a PyTorch Tutorial to Image Captioning
1.0.0
هذا هو البرنامج التعليمي Pytorch لتسمية الصورة .
هذا هو الأول في سلسلة من البرامج التعليمية التي أكتبها عن تطبيق النماذج الرائعة بمفردك مع مكتبة Pytorch المذهلة.
يُفترض أن المعرفة الأساسية للبيتورش ، والشبكات العصبية التلافيفية والمتكررة.
إذا كنت جديدًا على Pytorch ، فاحرص أولاً على التعلم العميق مع Pytorch: Blitz 60 دقيقة وتعلم Pytorch مع أمثلة.
يمكن نشر الأسئلة أو الاقتراحات أو التصحيحات كمشكلات.
أنا أستخدم PyTorch 0.4 في Python 3.6 .
27 يناير 2020 : تمت إضافة رمز العمل لبرامج تعليمية جديدة-ترجمة فائقة الدقة والآلة
موضوعي
المفاهيم
ملخص
تطبيق
تمرين
الاستدلال
الأسئلة المتداولة
لإنشاء نموذج يمكنه إنشاء تعليق وصفي لصورة نقدمها.
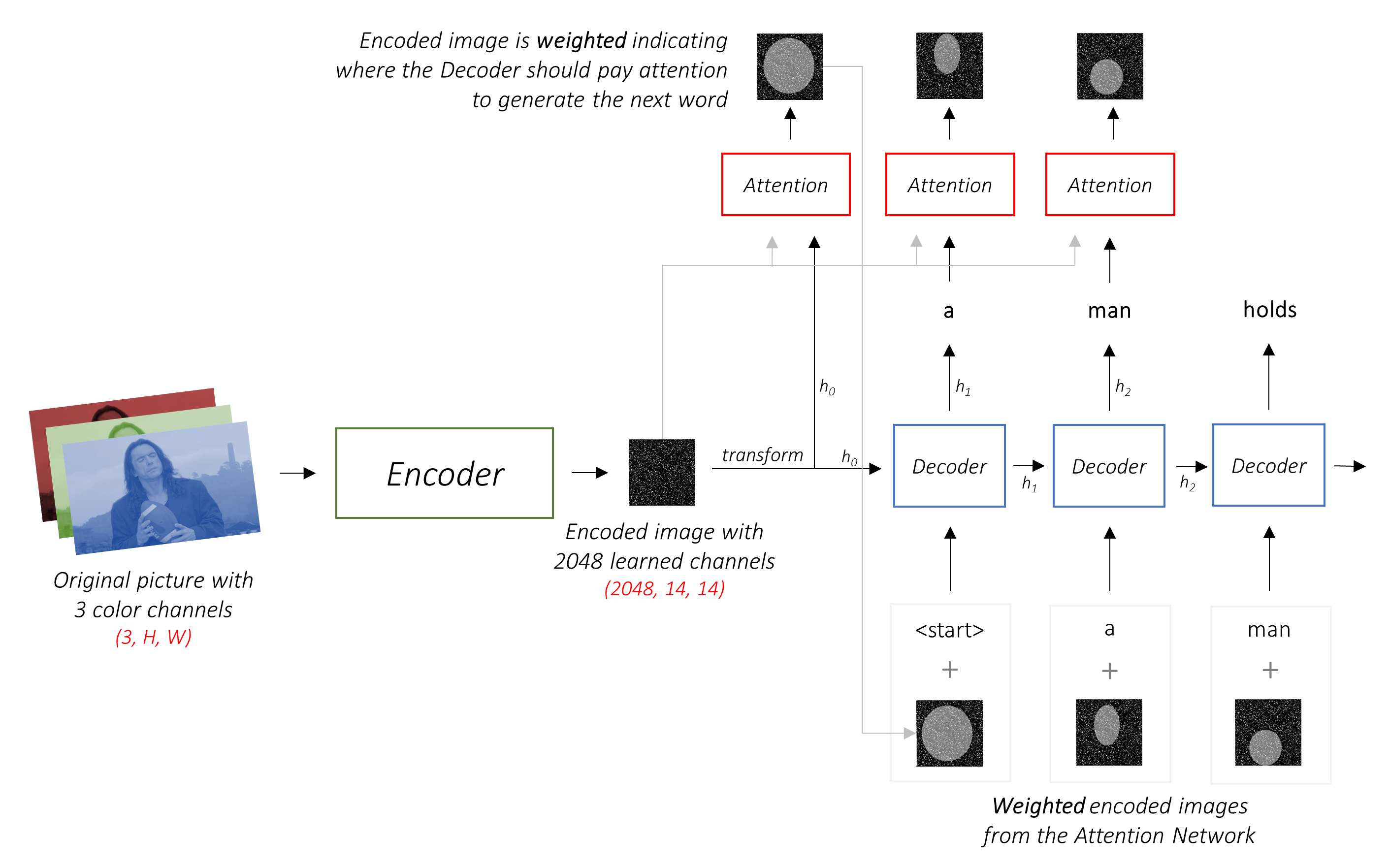
من أجل الحفاظ على الأشياء البسيطة ، دعنا ننفذ العرض والحضور وإخبار الورق. هذا ليس بأي حال من الأحوال على أحدث ما هو ، لكنه لا يزال مذهلاً للغاية. يمكن العثور على تطبيق المؤلفين الأصلي هنا.
هذا النموذج يتعلم مكان النظر.
عندما تقوم بإنشاء تعليق ، Word by Word ، يمكنك رؤية نظرة النموذج المتغيرة عبر الصورة.
هذا ممكن بسبب آلية الانتباه ، والتي تسمح لها بالتركيز على جزء من الصورة الأكثر صلة بالكلمة التي ستعمل عليها بعد ذلك.
فيما يلي بعض التسميات التوضيحية التي تم إنشاؤها على صور الاختبار التي لم يتم رؤيتها أثناء التدريب أو التحقق من الصحة:




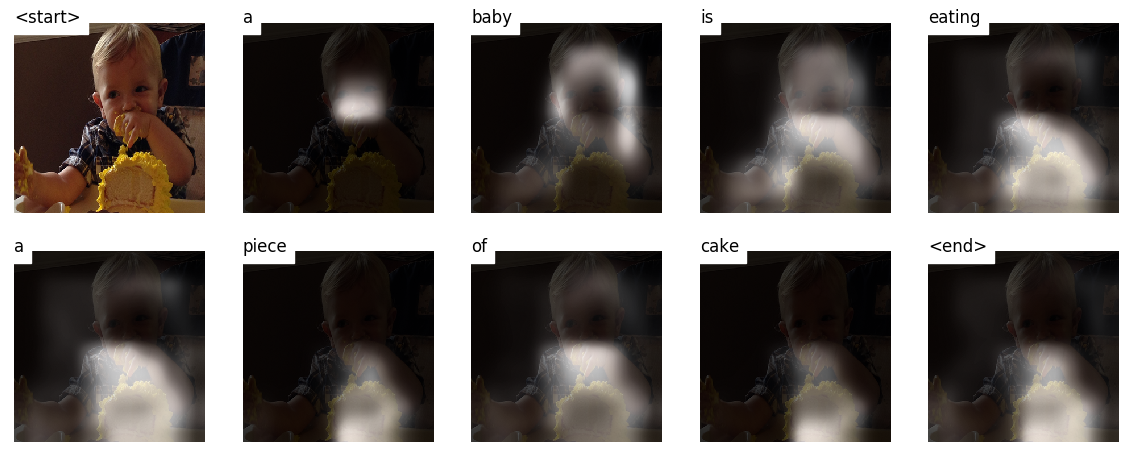

هناك المزيد من الأمثلة في نهاية البرنامج التعليمي.
التسمية التوضيحية للصور . دوه.
العمارة ترميز التشفير . عادةً ما يستخدم النموذج الذي ينشئ تسلسلات تشفيرًا لترميز الإدخال في نموذج ثابت وفك ترميز لفك تشفيره ، كلمة بالكلمة ، إلى تسلسل.
انتباه . إن استخدام شبكات الاهتمام واسعة الانتشار في التعلم العميق ، ولسبب وجيه. هذه طريقة لنموذج لاختيار فقط أجزاء الترميز التي تعتقد أنها ذات صلة بالمهمة المطروحة. يمكن استخدام نفس الآلية التي تراها المستخدمة هنا في أي نموذج حيث يكون لمخرج التشفير نقاط متعددة في الفضاء أو الوقت. في التسمية التوضيحية للصورة ، أنت تعتبر بعض وحدات البكسل أكثر أهمية من غيرها. بالتسلسل إلى مهام التسلسل مثل الترجمة الآلية ، فإنك تعتبر بعض الكلمات أكثر أهمية من غيرها.
نقل التعلم . هذا هو عندما تقترض من نموذج موجود باستخدام أجزاء منه في نموذج جديد. هذا دائمًا ما يكون أفضل من تدريب نموذج جديد من الصفر (أي ، لا تعرف شيئًا). كما سترى ، يمكنك دائمًا ضبط هذه المعرفة المستعملة للمهمة المحددة. إن استخدام تضمينات Word PretRained هو مثال غبي ولكنه صالح. بالنسبة لمشكلة تعليق الصور الخاصة بنا ، سنستخدم تشفيرًا مسبقًا ، ثم نتحمله حسب الحاجة.
بحث الشعاع . هذا هو المكان الذي لا تدع فيه وحدة فك ترميزك كسولًا واختيار الكلمات التي تحمل أفضل درجة في كل خطوة فك التشفير. يعد البحث عن الشعاع مفيدًا لأي مشكلة في نمذجة اللغة لأنه يجد التسلسل الأكثر أمانًا.
في هذا القسم ، سأقدم نظرة عامة على هذا النموذج. إذا كنت على دراية به بالفعل ، فيمكنك الانتقال مباشرة إلى قسم التنفيذ أو الرمز المعلق.
يشفر المشفر صورة الإدخال مع 3 قنوات ملونة في صورة أصغر مع قنوات "مستفادة" .
هذه الصورة المشفرة الأصغر هي تمثيل موجز لكل ما هو مفيد في الصورة الأصلية.
نظرًا لأننا نريد تشفير الصور ، فإننا نستخدم الشبكات العصبية التلافيفية (CNNs).
لا نحتاج إلى تدريب تشفير من الصفر. لماذا؟ لأن هناك بالفعل CNNs مدربة لتمثيل الصور.
لسنوات ، يقوم الناس ببناء نماذج جيدة بشكل غير عادي في تصنيف صورة إلى واحدة من ألف فئة. من المنطقي أن تلتقط هذه النماذج جوهر الصورة بشكل جيد للغاية.
لقد اخترت استخدام الشبكة المتبقية ذات الطبقات 101 المدربة على مهمة تصنيف ImageNet ، المتوفرة بالفعل في Pytorch. كما ذُكر سابقًا ، هذا مثال على التعلم النقل. لديك خيار صقله لتحسين الأداء.

تنشئ هذه النماذج تدريجياً تمثيلات أصغر وأصغر للصورة الأصلية ، وكل تمثيل لاحق أكثر "تعلم" ، مع عدد أكبر من القنوات. يبلغ حجم الترميز النهائي الذي ينتجه تشفير Resnet-101 14 × 14 مع قناة 2048 ، أي 2048, 14, 14 موتر الحجم.
أنا أشجعك على تجربة بنيات أخرى مدربة قبل التدريب. تستخدم الورقة vggnet ، كما تم تجهيزها أيضًا على ImageNet ، ولكن بدون ضبطها. في كلتا الحالتين ، التعديلات ضرورية. نظرًا لأن الطبقة الأخيرة أو اثنتين من هذه الطرز هي طبقات خطية مقرونة بتنشيط SoftMax للتصنيف ، فإننا نقوم بتجريدها بعيدًا.
تتمثل مهمة فك التشفير في النظر إلى الصورة المشفرة وإنشاء كلمة توضيحية بكلمة .
نظرًا لأنه يولد تسلسلًا ، يجب أن يكون شبكة عصبية متكررة (RNN). سوف نستخدم LSTM.
في إعداد نموذجي دون عناية ، يمكنك ببساطة متوسط الصورة المشفرة عبر جميع وحدات البكسل. يمكنك بعد ذلك إطعام هذا ، مع أو بدون تحول خطي ، في وحدة فك الترميز كأول حالة مخفية لها وتوليد التسمية التوضيحية. يتم استخدام كل كلمة متوقعة لإنشاء الكلمة التالية.
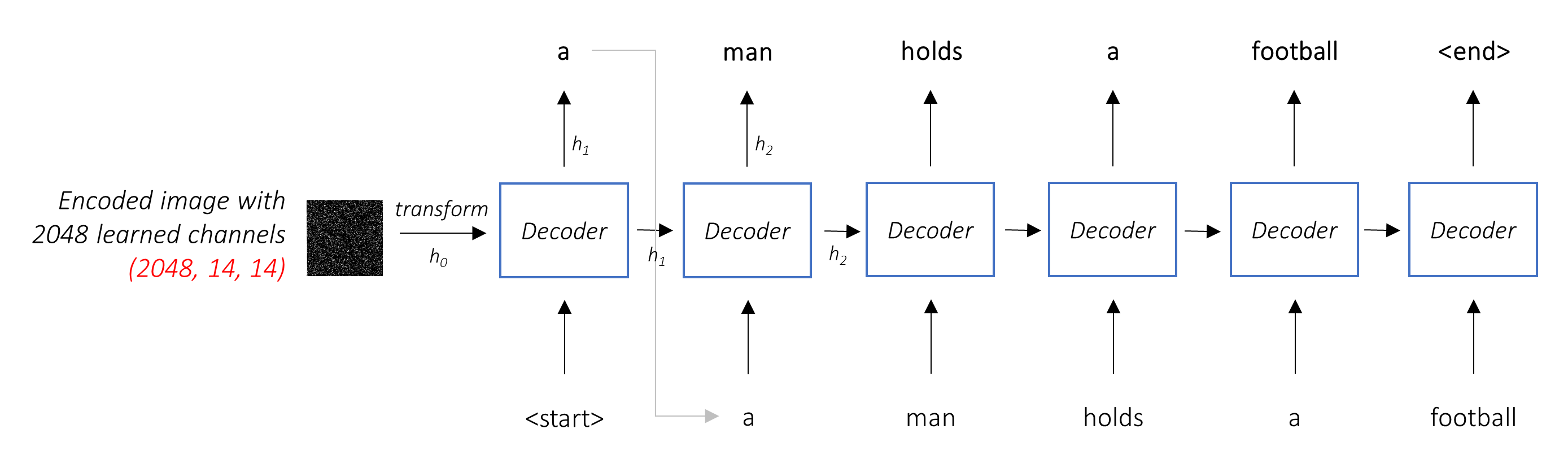
في إعداد مع الانتباه ، نريد أن يكون وحدة فك الترميز قادرة على النظر إلى أجزاء مختلفة من الصورة في نقاط مختلفة في التسلسل . على سبيل المثال ، أثناء توليد كلمة football في a man holds a football ، سيعرف وحدة فك الترميز التركيز عليها - لقد خمنت ذلك - كرة القدم!
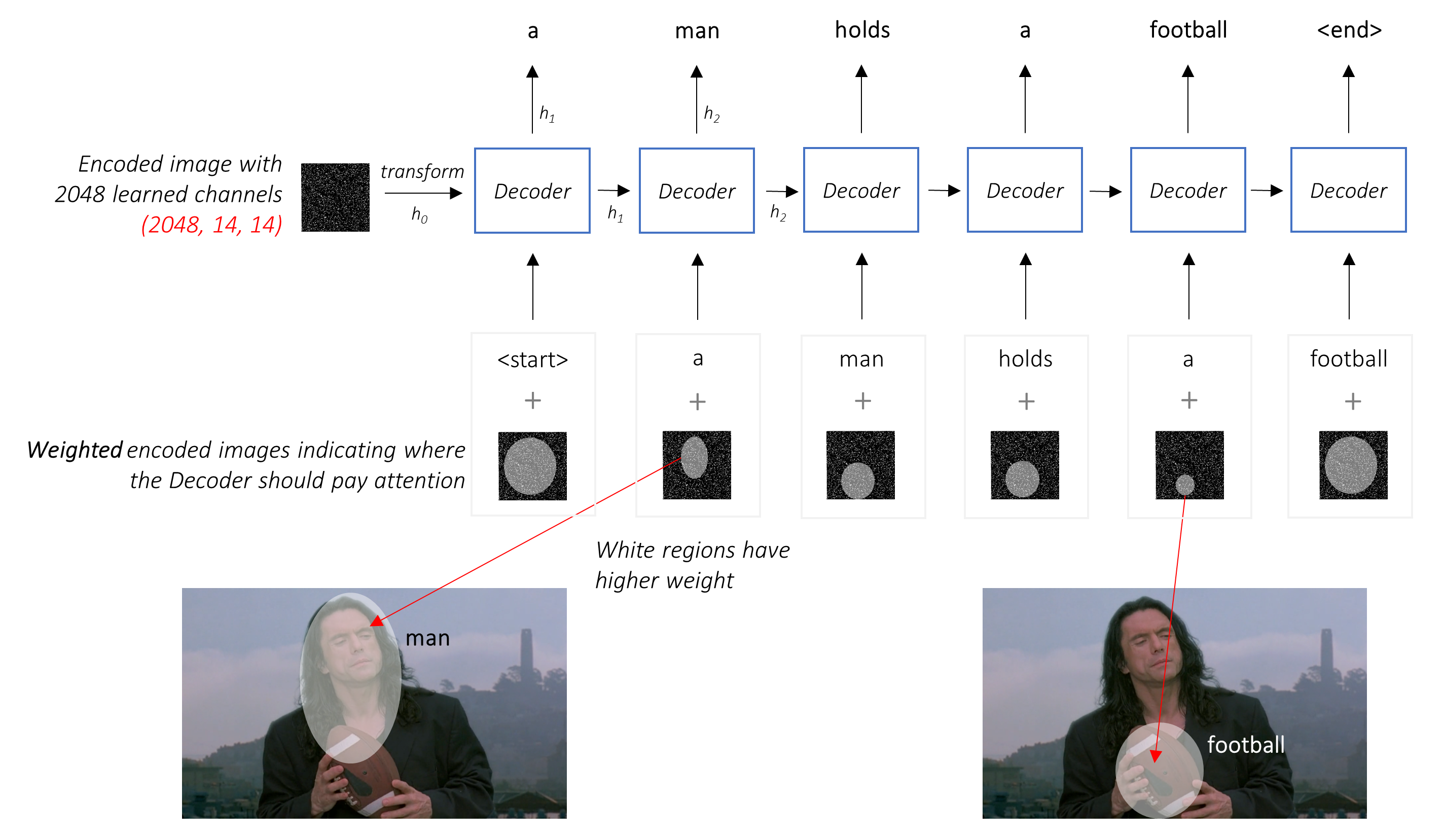
بدلاً من المتوسط البسيط ، نستخدم المتوسط المرجح في جميع وحدات البكسل ، مع أن أوزان البكسلات المهمة أكبر. يمكن تسلسل هذا التمثيل المرجح للصورة مع الكلمة التي تم إنشاؤها مسبقًا في كل خطوة لإنشاء الكلمة التالية.
شبكة الانتباه تحسب هذه الأوزان .
بشكل حدسي ، كيف يمكنك تقدير أهمية جزء معين من الصورة؟ ستحتاج إلى أن تكون على دراية بالتسلسل الذي أنشأته حتى الآن ، حتى تتمكن من النظر إلى الصورة وتحديد الاحتياجات التي تصف بعد ذلك. على سبيل المثال ، بعد ذكر a man ، من المنطقي إعلان أنه holding a football .
هذا هو بالضبط ما تفعله آلية الانتباه - فهي تعتبر التسلسل الناتج حتى الآن ، ويحضر إلى جزء من الصورة التي تحتاج إلى وصف بعد ذلك.
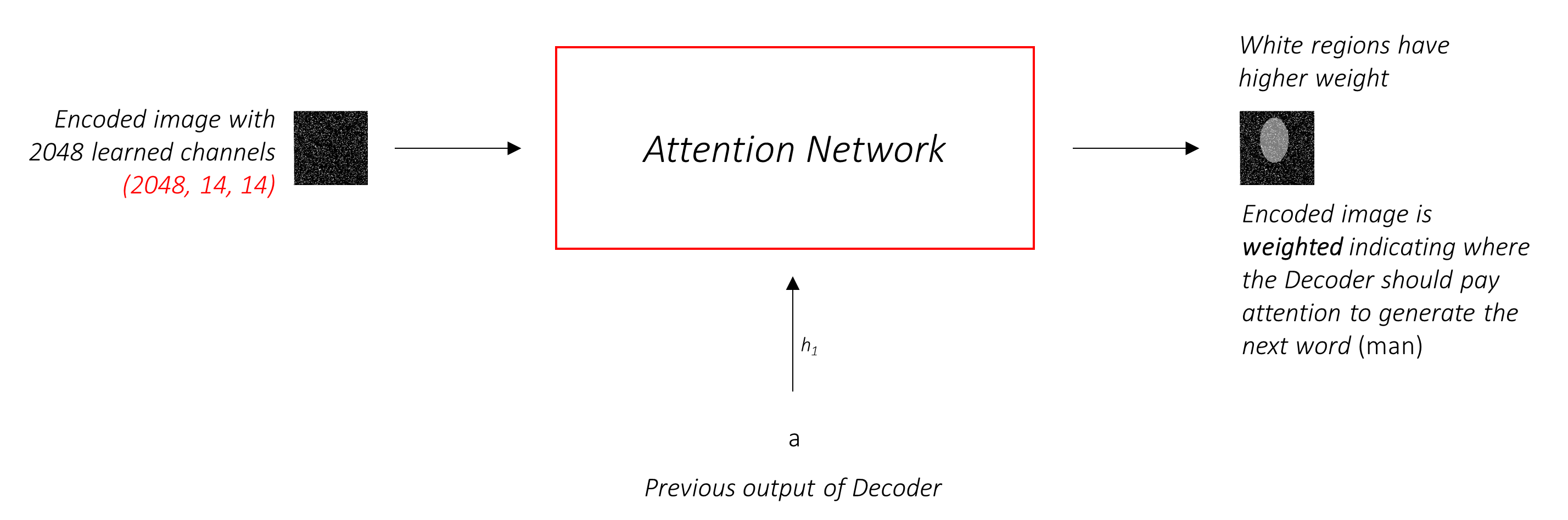
سوف نستخدم الاهتمام الناعم ، حيث تضيف أوزان البكسل إلى 1. إذا كان هناك بكسل P في صورتنا المشفرة ، ثم في كل timestep t -
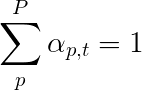
يمكنك تفسير هذه العملية برمتها على أنها حساب احتمال أن يكون البكسل هو المكان المناسب لإنشاء الكلمة التالية .
قد يكون من الواضح الآن كيف تبدو شبكتنا المدمجة.
h (وحالة الخلية C ) لفتحان LSTM.نستخدم طبقة خطية لتحويل إخراج وحدة فك الترميز إلى درجة لكل كلمة في المفردات.
سيكون الخيار المباشر - والجشع - هو اختيار الكلمة ذات أعلى درجة واستخدامها للتنبؤ بالكلمة التالية. ولكن هذا ليس الأمثل لأن بقية التسلسل يتوقف على تلك الكلمة الأولى التي تختارها. إذا لم يكن هذا الخيار هو الأفضل ، فكل ما يلي هو الأمثل. وهي ليست مجرد الكلمة الأولى - كل كلمة في التسلسل لها عواقب على تلك التي تنجح.
قد يحدث ذلك جيدًا إذا اخترت أفضل كلمة ثالثة في تلك الخطوة الأولى ، وثاني أفضل كلمة في الخطوة الثانية ، وهكذا ، فسيكون ذلك أفضل تسلسل يمكن أن تنشئه.
سيكون من الأفضل لو لم نتمكن من اتخاذ قرار بطريقة ما حتى انتهينا من فك التشفير تمامًا ، واختر التسلسل الذي يحمل أعلى درجة إجمالية من سلة من تسلسل المرشحين .
بحث الشعاع يفعل هذا بالضبط.
kk الثانية لكل من هذه k الأولى.k [الكلمة الأولى ، الكلمة الثانية] مجموعات النظر في الدرجات الإضافية.k الثانية من هذه الكلمات ، اختر الكلمات الثالثة k ، اختر Top k [الكلمة الأولى ، الكلمة الثانية ، الكلمة الثالثة].k ، اختر التسلسل بأفضل درجة إجمالية. 
كما ترون ، قد تفشل بعض التسلسلات (التي تم ضربها) مبكرًا ، لأنها لا تصل إلى أعلى k في الخطوة التالية. بمجرد إنشاء تسلسل k (تحتها خط) الرمز المميز <end> ، نختار النتيجة التي تحمل أعلى درجة.
تصف الأقسام أدناه بإيجاز التنفيذ.
من المفترض أن توفر بعض السياق ، ولكن من الأفضل فهم التفاصيل مباشرة من الكود ، الذي يتم التعليق عليه بشدة.
أنا أستخدم مجموعة بيانات MSCOCO '14. ستحتاج إلى تنزيل صور التدريب (13 جيجابايت) والتحقق من الصحة (6 جيجابايت).
سوف نستخدم تدريب Andrej Karpathy ، والتحقق من صحة ، واختبار الانقسامات. يحتوي ملف الرمز البريدي هذا على التسميات التوضيحية. ستجد أيضًا انشقاقات وتسميات توضيحية لمجموعات بيانات Flicker8K و Flicker30K ، لذلك لا تتردد في استخدامها بدلاً من mscoco إذا كان الأخير كبيرًا جدًا بالنسبة لجهاز الكمبيوتر الخاص بك.
سنحتاج إلى ثلاثة مدخلات.
نظرًا لأننا نستخدم تشفيرًا مسبقًا ، سنحتاج إلى معالجة الصور في النموذج الذي اعتاد هذا المشفر المسبق على ذلك.
نماذج ImageNet Pretrained متوفرة كجزء من وحدة torchvision الخاصة بـ Pytorch. تفاصيل هذه الصفحة تفاصيل المعالجة المسبقة أو التحول الذي نحتاجه إلى تنفيذ - يجب أن تكون قيم البكسل في النطاق [0،1] ويجب علينا بعد ذلك تطبيع الصورة من خلال الانحراف المعياري لقنوات RGB ImageNet.
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]أيضًا ، يتبع Pytorch اتفاقية NCHW ، مما يعني أن البعد القنوات (C) يجب أن يسبق أبعاد الحجم.
سنقوم بتغيير حجم جميع صور MSCOCO إلى 256x256 من أجل التوحيد.
لذلك ، يجب أن تكون الصور التي يتم تغذيتها للنموذج موترًا Float للبعد N, 3, 256, 256 ، ويجب تطبيعه بواسطة المتوسط المذكور والانحراف المعياري. N هو حجم الدُفعة.
التسميات التوضيحية هي الهدف ومدخلات وحدة فك الترميز حيث يتم استخدام كل كلمة لإنشاء الكلمة التالية.
لإنشاء الكلمة الأولى ، ومع ذلك ، نحتاج إلى كلمة Zeroth ، <start> .
في الكلمة الأخيرة ، يجب أن نتوقع <end> أن يتعلم وحدة فك الترميز التنبؤ بنهاية التسمية التوضيحية. هذا ضروري لأننا بحاجة إلى معرفة متى نتوقف عن فك التشفير أثناء الاستدلال.
<start> a man holds a football <end>
نظرًا لأننا نمرح التسميات التوضيحية حول الموترات ذات الحجم الثابت ، فإننا نحتاج إلى توصيل التسميات التوضيحية (والتي تكون بطبيعة الحال بطول متفاوت) بنفس الطول مع الرموز المميزة <pad> .
<start> a man holds a football <end> <pad> <pad> <pad>....
علاوة على ذلك ، نقوم بإنشاء word_map وهو رسم خرائط فهرس لكل كلمة في المجموعة ، بما في ذلك الرموز <start> و <end> و <pad> . يحتاج Pytorch ، مثل المكتبات الأخرى ، إلى كلمات مشفرة كمؤشرات للبحث عن التضمينات لهم أو لتحديد مكانها في درجات الكلمات المتوقعة.
9876 1 5 120 1 5406 9877 9878 9878 9878....
لذلك ، يجب أن تكون التسميات التوضيحية التي يتم تغذيتها إلى النموذج Int من البعد N, L حيث L هو الطول المبطن.
نظرًا لأن التسميات التوضيحية مبطنة ، سنحتاج إلى تتبع أطوال كل تعليق. هذا هو الطول الفعلي + 2 (لرموز <start> و <end> ).
تعد أطوال التسمية التوضيحية مهمة أيضًا لأنه يمكنك إنشاء رسوم بيانية ديناميكية باستخدام Pytorch. نقوم فقط بمعالجة تسلسل يصل إلى طوله ولا يضيعون حساب على <pad> s.
لذلك ، يجب أن تكون أطوال التسمية التوضيحية التي يتم تغذيتها للنموذج Int من البعد N
انظر create_input_files() في utils.py .
هذا يقرأ البيانات التي تم تنزيلها وحفظ الملفات التالية -
I, 3, 256, 256 Tensor ، حيث I عدد الصور في الانقسام. لا تزال قيم البكسل في النطاق [0 ، 255] ، ويتم تخزينها على أنها 8 Int غير موقعة.I N_c * ، حيث N_c هو عدد التسميات التوضيحية التي تم أخذ عينات منها لكل صورة. هذه التسميات التوضيحية هي في نفس ترتيب الصور في ملف HDF5. لذلك ، سوف تتوافق التسمية التوضيحية i th مع صورة i // N_c th.N_c * I القيمة i هي طول التسمية i ، والتي تتوافق مع صورة i // N_c th.word_map ، قاموس Word-to-Index. قبل أن نحفظ هذه الملفات ، لدينا خيار استخدام التسميات التوضيحية التي تكون أقصر فقط من العتبة ، وللحصول على كلمات أقل تواتراً في رمز <unk> .
نستخدم ملفات HDF5 للصور لأننا سنقرأها مباشرة من القرص أثناء التدريب / التحقق من الصحة. إنها ببساطة كبيرة جدًا بحيث لا تتناسب مع ذاكرة الوصول العشوائي في وقت واحد. لكننا نقوم بتحميل جميع التسميات التوضيحية وأطوالها في الذاكرة.
انظر CaptionDataset في datasets.py .
هذه فئة فرعية من Dataset Pytorch. إنه يحتاج إلى طريقة __len__ المحددة ، والتي تُرجع حجم مجموعة البيانات ، وطريقة __getitem__ التي تُرجع صورة i Th ، وتسمية التوضيح ، وطول التسمية التوضيحية.
نقرأ الصور من القرص ، وتحويل البيكسلات إلى [0،255] ، وتطبيعها داخل هذه الفئة.
سيتم استخدام Dataset بواسطة pytorch DataLoader في train.py .
انظر Encoder في models.py .
نحن نستخدم Resnet-101 المتاح بالفعل في وحدة torchvision الخاصة بـ Pytorch. تجاهل الطبقتين الأخيرتين (التجميع والطبقات الخطية) ، لأننا نحتاج فقط إلى تشفير الصورة ، وعدم تصنيفها.
نضيف طبقة AdaptiveAvgPool2d() لتغيير حجم الترميز إلى حجم ثابت . هذا يجعل من الممكن تغذية الصور ذات الحجم المتغير للمشفر. (ومع ذلك ، قمنا بتغيير حجم صور المدخلات الخاصة بنا إلى 256, 256 لأننا اضطررنا إلى تخزينها معًا كموتر واحد.)
نظرًا لأننا قد نرغب في ضبط التشفير ، فإننا نضيف طريقة fine_tune() تتيح أو تعطيل حساب التدرجات لمعلمات التشفير. نحن فقط الكتل التلافيفية التي نتحملها من 2 إلى 4 في RESNET ، لأن أول كتلة تلافيفية كانت ستتعلم عادة شيئًا أساسيًا للغاية لمعالجة الصور ، مثل الكشف عن الخطوط والحواف والمنحنيات ، وما إلى ذلك. نحن لا نعبث بالمؤسسات.
انظر Attention في models.py .
شبكة الانتباه بسيطة - إنها تتألف من طبقات خطية فقط واثنين من التنشيط.
تحول الطبقات الخطية المنفصلة كل من الصورة المشفرة (تم تسويتها إلى N, 14 * 14, 2048 ) والحالة المخفية (الإخراج) من وحدة فك الترميز إلى نفس البعد ، بمعنى. حجم الانتباه. ثم يتم إضافتها وتفعيلها. تحول الطبقة الخطية الثالثة هذه النتيجة إلى بُعد 1 ، حيث نطبق SoftMax لتوليد الأوزان alpha .
انظر DecoderWithAttention في models.py .
يتم استلام ناتج المشفر هنا ويتم تسويته إلى الأبعاد N, 14 * 14, 2048 . هذا مريح ويمنع الاضطرار إلى إعادة تشكيل الموتر عدة مرات.
نقوم بتهيئة الحالة المخفية والخلية لـ LSTM باستخدام الصورة المشفرة باستخدام طريقة init_hidden_state() ، والتي تستخدم طبقتين خطين منفصلتين.
في البداية ، نقوم بفرز الصور والتسميات N عن طريق تقليل أطوال التسمية التوضيحية . هذا حتى نتمكن من معالجة الأوقات الجيبية الصالحة فقط ، أي ، لا معالجة <pad> .
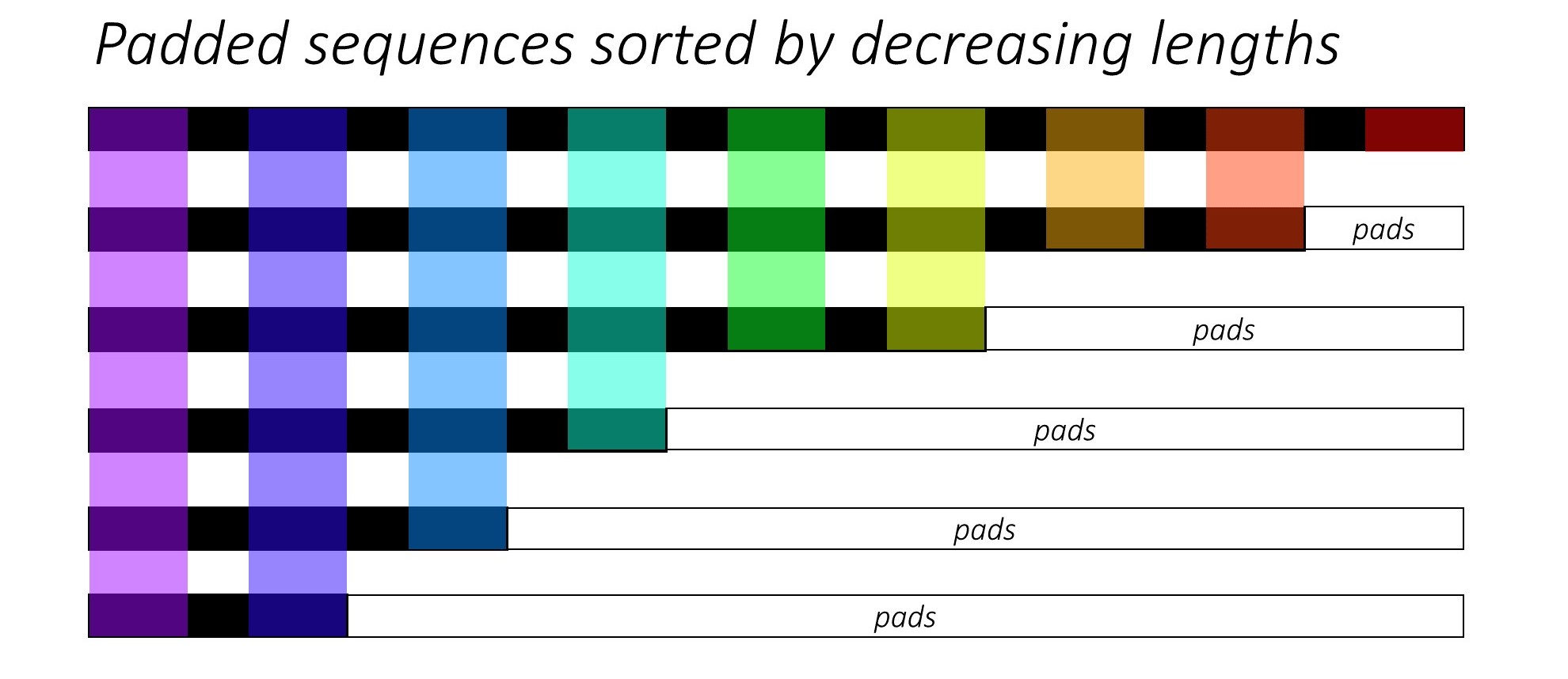
يمكننا التكرار على كل مدة زمنية ، معالجة المناطق الملونة فقط ، والتي هي حجم الدُفعة الفعال N_t في هذا الوقت. يسمح الفرز بأعلى N_t في أي Timestep للمحاذاة مع المخرجات من الخطوة السابقة. في Timestep الثالث ، على سبيل المثال ، نقوم بمعالجة أفضل 5 صور ، باستخدام أفضل 5 مخرجات من الخطوة السابقة.
يتم تنفيذ هذا التكرار يدويًا في for مع Pytorch LSTMCell بدلاً من التكرار تلقائيًا بدون حلقة مع Pytorch LSTM . وذلك لأننا بحاجة إلى تنفيذ آلية الانتباه بين كل خطوة فك تشفير. LSTMCell هي عملية TIMESTEP واحدة ، في حين أن LSTM سوف تتكرر عبر عدة مدة توقيت مستمر وتوفر جميع المخرجات في وقت واحد.
نقوم بحساب الأوزان والترميز المرجح في كل زمنية مع شبكة الانتباه. في القسم 4.2.1 من الورقة ، يوصون بتمرير الترميز المرجح من خلال مرشح أو بوابة . هذه البوابة عبارة عن تحويل خطي منشط Sigmoid للحالة المخفية السابقة لدلو. يذكر المؤلفون أن هذا يساعد شبكة الانتباه على التركيز بشكل أكبر على الكائنات في الصورة.
نقوم بتسلسل هذا الترميز المرشح للترفيه مع تضمين الكلمة السابقة ( <start> للبدء) ، وتشغيل LSTMCell لإنشاء الحالة المخفية الجديدة (أو الإخراج) . تقوم الطبقة الخطية بتحويل هذه الحالة المخفية الجديدة إلى عشرات لكل كلمة في المفردات ، والتي يتم تخزينها.
نقوم أيضًا بتخزين الأوزان التي يتم إرجاعها بواسطة شبكة الانتباه في كل زمنية. سترى لماذا قريبا بما فيه الكفاية.
قبل البدء ، تأكد من حفظ ملفات البيانات المطلوبة للتدريب والتحقق من الصحة والاختبار. للقيام بذلك ، قم بتشغيل محتويات create_input_files.py بعد توجيهها إلى ملف Karpathy JSON ومجلد الصورة الذي يحتوي على مجلدات train2014 و val2014 المستخرجة من البيانات التي تم تنزيلها.
انظر train.py .
توجد معلمات النموذج (وتدريبه) في بداية الملف ، بحيث يمكنك التحقق من أو تعديلها بسهولة إذا كنت ترغب في ذلك.
لتدريب النموذج الخاص بك من الصفر ، ما عليك سوى تشغيل هذا الملف -
python train.py
لاستئناف التدريب عند نقطة تفتيش ، أشر إلى الملف المقابل مع معلمة checkpoint في بداية الرمز.
لاحظ أننا نقوم بالتحقق من الصحة في نهاية كل فترة تدريب.
نظرًا لأننا نولد سلسلة من الكلمات ، فإننا نستخدم CrossEntropyLoss . تحتاج فقط إلى إرسال الدرجات الأولية من الطبقة النهائية في وحدة فك الترميز ، وستقوم وظيفة الخسارة بإجراء عمليات SoftMax و LOG.
يوصي مؤلفو الورقة باستخدام خسارة ثانية - " التنظيم العشوائي المضاعف ". نحن نعلم أن الأوزان تصل إلى 1 في زمن واحد معين. لكننا نشجع أيضًا الأوزان في بكسل واحد p لتلخيص 1 عبر جميع الأوقات الطوعية T -
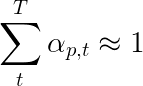
هذا يعني أننا نريد أن يحضر النموذج كل بكسل على مدار توليد التسلسل بأكمله. لذلك ، نحاول تقليل الفرق بين 1 ومجموع أوزان بكسل عبر جميع الأوقات الزمنية .
نحن لا نحسب الخسائر على المناطق المبطنة . تتمثل إحدى الطرق السهلة للتخلص من الفوط في استخدام Pytorch's pack_padded_sequence() ، والتي تضيء الموتر بواسطة Timestep مع تجاهل المناطق المبطنة. يمكنك الآن تجميع الخسارة على هذا الموتر المسطح.
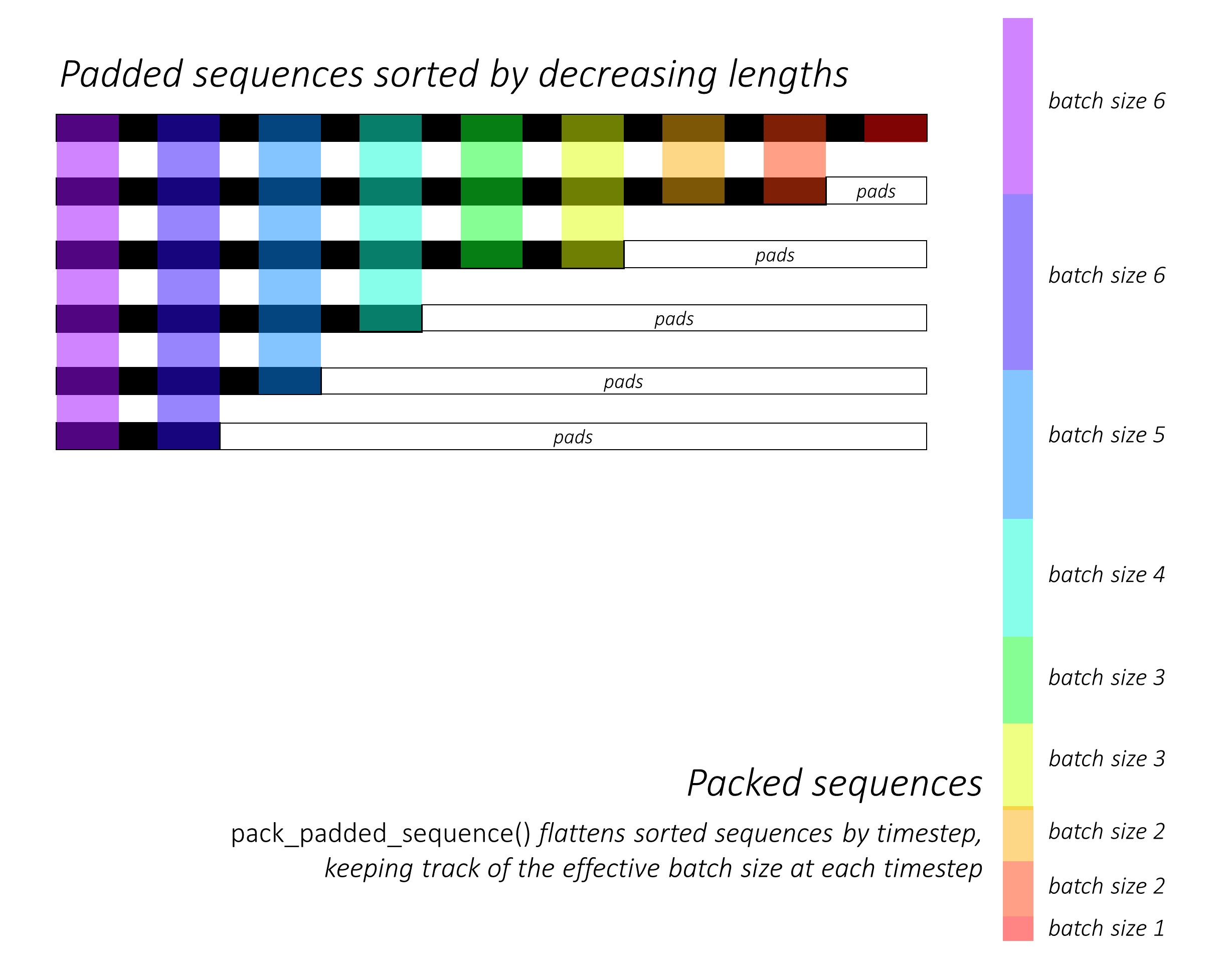
ملاحظة - يتم استخدام هذه الوظيفة فعليًا لأداء نفس التضمين الديناميكي (أي ، معالجة حجم الدُفعة الفعال فقط في كل زمن واحد) أجريناه في وحدة فك الترميز الخاصة بنا ، عند استخدام RNN أو LSTM في Pytorch. في هذه الحالة ، يتعامل Pytorch مع الرسوم البيانية ذات الطول المتغير الديناميكي داخليًا. يمكنك رؤية مثال في dynamic_rnn.py في برنامج البرنامج التعليمي الآخر حول وضع تسلسل. كنا قد استخدمنا هذه الوظيفة مع LSTM في وحدة فك الترميز الخاصة بنا إذا لم نكن نكرر يدويًا بسبب شبكة الانتباه.
لتقييم أداء النموذج في مجموعة التحقق من الصحة ، سنستخدم مقياس تقييم التقييم الثنائي اللغة (BLEU). هذا يقيم التسمية التوضيحية المولدة ضد التسمية التوضيحية المرجعية. لكل تعليق تم إنشاؤه ، سنستخدم جميع التسميات التوضيحية N_c المتاحة لتلك الصورة كتعليقات مرجعية.
يلاحظ مؤلفو العرض والحضور والورقة أن العلاقة بين الخسارة ونتيجة Bleu تنهار بعد نقطة ما ، لذلك يوصون بالتوقف عن التدريب في وقت مبكر عندما تبدأ درجة Bleu في التدهور ، حتى لو استمرت الخسارة في الانخفاض.
لقد استخدمت أداة Bleu المتاحة في وحدة NLTK.
لاحظ أن هناك انتقادات كبيرة لنتيجة Bleu لأنها لا ترتبط دائمًا بحكم الإنسان. أبلغ المؤلفون أيضًا عن نتائج النيزك لهذا السبب ، لكنني لم أقم بتطبيق هذا المقياس.
أوصيك بالتدريب على مراحل.
لقد تدربت لأول مرة فقط على وحدة فك الترميز ، أي دون ضبط التشفير ، بحجم دفعة 80 . لقد تدربت على 20 عصرًا ، وبلغت درجة Bleu-4 ذروتها عند حوالي 23.25 في العصر الثالث عشر. لقد استخدمت Optimizer Adam() مع معدل التعلم الأولي من 4e-4 .
واصلت من نقطة تفتيش الحقبة الثالثة عشرة مما يتيح صياغة التشفير مع حجم دفعة 32 . حجم الدُفعة الأصغر هو أن النموذج أكبر الآن لأنه يحتوي على تدرجات التشفير. مع صقل ، ارتفعت النتيجة إلى 24.29 في حوالي 3 عصر. من المحتمل أن يكون التدريب المستمر قد دفع النتيجة إلى أعلى قليلاً ، لكن اضطررت إلى ارتكاب وحدة معالجة الرسومات الخاصة بي في مكان آخر.
تمييز مهم لجعله هنا هو أنني ما زلت أقوم بتزويد الحقيقة الأرضية كمدخلات في كل خطوة فك الشفرة أثناء التحقق من الصحة ، بغض النظر عن الكلمة التي تم إنشاؤها آخر . وهذا ما يسمى المعلم إجبار . في حين أن هذا شائع الاستخدام أثناء التدريب لتسريع العملية ، كما نفعل ، يجب أن تحاكي الظروف أثناء التحقق من الصحة ظروف الاستدلال الحقيقية قدر الإمكان. لم أقم بتطبيق الاستدلال المكثف بعد - حيث يتم إنشاء كل كلمة في التسمية التوضيحية من الكلمة التي تم إنشاؤها مسبقًا ، وينتهي عند ضرب الرمز المميز <end> .
نظرًا لأن أنا معلمي أثناء التحقق من الصحة ، فإن درجة Bleu المقاسة أعلاه على التسميات التوضيحية الناتجة لا تعكس الأداء الحقيقي. في الواقع ، فإن درجة Bleu عبارة عن مقياس مصمم لمقارنة التسميات التوضيحية التي تم إنشاؤها بشكل طبيعي بتسميات التوضيح الأرضية ذات الطول المتنوع. بمجرد تنفيذ الاستدلال المكثف ، لا يوجد أي معلم يفرض ، فإن التوقف المبكر بنتيجة Bleu سيكون "مناسبًا" حقًا.
مع وضع ذلك في الاعتبار ، استخدمت eval.py لحساب درجات BLEU-4 الصحيحة من نقطة تفتيش النموذج هذه على مجموعات التحقق من الصحة واختبارها دون فرض المعلم ، بأحجام مختلفة من الشعاع-
| حجم الشعاع | التحقق من الصحة bleu-4 | اختبار bleu-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
تكون درجة الاختبار أعلى من النتيجة في الورقة ، ويمكن أن تكون بسبب كيفية تحديد المآسيويات لدينا Bleu ، وحقيقة أنني استخدمت مشفر Resnet ، وضبط التشفير في الواقع-حتى لو كان قليلًا.
تذكر أيضًا-عند ضبطه أثناء التعلم النقل ، من الأفضل دائمًا استخدام معدل التعلم أصغر بكثير مما كان يستخدم في الأصل لتدريب النموذج المقترض. وذلك لأن النموذج محسن تمامًا ، ولا نريد تغيير أي شيء بسرعة كبيرة. لقد استخدمت Adam() للمشفر أيضًا ، ولكن مع معدل تعلم 1e-4 ، وهو عُشر القيمة الافتراضية لهذا المُحسن.
على Titan X (Pascal) ، استغرق الأمر 55 دقيقة لكل عصر دون ضبطه ، و 2.5 ساعة مع صقلها بأحجام الدفع المذكورة.
يمكنك تنزيل هذا النموذج المسبق و word_map المقابل هنا.
لاحظ أنه يجب تحميل نقطة التفتيش هذه مباشرة باستخدام pytorch ، أو تم نقلها إلى caption.py - انظر أدناه.
انظر caption.py .
أثناء الاستدلال ، لا يمكننا استخدام طريقة forward() مباشرة في وحدة فك الترميز لأنها تستخدم فرض المعلم. بدلاً من ذلك ، سنحتاج فعليًا إلى إطعام الكلمة التي تم إنشاؤها مسبقًا إلى LSTM في كل زمنية .
caption_image_beam_search() يقرأ صورة ، وترميزها ، ويطبق الطبقات في وحدة فك الترميز بالترتيب الصحيح ، أثناء استخدام الكلمة التي تم إنشاؤها مسبقًا كمدخل إلى LSTM في كل زمنتيب. كما أنه يتضمن البحث عن الشعاع.
يمكن استخدام visualize_att() لتصور التسمية التوضيحية التي تم إنشاؤها مع الأوزان في كل زمنية كما هو موضح في الأمثلة.
لتسمية التوضيح صورة من سطر الأوامر ، تشير إلى الصورة ، ونقطة تفتيش النموذج ، وخريطة الكلمات (واختياريا ، حجم الحزمة) على النحو التالي -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
بدلاً من ذلك ، استخدم الوظائف في الملف حسب الحاجة.
انظر أيضًا eval.py ، والتي تنفذ هذه العملية لحساب درجة Bleu على مجموعة التحقق من الصحة ، مع أو بدون البحث عن شعاع.





اختبار Turing Tommy - أنت تعرف أن الذكاء الاصطناعى ليس منظمة العفو الدولية حقًا لأنه لم يشاهد الغرفة ولا يتعرف على العظمة عندما يراها.

قلت الاهتمام الناعم . هل هناك ، أم ، اهتمام شاق ؟
نعم ، يستخدم العرض والحضور والورق كلا المتغيرات ، ويؤدي وحدة فك الترميز مع الاهتمام "الصعب" بشكل أفضل بشكل هامشي.
في الاهتمام الناعم ، الذي نستخدمه هنا ، تقوم بحساب الأوزان alpha واستخدام المتوسط المرجح للميزات عبر جميع وحدات البكسل. هذه عملية حتمية واختلاف.
في الاهتمام الشاق ، تختار فقط أخذ عينات من بعض وحدات البكسل من التوزيع الذي حدده alpha . لاحظ أن أي أخذ عينات احتمالية من هذا القبيل غير محددة أو عشوائي ، أي لن يؤدي إدخال معين دائمًا إلى أن ينتج نفس الإخراج. ولكن نظرًا لأن الهبوط التدريجي يفترض أن الشبكة حتمية (وبالتالي يمكن اختلافها) ، يتم إعادة صياغة أخذ العينات لإزالة العشوائية. معرفتي بهذا السطحية إلى حد ما في هذه المرحلة - سأقوم بتحديث هذه الإجابة عندما يكون لدي فهم أكثر تفصيلاً.
كيف يمكنني استخدام شبكة انتباه لمهمة NLP مثل تسلسل إلى نموذج التسلسل؟
مثلما كنت تستخدم CNN لإنشاء ترميز مع ميزات في كل بكسل ، يمكنك استخدام RNN لإنشاء ميزات مشفرة في كل موضع كلمة IE Timestep في الإدخال.
بدون اهتمام ، يمكنك استخدام إخراج المشفر في آخر Timestep كترميز للجمل بأكملها ، لأنه سيحتوي أيضًا على معلومات من Timesteps السابقة. يحمل آخر إخراج المشفر الآن عبء الاضطرار إلى تشفير الجملة بأكملها بشكل مفيد ، وهو أمر غير سهول ، خاصة بالنسبة للجمل الأطول.
مع الاهتمام ، ستحضر الأوقات الزمنية في ناتج المشفر ، وتوليد أوزان لكل Timestep/Word ، واتخاذ المتوسط المرجح لتمثيل الجملة. في تسلسل إلى تسلسل مهمة مثل ترجمة الآلة ، ستحضر الكلمات ذات الصلة في الإدخال أثناء إنشاء كل كلمة في الإخراج.
يمكنك أيضا استخدام الانتباه دون فك التشفير. على سبيل المثال ، إذا كنت ترغب في تصنيف النص ، فيمكنك الالتحاق بالكلمات المهمة في الإدخال مرة واحدة فقط لأداء التصنيف.
هل يمكننا استخدام بحث الشعاع أثناء التدريب؟
ليس مع وظيفة الخسارة الحالية ، ولكن نعم. هذا ليس شائعًا على الإطلاق.
ما هو إجبار المعلم؟
إن إجبار المعلم هو عندما نستخدم التسميات التوضيحية لـ Ground Truth كمدخلات إلى وحدة فك الترميز في كل زمنية ، وليس الكلمة التي تم إنشاؤها في Timestep السابقة. من الشائع أن يكون لقوة المعلم أثناء التدريب لأنه قد يعني تقاربًا أسرع للنموذج. ولكن يمكن أن يتعلم أيضًا الاعتماد على الإجابة الصحيحة ، ويظهر بعض عدم الاستقرار في الممارسة.
سيكون من المثالي أن يتدرب على استخدام المعلم الذي يجبر بعض الوقت فقط ، بناءً على احتمال. وهذا ما يسمى أخذ العينات المجدولة.
(أخطط لإضافة الخيار).
هل يمكنني استخدام تضمينات الكلمات المسبقة (القفاز ، CBOW ، Skipgram ، إلخ) بدلاً من تعلمها من الصفر؟
نعم ، يمكنك ، باستخدام طريقة load_pretrained_embeddings() في فئة وحدة Decoder . يمكنك أيضًا اختيار ضبطها (أو لا) باستخدام طريقة fine_tune_embeddings() .
بعد إنشاء وحدة فك الترميز في train.py ، يجب عليك توفير المتجهات المسبقة إلى load_pretrained_embeddings() مكدسة بنفس الترتيب كما في word_map . بالنسبة للكلمات التي ليس لديك متجهات مسبقة ، مثل <start> ، يمكنك تهيئة التضمينات بشكل عشوائي كما فعلنا في init_weights() . أوصي بالضبط لمعرفة المتجهات الأكثر أهمية لهذه المتجهات التي تم تهيئتها بشكل عشوائي.
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False تأكد أيضًا من تغيير معلمة emb_dim من قيمتها الحالية البالغة 512 إلى حجم تضميناتك التي تم تدريبك مسبقًا. يجب أن يعدل هذا تلقائيًا حجم إدخال LSTM Decoder لإقامةها.
كيف يمكنني تتبع أي موترات تسمح بحساب التدرجات؟
مع إطلاق Pytorch 0.4 ، لم يعد التغليف Variable كمتغير S مطلوبًا. بدلاً من ذلك ، لدى Tensors سمة requires_grad ، والتي تقرر ما إذا كانت تتبعها بواسطة autograd ، وبالتالي ما إذا كانت التدرجات يتم حسابها لها أثناء التراجع.
requires_grad على False .requires_grad على True .torch.nn بالفعل تعيين requires_grad على True .كيف يمكنني حساب كل درجات Bleu (IE Bleu-1 إلى Bleu-4) أثناء التقييم؟
ستحتاج إلى تعديل الكود في eval.py للقيام بذلك. يرجى الاطلاع على هذه الإجابة الممتازة من قبل Kmario23 للحصول على شرح واضح ومفصل.


