum à força de professores durante o treinamento, pois isso pode significar uma convergência mais rápida do modelo. Mas também pode aprender a depender de saber a resposta correta e exibir alguma instabilidade na prática.
Seria ideal treinar usando o professor forçando apenas algumas vezes, com base em uma probabilidade. Isso é chamado de amostragem programada.
(Pretendo adicionar a opção).
Posso usar incorporações de palavras pré -gravadas (luva, CBOW, Skipgram, etc.) em vez de aprendê -las do zero?
Sim, você pode, com o método load_pretrained_embeddings() na classe Decoder . Você também pode optar por ajustar (ou não) com o método fine_tune_embeddings() .
Depois de criar o decodificador em train.py , você deve fornecer os vetores pré -terem traido para load_pretrained_embeddings() empilhados na mesma ordem que no word_map . Para palavras para as quais você não possui vetores pré -criados para, como <start> , você pode inicializar incorporação aleatoriamente como fizemos em init_weights() . Eu recomendo o ajuste fino para aprender vetores mais significativos para esses vetores inicializados aleatoriamente.
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False Certifique-se também de alterar o parâmetro emb_dim de seu valor atual de 512 para o tamanho de suas incorporações pré-treinadas. Isso deve ajustar automaticamente o tamanho da entrada do decodificador LSTM para acomodá -los.
Como acompanho quais tensores permitem que os gradientes sejam calculados?
Com a liberação do Pytorch 0.4 , os tensores de embrulho como Variable S não são mais necessários. Em vez disso, os tensores têm o atributo requires_grad , que decide se ele é rastreado pelo autograd e, portanto, se os gradientes são calculados para ele durante a retropoupagação.
requires_grad será definido como False .requires_grad será definido como True .requires_grad tensores que são parâmetros de torch.nn TrueComo faço para calcular todas as pontuações Bleu (ou seja, Bleu-1 para Bleu-4) durante a avaliação?
Você precisaria modificar o código em eval.py para fazer isso. Consulte esta excelente resposta do Kmario23 para uma explicação clara e detalhada.


