a PyTorch Tutorial to Image Captioning
1.0.0
Ceci est un tutoriel Pytorch au sous-titrage de l'image .
Ceci est le premier d'une série de tutoriels que j'écris sur la mise en œuvre de modèles sympas par vous-même avec l'incroyable bibliothèque Pytorch.
La connaissance de base des réseaux de neurones pytorch, convolutionnels et récurrents est supposé.
Si vous êtes nouveau sur Pytorch, lisez d'abord l'apprentissage en profondeur avec Pytorch: un blitz de 60 minutes et l'apprentissage pytorch avec des exemples.
Des questions, des suggestions ou des corrections peuvent être affichées comme des problèmes.
J'utilise PyTorch 0.4 dans Python 3.6 .
27 janvier 2020 : le code de travail pour deux nouveaux tutoriels a été ajouté - Super-résolution et traduction automatique
Objectif
Concepts
Aperçu
Mise en œuvre
Entraînement
Inférence
Questions fréquemment posées
Pour créer un modèle qui peut générer une légende descriptive pour une image que nous lui fournissons.
Dans l'intérêt de garder les choses simples, mettons en œuvre le spectacle, assistez et racontez du papier. Ce n'est en aucun cas l'état actuel de la technologie, mais il est toujours assez étonnant. L'implémentation originale des auteurs peut être trouvée ici.
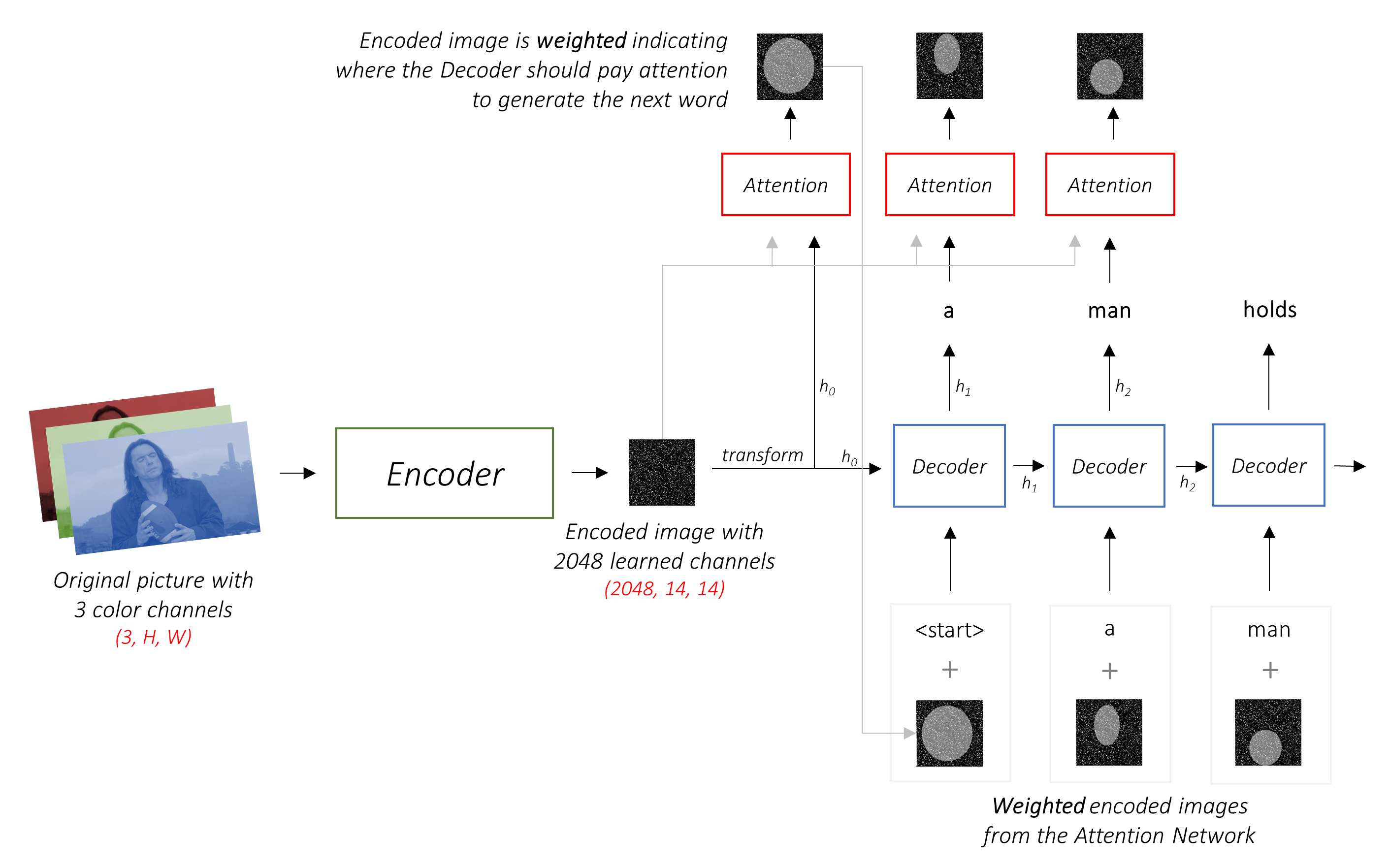
Ce modèle apprend où chercher.
Lorsque vous générez une légende, Word par mot, vous pouvez voir le regard du modèle passer à travers l'image.
Cela est possible en raison de son mécanisme d'attention , qui lui permet de se concentrer sur la partie de l'image la plus pertinente pour le mot qu'elle va prononcer ensuite.
Voici quelques légendes générées sur les images de test non visibles pendant la formation ou la validation:




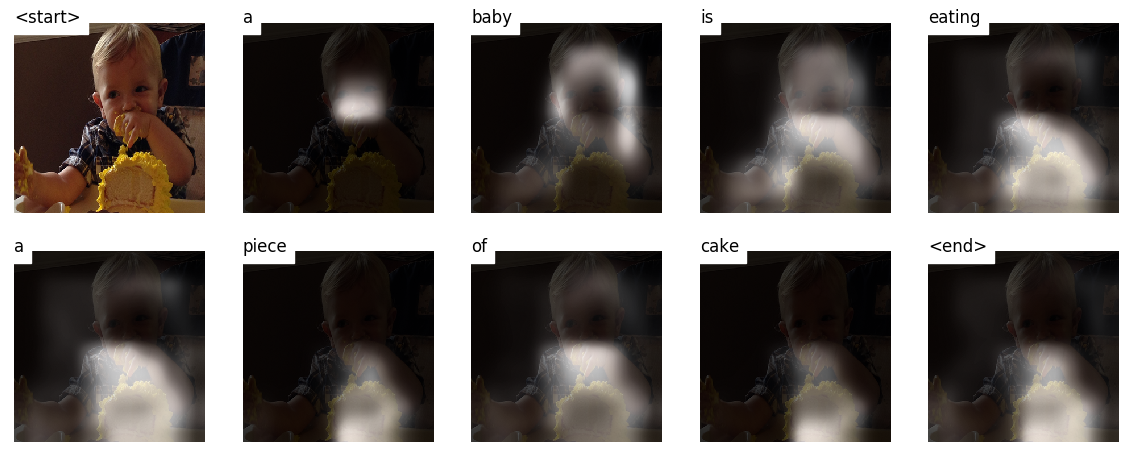

Il y a plus d'exemples à la fin du tutoriel.
Sous-titrage de l'image . duh.
Architecture d'encodeur-décodeur . En règle générale, un modèle qui génère des séquences utilisera un encodeur pour coder l'entrée dans une forme fixe et un décodeur pour le décoder, mot par mot, dans une séquence.
Attention . L'utilisation de réseaux d'attention est répandue dans l'apprentissage en profondeur et pour raison. C'est un moyen pour un modèle de choisir uniquement les parties de l'encodage qui, selon elle, est pertinente pour la tâche à accomplir. Le même mécanisme que vous voyez utilisé ici peut être utilisé dans n'importe quel modèle où la sortie de l'encodeur a plusieurs points dans l'espace ou le temps. Dans le sous-titrage de l'image, vous considérez certains pixels plus importants que d'autres. Dans les tâches de séquence à séquence comme la traduction machine, vous considérez certains mots plus importants que d'autres.
Transférer l'apprentissage . C'est à ce moment que vous empruntez à un modèle existant en utilisant des parties de celui-ci dans un nouveau modèle. C'est presque toujours mieux que de former un nouveau modèle à partir de zéro (c'est-à-dire, ne sachant rien). Comme vous le verrez, vous pouvez toujours affiner cette connaissance d'occasion à la tâche spécifique à portée de main. L'utilisation d'incorporation de mots pré-entraînés est un exemple stupide mais valide. Pour notre problème de sous-titrage d'image, nous utiliserons un encodeur pré-entraîné, puis l'a affiner au besoin.
Recherche de faisceau . C'est là que vous ne laissez pas votre décodeur être paresseux et choisissez simplement les mots avec le meilleur score à chaque pas de décodage. La recherche de faisceau est utile pour tout problème de modélisation du langage car il trouve la séquence la plus optimale.
Dans cette section, je présenterai un aperçu de ce modèle. Si vous le savez déjà, vous pouvez passer directement à la section d'implémentation ou au code commenté.
L'encodeur code l'image d'entrée avec 3 canaux de couleur dans une image plus petite avec des canaux "appris" .
Cette image codée plus petite est une représentation sommaire de tout ce qui est utile dans l'image d'origine.
Puisque nous voulons coder des images, nous utilisons des réseaux de neurones convolutionnels (CNN).
Nous n'avons pas besoin de former un encodeur à partir de zéro. Pourquoi? Parce qu'il y a déjà des CNN formés pour représenter des images.
Depuis des années, les gens construisent des modèles qui sont extraordinairement bons pour classer une image dans l'une des mille catégories. Il va de soi que ces modèles capturent très bien l'essence d'une image.
J'ai choisi d'utiliser le réseau résiduel en couches 101 formé sur la tâche de classification ImageNet , déjà disponible à Pytorch. Comme indiqué précédemment, il s'agit d'un exemple d'apprentissage par transfert. Vous avez la possibilité de le régler pour améliorer les performances.

Ces modèles créent progressivement des représentations de plus en plus petites de l'image d'origine, et chaque représentation ultérieure est plus "apprise", avec un plus grand nombre de canaux. Le codage final produit par notre encodeur RESNET-101 a une taille de 14x14 avec 2048 canaux, c'est-à-dire un tenseur de taille 2048, 14, 14 .
Je vous encourage à expérimenter d'autres architectures pré-formées. Le papier utilise un VGGNET, également pré-entraîné sur ImageNet, mais sans réglage fin. Quoi qu'il en soit, des modifications sont nécessaires. Étant donné que la dernière couche ou deux de ces modèles sont des couches linéaires couplées à l'activation de SoftMax pour la classification, nous les supprimons.
Le travail du décodeur consiste à regarder l'image codée et à générer une légende mot par mot .
Puisqu'il génère une séquence, il devrait être un réseau neuronal récurrent (RNN). Nous utiliserons un LSTM.
Dans un cadre typique sans attention, vous pouvez simplement en moyenne l'image codée sur tous les pixels. Vous pouvez ensuite nourrir cela, avec ou sans transformation linéaire, en décodeur comme premier état caché et générer la légende. Chaque mot prévu est utilisé pour générer le mot suivant.
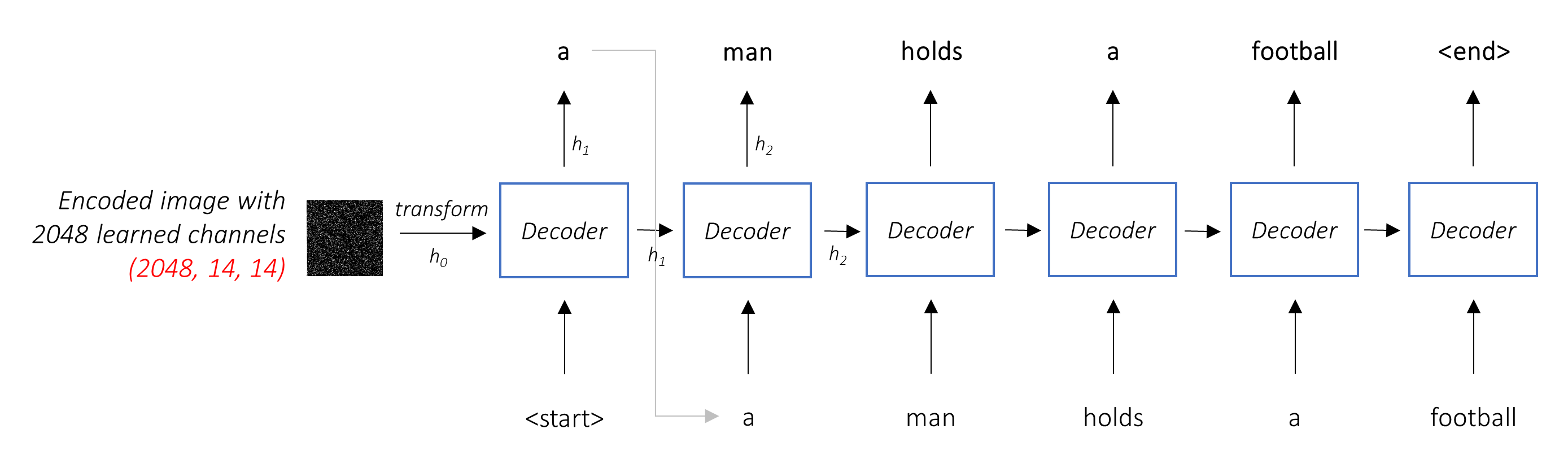
Dans un cadre avec attention, nous voulons que le décodeur puisse regarder différentes parties de l'image à différents points de la séquence . Par exemple, tout en générant le mot football chez a man holds a football , le décodeur saurait se concentrer sur - vous l'avez deviné - le football!
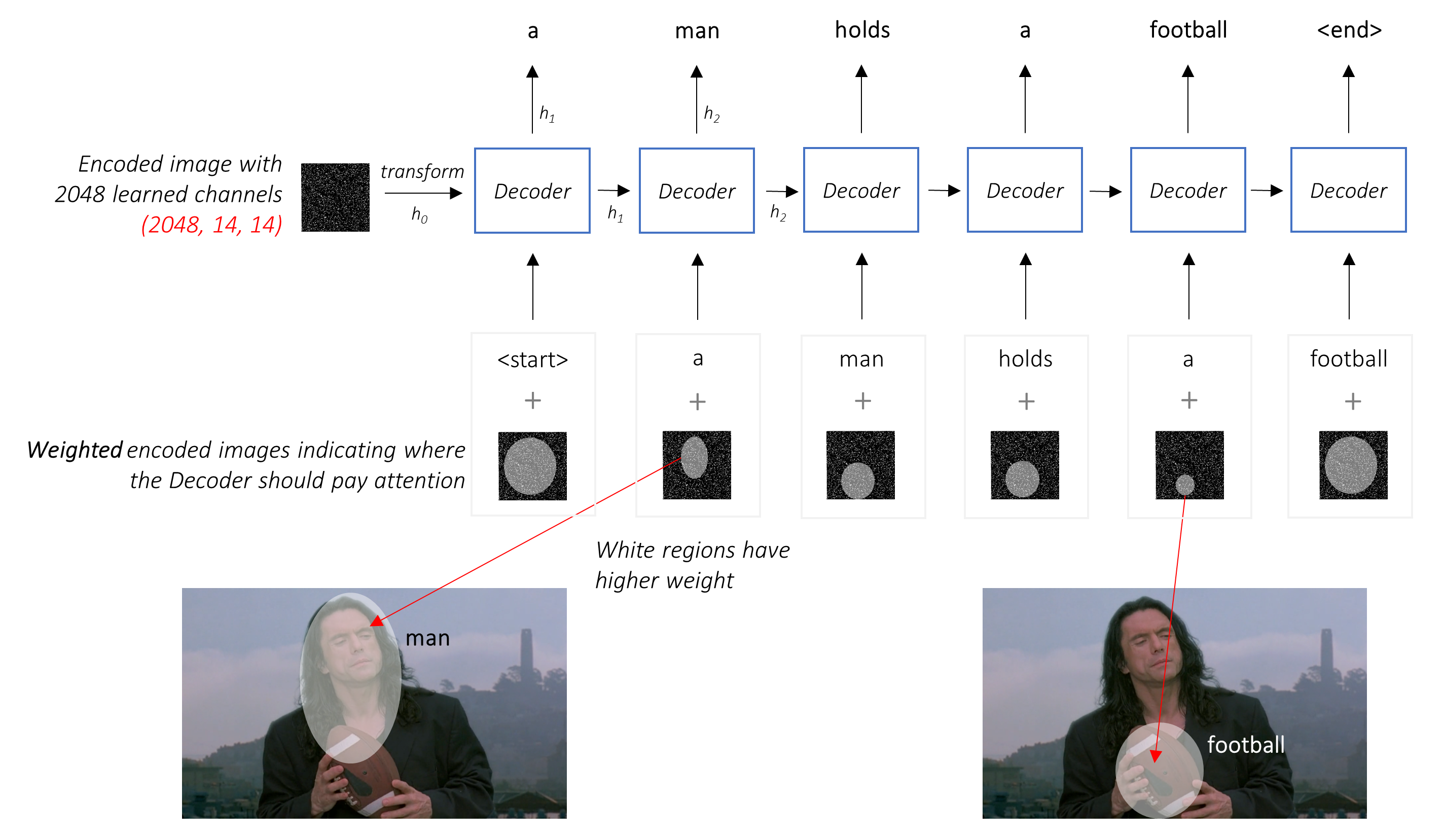
Au lieu de la moyenne simple, nous utilisons la moyenne pondérée sur tous les pixels, les poids des pixels importants étant plus importants. Cette représentation pondérée de l'image peut être concaténée avec le mot généré précédemment à chaque étape pour générer le mot suivant.
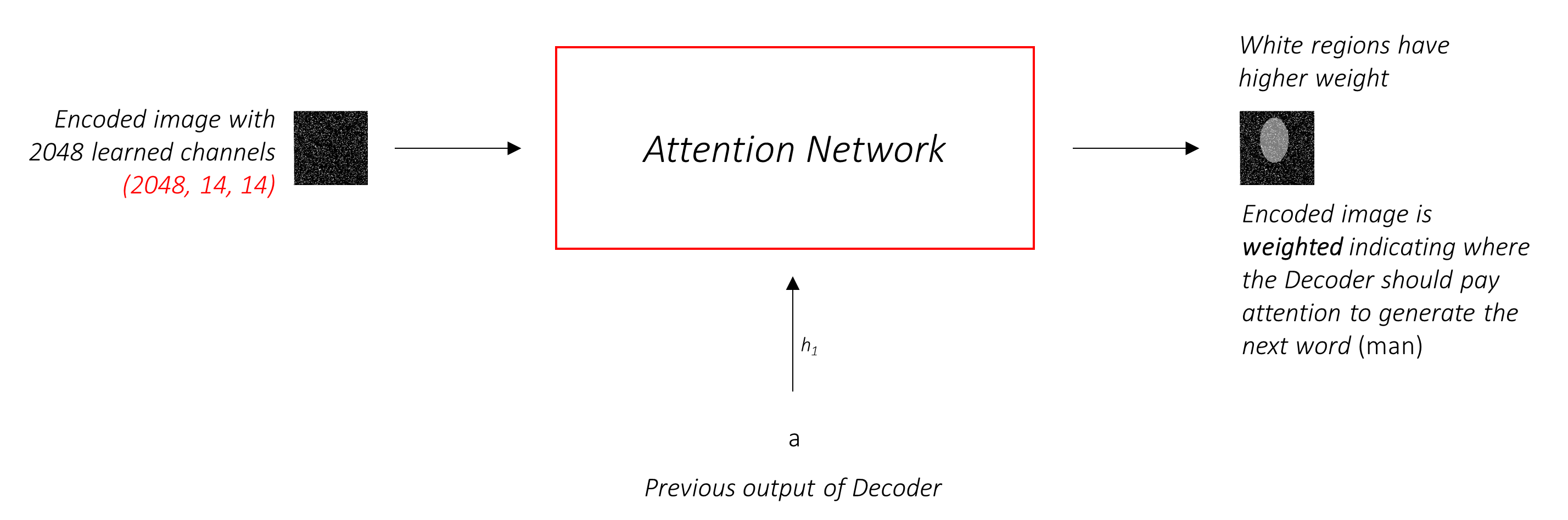
Le réseau d'attention calcule ces poids .
Intuitivement, comment estimeriez-vous l'importance d'une certaine partie d'une image? Vous devez être conscient de la séquence que vous avez générée jusqu'à présent , afin que vous puissiez regarder l'image et décider ce qui doit être décrit ensuite. Par exemple, après avoir mentionné a man , il est logique de déclarer qu'il holding a football .
C'est exactement ce que fait le mécanisme d'attention - il considère la séquence générée jusqu'à présent, et s'occupe de la partie de l'image qui doit être décrite ensuite.
Nous utiliserons une douce attention, où les poids des pixels s'ajoutent à 1. S'il y a P pixels dans notre image codée, alors à chaque temps t -
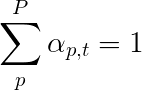
Vous pouvez interpréter tout ce processus comme calculant la probabilité qu'un pixel soit l' endroit où chercher à générer le mot suivant .
Il pourrait maintenant être clair à quoi ressemble notre réseau combiné.
h (et l'état de cellule C ) pour le décodeur LSTM.Nous utilisons une couche linéaire pour transformer la sortie du décodeur en un score pour chaque mot dans le vocabulaire.
L'option simple - et gourmand - serait de choisir le mot avec le score le plus élevé et de l'utiliser pour prédire le mot suivant. Mais ce n'est pas optimal car le reste de la séquence dépend de ce premier mot que vous choisissez. Si ce choix n'est pas le meilleur, tout ce qui suit est sous-optimal. Et ce n'est pas seulement le premier mot - chaque mot de la séquence a des conséquences pour ceux qui l'ont réussi.
Il pourrait très bien arriver que si vous aviez choisi le troisième meilleur mot à cette première étape, et le deuxième meilleur mot à la deuxième étape, et ainsi de suite ... ce serait la meilleure séquence que vous pourriez générer.
Il serait préférable que nous ne puissions pas décider d'une manière ou d'une autre avant d'avoir terminé le décodage complètement et de choisir la séquence qui a le score global le plus élevé à partir d'un panier de séquences candidates .
La recherche de faisceau fait exactement cela.
k des candidats.k seconds mots pour chacun de ces k premiers mots.k [premier mot, deuxième mot] en considérant les scores additifs.k secondes mots, choisissez k troisième mots, choisissez les combinaisons supérieures k [premier mot, deuxième mot, troisième mot].k , choisissez la séquence avec le meilleur score global. 
Comme vous pouvez le voir, certaines séquences (frappées) peuvent échouer tôt, car elles ne parviennent pas à la k top à l'étape suivante. Une fois que les séquences k (soulignées) ont généré le jeton <end> , nous choisissons celui avec le score le plus élevé.
Les sections ci-dessous décrivent brièvement la mise en œuvre.
Ils sont censés fournir un certain contexte, mais les détails sont mieux compris directement à partir du code , qui est assez fortement commenté.
J'utilise l'ensemble de données MSCOCO '14. Vous devez télécharger les images de formation (13 Go) et de validation (6 Go).
Nous utiliserons la formation, la validation et les coupures de test d'Andrej Karpathy. Ce fichier zip contienne les légendes. Vous trouverez également des divisions et des légendes pour les ensembles de données Flicker8K et Flicker30k, alors n'hésitez pas à les utiliser au lieu de MSCOCO si ce dernier est trop grand pour votre ordinateur.
Nous aurons besoin de trois entrées.
Puisque nous utilisons un encodeur pré-entraîné, nous devons traiter les images sous la forme auquel le codeur pré-entraîné est habitué.
Modèles ImageNet pré-entraînés disponibles dans le cadre du module torchvision de Pytorch. Cette page détaille le prétraitement ou la transformation que nous devons effectuer - les valeurs de pixels doivent être dans la plage [0,1] et nous devons ensuite normaliser l'image par la moyenne et l'écart type des canaux RVB des images ImageNet.
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]De plus, Pytorch suit la convention NCHW, ce qui signifie que la dimension des canaux (C) doit précéder les dimensions de la taille.
Nous redimensions toutes les images MSCOCO à 256x256 pour l'uniformité.
Par conséquent, les images fournies au modèle doivent être un tenseur Float de dimension N, 3, 256, 256 , et doivent être normalisés par la moyenne et l'écart type susmentionné. N est la taille du lot.
Les légendes sont à la fois la cible et les entrées du décodeur car chaque mot est utilisé pour générer le mot suivant.
Pour générer le premier mot, cependant, nous avons besoin d'un mot zeroth , <start> .
Au dernier mot, nous devons prédire <end> le décodeur doit apprendre à prédire la fin d'une légende. Cela est nécessaire car nous devons savoir quand arrêter le décodage pendant l'inférence.
<start> a man holds a football <end>
Étant donné que nous passons les légendes autour de tenseurs de taille fixe, nous devons remplir des légendes (qui sont naturellement de longueur variable) à la même longueur que les jetons <pad> .
<start> a man holds a football <end> <pad> <pad> <pad>....
De plus, nous créons un word_map qui est un mappage d'index pour chaque mot dans le corpus, y compris les jetons <start> , <end> et <pad> . Pytorch, comme d'autres bibliothèques, a besoin de mots codés comme des indices pour rechercher des incorporations pour eux ou pour identifier leur place dans les scores de mots prévus.
9876 1 5 120 1 5406 9877 9878 9878 9878....
Par conséquent, les légendes fournies au modèle doivent être un tenseur Int de dimension N, L où L est la longueur rembourrée.
Étant donné que les légendes sont rembourrées, nous devons garder une trace des longueurs de chaque légende. Il s'agit de la longueur réelle + 2 (pour les jetons <start> et <end> ).
Les longueurs de légende sont également importantes car vous pouvez créer des graphiques dynamiques avec Pytorch. Nous ne traitons qu'une séquence jusqu'à sa longueur et ne gaspillons pas de calcul sur les <pad> s.
Par conséquent, les longueurs de légende alimentées au modèle doivent être un tenseur Int de dimension N .
Voir create_input_files() dans utils.py .
Cela lit les données téléchargées et enregistre les fichiers suivants -
I, 3, 256, 256 , où I est le nombre d'images dans la scission. Les valeurs de pixels sont toujours dans la plage [0, 255] et sont stockées comme Int 8 bits non signés.I N_c * , où N_c est le nombre de légendes échantillonnées par image. Ces légendes sont dans le même ordre que les images du fichier HDF5. Par conséquent, la légende i th correspondra à l'image i // N_c th.N_c * I . La valeur i th est la longueur de la légende i th, qui correspond à l'image i // N_c th.word_map , le dictionnaire Word-to-Index. Avant de sauvegarder ces fichiers, nous avons la possibilité d'utiliser uniquement des légendes qui sont plus courtes qu'un seuil et de mettre des mots moins fréquents dans un jeton <unk> .
Nous utilisons des fichiers HDF5 pour les images car nous les lirons directement à partir du disque pendant la formation / validation. Ils sont tout simplement trop grands pour s'adapter à la RAM à la fois. Mais nous chargeons toutes les légendes et leurs longueurs en mémoire.
Voir CaptionDataset dans datasets.py .
Il s'agit d'une sous-classe de Dataset Pytorch. Il a besoin d'une méthode __len__ définie, qui renvoie la taille de l'ensemble de données et une méthode __getitem__ qui renvoie i image, la légende et la longueur de légende.
Nous lisons des images du disque, convertissons des pixels en [0,255] et les normalisons à l'intérieur de cette classe.
L' Dataset sera utilisé par un Pytorch DataLoader dans train.py pour créer et alimenter les lots de données au modèle de formation ou de validation.
Voir Encoder dans models.py .
Nous utilisons un RESNET-101 pré-entraîné déjà disponible dans le module torchvision de Pytorch. Jeter les deux dernières couches (regroupement et couches linéaires), car nous n'avons qu'à coder l'image et à ne pas le classer.
Nous ajoutons une couche AdaptiveAvgPool2d() pour redimensionner le codage à une taille fixe . Cela permet de nourrir des images de taille variable à l'encodeur. (Nous avons cependant redimensionné nos images d'entrée à 256, 256 parce que nous avons dû les stocker ensemble en tant que tenseur unique.)
Étant donné que nous pouvons vouloir affiner l'encodeur, nous ajoutons une méthode fine_tune() qui permet ou désactive le calcul des gradients pour les paramètres de l'encodeur. Nous n'avons affiner les blocs de convolution 2 à 4 dans le Resnet , car le premier bloc de convolutionnel aurait généralement appris quelque chose de très fondamental pour le traitement d'image, tels que la détection des lignes, des bords, des courbes, etc. Nous ne gâchons pas les fondations.
Voir Attention dans models.py .
Le réseau d'attention est simple - il est composé uniquement de couches linéaires et de quelques activations.
Des couches linéaires séparées transforment à la fois l'image codée (aplatie en N, 14 * 14, 2048 ) et l'état caché (sortie) du décodeur à la même dimension , à savoir. la taille de l'attention. Ils sont ensuite ajoutés et activés en relu. Une troisième couche linéaire transforme ce résultat en une dimension de 1 , après quoi nous appliquons le softmax pour générer les poids alpha .
Voir DecoderWithAttention dans models.py .
La sortie de l'encodeur est reçue ici et aplatie en dimensions N, 14 * 14, 2048 . Cela est tout simplement pratique et empêche de devoir remodeler le tenseur plusieurs fois.
Nous initialisons l'état caché et cellulaire du LSTM à l'aide de l'image codée avec la méthode init_hidden_state() , qui utilise deux couches linéaires distinctes.
Au tout début, nous trierons les N images et les légendes en diminuant les longueurs de légende . C'est pour que nous ne puissions traiter que des horodatages valides , c'est-à-dire pas de traiter les <pad> s.
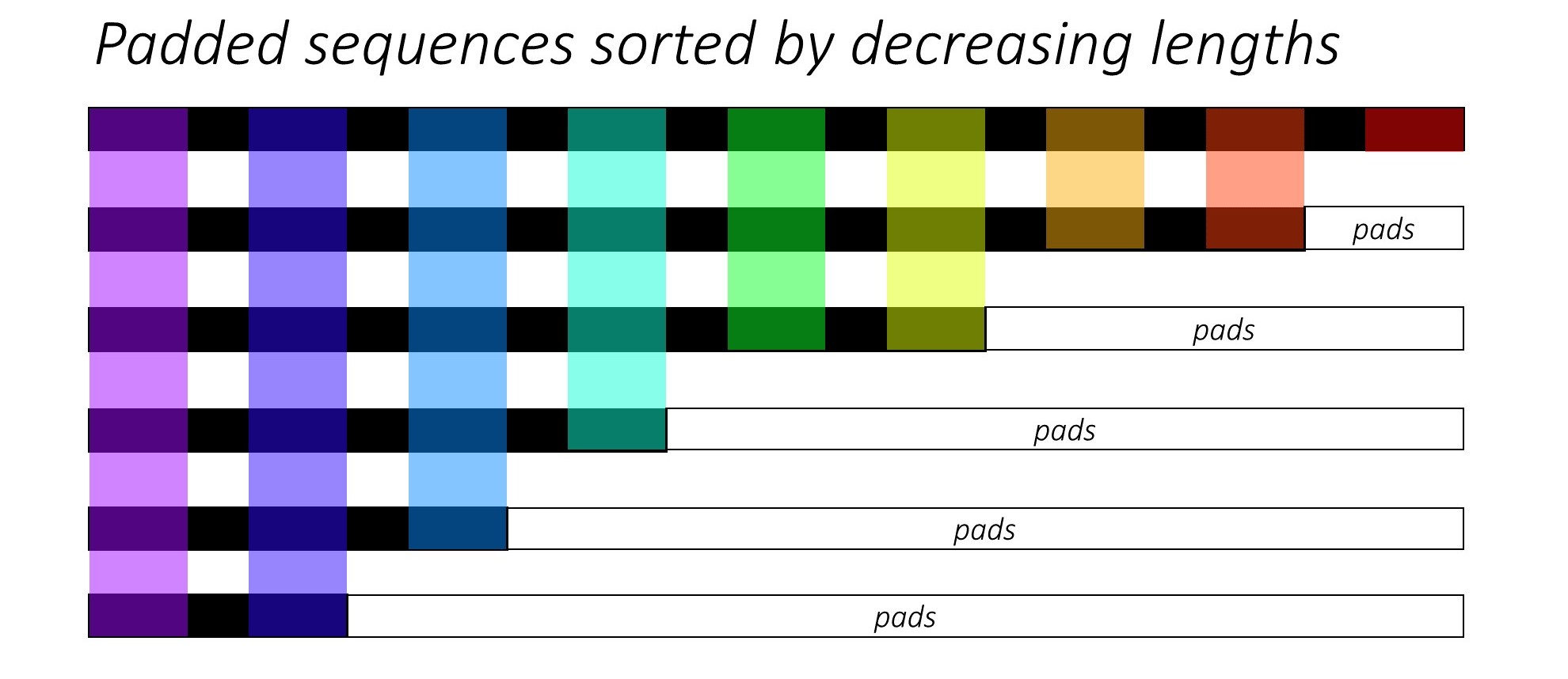
Nous pouvons itérer sur chaque étalage, ne traitant que les régions colorées, qui sont la taille efficace du lot N_t à ce pas de l'horodatage. Le tri permet au N_t supérieur à n'importe quel étalage pour s'aligner sur les sorties de l'étape précédente. Au troisième temps, par exemple, nous ne traitons que les 5 meilleures images, en utilisant les 5 premières sorties de l'étape précédente.
Cette itération est effectuée manuellement dans une for pour un LSTMCell pytorch au lieu d'itérer automatiquement sans boucle avec un LSTM pytorch. En effet, nous devons exécuter le mécanisme d'attention entre chaque étape de décodage. Un LSTMCell est une opération à horaire unique, tandis qu'un LSTM iternerait sur plusieurs horaires en continu et fournirait toutes les sorties à la fois.
Nous calculons les poids et le codage pondéré en fonction de l'attention à chaque étalage avec le réseau d'attention. Dans la section 4.2.1 de l'article, ils recommandent de passer le codage pondéré par l'attention à travers un filtre ou une porte . Cette porte est une transformée linéaire activée sigmoïde de l'état caché précédent du décodeur. Les auteurs déclarent que cela aide le réseau d'attention à mettre davantage l'accent sur les objets de l'image.
Nous concatenons ce codage filtré pondéré par l'attention avec l'incorporation du mot précédent ( <start> pour commencer), et exécutons le LSTMCell pour générer le nouvel état caché (ou sortie) . Une couche linéaire transforme ce nouvel état caché en scores pour chaque mot du vocabulaire , qui est stocké.
Nous stockons également les poids renvoyés par le réseau d'attention à chaque étalage. Vous verrez pourquoi assez tôt.
Avant de commencer, assurez-vous d'enregistrer les fichiers de données requis pour la formation, la validation et les tests. Pour ce faire, exécutez le contenu de create_input_files.py après l'avoir pointé vers le fichier JSON du Karpathy et le dossier d'image contenant les dossiers train2014 et val2014 extraits de vos données téléchargées.
Voir train.py .
Les paramètres du modèle (et la formation) sont au début du fichier, vous pouvez donc facilement les vérifier ou les modifier si vous le souhaitez.
Pour former votre modèle à partir de zéro , exécutez simplement ce fichier -
python train.py
Pour reprendre la formation à un point de contrôle , indiquez le fichier correspondant avec le paramètre de checkpoint au début du code.
Notez que nous effectuons la validation à la fin de chaque époque d'entraînement.
Puisque nous générons une séquence de mots, nous utilisons CrossEntropyLoss . Il vous suffit de soumettre les scores bruts de la couche finale du décodeur, et la fonction de perte effectuera les opérations Softmax et Log.
Les auteurs de l'article recommandent d'utiliser une deuxième perte - une " régularisation doublement stochastique ". Nous savons que les poids diminuent 1 à un pas de temps donné. Mais nous encourageons également les poids à un seul pixel p pour résumer à 1 à tous les temps T -
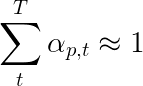
Cela signifie que nous voulons que le modèle s'occupe de chaque pixel au cours de la génération de la séquence entière. Par conséquent, nous essayons de minimiser la différence entre 1 et la somme des poids d'un pixel à tous les temps .
Nous ne calculons pas les pertes sur les régions rembourrées . Un moyen facile de se débarrasser des coussinets est d'utiliser Pytorch's pack_padded_sequence() , qui applaudie le tenseur par TimeStEp tout en ignorant les régions rembourrées. Vous pouvez désormais agréger la perte sur ce tenseur aplati.
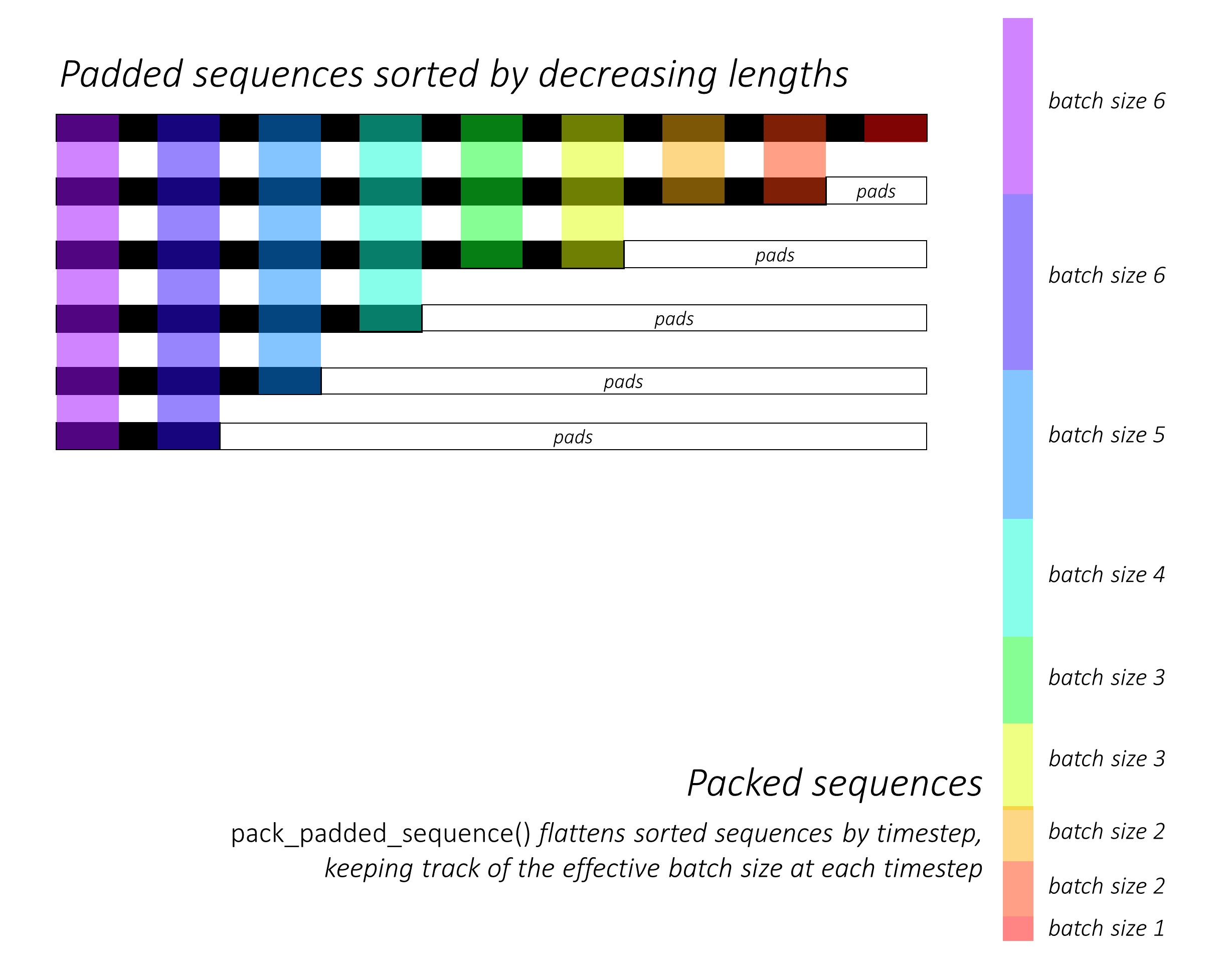
Remarque - Cette fonction est réellement utilisée pour effectuer le même lot dynamique (c'est-à-dire, le traitement uniquement de la taille du lot efficace à chaque étalage) que nous avons effectué dans notre décodeur, lorsque vous utilisez un RNN ou LSTM dans Pytorch. Dans ce cas, Pytorch gère les graphiques dynamiques de longueur variable en interne. Vous pouvez voir un exemple dans dynamic_rnn.py dans mon autre tutoriel sur l'étiquetage des séquences. Nous aurions utilisé cette fonction avec un LSTM dans notre décodeur si nous n'étendons pas manuellement en raison du réseau d'attention.
Pour évaluer les performances du modèle sur l'ensemble de validation, nous utiliserons la métrique d'évaluation automatisée de l'évaluation de l'évaluation bilingue (BLEU). Cela évalue une légende générée par rapport aux légendes de référence. Pour chaque légende générée, nous utiliserons toutes les légendes N_c disponibles pour cette image comme légendes de référence.
Les auteurs de l' émission, assistent et disent au papier observent que la corrélation entre la perte et le score BLEU se décompose après un point, ils recommandent donc d'arrêter de s'entraîner tôt lorsque le score BLEU commence à se dégrader, même si la perte continue de diminuer.
J'ai utilisé l'outil BLEU disponible dans le module NLTK.
Notez qu'il y a une critique considérable de la partition de BLEU car elle ne est pas toujours en corrélation avec le jugement humain. Les auteurs rapportent également les scores Meteor pour cette raison, mais je n'ai pas implémenté cette métrique.
Je vous recommande de vous entraîner aux étapes.
Je n'ai d'abord formé que le décodeur, c'est-à-dire sans affiner l'encodeur, avec une taille de lot de 80 . Je me suis entraîné pour 20 époques et le score BLEU-4 a culminé à environ 23.25 à la 13e époque. J'ai utilisé l'optimiseur Adam() avec un taux d'apprentissage initial de 4e-4 .
J'ai continué à partir du 13e point de contrôle de l'époque permettant un réglage fin de l'encodeur avec une taille de lot de 32 . La plus petite taille de lot est due au modèle est désormais plus grand car il contient les gradients de l'encodeur. Avec un réglage fin, le score est passé à 24.29 en environ 3 époques. La formation continue aurait probablement poussé le score légèrement plus élevé, mais j'ai dû commettre mon GPU ailleurs.
Une distinction importante à faire ici est que je fournit toujours la vérification du sol comme l'entrée à chaque pas de décodage pendant la validation, quel que soit le mot généré pour la dernière fois . C'est ce qu'on appelle le forçage des enseignants . Bien que cela soit couramment utilisé pendant l'entraînement pour accélérer le processus, comme nous le faisons, les conditions pendant la validation doivent imiter autant que possible les conditions réelles d'inférence. Je n'ai pas encore implémenté l'inférence lot - où chaque mot de la légende est généré à partir du mot précédemment généré et se termine en frappant le jeton <end> .
Étant donné que je suis en train de forcer les enseignants pendant la validation, le score BLEU mesuré ci-dessus sur les légendes résultantes ne reflète pas de réelles performances. En fait, le score BLEU est une métrique conçue pour comparer des légendes générées naturellement aux légendes de la fin de la longueur différente. Une fois l'inférence par lots mises en œuvre, c'est-à-dire qu'aucun enseignant ne forçait, à l'abri avec le score BLEU sera vraiment «approprié».
Dans cet esprit, j'ai utilisé eval.py pour calculer les scores BLEU-4 corrects de ce modèle de contrôle sur les ensembles de validation et de tests sans forçage des enseignants, à différentes tailles de faisceau -
| Taille de faisceau | Validation Bleu-4 | Tester Bleu-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
Le score de test est plus élevé que le résultat dans le papier et pourrait être en raison de la façon dont nos calculatrices BLEU sont paramétrées, du fait que j'ai utilisé un encodeur RESNET, et en fait un encodeur affiné - même s'il est juste un peu.
N'oubliez pas non plus - lorsqu'il a affiné pendant l'apprentissage du transfert, il est toujours préférable d'utiliser un taux d'apprentissage considérablement plus petit que ce qui a été utilisé à l'origine pour former le modèle emprunté. En effet, le modèle est déjà assez optimisé, et nous ne voulons rien changer trop rapidement. J'ai également utilisé Adam() pour l'encodeur, mais avec un taux d'apprentissage de 1e-4 , qui est un dixième de la valeur par défaut pour cet optimiseur.
Sur un Titan X (Pascal), il a fallu 55 minutes par époque sans réglage fin et 2,5 heures avec un réglage fin aux tailles de lots indiquées.
Vous pouvez télécharger ce modèle pré-entraîné et le word_map correspondant ici.
Notez que ce point de contrôle doit être chargé directement avec Pytorch, ou transmis à caption.py - voir ci-dessous.
Voir caption.py .
Pendant l'inférence, nous ne pouvons pas utiliser directement la méthode forward() dans le décodeur car il utilise le forçage des enseignants. Nous aurions plutôt besoin de nourrir le mot précédemment généré au LSTM à chaque étalage .
caption_image_beam_search() lit une image, la code et applique les couches dans le décodeur dans l'ordre correct, tout en utilisant le mot généré précédemment comme entrée au LSTM à chaque temps. Il intègre également la recherche de faisceau.
visualize_att() peut être utilisé pour visualiser la légende générée avec les poids à chaque étalage comme le montre les exemples.
Pour légendre une image de la ligne de commande, pointez à l'image, point de contrôle du modèle, carte mot (et éventuellement, taille du faisceau) comme suit -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
Alternativement, utilisez les fonctions dans le fichier au besoin.
Voir également eval.py , qui met en œuvre ce processus de calcul du score BLEU sur l'ensemble de validation, avec ou sans recherche de faisceau.





Le test Tommy Turing - vous savez que l'IA n'est pas vraiment l'IA parce qu'elle n'a pas regardé la pièce et ne reconnaît pas la grandeur quand elle le voit.

Vous avez dit une douce attention. Y a-t-il, euh, une attention difficile ?
Oui, le spectacle, assister et dire que le papier utilise les deux variantes, et le décodeur avec une attention "dure" fonctionne légèrement mieux.
Dans l'attention douce , que nous utilisons ici, vous composez les poids alpha et en utilisant la moyenne pondérée des fonctionnalités sur tous les pixels. Il s'agit d'une opération déterministe et différenciable.
Dans une attention difficile , vous choisissez de simplement goûter à des pixels à partir d'une distribution définie par alpha . Notez qu'un tel échantillonnage probabiliste est non déterministe ou stochastique , c'est-à-dire qu'une entrée spécifique ne produira pas toujours la même sortie. Mais comme la descente de gradient suppose que le réseau est déterministe (et donc différenciable), l'échantillonnage est retravaillé pour éliminer sa stochasticité. Ma connaissance est assez superficielle à ce stade - je mettrai à jour cette réponse lorsque j'aurai une compréhension plus détaillée.
Comment utiliser un réseau d'attention pour une tâche PNL comme un modèle de séquence pour séquence?
Tout comme vous utilisez un CNN pour générer un codage avec des fonctionnalités à chaque pixel, vous utiliseriez un RNN pour générer des fonctionnalités codées à chaque position de mot horaire, c'est-à-dire dans l'entrée.
Sans attention, vous utiliseriez la sortie de l'encodeur au dernier pas de temps comme codage pour toute la phrase, car il contiendrait également des informations à partir de temps de temps antérieurs. La dernière sortie de l'encodeur supporte désormais le fardeau de devoir coder toute la phrase de manière significative, ce qui n'est pas facile, surtout pour des phrases plus longues.
Avec l'attention, vous assisriez sur les pas de temps de la sortie de l'encodeur, générant des poids pour chaque pas de temps / mot, et prenez la moyenne pondérée pour représenter la phrase. Dans une séquence pour séquencer la tâche comme la traduction machine, vous assisriez aux mots pertinents dans l'entrée lorsque vous générez chaque mot dans la sortie.
Vous pouvez également utiliser l'attention sans décodeur. Par exemple, si vous souhaitez classer le texte, vous pouvez assister aux mots importants de l'entrée une seule fois pour effectuer la classification.
Pouvons-nous utiliser la recherche de faisceau pendant la formation?
Pas avec la fonction de perte actuelle, mais oui. Ce n'est pas du tout courant.
Qu'est-ce que les enseignants forcent?
Le forçage des enseignants, c'est lorsque nous utilisons les légendes de la vérité au sol comme entrée au décodeur à chaque étalage, et non le mot qu'il a généré dans le pas de temps précédent. Il est courant de la force des enseignants pendant la formation, car cela pourrait signifier une convergence plus rapide du modèle. Mais il peut également apprendre à dépendre de la dise de la bonne réponse et de présenter une certaine instabilité dans la pratique.
Il serait idéal de s'entraîner en utilisant un enseignant ne forçant que une partie du temps, en fonction d'une probabilité. C'est ce qu'on appelle l'échantillonnage prévu.
(Je prévois d'ajouter l'option).
Puis-je utiliser des incorporations de mots pré-entraînées (gant, cbow, skipgram, etc.) au lieu de les apprendre à partir de zéro?
Oui, vous pouvez, avec la méthode load_pretrained_embeddings() dans la classe Decoder . Vous pouvez également choisir d'adapter (ou non) avec la méthode fine_tune_embeddings() .
Après avoir créé le décodeur dans train.py , vous devez fournir les vecteurs pré-entraînés à load_pretrained_embeddings() empilés dans le même ordre que dans le word_map . Pour les mots pour lesquels vous n'avez pas de vecteurs pré-entraînés, comme <start> , vous pouvez initialiser les intégres au hasard comme nous l'avons fait dans init_weights() . Je recommande du réglage fin pour apprendre des vecteurs plus significatifs pour ces vecteurs initialisés au hasard.
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False Assurez-vous également de modifier le paramètre emb_dim de sa valeur actuelle de 512 à la taille de vos intérêts pré-formés. Cela devrait ajuster automatiquement la taille d'entrée du décodeur LSTM pour les accueillir.
Comment suivre les tenseurs permettent de calculer les gradients?
Avec la libération de Pytorch 0.4 , envelopper les tenseurs en tant que Variable ne sont plus nécessaires. Au lieu de cela, les tenseurs ont l'attribut requires_grad , qui décide s'il est suivi par autograd , et donc si les gradients sont calculés pour cela pendant la rétro-propagation.
requires_grad sera défini sur False .requires_grad sur True .torch.nn auront déjà requires_grad Set sur True .Comment calculer toutes les scores BLEU (c'est-à-dire Bleu-1 à Bleu-4) pendant l'évaluation?
Vous devrez modifier le code dans eval.py pour ce faire. Veuillez consulter cette excellente réponse de Kmario23 pour une explication claire et détaillée.


