a PyTorch Tutorial to Image Captioning
1.0.0
这是图像字幕的Pytorch教程。
这是我正在写的一系列教程中的第一个,内容涉及出色的Pytorch图书馆独自实施酷模型。
假定Pytorch,卷积和经常性神经网络的基础知识。
如果您是Pytorch的新手,请首先使用Pytorch阅读深度学习:60分钟的闪电战和学习示例的Pytorch。
问题,建议或更正可以作为问题发布。
我在Python 3.6中使用PyTorch 0.4 。
2020年1月27日:添加了两个新教程的工作代码 - 超分辨率和机器翻译
客观的
概念
概述
执行
训练
推理
常见问题
为了构建可以为图像生成描述性标题的模型,我们提供了图像。
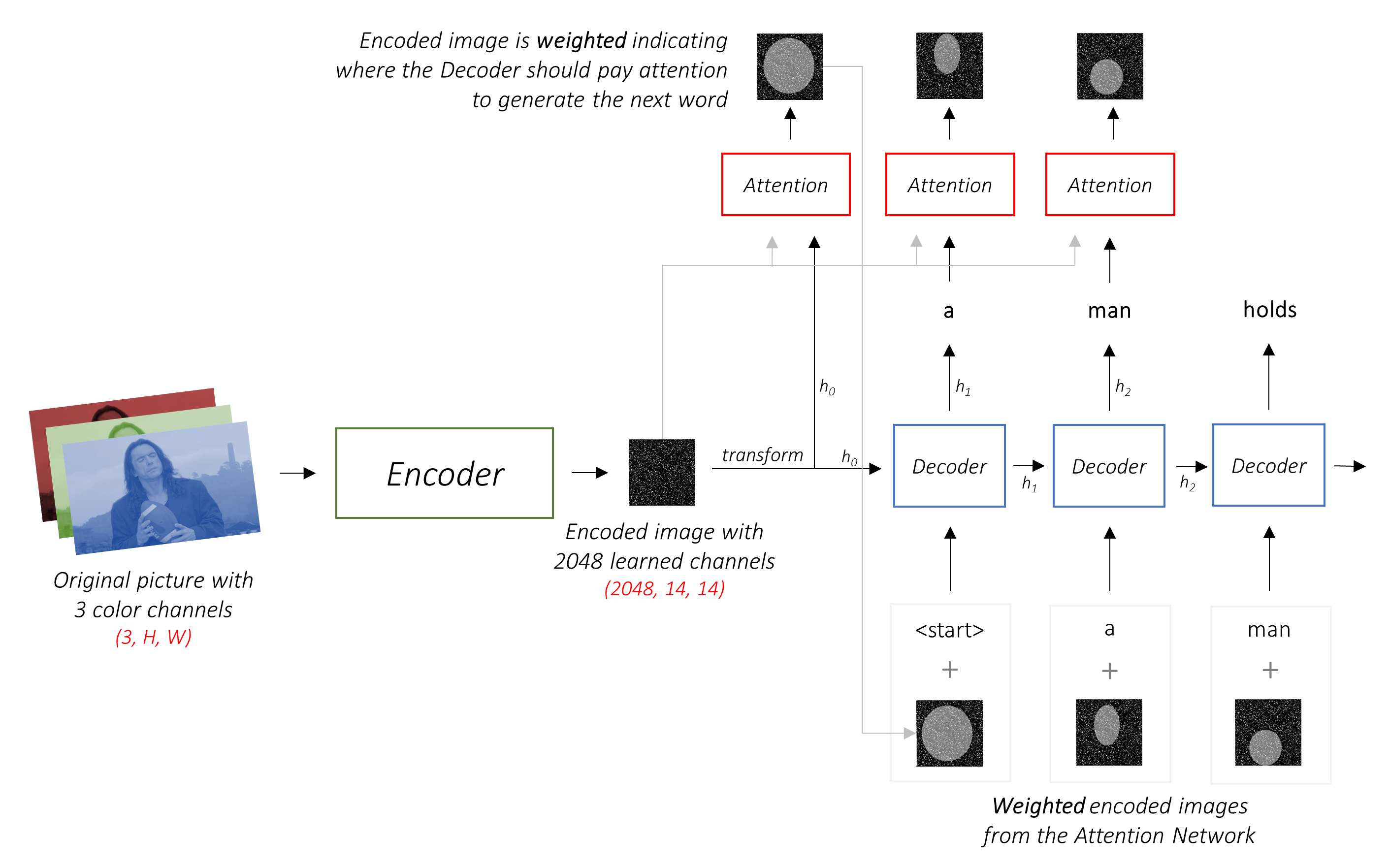
为了使事情保持简单,让我们实施演出,参加并告诉论文。这绝不是当前的最新最新,但仍然非常惊人。作者的原始实现可以在此处找到。
该模型学会了看哪里。
当您生成字幕,单词时,您会看到模型的目光在整个图像上转移。
这是可能的,因为它的注意机制使其可以专注于与接下来要说的一词最相关的图像的一部分。
以下是在训练或验证期间看不到的测试图像上生成的一些字幕:




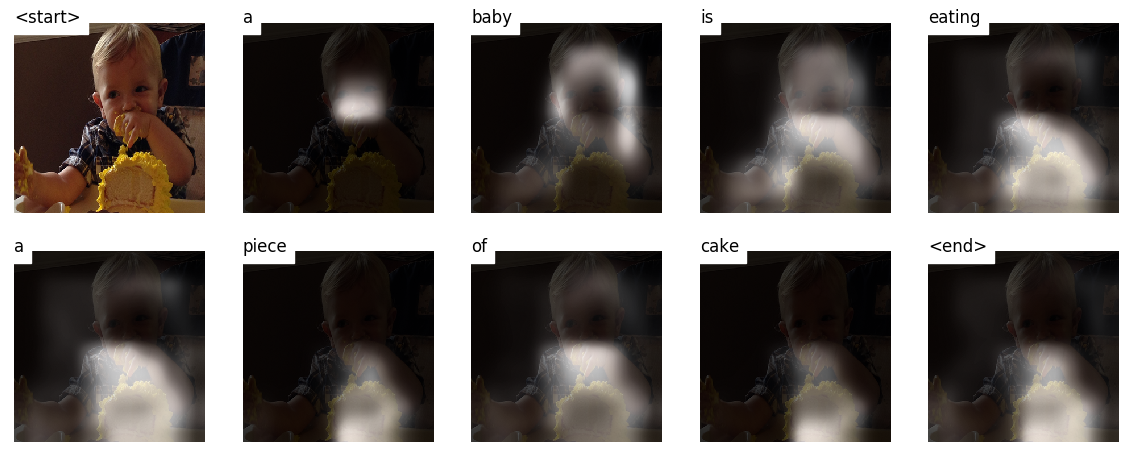

教程结束时还有更多示例。
图像字幕。 du。
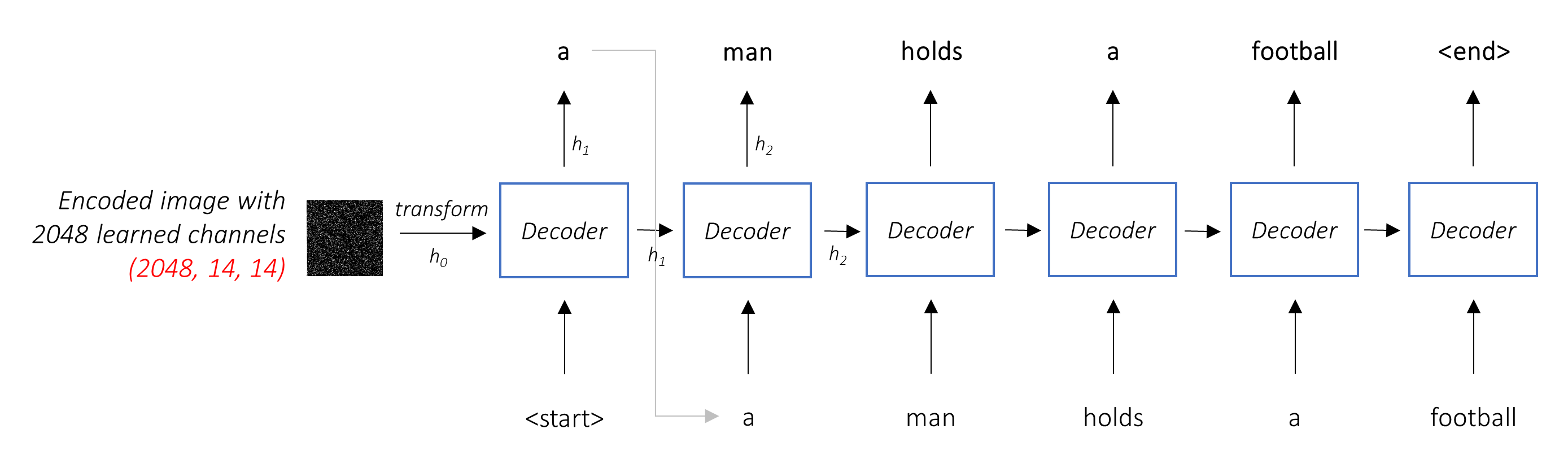
编码器架构。通常,生成序列的模型将使用编码器将输入编码为固定的形式和解码器,将其通过单词将其解码为序列。
注意力。注意网络的使用在深度学习中广泛存在,并且有充分的理由。这是模型仅选择其认为与手头任务相关的编码部分的一种方式。您在此处看到的相同机制可以在任何模型中使用编码器的输出具有多个空间或时间点。在图像字幕中,您认为有些像素比其他像素更重要。按照机器翻译等序列任务的顺序,您认为一些单词比其他单词更重要。
转移学习。这是您通过在新模型中使用其部分从现有模型借用的时候。这几乎总是比从头开始训练新模型更好(即一无所知)。如您所见,您始终可以将这些二手知识调整为手头的特定任务。使用验证的单词嵌入是一个愚蠢但有效的例子。对于我们的图像字幕问题,我们将使用验证的编码器,然后根据需要对其进行微调。
梁搜索。在这里,您不让解码器懒惰,只需在每个解码步骤中选择最佳分数的单词即可。光束搜索对于任何语言建模问题都是有用的,因为它找到了最佳的序列。
在本节中,我将介绍此模型。如果您已经熟悉它,则可以直接跳到实施部分或注释代码。
编码器将带有3个颜色通道的输入图像编码为带有“学习”通道的较小图像。
这个较小的编码图像是原始图像中所有有用的所有内容的摘要表示。
由于我们想编码图像,因此我们使用卷积神经网络(CNN)。
我们不需要从头开始训练编码器。为什么?因为已经有CNN训练来表示图像。
多年来,人们一直在建立非常擅长将图像分为一千个类别之一的模型。可以很好地理解这些模型很好地捕获了图像的本质。
我选择使用在Pytorch中已经可用的ImageNet分类任务的101个分层残差网络。如前所述,这是转移学习的一个例子。您可以选择对其进行微调以提高性能。

这些模型逐渐创建了原始图像的越来越小的表示形式,并且每个后续表示形式更加“学到”,并具有更多的渠道。我们的Resnet-101编码器生产的最终编码的大小为14x14,具有2048个通道,即2048, 14, 14尺寸张量。
我鼓励您尝试其他预训练的架构。该论文使用VGGNET,也可以在ImageNet上预处理,但没有进行微调。无论哪种方式,都需要修改。由于其中的最后一层或两个模型是线性层以及用于分类的SoftMax激活,因此我们将其剥离。
解码器的工作是查看编码的图像并通过单词生成字幕。
由于它正在生成一个序列,因此需要是复发性神经网络(RNN)。我们将使用LSTM。
在典型的环境中,无需注意,您可以简单地平均所有像素上的编码图像。然后,您可以将其作为第一个隐藏状态以或不用线性转换为单位,并生成标题。每个预测的单词用于生成下一个单词。
在引起注意的环境中,我们希望解码器能够在序列的不同点上查看图像的不同部分。例如,在a man holds a football中产生football一词时,解码器会注意到 - 您猜对了 - 足球!
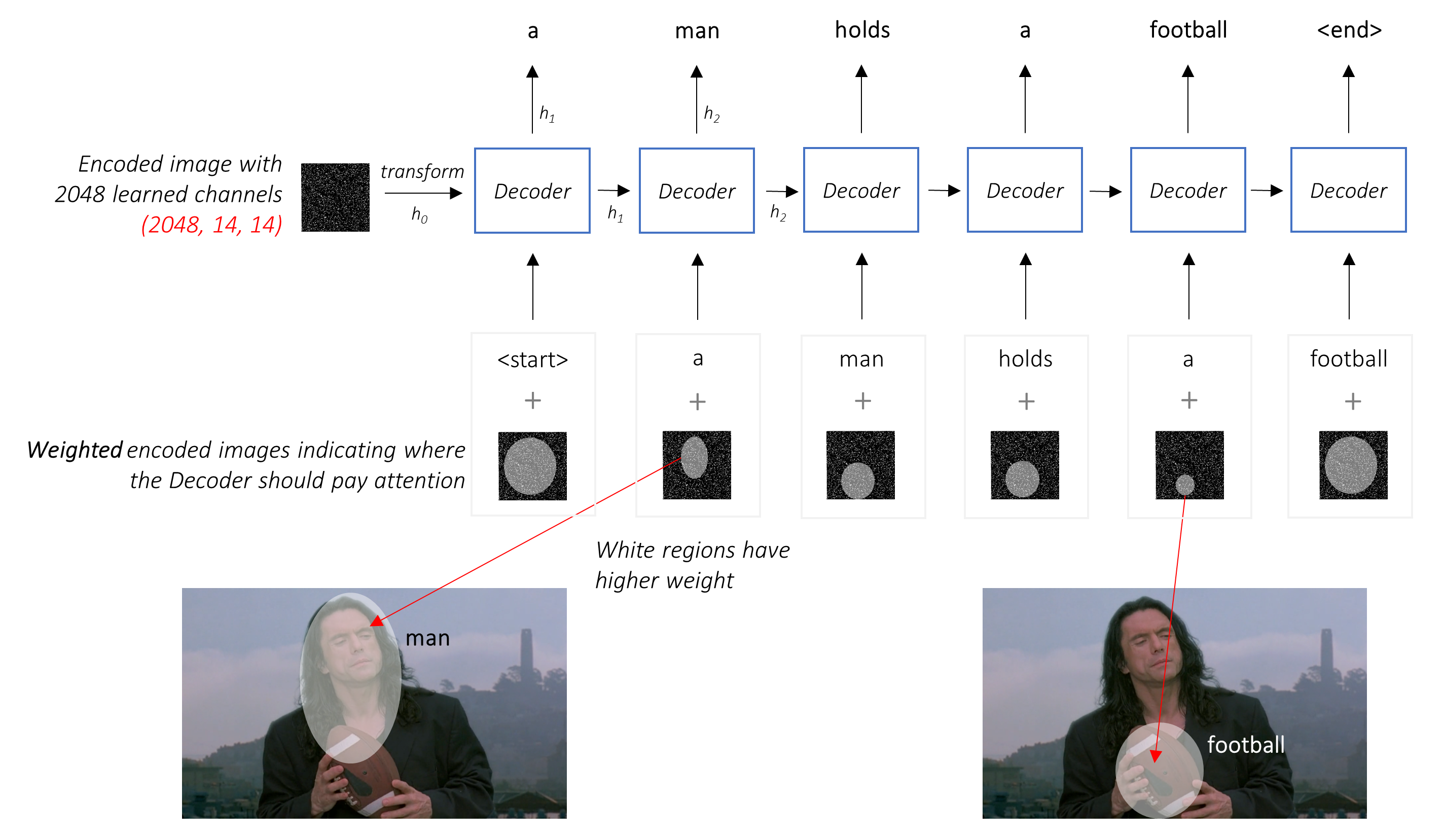
我们使用所有像素的加权平均值,而不是简单的平均值,重要的像素的权重更大。图像的加权表示可以与先前生成的单词在每个步骤中串联以生成下一个单词。
注意网络计算这些权重。
直观地,您如何估计图像某个部分的重要性?您需要了解到目前为止生成的序列,因此您可以查看图像并确定接下来描述的需求。例如,在提到a man之后,宣布他在holding a football是合乎逻辑的。
这正是注意机制所做的 - 它考虑到迄今为止生成的序列,并参与了下一描述的图像部分。
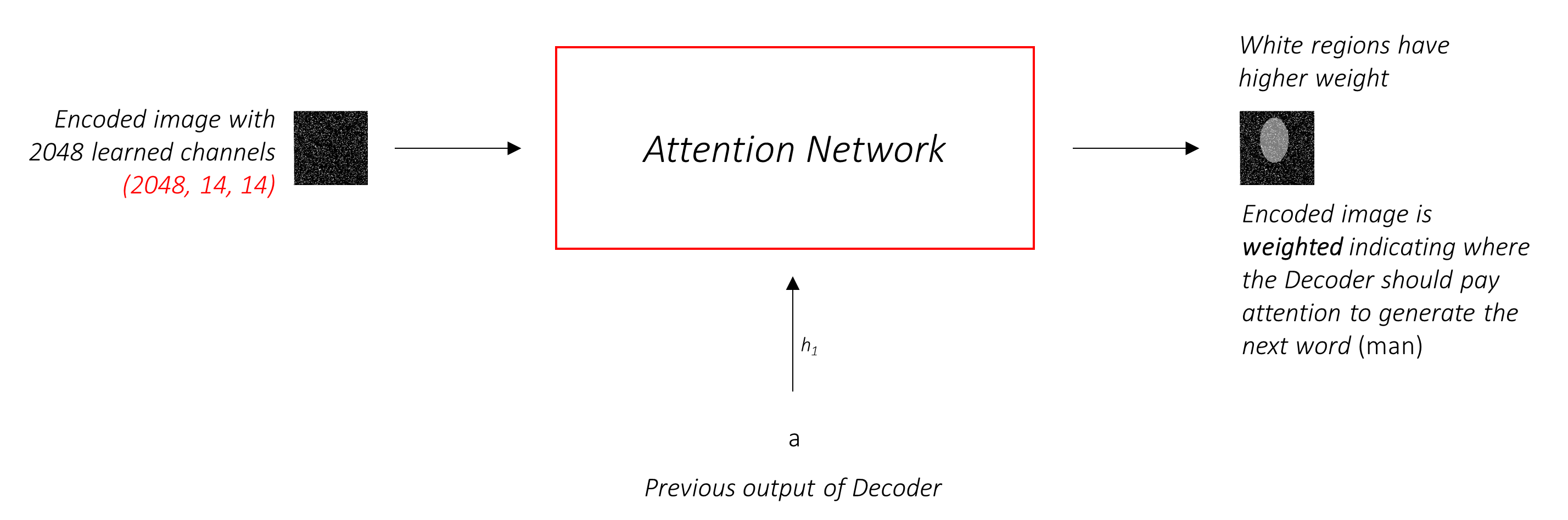
我们将使用柔和的注意,其中像素P重量加起来t 1。
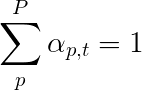
您可以将整个过程解释为计算像素是要生成下一个单词的地方的概率。
到目前为止,我们的组合网络的外观可能很清楚。
h (和单元格状态C )。我们使用线性层将解码器的输出转换为词汇中每个单词的分数。
直接和贪婪的选项是选择具有最高分数的单词,并使用它来预测下一个单词。但这不是最佳的,因为序列的其余部分取决于您选择的第一个单词。如果这种选择不是最好的,那么随后的一切都是最佳的。这不仅是第一个单词 - 顺序中的每个单词都会对成功的后果产生后果。
如果您在第一步中选择了第三个最佳单词,而在第二步中选择了第二个最佳单词,那么……这将是您可以生成的最好的序列。
最好只有以某种方式不能以某种方式决定,直到我们完全解码并选择从一篮子候选序列中总分最高得分的序列。
光束搜索是这样做的。
k候选人。k的第一个单词生成k第二个单词。k [第一个单词,第二个单词]组合考虑加法分数。k第二个单词,请选择k第三个单词,选择顶部k [第一个单词,第二个单词,第三个单词]组合。k序列终止之后,选择具有最佳总分的序列。 
如您所见,某些序列(击中)可能会更早失败,因为它们在下一步中没有进入顶部k一旦k序列(带下划线)生成<end>令牌,我们就会选择分数最高的一个。
以下各节简要描述了实现。
它们的目的是提供一些背景,但是最好直接从代码中理解细节,这是非常重大评论的。
我正在使用MSCOCO '14数据集。您需要下载培训(13GB)和验证(6GB)图像。
我们将使用Andrej Karpathy的培训,验证和测试拆分。该邮政编码包含字幕。您还将找到Flicker8K和Flicker30k数据集的拆分和字幕,因此,如果对于您的计算机来说太大,请随时使用这些拆分和字幕而不是MSCOCO。
我们将需要三个输入。
由于我们使用了验证的编码器,因此我们需要将图像处理为习惯的验证编码器的形式。
预处理的成像网模型是Pytorch的torchvision模块的一部分。此页面详细介绍了我们需要执行的预处理或转换 - 像素值必须在[0,1]范围内,然后我们必须通过Imagenet图像的RGB通道的平均值和标准偏差来归一化图像。
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]另外,Pytorch遵循NCHW惯例,这意味着通道维度(C)必须先于大小尺寸。
我们将使所有Mscoco图像的大小调整到256x256,以保持均匀性。
因此,馈送到模型的图像必须是尺寸N, 3, 256, 256的Float张量,并且必须通过上述平均值和标准偏差进行标准化。 N是批处理大小。
字幕既是解码器的目标又是输入,因为每个单词都用于生成下一个单词。
但是,要生成第一个单词,我们需要一个zeroth单词<start> 。
在最后一句话中,我们应该预测<end>解码器必须学会预测标题的结尾。这是必要的,因为我们需要知道何时在推理过程中停止解码。
<start> a man holds a football <end>
由于我们将字幕传递为固定尺寸张量,因此我们需要用<pad>令牌将标题(自然的长度变化)添加到相同的长度。
<start> a man holds a football <end> <pad> <pad> <pad>....
此外,我们创建一个word_map ,它是语料库中每个单词的索引映射,包括<start> , <end>和<pad>令牌。与其他库一样,Pytorch需要编码单词作为索引来查找它们的嵌入或在预测的单词分数中识别其位置。
9876 1 5 120 1 5406 9877 9878 9878 9878....
因此,馈送到模型的字幕必须是尺寸为N, L的Int张量,其中L是填充长度。
由于标题是填充的,因此我们需要跟踪每个字幕的长度。这是实际的长度 + 2(对于<start>和<end>令牌)。
字幕长度也很重要,因为您可以使用Pytorch构建动态图。我们仅处理一个序列,直到其长度,并且不会浪费在<pad> s上的计算。
因此,馈送到模型的字幕长度必须是维数N的Int张量。
请参阅utils.py中的create_input_files() 。
这会读取下载的数据并保存以下文件 -
I, 3, 256, 256张量中的每个拆分的图像,其中I是拆分中的图像数。像素值仍在[0,255]范围内,并存储为未签名的8位Int s。N_c * I编码字幕的列表,其中N_c是每个图像采样的字幕数。这些字幕与HDF5文件中的图像的顺序相同。因此, i字幕将对应于i // N_c th图像。N_c * I字幕长度的列表。 i th值是i字幕的长度,与i // N_c th图像相对应。word_map的JSON文件,单词到索引字典。在保存这些文件之前,我们可以选择仅使用比阈值短的字幕,而将频率较低的单词放入<unk>中。
我们将HDF5文件用于图像,因为我们将在培训 /验证过程中直接从磁盘中读取它们。它们太大了,无法一次适合RAM。但是我们确实将所有字幕及其长度加载到内存中。
请参阅datasets.py中的CaptionDataset 。
这是Pytorch Dataset集的子类。它需要定义的__len__方法,该方法返回数据集的大小,以及一个返回i th映像,标题和字幕长度的__getitem__方法。
我们读取来自磁盘的图像,将像素转换为[0,255],并在此类中将其归一化。
该Dataset将在train.py中的pytorch DataLoader器使用,以创建和将数据批量馈送到模型中以进行培训或验证。
请参阅models.py中的Encoder 。
我们使用Pytorch的torchvision模块中已经可用的预处理的RESNET-101。丢弃最后两层(池和线性层),因为我们只需要编码图像,而不是对其进行分类。
我们确实添加了一个AdaptiveAvgPool2d()层,以将编码大小调整到固定尺寸。这使得可以将可变大小的图像馈送到编码器。 (但是,我们确实将输入图像大小调整到256, 256因为我们必须将它们作为单个张量存储在一起。)
由于我们可能想微调编码器,因此添加了一个fine_tune()方法,该方法可以启用或禁用编码器参数的梯度计算。我们仅在Resnet中微调卷积区块2到4 ,因为第一个卷积块通常会学到对图像处理非常基本的东西,例如检测线,边缘,曲线等。我们不会对基础感到烦恼。
请参阅models.py中的Attention 。
注意网络很简单 - 它仅由线性层和几个激活组成。
单独的线性层将编码的图像(扁平为N, 14 * 14, 2048 )和隐藏状态(输出)从解码器到相同的尺寸,即。注意力大小。然后添加它们并激活。第三个线性层将此结果转换为1的尺寸,因此我们应用SoftMax来生成权重alpha 。
参见models.py中的DecoderWithAttention 。
在此处接收编码器的输出,并扁平到N, 14 * 14, 2048 。这只是方便的,并且可以防止多次重塑张量。
我们使用init_hidden_state()方法使用编码图像初始化LSTM的隐藏和单元格状态,该图像使用了两个单独的线性层。
从一开始,我们通过减小字幕长度来对N图像和字幕进行排序。这样我们才能仅处理有效的时间段,即,而不是处理<pad> s。
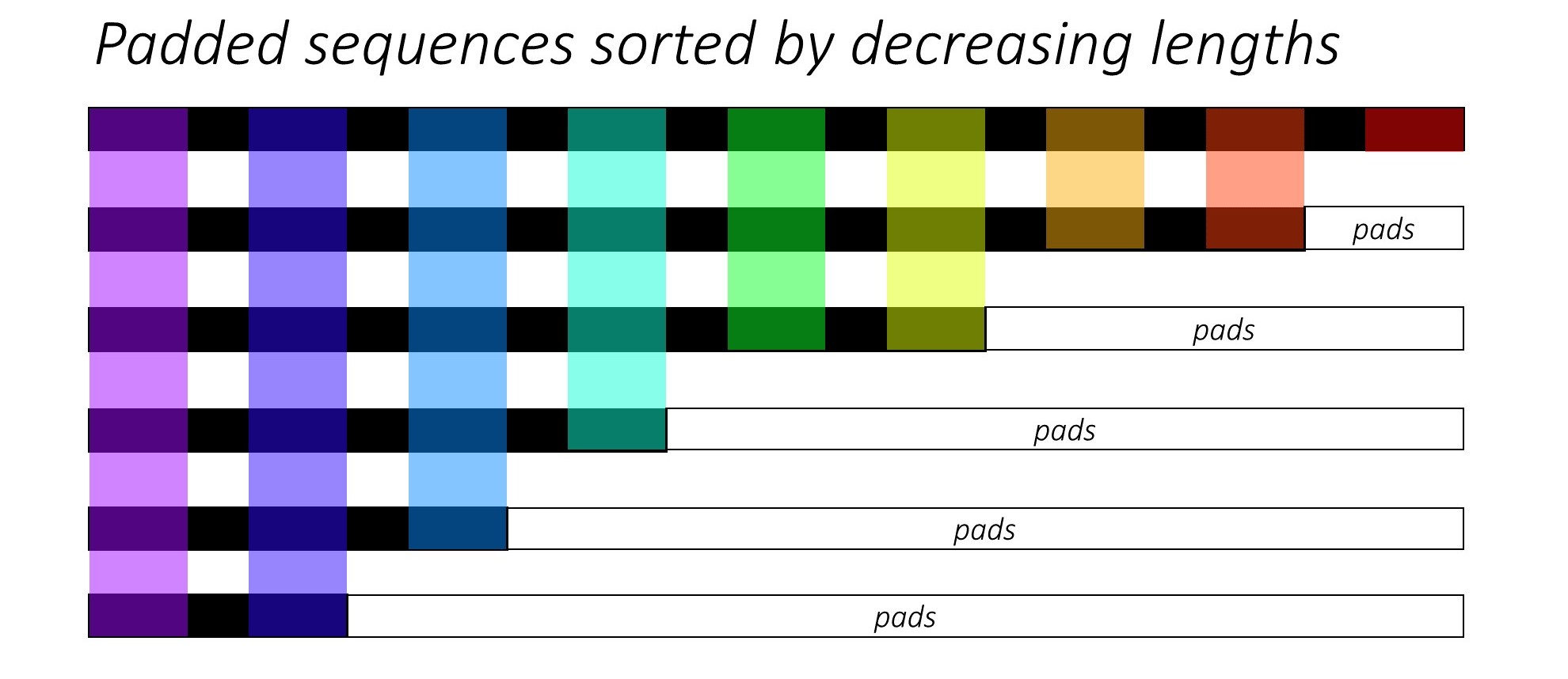
我们可以在每个时间段上迭代,只处理彩色区域,这是该时间步中有效的批量N_t 。排序允许在任何时间步上的顶部N_t与上一步的输出对齐。例如,在第三个时间步中,我们仅使用上一步的前5个输出来处理前5个图像。
此迭代是用Pytorch LSTMCell手动进行的for而不是在没有带有Pytorch LSTM循环的情况下自动迭代。这是因为我们需要在每个解码步骤之间执行注意机制。 LSTMCell是一个单个时间步操作,而LSTM会持续在多个时间步上迭代并立即提供所有输出。
我们通过注意网络计算每个时间步上的权重和注意力加权编码。在论文的4.2.1节中,他们建议通过过滤器或门传递编码的注意力加权。该门是解码器先前隐藏状态的Sigmoid激活线性变换。作者指出,这有助于注意力网络更加强调图像中的对象。
我们将这种过滤的注意力加权编码与上一个单词的嵌入( <start>开始)相连,然后运行LSTMCell以生成新的隐藏状态(或输出) 。线性层将这个新的隐藏状态转换为词汇中每个单词的得分,该单词存储。
我们还将注意力网络返回的权重在每个时间步段返回。您会明白为什么很快。
在开始之前,请确保保存所需的数据文件进行培训,验证和测试。为此,将其指向到karpathy文件和包含提取的train2014和val2014文件夹的图像文件夹后,运行create_input_files.py的内容。
参见train.py 。
模型的参数(和培训)在文件的开头,因此您可以在愿意的情况下轻松检查或修改它们。
要从头开始训练您的模型,只需运行此文件 -
python train.py
要在检查点恢复培训,请指向代码开头的checkpoint参数的相应文件。
请注意,我们在每个培训时期结束时执行验证。
由于我们正在生成一系列单词,因此我们使用CrossEntropyLoss 。您只需要从解码器中的最后一层提交原始分数,损耗函数将执行SoftMax和日志操作。
本文的作者建议使用第二次损失 - “双随机正则化”。我们知道在给定时间步长的权重总和至1。但是我们也鼓励单个像素p的重量在所有时间段T中总和为1 -
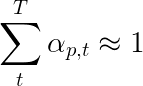
这意味着我们希望该模型在生成整个序列的过程中关注每个像素。因此,我们试图最大程度地减少所有时间步中1与像素权重的总和之间的差异。
我们不计算填充区域上的损失。消除垫子的一种简单方法是使用pytorch的pack_padded_sequence() ,它通过时间段来平移张量,同时忽略填充区域。现在,您可以汇总此扁平张量的损失。
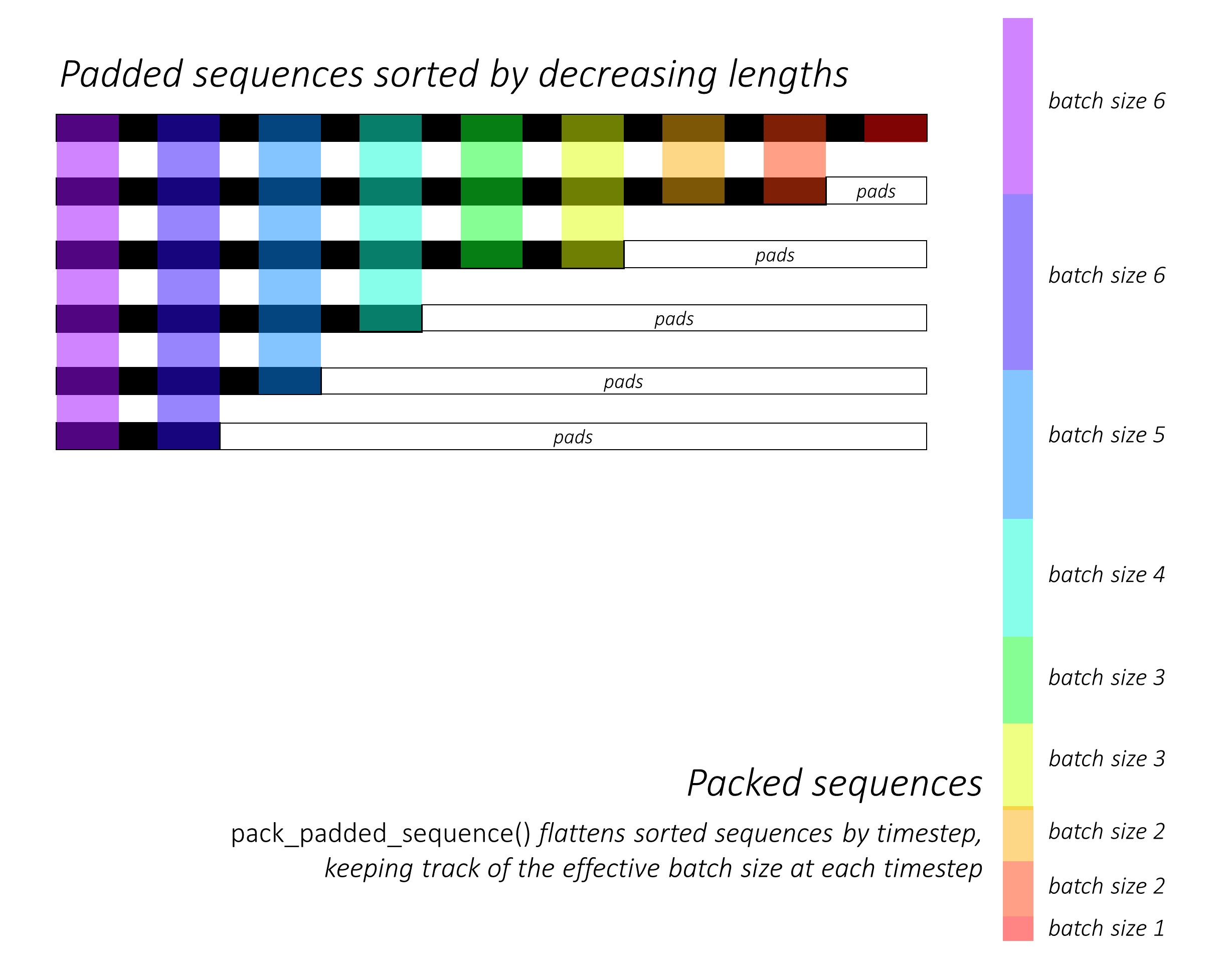
注意- 实际上,此功能用于执行相同的动态批处理(即,在每个时间步中仅处理有效的批处理大小),当时我们在解码器中使用Pytorch中的RNN或LSTM时执行。在这种情况下,Pytorch内部处理动态变量长度图。您可以在我的其他序列标签教程中在dynamic_rnn.py中看到一个示例。如果由于注意力网络而没有手动迭代,我们将在解码LSTM中使用此功能。
为了评估模型在验证集上的性能,我们将使用自动化的双语评估研究(BLEU)评估度量指标。这评估了针对参考标题的生成字幕。对于每个生成的字幕,我们将使用该图像可用的所有N_c字幕作为参考字幕。
演出的作者参加并告诉Paper观察到,损失与BLEU分数之间的相关性在点之后分解,因此他们建议在BLEU分数何时开始降级,即使损失继续下降,也建议停止训练。
我使用了NLTK模块中可用的BLEU工具。
请注意,对BLEU分数有相当大的批评,因为它并不总是与人类判断良好相关。作者还报告了流星得分,因此我尚未实施此指标。
我建议您分阶段训练。
我首先仅培训了解码器,即没有微调编码器,批量大小为80 。我训练了20个时代,而BLEU-4的得分在第13个时代达到了约23.25 。我使用的是Adam()优化器的初始学习率为4e-4 。
我从第13个时期检查点继续进行,允许对编码器进行微调,批量大小为32 。较小的批量大小是因为该模型现在更大,因为它包含编码器的梯度。通过微调,得分仅在大约3个时代上升到24.29 。继续训练可能会使分数略高,但我不得不在其他地方提出GPU。
在这里做出的一个重要区别是,无论最后生成的单词如何,我仍在验证过程中每个解码步骤中的输入作为输入。这称为老师强迫。尽管这在培训期间通常用于加速过程,但就像我们正在训练一样,验证期间的条件必须尽可能地模仿实际的推理条件。我尚未实现批处理推断 - 标题中的每个单词都是从先前生成的单词生成的,并在击中<end>令牌时终止。
由于我在验证期间对教师进行了努力,因此上面在结果字幕上测得的BLEU得分并不能反映实际的性能。实际上,BLEU评分是一个旨在将自然产生的字幕与不同长度不同的基本字幕进行比较的度量。一旦实施了批处理推断,即没有老师强迫,与BLEU分数的早期停滞将是真正的“适当”。
考虑到这一点,我使用eval.py来计算验证和测试集的此模型检查点的正确BLEU-4分数,而无需老师强迫,在不同的光束尺寸 -
| 梁尺寸 | 验证bleu-4 | 测试BLEU-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
测试分数高于论文的结果,可能是因为我们的BLEU计算器的参数化,我使用了Resnet Encoder的事实,并且实际上对编码器进行了微调 - 即使只是一点。
另外,请记住 - 在转移学习过程中进行微调时,使用学习率比最初用于训练借用模型的学习率要比最初要小得多。这是因为该模型已经非常优化,我们不想太快更改任何内容。我也将Adam()用于编码器,但是学习率为1e-4 ,这是该优化器的默认值的十分之一。
在泰坦X(Pascal)上,每个时期花费了55分钟,而无需微调,而在规定的批处理大小上进行了2.5小时。
您可以在此处下载此验证的模型和相应的word_map 。
请注意,该检查点应直接与Pytorch一起加载,或将其传递到caption.py - 请参见下文。
请参阅caption.py 。
在推论期间,我们无法在解码器中直接使用forward()方法,因为它使用了教师强迫。相反,我们实际上需要在每个时间步中将先前生成的单词馈送到LSTM 。
caption_image_beam_search()读取图像,对其进行编码,并按照正确的顺序应用解码器中的层,同时使用先前生成的单词作为每个时间段的LSTM的输入。它还结合了光束搜索。
如示例所示,可视visualize_att()生成的字幕以及每个时间步中的权重来可视化生成的字幕。
要在命令行中标记图像,指向图像,模型检查点,单词映射(以及可选的,光束大小)如下 -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
或者,根据需要使用文件中的功能。
另请参见eval.py ,该过程实现此过程,用于计算验证集上的BLEU分数,无论是否没有光束搜索。





Turing Tommy测试- 您知道AI并不是真正的AI,因为它没有看过房间,并且在看到它时也不认识到伟大。

你说的是轻松的关注。嗯,有一个艰难的关注吗?
是的,节目,参加和告诉纸张使用两种变体,而“硬”注意的解码器的表现略有差异。
在我们在这里使用的柔和注意力中,您正在计算权重alpha ,并使用所有像素上功能的加权平均值。这是一个确定性的,可区分的操作。
在急需的关注下,您选择仅从alpha定义的分布中采样一些像素。请注意,任何此类概率采样都是非确定性或随机的,即特定输入不会始终产生相同的输出。但是,由于梯度下降以确定性(因此可以差异化)为前提,因此对采样进行了重新设计以消除其随机性。在这一点上,我对此的了解相当肤浅 - 当我有更详细的理解时,我将更新此答案。
如何将注意力网络用于NLP任务,例如序列进行序列模型?
就像您使用CNN在每个像素处生成具有功能的编码一样,您将使用RNN在输入中的每个时间步中生成编码的功能。
没有注意力,您将在最后一个时间步长将编码器的输出用作整个句子的编码,因为它还包含了先前的时间步中的信息。现在,编码器的最后一个输出承担了必须有意义地编码整个句子的负担,这并不容易,尤其是对于更长的句子。
注意,您将参加编码器输出中的时间段,为每个时间步/单词产生权重,并以加权平均值表示句子。在诸如机器翻译之类的序列任务的序列中,您将在输出中生成每个单词时在输入中的相关单词。
您也可以在没有解码器的情况下使用注意力。例如,如果您想对文本进行分类,则可以仅一次输入中的重要单词来执行分类。
我们可以在训练期间使用梁搜索吗?
不是当前的损失功能,而是。这根本不常见。
什么是老师强迫?
老师的强迫是,当我们使用地面真相字幕作为每个时间步中解码器的输入时,而不是它在上一个时间步中生成的单词。在培训期间,教师力量很常见,因为这可能意味着模型的融合更快。但是,它也可以学会依靠被告知正确的答案,并在实践中表现出一些不稳定。
根据概率,使用老师在某些时候训练是理想的选择。这称为计划采样。
(我计划添加选项)。
我可以使用预验证的单词嵌入(手套,cbow,skipgram等),而不是从头开始学习它们吗?
是的,您可以在Decoder类中使用load_pretrained_embeddings()方法。您也可以选择使用fine_tune_embeddings()方法微调(或不)。
在train.py中创建解码器后,您应该为load_pretrained_embeddings()以与word_map中相同的顺序堆叠。对于您没有预估计的向量的单词,例如<start> ,您可以像在init_weights()中一样随机初始化嵌入式。我建议您进行微调,以了解这些随机初始化的向量的更多有意义的向量。
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False另外,请确保将emb_dim参数从其当前值的512更改为预训练的嵌入式的大小。这应该自动调整解码器LSTM的输入大小以适应它们。
如何跟踪哪些张量允许计算梯度?
随着pytorch 0.4的释放,不再需要包装张量作为Variable S。取而代之的是,张量具有requires_grad属性,该属性决定是否由autograd跟踪,因此是否在反向传播过程中为其计算梯度。
requires_grad设置为False 。requires_grad设置为True 。torch.nn层的参数,已经将需要requires_grad设置为True 。在评估过程中,如何计算所有BLEU(IE BLEU-1至BLEU-4)得分?
您需要修改eval.py中的代码才能执行此操作。请参阅KMARIO23的这一出色答案,以进行清晰而详细的解释。


