a PyTorch Tutorial to Image Captioning
1.0.0
Это учебник Pytorch для подписания изображения .
Это первый в серии учебных пособий, которые я пишу о внедрении классных моделей самостоятельно с удивительной библиотекой Pytorch.
Предполагается базовые знания о питорх, сверточных и повторяющихся нейронных сетях.
Если вы новичок в Pytorch, сначала прочитайте Deep Learning с помощью Pytorch: 60 -минутный блиц и изучение питорха с примерами.
Вопросы, предложения или исправления могут быть опубликованы в качестве вопросов.
Я использую PyTorch 0.4 в Python 3.6 .
27 января 2020 года : был добавлен рабочий код для двух новых учебных пособий-супер-разрешение и машинный перевод
Цель
Концепции
Обзор
Выполнение
Обучение
Вывод
Часто задаваемые вопросы
Чтобы создать модель, которая может генерировать описательную подпись для изображения, которое мы его предоставляем.
В интересах обеспечения проста, давайте внедрим шоу, посетим и расскажем бумагу. Это ни в коем случае не является текущим современным, но все еще чертовски удивительно. Оригинальную реализацию авторов можно найти здесь.
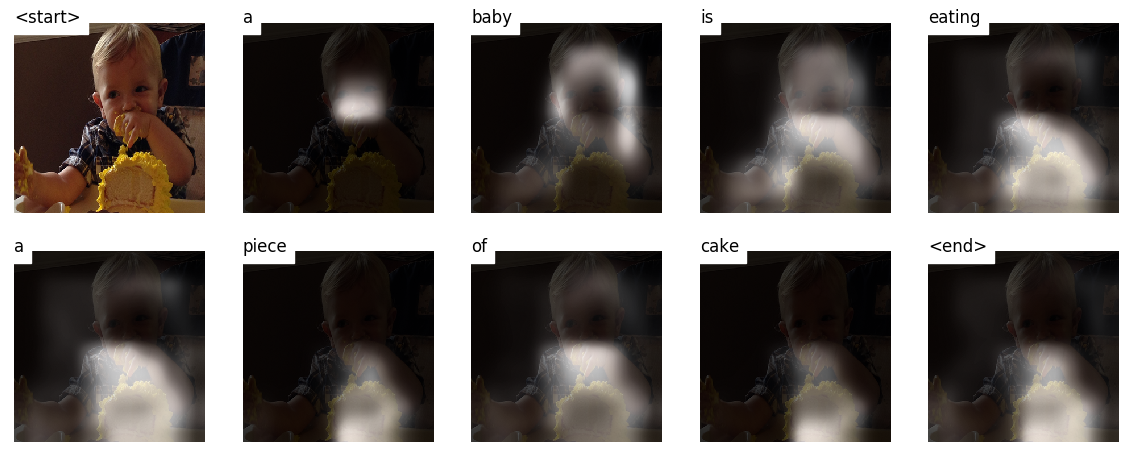
Эта модель узнает , где искать.
Когда вы генерируете заголовок, Word By Word, вы можете увидеть, как взгляд модели смещается по изображению.
Это возможно из -за его механизма внимания , который позволяет ему сосредоточиться на части изображения, наиболее подходящего для слова, которое оно произнесет дальше.
Вот несколько подписей, сгенерированных на тестовых изображениях, не наблюдаемых во время обучения или проверки:





В конце учебника есть больше примеров.
Подпись изображения . дух
Энкодер-декодер архитектура . Как правило, модель, которая генерирует последовательности, будет использовать энкодер для кодирования ввода в фиксированную форму и декодер, чтобы декодировать его, слово по слову, в последовательность.
Внимание . Использование сетей внимания широко распространено по глубокому обучению, и по уважительной причине. Это способ для модели выбирать только те части кодирования, которые, по ее мнению, имеют отношение к поставленной задаче. Тот же механизм, который вы видите, используемый здесь, можно использовать в любой модели, где вывод энкодера имеет несколько точек в пространстве или времени. В подписи изображения вы считаете некоторые пиксели более важными, чем другие. В последовательности к последовательности задач, как машинный перевод, вы рассматриваете некоторые слова более важными, чем другие.
Передача обучения . Это когда вы одолжите из существующей модели, используя ее части в новой модели. Это почти всегда лучше, чем тренировать новую модель с нуля (т.е. ничего не зная). Как вы увидите, вы всегда можете точно настроить это знание подержанного от конкретной задачи. Использование предварительно подготовленных вторжений слов является глупым, но достоверным примером. Для нашей проблемы подписания изображения мы будем использовать предварительно проведенный кодировщик, а затем настраивать его по мере необходимости.
Лучший поиск . Здесь вы не позволяете своему декодеру быть ленивыми и просто выбирать слова с наилучшей оценкой на каждом шаге декодирования. Поиск луча полезен для любой проблемы с моделированием языка, потому что он находит наиболее оптимальную последовательность.
В этом разделе я представим обзор этой модели. Если вы уже знакомы с этим, вы можете пропустить прямо в раздел реализации или комментированный код.
Энкодер кодирует входное изображение с 3 цветными каналами в меньшее изображение с «изученными» каналами .
Это меньшее кодированное изображение является кратким представлением всего, что полезно в исходном изображении.
Поскольку мы хотим кодировать изображения, мы используем сверточные нейронные сети (CNN).
Нам не нужно тренировать энкодер с нуля. Почему? Потому что уже есть CNN, обученные представлять изображения.
В течение многих лет люди строили модели, которые чрезвычайно хороши в классификации изображения в одну из тысяч категорий. Способствует причине, что эти модели очень хорошо отражают суть изображения.
Я решил использовать 101 многоуровневую остаточную сеть, обученную задаче классификации ImageNet , уже доступной в Pytorch. Как указывалось ранее, это пример обучения передачи. У вас есть возможность настройки его для повышения производительности.

Эти модели постепенно создают меньшие и меньшие представления исходного изображения, и каждое последующее представление является более «изученным», с большим количеством каналов. Последняя кодировка, созданная нашим энкодером RESNET-101, имеет размер 14x14 с 2048 каналами, т. Е. Тензор размером 2048, 14, 14 .
Я призываю вас экспериментировать с другими предварительно обученными архитектурами. В статье используется VGGNET, также предварительно подготовленный на ImageNet, но без точной настройки. В любом случае, модификации необходимы. Поскольку последний или два из этих моделей - это линейные слои в сочетании с активацией SoftMax для классификации, мы лишаем их.
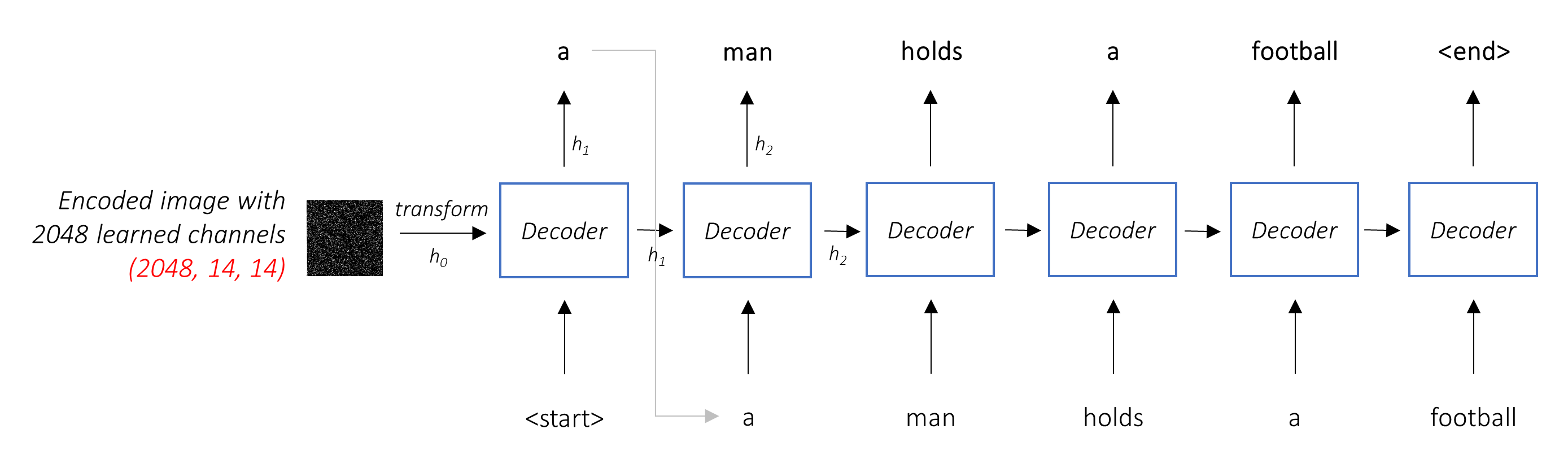
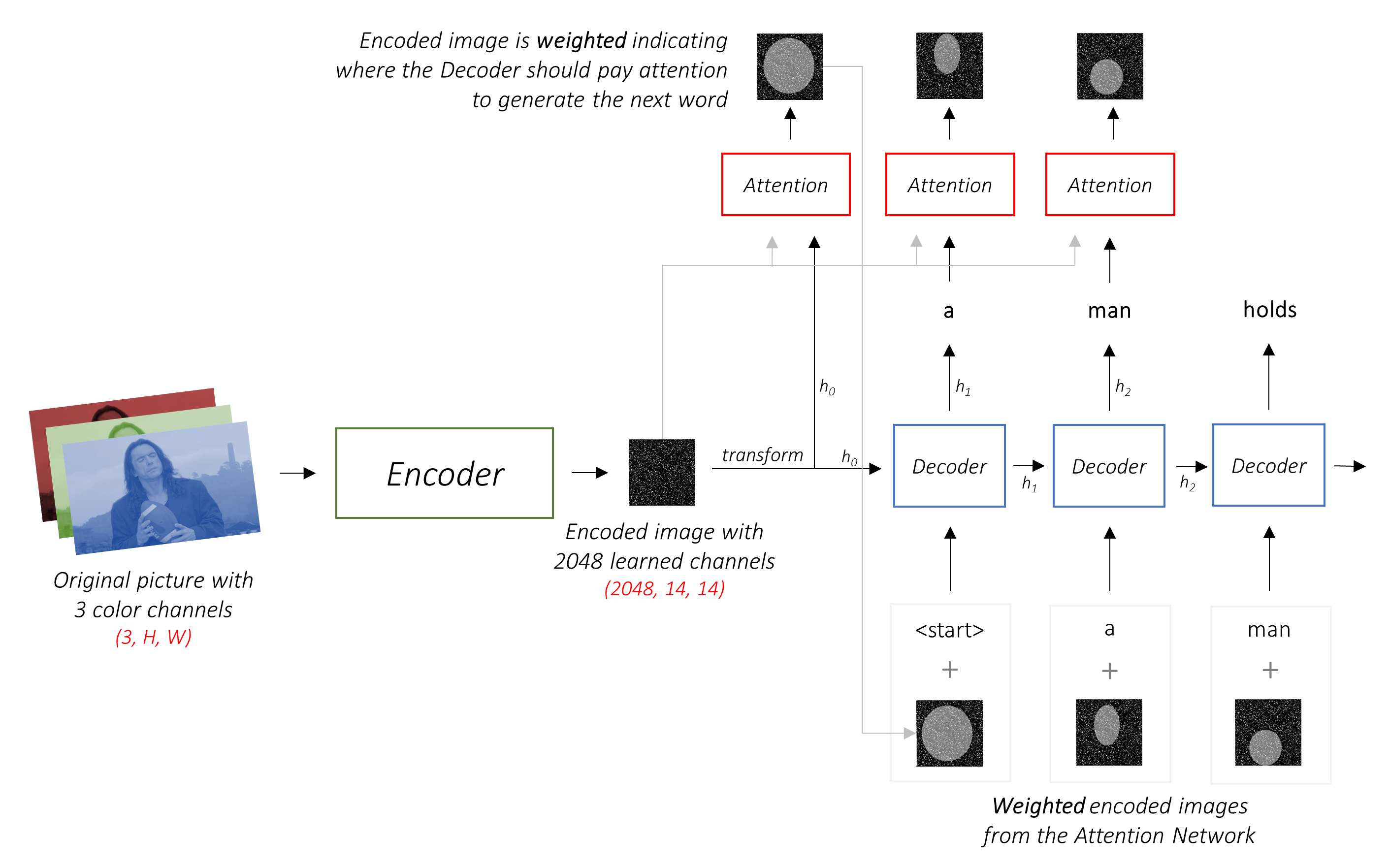
Работа декодера состоит в том, чтобы взглянуть на кодированное изображение и генерировать слово под подписью по слову .
Поскольку он генерирует последовательность, она должна быть повторяющейся нейронной сетью (RNN). Мы будем использовать LSTM.
В типичной настройке без внимания вы можете просто усреднить кодированное изображение по всем пикселям. Затем вы можете подавать это с линейным преобразованием или без него, в декодер в качестве первого скрытого состояния и генерировать подпись. Каждое предсказанное слово используется для генерации следующего слова.
В обстановке с вниманием мы хотим, чтобы декодер мог смотреть на разные части изображения в разных точках последовательности . Например, в то время как генерируя слово football в a man holds a football , декодер знал бы, чтобы сосредоточиться - как вы уже догадались - футбол!
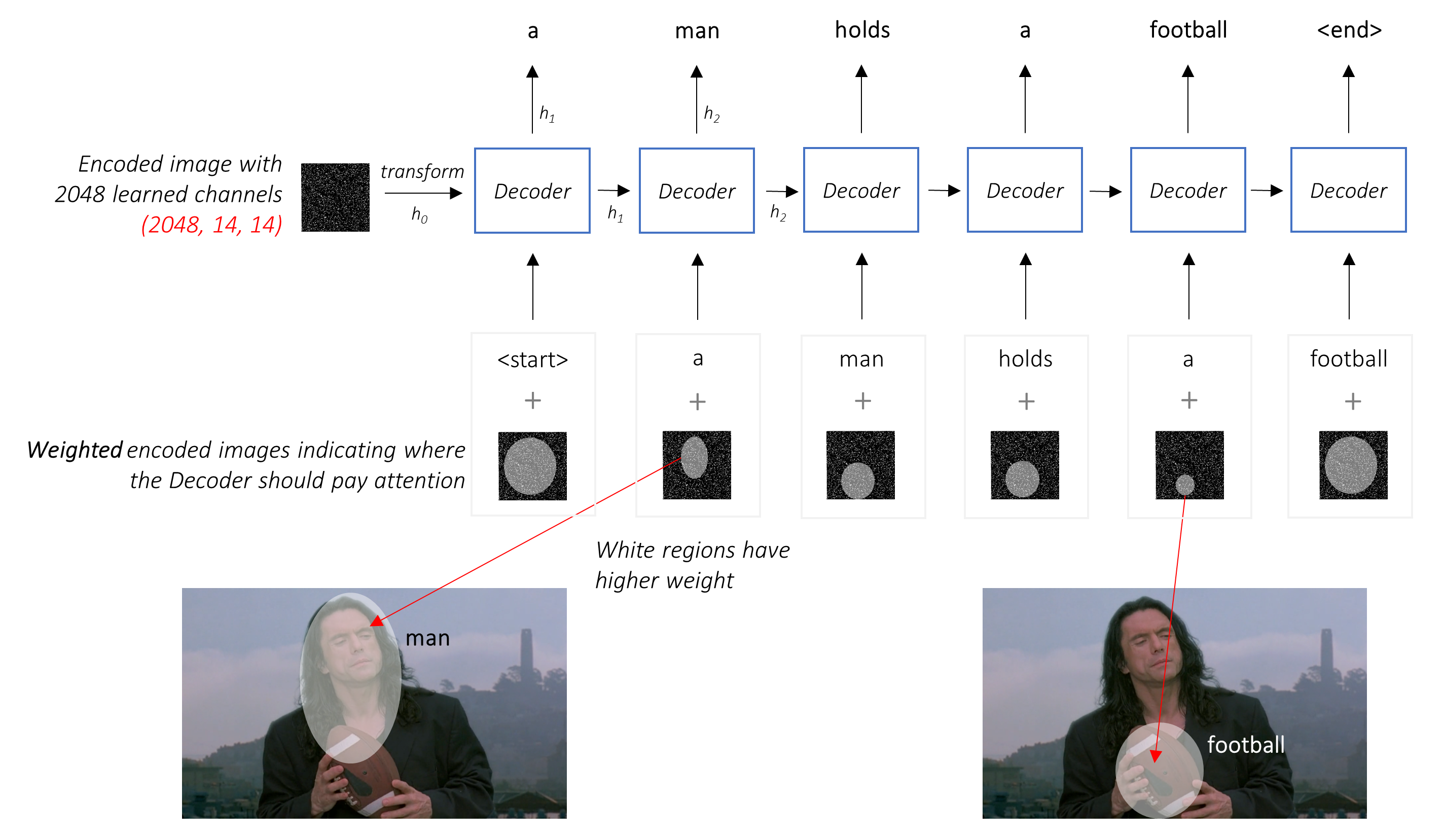
Вместо простого среднего мы используем средневзвешенное по всей пикселях, причем вес важных пикселей больше. Это взвешенное представление изображения может быть объединено с ранее сгенерированным словом на каждом шаге для создания следующего слова.
Сеть внимания вычисляет эти веса .
Интуитивно, как бы вы оценили важность определенной части изображения? Вам нужно знать о последовательности, которую вы сгенерировали до сих пор , чтобы вы могли посмотреть на изображение и решить, какие потребности описывают дальше. Например, после того, как вы упомяните a man , логично заявить, что он holding a football .
Это именно то, что делает механизм внимания - он учитывает полученную последовательность до сих пор, и относится к той части изображения, который нуждается в описании следующего.
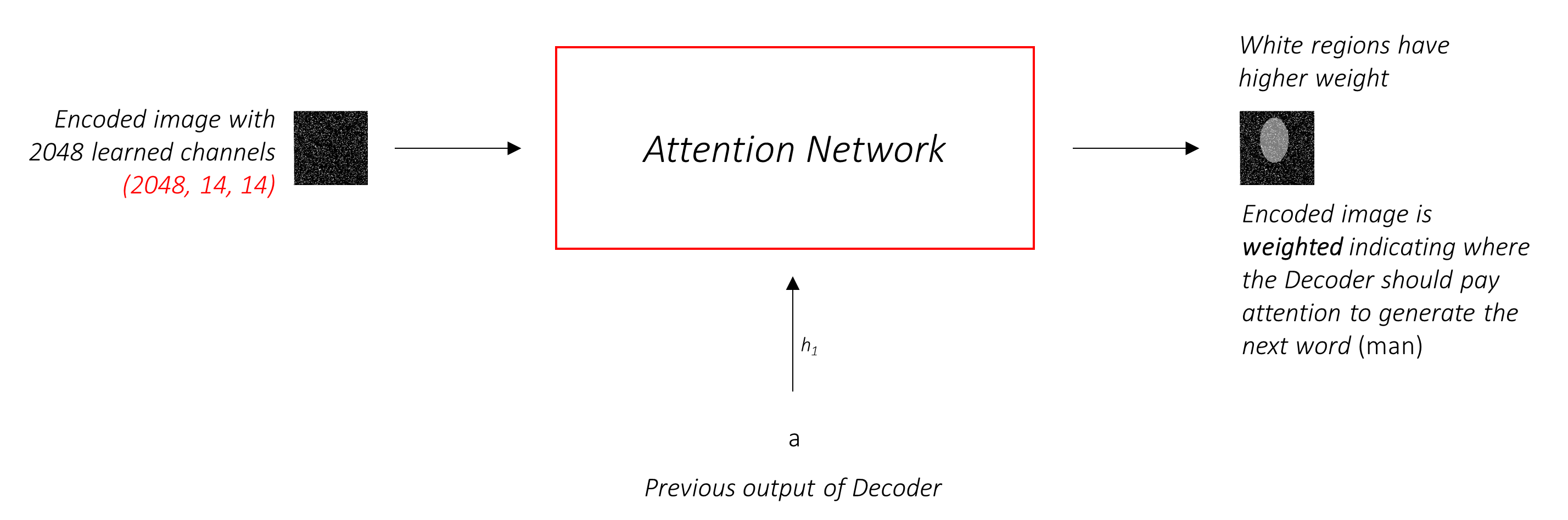
Мы будем использовать мягкое внимание, где веса пикселей складываются до 1. Если в нашем кодированном изображении есть P пикселей, то при каждом временном разделе t -
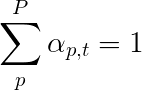
Вы можете интерпретировать весь этот процесс как вычисление вероятности того, что пиксель - это место , где можно было бы создать следующее слово .
Теперь может быть ясно, как выглядит наша комбинированная сеть.
h (и состояние C ) для декодера LSTM.Мы используем линейный слой, чтобы преобразовать вывод декодера в счет для каждого слова в словаре.
Простой - и жадный - вариант - выбрать слово с самым высоким баллом и использовать его для прогнозирования следующего слова. Но это не оптимально, потому что остальная часть последовательности зависит от того первого слова, которое вы выбираете. Если этот выбор не самый лучший, все, что следует, является неоптимальным. И это не только первое слово - каждое слово в последовательности имеет последствия для тех, кто преуспевает его.
Вполне может случиться так, что если бы вы выбрали третье лучшее слово на этом первом шаге и второе лучшее слово на втором этапе, и так далее ... это будет лучшая последовательность, которую вы могли бы генерировать.
Было бы лучше, если бы мы не могли каким -то образом решать, пока не закончим полностью декодировать, и выбрать последовательность, которая имеет самый высокий общий балл из корзины последовательностей кандидатов .
Поиск луча делает именно это.
kk вторые слова для каждого из k первых слов.k [первое слово, второе слово], рассматривающие аддитивные оценки.k второго слова выберите k третьи слова, выберите Top k [первое слово, второе слово, третье слово].k -последовательности завершится, выберите последовательность с наилучшим общим баллом. 
Как вы можете видеть, некоторые последовательности (вычеркнутые) могут потерпеть неудачу рано, так как они не добираются до вершины k на следующем шаге. Как только k -последовательности (подчеркнутые) генерируют токен <end> , мы выбираем тот, который с самым высоким баллом.
В разделах ниже кратко описываются реализация.
Они предназначены для предоставления некоторого контекста, но детали лучше всего понимаются непосредственно из кода , что довольно много прокомментировано.
Я использую набор данных MSCOCO '14. Вам нужно будет загрузить изображения обучения (13 ГБ) и валидации (6 ГБ).
Мы будем использовать обучение, валидацию и тесты Андрея Карпати. Этот zip -файл содержит подписи. Вы также найдете разделы и подписи для наборов данных Flicker8K и Flicker30K, поэтому не стесняйтесь использовать их вместо MSCOCO, если последний слишком большой для вашего компьютера.
Нам понадобится три входа.
Поскольку мы используем предварительно проведенный энкодер, нам нужно было бы обработать изображения в форму, к которому привык этот предварительно предварительный энкодер.
Предварительные модели ImageNet, доступные как часть модуля torchvision от Pytorch. На этой странице подробно описывается предварительная обработка или преобразование, которую мы должны выполнить - значения пикселей должны быть в диапазоне [0,1], и затем мы должны нормализовать изображение по среднему и стандартному отклонениям RGB -каналов ImageNet.
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]Кроме того, Pytorch следует соглашению NCHW, что означает, что размер каналов (C) должно предшествовать размерам.
Мы изменим размер всех изображений MSCOCO до 256x256 для единообразия.
Следовательно, изображения, подаваемые на модель, должны быть тензором Float измерения N, 3, 256, 256 , и должны быть нормализованы вышеупомянутым средним и стандартным отклонением. N - это размер партии.
Подписи являются как целью, так и входными данными декодера, поскольку каждое слово используется для генерации следующего слова.
Однако, чтобы сгенерировать первое слово, нам нужно слово нужен , <start> .
В последнем словом мы должны предсказать <end> Декодер должен научиться предсказывать конец подписи. Это необходимо, потому что нам нужно знать, когда прекратить декодирование во время вывода.
<start> a man holds a football <end>
Поскольку мы передаем подписи в виде тензоров фиксированного размера, нам необходимо подготовить подписи (которые естественным образом имеют различную длину) до той же длины с токенами <pad> .
<start> a man holds a football <end> <pad> <pad> <pad>....
Кроме того, мы создаем word_map , который является индексным отображением для каждого слова в корпусе, включая токены <start> , <end> и <pad> . Pytorch, как и другие библиотеки, нуждаются в словах, закодированных как индексы, чтобы искать встраивания для них или идентифицировать их место в прогнозируемых оценках слов.
9876 1 5 120 1 5406 9877 9878 9878 9878....
Следовательно, подписи, поданные на модель, должны быть Int измерения N, L где L - мягкая длина.
Поскольку надписей мягкие, нам нужно будет отслеживать длину каждого заголовка. Это фактическая длина + 2 (для токенов <start> и <end> .
Длина заголовка также важна, потому что вы можете создавать динамические графики с помощью Pytorch. Мы обрабатываем только последовательность до его длины и не тратим вычисления на <pad> s.
Следовательно, длина подписи, подаваемая на модель, должна быть Int измерения N .
См. create_input_files() в utils.py .
Это читает загруженные данные и сохраняет следующие файлы -
I, 3, 256, 256 Tensor , где I - количество изображений в разделении. Значения пикселя все еще находятся в диапазоне [0, 255] и хранятся в виде 8-битных 8-битных Int .N_c * I , где N_c - это количество подписей, выбранных на изображение. Эти подписи находятся в том же порядке, что и изображения в файле HDF5. Следовательно, i будет соответствовать изображению i // N_c .N_c * I i - это длина i , которая соответствует изображению i // N_c .word_map , словарь Word-To-Index. Прежде чем мы сохраним эти файлы, у нас есть возможность использовать только подписи, которые короче порога, и для того, чтобы бин менее частые слова в токен <unk> .
Мы используем файлы HDF5 для изображений, потому что мы будем читать их непосредственно с диска во время обучения / проверки. Они просто слишком большие, чтобы вписаться в оперативную память одновременно. Но мы загружаем все подписи и их длину в память.
См. CaptionDataset в datasets.py .
Это подкласс Dataset Pytorch. Это нужен определенный метод __len__ , который возвращает размер набора данных, и метод __getitem__ , который возвращает i , заголовок и длина подписи.
Мы читаем изображения с диска, конвертируем пиксели в [0,255] и нормализуем их в этом классе.
Dataset будет использоваться Pytorch DataLoader в train.py для создания и подачи партий данных в модель для обучения или проверки.
См. Encoder в models.py .
Мы используем предварительно проведенный Resnet-101, уже доступный в модуле torchvision от Pytorch. Отбросьте последние два слоя (объединение и линейные слои), поскольку нам нужно только кодировать изображение, а не классифицировать его.
Мы добавляем слой AdaptiveAvgPool2d() , чтобы изменить размер кодирования до фиксированного размера . Это позволяет питать изображения размера переменной в энкодер. (Однако мы изменили размер наших входных изображений до 256, 256 потому что нам пришлось хранить их вместе как один тензор.)
Поскольку мы можем захотеть точно настроить энкодер, мы добавляем метод fine_tune() , который позволяет или отключает расчет градиентов для параметров кодера. Мы только настраивались только на сверточные блоки с 2 по 4 в Resnet , потому что первый сверточный блок обычно узнал бы что-то очень фундаментальное для обработки изображений, например, обнаружение линий, краев, кривых и т. Д. Мы не связываемся с фондами.
См. Attention в models.py .
Сеть внимания проста - она состоит из только линейных слоев и пары активаций.
Отдельные линейные слои преобразуют как закодированное изображение (сглаженное до N, 14 * 14, 2048 ), так и скрытое состояние (выход) от декодера в одно и то же измерение , а именно. размер внимания. Затем они добавляются и активируются. Третий линейный слой преобразует этот результат в размер 1 , после чего мы применяем Softmax для генерации alpha -весов.
См. DecoderWithAttention в models.py .
Выход энкодера получен здесь и сглаживается до размеров N, 14 * 14, 2048 . Это просто удобно и предотвращает изменение тензора несколько раз.
Мы инициализируем скрытое состояние и ячейку LSTM, используя кодированное изображение с помощью метода init_hidden_state() , который использует два отдельных линейных слоя.
В самом начале мы сортируем N -изображения и подписи, уменьшая длины подписи . Это так, что мы можем обрабатывать только действительные временные рамки, то есть не обрабатывать <pad> s.
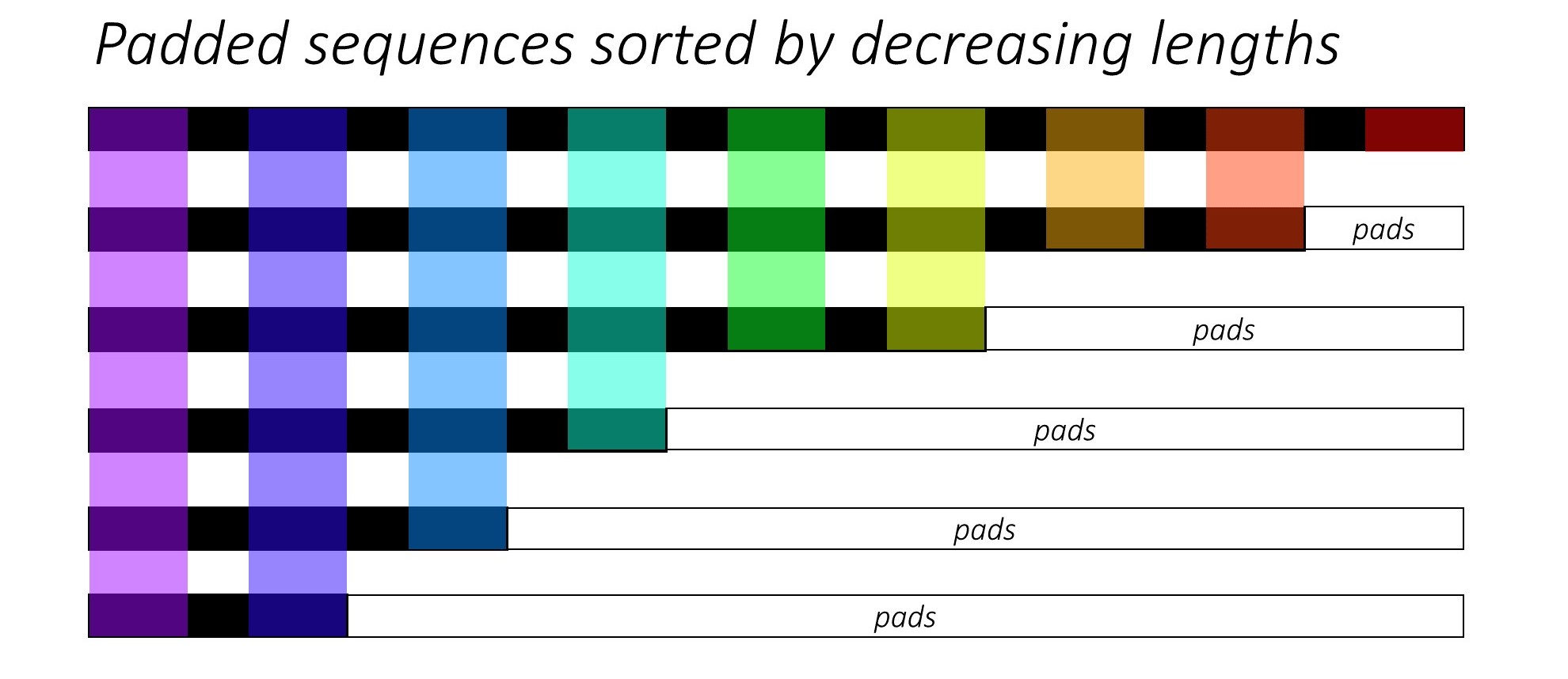
Мы можем итерации по каждому временному депутату, обрабатывая только цветные области, которые являются эффективным размером партии N_t в этом временном разделе. Сортировка позволяет верхнему N_t при любом временном шаге соответствовать выходам с предыдущего шага. Например, в третьем времени мы обрабатываем только 5 лучших изображений, используя 5 лучших выходов с предыдущего шага.
Эта итерация выполняется вручную в for с Pytorch LSTMCell вместо итерации автоматически без петли с LSTM Pytorch. Это потому, что нам нужно выполнить механизм внимания между каждым шагом декодирования. LSTMCell - это единая операция TimeStep, тогда как LSTM постоянно выполняет несколько временных точек и обеспечивает все выходы одновременно.
Мы вычисляем веса и взвешенные с вниманием кодирование в каждом временном разделе с сетью внимания. В разделе 4.2.1 статьи они рекомендуют передавать взвешенное внимание кодирование через фильтр или ворота . Эти ворота представляет собой сигмоидное линейное преобразование предыдущего скрытого состояния декодера. Авторы утверждают, что это помогает сети внимания уделять больше внимания объектам на изображении.
Мы объединяем этот фильтрованный взвешенные внимания кодирование с внедрением предыдущего слова ( <start> ) и запускаем LSTMCell для генерации нового скрытого состояния (или вывода) . Линейный слой превращает это новое скрытое состояние в оценки для каждого слова в словаре , который хранится.
Мы также храним веса, возвращаемые сетью внимания в каждом временном разделе. Вы поймете, почему достаточно скоро.
Прежде чем начать, обязательно сохраните необходимые файлы данных для обучения, проверки и тестирования. Для этого запустите содержимое create_input_files.py после указания его в файл hass karpathy и папку изображения, содержащая папки извлеченного train2014 и val2014 из ваших загруженных данных.
Смотрите train.py .
Параметры для модели (и обучения ее) находятся в начале файла, поэтому вы можете легко проверить или изменить их, если хотите.
Чтобы обучить свою модель с нуля , просто запустите этот файл -
python train.py
Чтобы возобновить обучение на контрольно -пропускной пункте , укажите на соответствующий файл с параметром checkpoint в начале кода.
Обратите внимание, что мы выполняем проверку в конце каждой эпохи обучения.
Поскольку мы генерируем последовательность слов, мы используем CrossEntropyLoss . Вам нужно только отправить необработанные оценки из окончательного уровня в декодере, и функция потерь выполнит операции Softmax и журнал.
Авторы статьи рекомендуют использовать вторую потерю - « вдвойне стохастическую регуляризацию ». Мы знаем, что веса суммы до 1 при данном времени. Но мы также поощряем веса на одном пикселе p чтобы суммировать до 1 во всех временных точках T -
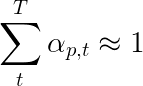
Это означает, что мы хотим, чтобы модель занималась каждым пикселем в течение всей создания всей последовательности. Поэтому мы стараемся минимизировать разницу между 1 и суммой весов пикселя во всех временных точках .
Мы не вычисляем потери в мягких областях . Легкий способ избавиться от подушек - это использовать pytorch's pack_padded_sequence() , который выравнивает тензор путем временного тома, игнорируя мягкие области. Теперь вы можете собрать потерю по сравнению с этим сплющенным тензором.
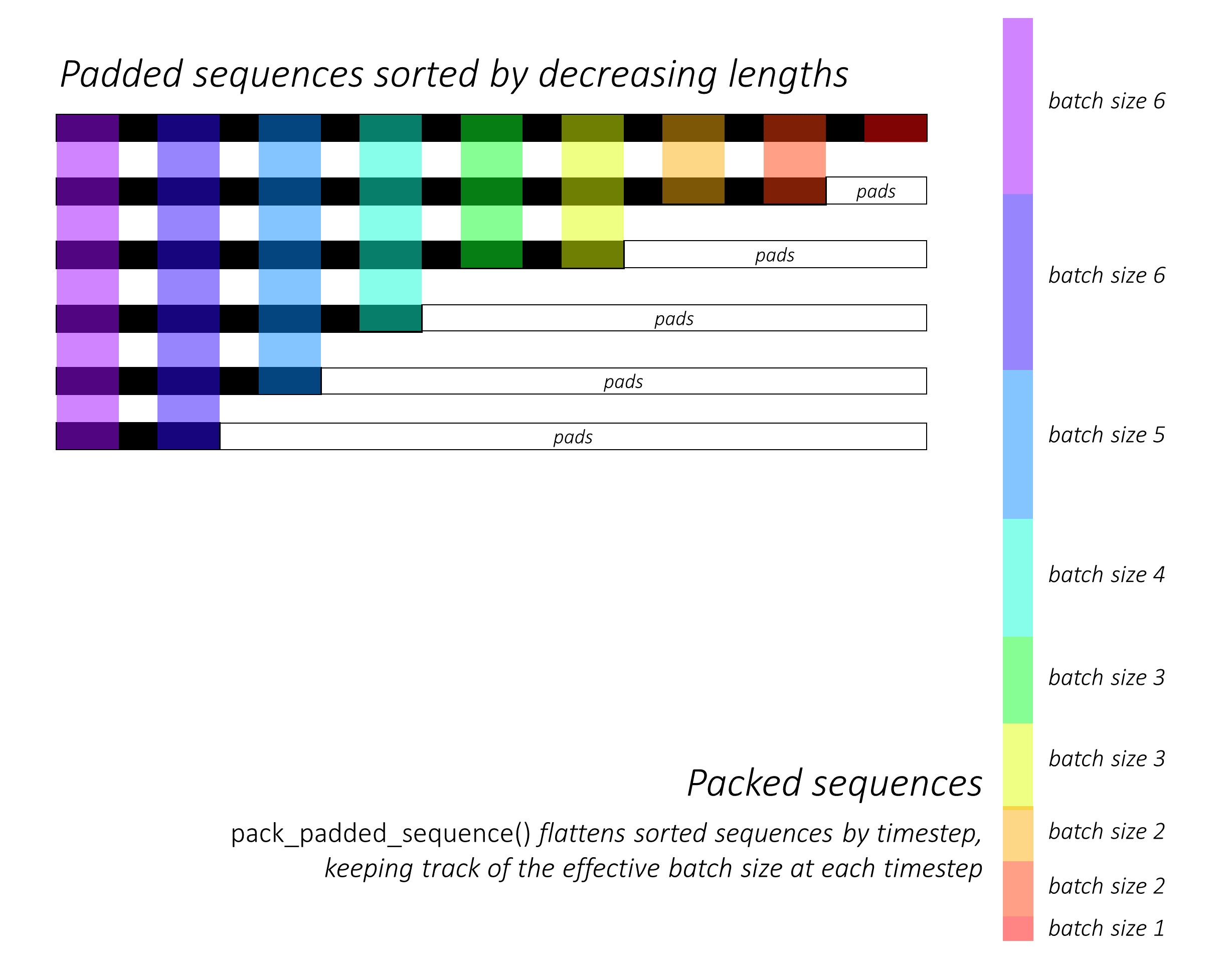
Примечание - эта функция фактически используется для выполнения того же динамического пакета (то есть обработка только эффективного размера партии в каждом временном разделе), который мы выполняли в нашем декодере, при использовании RNN или LSTM в Pytorch. В этом случае Pytorch обрабатывает динамические графики переменной длины внутри. Вы можете увидеть пример в dynamic_rnn.py в моем другом уроке по маркировке последовательности. Мы бы использовали эту функцию вместе с LSTM в нашем декодере, если бы мы не были вручную итерационными из -за сети внимания.
Чтобы оценить производительность модели в наборе проверки, мы будем использовать автоматическую двуязычную оценку оценки (BLEU). Это оценивает сгенерированную подпись против справочной подписи. Для каждой сгенерированной подписи мы будем использовать все подписи N_c , доступные для этого изображения в качестве ссылок.
Авторы шоу, посещают и сообщают Paper, наблюдая, что корреляция между потерей и оценкой BLEU разрушается после точки, поэтому они рекомендуют прекратить тренировки на раннем этапе, когда оценка Bleu начинает ухудшаться, даже если потеря продолжает уменьшаться.
Я использовал инструмент Bleu, доступный в модуле NLTK.
Обратите внимание, что существует значительная критика оценки BLEU, потому что он не всегда хорошо коррелирует с человеческим суждением. По этой причине авторы также сообщают о метеоре, но я не реализовал эту метрику.
Я рекомендую вам тренироваться поэтапно.
Впервые я тренировал только декодер, т.е. без точной настройки энкодера, с размером партии 80 . Я тренировался в течение 20 эпох, и оценка Bleu-4 достигла своего пика на уровне около 23.25 в 13-й эпохе. Я использовал оптимизатор Adam() с начальной скоростью обучения 4e-4 .
Я продолжил с 13-й эпохи контрольной точки, позволяя тонкой настройке энкодера с размером партии 32 . Меньший размер партии заключается в том, что модель теперь больше, потому что она содержит градиенты энкодера. С точной настройкой, счет вырос до 24.29 в почти 3 эпохах. Продолжение обучения, вероятно, подтолкнуло бы счет немного выше, но мне пришлось совершить свой графический процессор в другом месте.
Важным различием для проведения здесь является то, что я все еще поставляю землю в качестве ввода на каждом шаге декодирования во время проверки, независимо от того, что слово «последнее» . Это называется учителем . Хотя это обычно используется во время обучения для ускорения процесса, как мы делаем, условия во время проверки должны как можно больше имитировать условия вывода. Я еще не внедрил пакетный вывод - где каждое слово в подписи генерируется из ранее сгенерированного слова и заканчивается при ударе по токену <end> .
Поскольку я принимаю учитель во время проверки, оценка BLEU, измеренная выше, по результирующим подписям не отражает реальную производительность. Фактически, оценка BLEU представляет собой метрику, предназначенную для сравнения естественных подписей с наземными надписями различной длины. Как только пакетный вывод будет реализован, т.е. не принуждает учителя, раннее сокращение с баллом Bleu будет действительно «правильным».
Имея это в виду, я использовал eval.py для вычисления правильных показателей BLEU-4 этой модели контрольной точки по проверке и тестовым наборам без принуждения учителей, при разных размерах луча-
| Размер луча | Валидация Bleu-4 | Тест bleu-4 |
|---|---|---|
| 1 | 29,98 | 30.28 |
| 3 | 32,95 | 33,06 |
| 5 | 33,17 | 33,29 |
Оценка теста выше, чем результат в статье, и может быть из-за того, как наши калькуляторы Bleu параметризованы, тот факт, что я использовал энкодер Resnet и фактически точно настроил энкодер-даже если немного.
Кроме того, помните-при тонкой настройке во время переноса обучения всегда лучше использовать скорость обучения значительно меньше, чем первоначально использовалось для обучения заимствованной модели. Это потому, что модель уже довольно оптимизирована, и мы не хотим что -то менять слишком быстро. Я также использовал Adam() и для энкодера, но с частотой обучения 1e-4 , который является десятой из значения по умолчанию для этого оптимизатора.
На титане X (Pascal) он занял 55 минут на эпоху без точной настройки и 2,5 часа с точной настройкой в указанных размерах партии.
Вы можете скачать эту предварительную модель и соответствующую word_map здесь.
Обратите внимание, что эта контрольная точка должна быть загружена непосредственно с помощью pytorch или передавать в caption.py - см. Ниже.
См. caption.py .
Во время вывода мы не можем напрямую использовать метод forward() в декодере, потому что он использует принуждение учителя. Скорее, нам на самом деле нужно будет подавать ранее сгенерированное слово в LSTM в каждом временном разделе .
caption_image_beam_search() считывает изображение, кодирует его и применяет слои в декодере в правильном порядке, используя ранее сгенерированное слово в качестве ввода для LSTM в каждом временном разделе. Это также включает в себя поиск луча.
visualize_att() может использоваться для визуализации сгенерированной подписи вместе с весами в каждом временном разделе, как видно из примеров.
Чтобы подготовить изображение из командной строки, укажите на изображение, контрольную точку модели, карту слов (и, необязательно, размер луча) следующим образом -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
Альтернативно, используйте функции в файле по мере необходимости.
Также см. eval.py , который реализует этот процесс для расчета оценки BLEU по набору валидации, с поиском луча или без него.





Тест Тьюринга Томми - вы знаете, что ИИ не совсем ИИ, потому что он не смотрел комнату и не узнает величие, когда он его видит.

Вы обратили на себя мягкое внимание. Есть ли сложное внимание?
Да, шоу, посещение и рассказ Paper использует оба варианта, а декодер с «жестким» вниманием работает немного лучше.
В мягком внимании, которое мы используем здесь, вы вычисляете alpha -веса и используете средневзвешенные функции для всех пикселей. Это детерминированная, дифференцируемая операция.
В пристальном внимании вы выбираете просто попробовать некоторые пиксели из распределения, определяемого alpha . Обратите внимание, что любая такая вероятностная выборка является не определенной или стохастической , то есть конкретный вход не всегда будет производить один и тот же выход. Но поскольку градиентный спуск предполагает, что сеть является детерминированной (и, следовательно, дифференцируемой), выборка переработана для удаления стохастичности. Мои знания об этом довольно поверхностно - я обновлю этот ответ, когда у меня будет более подробное понимание.
Как использовать сеть внимания для задачи NLP, например, последовательность для модели последовательности?
Подобно тому, как вы используете CNN для генерации кодирования с функциями на каждом пикселе, вы использовали бы RNN для генерации кодируемых функций в каждом положении слов TimeStep IE на входе.
Без внимания вы бы использовали вывод энкодера в последнем временном разделе в качестве кодирования для всего предложения, поскольку он также содержит информацию из предыдущих временных точек. Последний вывод энкодера теперь несет бремя от необходимости кодировать все предложение осмысленно, что нелегко, особенно для более длинных предложений.
С вниманием вы посещаете временные рамки в выходе энкодера, генерируя веса для каждого временного значения/слова, и принять средневзвешенное значение для представления предложения. В последовательности к задаче последовательности, такой как машинный перевод, вы будете заниматься соответствующими словами на входе, когда вы генерируете каждое слово в выводе.
Вы также можете использовать внимание без декодера. Например, если вы хотите классифицировать текст, вы можете принять участие в важных словах на входе только один раз, чтобы выполнить классификацию.
Можем ли мы использовать поиск луча во время тренировки?
Не с текущей функцией потери, но да. Это совсем не распространено.
Что зажигает учителя?
Учительное принуждение - это когда мы используем названые названия истины в качестве ввода декодера в каждом временном панели, а не слово, которое он генерировал в предыдущем временном разделе. Это часто для преподавателя во время обучения, поскольку это может означать более быстрое сближение модели. Но это также может научиться зависеть от того, чтобы им сообщали правильный ответ и демонстрирует некоторую нестабильность на практике.
Это было бы идеально для обучения, используя учителя, принуждающего только некоторое время, в зависимости от вероятности. Это называется запланированной выборкой.
(Я планирую добавить вариант).
Могу ли я использовать предварительно проведенные встроенные слова (перчатка, Cbow, Skipgram и т. Д.) Вместо того, чтобы изучать их с нуля?
Да, вы могли бы, с помощью метода load_pretrained_embeddings() в классе Decoder . Вы также можете выбрать точную настройку (или нет) с помощью метода fine_tune_embeddings() .
После создания декодера в train.py вы должны предоставить предварительно подготовленные векторы для load_pretrained_embeddings() сложенных в том же порядке, что и в word_map . Для слов, для которых у вас нет предварительных векторов, таких как <start> , вы можете инициализировать встраивания случайным образом, как мы это делали в init_weights() . Я рекомендую тонкую настройку, чтобы изучить более значимые векторы для этих случайно инициализированных векторов.
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False Также убедитесь, что изменить параметр emb_dim от его текущего значения 512 на размер ваших предварительно обученных вторжений. Это должно автоматически отрегулировать входной размер LSTM декодера, чтобы пометить их.
Как я могу отслеживать, какие тензоры позволяют вычислять градиенты?
При высвобождении Pytorch 0.4 обертывание тензоров в виде Variable S больше не требуется. Вместо этого тензоры имеют атрибут requires_grad , который решает, отслеживается ли он autograd , и, следовательно, вычисляются ли градиенты для него во время обратного распространения.
requires_grad будет установлен на False .requires_grad будет установлен на True .torch.nn , уже будут иметь requires_grad установленную в True .Как вычислить все оценки Bleu (IE Bleu-1 для Bleu-4) во время оценки?
Вам нужно изменить код в eval.py , чтобы сделать это. Пожалуйста, смотрите этот отличный ответ Kmario23 для четкого и подробного объяснения.


