a PyTorch Tutorial to Image Captioning
1.0.0
นี่คือ การสอน Pytorch สำหรับคำบรรยายภาพ
นี่เป็นครั้งแรกในชุดของบทเรียนที่ฉันเขียนเกี่ยวกับ การใช้ โมเดลเย็น ๆ ด้วยตัวคุณเองด้วยห้องสมุด Pytorch ที่น่าตื่นตาตื่นใจ
ความรู้พื้นฐานของ Pytorch, เครือข่ายประสาทและการเกิดซ้ำของระบบประสาทจะถือว่า
หากคุณยังใหม่กับ Pytorch ก่อนอื่นให้อ่านการเรียนรู้อย่างลึกซึ้งกับ Pytorch: Blitz 60 นาทีและการเรียนรู้ Pytorch พร้อมตัวอย่าง
คำถามคำแนะนำหรือการแก้ไขสามารถโพสต์เป็นปัญหา
ฉันใช้ PyTorch 0.4 ใน Python 3.6
27 ม.ค. 2020 : มีการเพิ่มรหัสการทำงานสำหรับสองบทเรียนใหม่-การแปลความละเอียดสูงและการแปลของเครื่อง
วัตถุประสงค์
แนวคิด
ภาพรวม
การดำเนินการ
การฝึกอบรม
การอนุมาน
คำถามที่พบบ่อย
ในการสร้างแบบจำลองที่สามารถสร้างคำอธิบายภาพเชิงพรรณนาสำหรับภาพที่เราให้ไว้
เพื่อประโยชน์ในการรักษาสิ่งต่าง ๆ ให้เรียบง่ายมาใช้ การแสดงเข้าร่วมและบอก กระดาษ นี่ไม่ใช่สิ่งที่ทันสมัยในปัจจุบัน แต่ก็ยังน่าทึ่งมาก การใช้งานดั้งเดิมของผู้เขียนสามารถพบได้ที่นี่
รุ่นนี้เรียนรู้ว่าจะดู ที่ไหน
ในขณะที่คุณสร้างคำบรรยายภาพโดยใช้คำพูดคุณสามารถเห็นการจ้องมองของรุ่นเปลี่ยนไปทั่วภาพ
สิ่งนี้เป็นไปได้เนื่องจากกลไก ความสนใจ ซึ่งช่วยให้สามารถมุ่งเน้นไปที่ส่วนของภาพที่เกี่ยวข้องกับคำที่มันจะเปล่งออกมาต่อไป
นี่คือคำอธิบายภาพบางส่วนที่สร้างขึ้นในภาพ ทดสอบ ที่ไม่เห็นในระหว่างการฝึกอบรมหรือการตรวจสอบ:




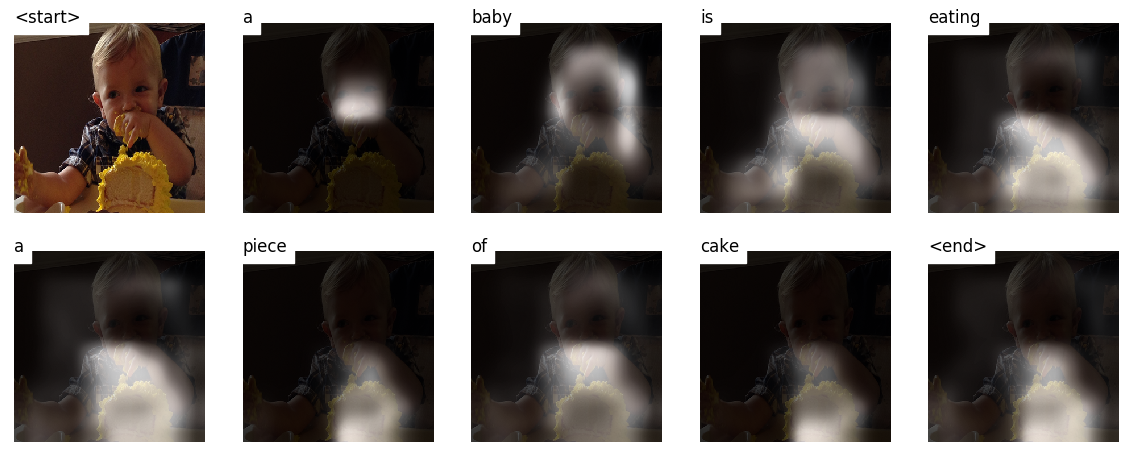

มีตัวอย่างเพิ่มเติมในตอนท้ายของการสอน
คำบรรยายภาพ DUH.
สถาปัตยกรรมเครื่องเข้ารหัส โดยทั่วไปแล้วโมเดลที่สร้างลำดับจะใช้ตัวเข้ารหัสเพื่อเข้ารหัสอินพุตลงในรูปแบบคงที่และตัวถอดรหัสเพื่อถอดรหัสคำโดยคำเป็นลำดับ
ความสนใจ . การใช้เครือข่ายความสนใจนั้นแพร่หลายในการเรียนรู้อย่างลึกซึ้งและมีเหตุผลที่ดี นี่เป็นวิธีสำหรับแบบจำลองในการเลือกเฉพาะส่วนเหล่านั้นของการเข้ารหัสที่คิดว่าเกี่ยวข้องกับงานที่อยู่ในมือ กลไกเดียวกับที่คุณเห็นที่ใช้ที่นี่สามารถใช้ในรุ่นใดก็ได้ที่เอาต์พุตของตัวเข้ารหัสมีหลายจุดในอวกาศหรือเวลา ในคำบรรยายภาพคุณจะพิจารณาพิกเซลที่สำคัญกว่าอื่น ๆ ตามลำดับการจัดลำดับงานเช่นการแปลของเครื่องคุณจะพิจารณาคำบางคำที่สำคัญกว่าคำอื่น ๆ
ถ่ายโอนการเรียนรู้ นี่คือเมื่อคุณยืมจากโมเดลที่มีอยู่โดยใช้ชิ้นส่วนของมันในรุ่นใหม่ นี่เป็นสิ่งที่ดีกว่าการฝึกอบรมรุ่นใหม่ตั้งแต่เริ่มต้น (เช่นไม่รู้อะไรเลย) อย่างที่คุณจะเห็นคุณสามารถปรับความรู้มือสองนี้ให้เข้ากับงานเฉพาะที่อยู่ในมือ การใช้การฝังคำที่ทำไว้ล่วงหน้าเป็นตัวอย่างที่โง่ แต่ถูกต้อง สำหรับปัญหาคำบรรยายภาพของเราเราจะใช้เครื่องเข้ารหัสที่ผ่านการปรับแต่งแล้วปรับแต่งตามต้องการ
การค้นหาลำแสง นี่คือที่ที่คุณไม่ปล่อยให้ตัวถอดรหัสของคุณขี้เกียจและเพียงแค่เลือกคำที่มีคะแนน ที่ดีที่สุด ในแต่ละขั้นตอนการถอดรหัส การค้นหาลำแสงมีประโยชน์สำหรับปัญหาการสร้างแบบจำลองภาษาใด ๆ เพราะพบลำดับที่ดีที่สุด
ในส่วนนี้ฉันจะนำเสนอภาพรวมของรุ่นนี้ หากคุณคุ้นเคยกับมันแล้วคุณสามารถข้ามไปยังส่วนการใช้งานหรือรหัสความคิดเห็นได้โดยตรง
ตัวเข้ารหัส เข้ารหัสภาพอินพุตด้วยช่องสี 3 ช่องเป็นภาพขนาดเล็กที่มีช่อง "เรียนรู้"
ภาพที่เข้ารหัสขนาดเล็กนี้เป็นตัวแทนสรุปทั้งหมดที่มีประโยชน์ในภาพต้นฉบับ
เนื่องจากเราต้องการเข้ารหัสภาพเราจึงใช้เครือข่ายประสาทเทียม (CNNS)
เราไม่จำเป็นต้องฝึกตัวเข้ารหัสตั้งแต่เริ่มต้น ทำไม เพราะมี CNNs ที่ผ่านการฝึกอบรมมาแล้วเพื่อแสดงภาพ
เป็นเวลาหลายปีที่ผู้คนสร้างแบบจำลองที่ดีเป็นพิเศษในการจำแนกภาพเป็นหนึ่งในหมวดหมู่หนึ่งพัน มันหมายถึงเหตุผลที่โมเดลเหล่านี้จับภาพสาระสำคัญของภาพได้ดีมาก
ฉันเลือกที่จะใช้ เครือข่ายที่เหลืออยู่ 101 ชั้นที่ผ่านการฝึกอบรมเกี่ยวกับงานการจำแนกประเภท Imagenet ซึ่งมีอยู่แล้วใน Pytorch ตามที่ระบุไว้ก่อนหน้านี้นี่เป็นตัวอย่างของการเรียนรู้การถ่ายโอน คุณมีตัวเลือกในการปรับแต่งเพื่อปรับปรุงประสิทธิภาพ

โมเดลเหล่านี้สร้างการแสดงภาพต้นฉบับที่เล็กลงและเล็กลงอย่างต่อเนื่องและการเป็นตัวแทนที่ตามมาแต่ละครั้งจะ "เรียนรู้" มากขึ้นด้วยจำนวนช่องทางที่มากขึ้น การเข้ารหัสครั้งสุดท้ายที่ผลิตโดย Resnet-101 encoder ของเรามีขนาด 14x14 พร้อมช่อง 2048 ช่องเช่น 2048, 14, 14 ขนาดเทนเซอร์
ฉันขอแนะนำให้คุณทดลองกับสถาปัตยกรรมที่ผ่านการฝึกอบรมมาก่อน กระดาษใช้ VGGNET ซึ่งได้รับการปรับแต่งบน ImageNet แต่ไม่มีการปรับแต่ง ไม่ว่าจะด้วยวิธีใดจำเป็นต้องมีการแก้ไข เนื่องจากเลเยอร์สุดท้ายหรือสองรุ่นเหล่านี้เป็นเลเยอร์เชิงเส้นควบคู่ไปกับการเปิดใช้งาน Softmax สำหรับการจำแนกประเภทเราจึงตัดมันออกไป
งานของตัวถอดรหัสคือการ ดูภาพที่เข้ารหัสและสร้างคำบรรยายตามคำ
เนื่องจากมันกำลังสร้างลำดับจึงจะต้องเป็นเครือข่ายประสาท (RNN) เราจะใช้ LSTM
ในการตั้งค่าทั่วไปโดยไม่ได้รับความสนใจคุณสามารถเฉลี่ยภาพที่เข้ารหัสผ่านพิกเซลทั้งหมด จากนั้นคุณสามารถป้อนสิ่งนี้ได้โดยมีหรือไม่มีการเปลี่ยนแปลงเชิงเส้นเข้าสู่ตัวถอดรหัสเป็นสถานะที่ซ่อนอยู่ครั้งแรกและสร้างคำบรรยายภาพ แต่ละคำที่คาดการณ์จะใช้เพื่อสร้างคำถัดไป
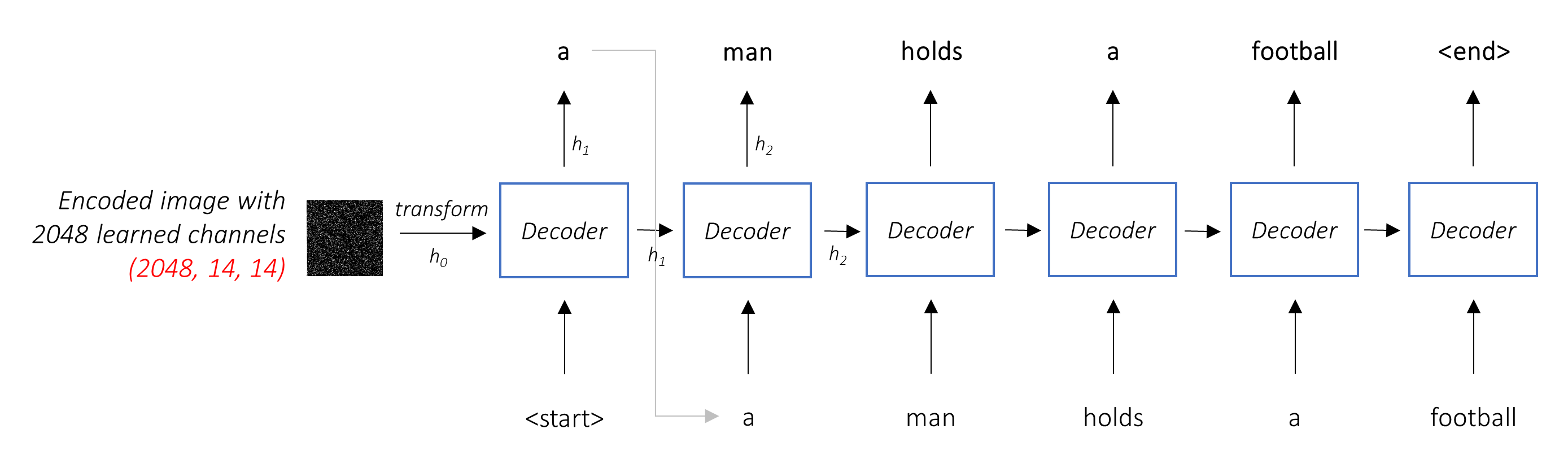
ในการตั้งค่า ที่มี ความสนใจเราต้องการให้ตัวถอดรหัสสามารถ ดูส่วนต่าง ๆ ของภาพที่จุดต่าง ๆ ในลำดับ ตัวอย่างเช่นในขณะที่สร้างคำว่า football ใน a man holds a football ตัวถอดรหัสจะรู้ว่าจะมุ่งเน้น - คุณเดาได้ - ฟุตบอล!
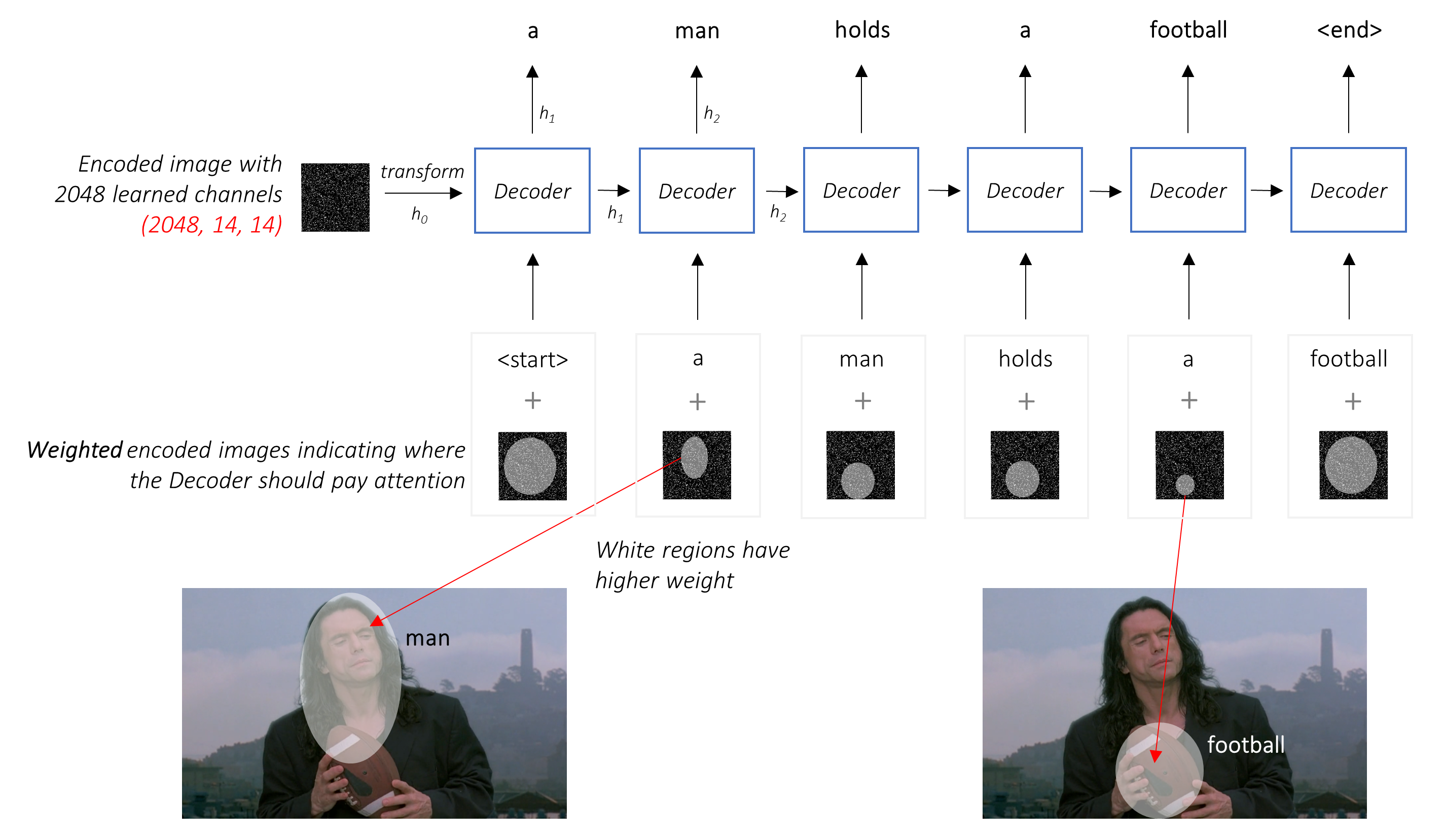
แทนที่จะเป็นค่าเฉลี่ยง่าย ๆ เราใช้ค่าเฉลี่ย ถ่วงน้ำหนัก ในพิกเซลทั้งหมดด้วยน้ำหนักของพิกเซลที่สำคัญยิ่งขึ้น การเป็นตัวแทนถ่วงน้ำหนักของภาพนี้สามารถเชื่อมต่อกับคำที่สร้างขึ้นก่อนหน้านี้ในแต่ละขั้นตอนเพื่อสร้างคำถัดไป
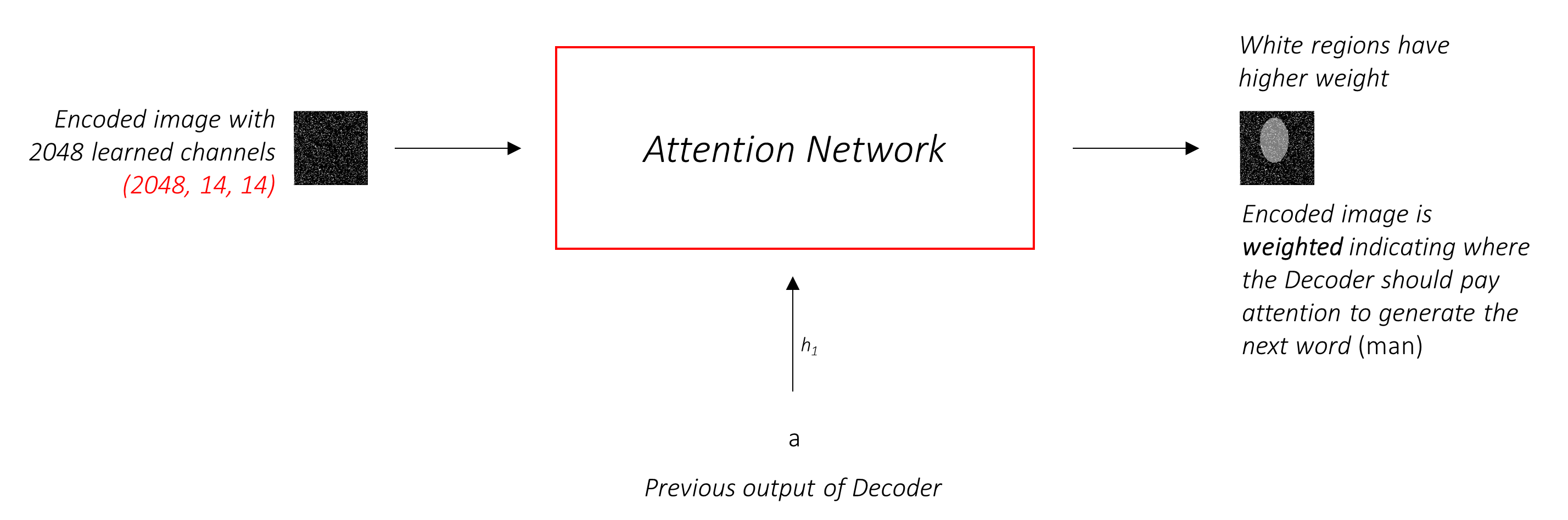
เครือข่ายความสนใจ คำนวณน้ำหนักเหล่านี้
โดยสังหรณ์ใจคุณจะประเมินความสำคัญของส่วนหนึ่งของภาพได้อย่างไร คุณจะต้องตระหนักถึงลำดับที่คุณสร้างมา จนถึงตอนนี้ ดังนั้นคุณสามารถดูภาพและตัดสินใจว่าต้องการอะไรอธิบายต่อไป ตัวอย่างเช่นหลังจากที่คุณพูดถึง a man มันมีเหตุผลที่จะประกาศว่าเขากำลัง holding a football
นี่คือสิ่งที่กลไกความสนใจทำ - พิจารณาลำดับที่สร้างขึ้นมาแล้วและ เข้าร่วม ในส่วนของภาพที่ต้องการอธิบายต่อไป
เราจะใช้ความสนใจ อย่างนุ่มนวล ซึ่งน้ำหนักของพิกเซลเพิ่มขึ้นถึง 1 ถ้ามีพิกเซล P ในภาพที่เข้ารหัสของเราจากนั้นในแต่ละครั้ง t - timestep t -
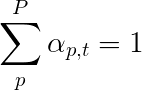
คุณสามารถตีความกระบวนการทั้งหมดนี้เป็นการคำนวณ ความน่าจะเป็นที่พิกเซลเป็น สถาน ที่ที่จะสร้างคำต่อไป
ตอนนี้อาจชัดเจนว่าเครือข่ายรวมของเราเป็นอย่างไร
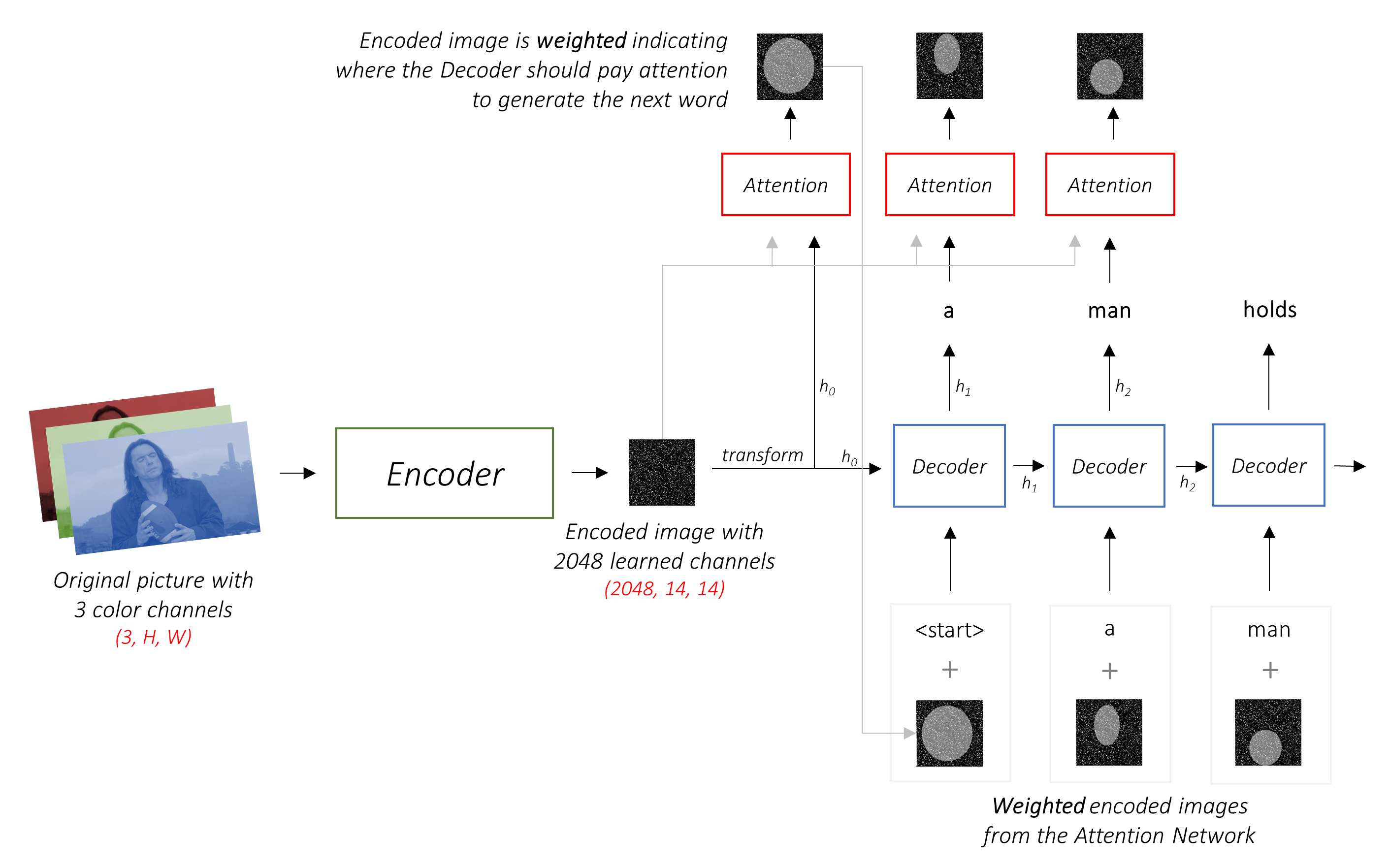
h (และสถานะเซลล์ C ) สำหรับตัวถอดรหัส LSTMเราใช้เลเยอร์เชิงเส้นเพื่อแปลงเอาต์พุตของตัวถอดรหัสเป็นคะแนนสำหรับแต่ละคำในคำศัพท์
ตัวเลือกที่ตรงไปตรงมา - และโลภ - คือการเลือกคำที่มีคะแนนสูงสุดและใช้เพื่อทำนายคำต่อไป แต่นี่ไม่เหมาะสมเพราะส่วนที่เหลือของบานพับลำดับในคำแรกที่คุณเลือก หากตัวเลือกนั้นไม่ได้ดีที่สุดทุกอย่างที่ตามมาคือการเลือกย่อย และไม่ใช่แค่คำแรก - แต่ละคำในลำดับมีผลที่ตามมาสำหรับคำที่ประสบความสำเร็จ
มันอาจจะเกิดขึ้นได้ดีว่าถ้าคุณเลือกคำที่ดีที่สุดที่ สาม ในขั้นตอนแรกและคำที่ดีที่สุด อันดับสอง ในขั้นตอนที่สองและอื่น ๆ ... นั่น จะเป็นลำดับที่ดีที่สุดที่คุณสามารถสร้างได้
มันจะเป็นการดีที่สุดถ้าเรา ไม่ สามารถตัดสินใจได้จนกว่าเราจะถอดรหัสเสร็จสมบูรณ์และ เลือกลำดับที่มีคะแนน โดยรวม สูงสุดจากตะกร้าลำดับผู้สมัคร
การค้นหาลำแสงทำสิ่งนี้อย่างแน่นอน
k อันดับต้น ๆk สำหรับคำแรก k แต่ละคำเหล่านี้k [คำแรกคำที่สอง] ชุดค่าผสมพิจารณาคะแนนเพิ่มเติมk เหล่านี้แต่ละคำเลือก k คำที่สามเลือก k [คำแรกคำแรกคำที่สองคำที่สาม] ชุดค่าผสมk สิ้นสุดให้เลือกลำดับด้วยคะแนนโดยรวมที่ดีที่สุด 
อย่างที่คุณเห็นบางลำดับ (ตีออก) อาจล้มเหลวเร็วเนื่องจากพวกเขาไม่ได้ไปที่ k สูงสุดในขั้นตอนต่อไป เมื่อ k Sequences (ขีดเส้นใต้) สร้างโทเค็น <end> เราเลือกอันที่มีคะแนนสูงสุด
ส่วนด้านล่างอธิบายการใช้งานสั้น ๆ
พวกเขามีความหมายที่จะให้บริบทบางอย่าง แต่ รายละเอียดเป็นที่เข้าใจได้ดีที่สุดโดยตรงจากรหัส ซึ่งมีความคิดเห็นค่อนข้างมาก
ฉันใช้ชุดข้อมูล MSCOCO '14 คุณต้องดาวน์โหลดภาพการฝึกอบรม (13GB) และการตรวจสอบความถูกต้อง (6GB)
เราจะใช้การฝึกอบรมการตรวจสอบความถูกต้องของ Andrej Karpathy และการแยกการทดสอบ ไฟล์ zip นี้มีคำอธิบายภาพ นอกจากนี้คุณยังจะพบกับการแยกและคำอธิบายภาพสำหรับชุดข้อมูล Flicker8K และ Flicker30K ดังนั้นอย่าลังเลที่จะใช้สิ่งเหล่านี้แทน MSCOCO หากหลังมีขนาดใหญ่เกินไปสำหรับคอมพิวเตอร์ของคุณ
เราจะต้องมีอินพุตสามตัว
เนื่องจากเรากำลังใช้เครื่องเข้ารหัสที่ผ่านการฝึกอบรมเราจะต้องประมวลผลภาพลงในรูปแบบการเข้ารหัสที่ผ่านการฝึกฝนนี้จึงคุ้นเคย
โมเดล Imagenet ที่ได้รับการฝึกฝนไว้เป็นส่วนหนึ่งของโมดูล torchvision ของ Pytorch หน้านี้มีรายละเอียดเกี่ยวกับการประมวลผลล่วงหน้าหรือการแปลงที่เราต้องดำเนินการ - ค่าพิกเซลจะต้องอยู่ในช่วง [0,1] และจากนั้นเราจะต้องทำให้ภาพปกติโดยค่าเฉลี่ยและค่าเบี่ยงเบนมาตรฐานของช่องสัญญาณ RGB ของ Imagenet Image Image
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]นอกจากนี้ Pytorch เป็นไปตามอนุสัญญา NCHW ซึ่งหมายถึงมิติของช่อง (c) จะต้องนำหน้าขนาดขนาด
เราจะปรับขนาดภาพ MSCOCO ทั้งหมดเป็น 256x256 เพื่อความสม่ำเสมอ
ดังนั้น ภาพที่ป้อนเข้ากับแบบจำลองจะต้องเป็นเทนเซอร์ Float ของมิติ N, 3, 256, 256 และจะต้องได้รับการทำให้เป็นมาตรฐานโดยค่าเฉลี่ยดังกล่าวและค่าเบี่ยงเบนมาตรฐาน N คือขนาดแบทช์
คำอธิบายภาพเป็นทั้งเป้าหมายและอินพุตของตัวถอดรหัสเนื่องจากแต่ละคำใช้เพื่อสร้างคำถัดไป
อย่างไรก็ตามในการสร้างคำแรกเราต้องใช้คำ Zeroth , <start>
ในคำสุดท้ายเราควรทำนาย <end> ตัวถอดรหัสจะต้องเรียนรู้ที่จะทำนายจุดสิ้นสุดของคำบรรยายภาพ สิ่งนี้จำเป็นเพราะเราจำเป็นต้องรู้ว่าเมื่อใดที่จะหยุดการถอดรหัสระหว่างการอนุมาน
<start> a man holds a football <end>
เนื่องจากเราผ่านคำอธิบายภาพเป็นเทนเซอร์ขนาดคงที่เราจำเป็นต้องใช้คำอธิบายภาพ (ซึ่งเป็นธรรมชาติของความยาวที่แตกต่างกัน) ความยาวเท่ากันกับโทเค็น <pad>
<start> a man holds a football <end> <pad> <pad> <pad>....
นอกจากนี้เรายังสร้าง word_map ซึ่งเป็นการแมปดัชนีสำหรับแต่ละคำในคลังข้อมูลรวมถึง <start> , <end> และ <pad> TOKENS Pytorch เช่นเดียวกับห้องสมุดอื่น ๆ ต้องการคำที่เข้ารหัสเป็นดัชนีเพื่อค้นหาการฝังตัวสำหรับพวกเขาหรือเพื่อระบุสถานที่ของพวกเขาในคะแนนคำที่คาดการณ์ไว้
9876 1 5 120 1 5406 9877 9878 9878 9878....
ดังนั้น คำอธิบายภาพที่ป้อนเข้ากับแบบจำลองจะต้องเป็นเทนเซอร์ Int ของมิติ N, L โดยที่ L คือความยาวเบาะ
เนื่องจากคำอธิบายภาพเบาะเราจะต้องติดตามความยาวของคำบรรยายแต่ละคำ นี่คือความยาวจริง + 2 (สำหรับ <start> และ <end> โทเค็น)
ความยาวคำบรรยายภาพก็มีความสำคัญเช่นกันเพราะคุณสามารถสร้างกราฟแบบไดนามิกด้วย pytorch เราประมวลผลลำดับความยาวของมันเท่านั้นและไม่ต้องคำนวณการคำนวณบน <pad> s
ดังนั้น ความยาวของคำบรรยายภาพที่ป้อนเข้ากับโมเดลจะต้องเป็นเทนเซอร์ Int ของมิติ N
ดู create_input_files() ใน utils.py
สิ่งนี้จะอ่านข้อมูลที่ดาวน์โหลดและบันทึกไฟล์ต่อไปนี้ -
I, 3, 256, 256 เทนเซอร์ ที่ I คือจำนวนภาพในการแยก ค่าพิกเซลยังคงอยู่ในช่วง [0, 255] และถูกเก็บไว้เป็น Int 8 บิตที่ไม่ได้ลงชื่อN_c * I คำอธิบายภาพที่เข้ารหัส โดยที่ N_c คือจำนวนคำอธิบายภาพตัวอย่างต่อภาพ คำบรรยายเหล่านี้อยู่ในลำดับเดียวกับรูปภาพในไฟล์ HDF5 ดังนั้นคำบรรยายภาพ i th จะสอดคล้องกับภาพ i // N_c thN_c * I ความยาวคำบรรยายภาพ ค่า i th คือความยาวของคำบรรยายภาพ i ซึ่งสอดคล้องกับภาพ i // N_c thword_map ซึ่งเป็นพจนานุกรม Word-to-Index ก่อนที่เราจะบันทึกไฟล์เหล่านี้เรามีตัวเลือกในการใช้คำอธิบายภาพที่สั้นกว่า <unk> เท่านั้น
เราใช้ไฟล์ HDF5 สำหรับรูปภาพเพราะเราจะอ่านโดยตรงจากดิสก์ระหว่างการฝึกอบรม / การตรวจสอบ พวกมันใหญ่เกินไปที่จะพอดีกับ Ram ทั้งหมดในครั้งเดียว แต่เราโหลดคำบรรยายทั้งหมดและความยาวของพวกเขาลงในหน่วยความจำ
ดู CaptionDataset ใน datasets.py
นี่คือคลาสย่อยของ Dataset Pytorch มันต้องการวิธีการ __len__ ที่กำหนดซึ่งส่งคืนขนาดของชุดข้อมูลและวิธี __getitem__ ซึ่งส่งคืนภาพ i th, คำอธิบายภาพและความยาวคำบรรยายภาพ
เราอ่านภาพจากดิสก์แปลงพิกเซลเป็น [0,255] และทำให้เป็นปกติภายในคลาสนี้
Dataset จะถูกใช้โดย pytorch DataLoader ใน train.py เพื่อสร้างและป้อนแบทช์ข้อมูลไปยังแบบจำลองสำหรับการฝึกอบรมหรือการตรวจสอบความถูกต้อง
ดู Encoder ใน models.py
เราใช้ resnet-101 ที่ผ่านการฝึกอบรมไว้แล้วในโมดูล torchvision ของ Pytorch ทิ้งสองเลเยอร์สุดท้าย (การรวมและเลเยอร์เชิงเส้น) เนื่องจากเราจำเป็นต้องเข้ารหัสภาพเท่านั้นและไม่จำแนก
เราเพิ่มเลเยอร์ AdaptiveAvgPool2d() เพื่อ ปรับขนาดการเข้ารหัสให้มีขนาดคงที่ สิ่งนี้ทำให้สามารถป้อนภาพขนาดตัวแปรให้กับตัวเข้ารหัส (เราได้ปรับขนาดภาพอินพุตของเราเป็น 256, 256 เพราะเราต้องเก็บไว้ด้วยกันเป็นเทนเซอร์เดียว)
เนื่องจากเราอาจต้องการปรับแต่งเครื่องเข้ารหัสเราจึงเพิ่มวิธีการ fine_tune() ซึ่งเปิดใช้งานหรือปิดใช้งานการคำนวณการไล่ระดับสีสำหรับพารามิเตอร์ของตัวเข้ารหัส เรา ปรับการปรับบล็อก convolutional 2 ถึง 4 ใน resnet เพราะบล็อก convolutional แรกมักจะเรียนรู้บางสิ่งบางอย่างพื้นฐานมากในการประมวลผลภาพเช่นการตรวจจับเส้นขอบเส้นโค้ง ฯลฯ เราไม่ยุ่งกับฐานราก
ดู Attention ใน models.py
เครือข่ายความสนใจนั้นง่าย - ประกอบด้วยเลเยอร์เชิงเส้นเท่านั้นและการเปิดใช้งานสองสามครั้ง
เลเยอร์เชิงเส้นแยก แปลงทั้งภาพที่เข้ารหัส (แบนเป็น N, 14 * 14, 2048 ) และสถานะที่ซ่อนอยู่ (เอาท์พุท) จากตัวถอดรหัสไปยังมิติเดียวกัน ได้แก่ ขนาดความสนใจ พวกเขาจะถูกเพิ่มและเปิดใช้งาน relu เลเยอร์เชิงเส้นที่สาม แปลงผลลัพธ์นี้เป็นมิติ 1 ดังนั้นเราจึง ใช้ softmax เพื่อสร้างน้ำหนัก alpha
ดู DecoderWithAttention ใน models.py
เอาต์พุตของตัวเข้ารหัสได้รับที่นี่และแบนเป็นขนาด N, 14 * 14, 2048 นี่เป็นสิ่งที่สะดวกและป้องกันไม่ให้ปรับเปลี่ยนเทนเซอร์หลายครั้ง
เรา เริ่มต้นสถานะที่ซ่อนและเซลล์ของ LSTM โดยใช้อิมเมจที่เข้ารหัสด้วยเมธอด init_hidden_state() ซึ่งใช้สองชั้นเชิงเส้นแยกกัน
ในตอนแรกเรา เรียง N ภาพและคำอธิบายภาพโดยการลดความยาวของคำบรรยายภาพ นี่คือเพื่อให้เราสามารถประมวลผลเฉพาะเวลา ที่ถูกต้อง เช่นไม่ใช่การประมวลผล <pad> s
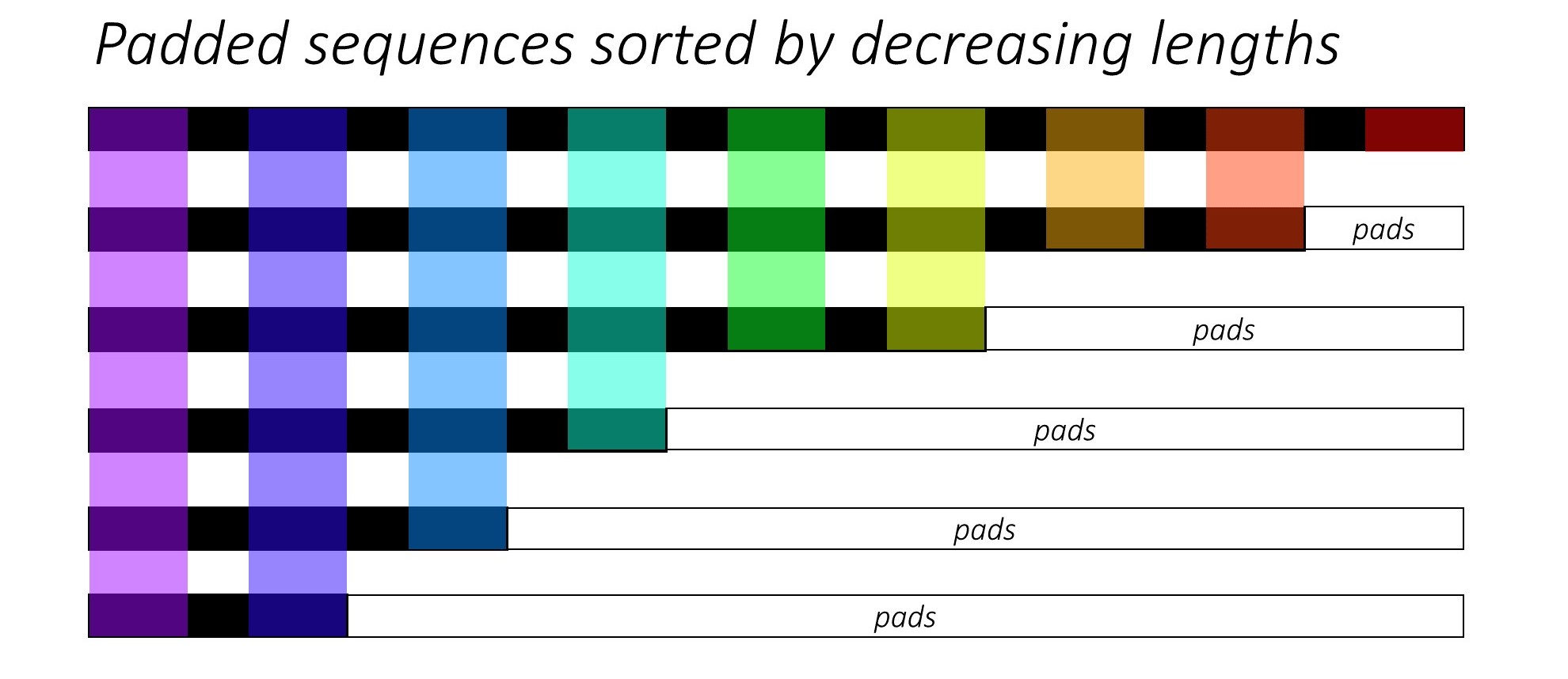
เราสามารถวนซ้ำในแต่ละช่วงเวลาโดยประมวลผลเฉพาะภูมิภาคที่มีสีซึ่งเป็น ขนาดแบทช์ ที่มีประสิทธิภาพ N_t ในเวลานั้น การเรียงลำดับอนุญาตให้ N_t บนสุดที่กำหนดเวลาใด ๆ ให้สอดคล้องกับเอาต์พุตจากขั้นตอนก่อนหน้า ตัวอย่างเช่นครั้งที่สามเราจะประมวลผลเฉพาะภาพ 5 อันดับแรกโดยใช้เอาต์พุต 5 อันดับแรกจากขั้นตอนก่อนหน้า
การทำซ้ำนี้ดำเนินการ ด้วยตนเอง ใน for วนรอบ ด้วย pytorch LSTMCell แทนที่จะทำซ้ำโดยอัตโนมัติโดยไม่ต้องวนรอบด้วย pytorch LSTM นี่เป็นเพราะเราจำเป็นต้องดำเนินการกลไกความสนใจระหว่างแต่ละขั้นตอนการถอดรหัส LSTMCell เป็นการดำเนินการครั้งเดียวในขณะที่ LSTM จะวนซ้ำหลายครั้งอย่างต่อเนื่องและให้ผลลัพธ์ทั้งหมดในครั้งเดียว
เรา คำนวณน้ำหนักและการเข้ารหัสน้ำหนักความสนใจ ในแต่ละช่วงเวลาด้วยเครือข่ายความสนใจ ในส่วนที่ 4.2.1 ของกระดาษพวกเขาแนะนำ ให้ผ่านการเข้ารหัสน้ำหนักความสนใจผ่านตัวกรองหรือประตู ประตูนี้เป็นการแปลงเชิงเส้นที่เปิดใช้งาน sigmoid ของสถานะที่ซ่อนอยู่ก่อนหน้าของตัวถอดรหัส ผู้เขียนระบุว่าสิ่งนี้ช่วยให้เครือข่ายความสนใจให้ความสำคัญกับวัตถุในภาพมากขึ้น
เรา เชื่อมต่อการเข้ารหัสน้ำหนักที่ได้รับการกรองด้วยการฝังคำก่อนหน้านี้ ( <start> เพื่อเริ่มต้น) และเรียกใช้ LSTMCell เพื่อ สร้างสถานะที่ซ่อนอยู่ใหม่ (หรือเอาท์พุท) เลเยอร์เชิงเส้น แปลงสถานะที่ซ่อนอยู่ใหม่นี้เป็นคะแนนสำหรับแต่ละคำในคำศัพท์ ซึ่งเก็บไว้
นอกจากนี้เรายังเก็บน้ำหนักที่ส่งคืนโดยเครือข่ายความสนใจในแต่ละช่วงเวลา คุณจะเห็นว่าทำไมเร็วพอ
ก่อนที่คุณจะเริ่มตรวจสอบให้แน่ใจว่าได้บันทึกไฟล์ข้อมูลที่จำเป็นสำหรับการฝึกอบรมการตรวจสอบและการทดสอบ ในการทำเช่นนี้ให้เรียกใช้เนื้อหาของ create_input_files.py หลังจากชี้ไปที่ไฟล์ Karpathy JSON และโฟลเดอร์รูปภาพที่มีโฟลเดอร์ train2014 และ val2014 จากข้อมูลที่คุณดาวน์โหลด
ดู train.py
พารามิเตอร์สำหรับโมเดล (และการฝึกอบรม) อยู่ที่จุดเริ่มต้นของไฟล์ดังนั้นคุณสามารถตรวจสอบหรือแก้ไขได้อย่างง่ายดายหากคุณต้องการ
ใน การฝึกอบรมโมเดลของคุณตั้งแต่เริ่มต้น เพียงแค่เรียกใช้ไฟล์นี้ -
python train.py
ใน การกลับมาฝึกอบรมที่จุดตรวจสอบ ให้ชี้ไปที่ไฟล์ที่เกี่ยวข้องกับพารามิเตอร์ checkpoint ที่จุดเริ่มต้นของรหัส
โปรดทราบว่าเราทำการตรวจสอบความถูกต้องในตอนท้ายของการฝึกอบรมทุกครั้ง
เนื่องจากเรากำลังสร้างลำดับของคำเราจึงใช้ CrossEntropyLoss คุณจะต้องส่งคะแนนดิบจากเลเยอร์สุดท้ายในตัวถอดรหัสและฟังก์ชั่นการสูญเสียจะดำเนินการ SoftMax และการบันทึก
ผู้เขียนกระดาษแนะนำให้ใช้การสูญเสียครั้งที่สอง - " การทำให้เป็นปกติแบบสุ่มสองเท่า " เรารู้ว่าน้ำหนักรวมเป็น 1 ที่กำหนดเวลาที่กำหนด แต่เรายังสนับสนุนให้น้ำหนักที่พิกเซล p เดียวเป็นผลรวมถึง 1 ใน ทุก ช่วงเวลา T -
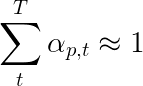
ซึ่งหมายความว่าเราต้องการให้โมเดลเข้าร่วมพิกเซลทุกพิกเซลตลอดระยะเวลาการสร้างลำดับทั้งหมด ดังนั้นเราจึงพยายาม ลดความแตกต่างระหว่าง 1 และผลรวมของน้ำหนักของพิกเซลในทุกช่วงเวลา
เราไม่คำนวณการสูญเสียในภูมิภาคเบาะ วิธีที่ง่ายในการกำจัดแผ่นรองคือการใช้ pack_padded_sequence() ของ Pytorch ซึ่งทำให้เทนเซอร์แบนโดยกำหนดเวลาในขณะที่เพิกเฉยต่อพื้นที่เบาะ ตอนนี้คุณสามารถรวมการสูญเสียของเทนเซอร์ที่แบนนี้
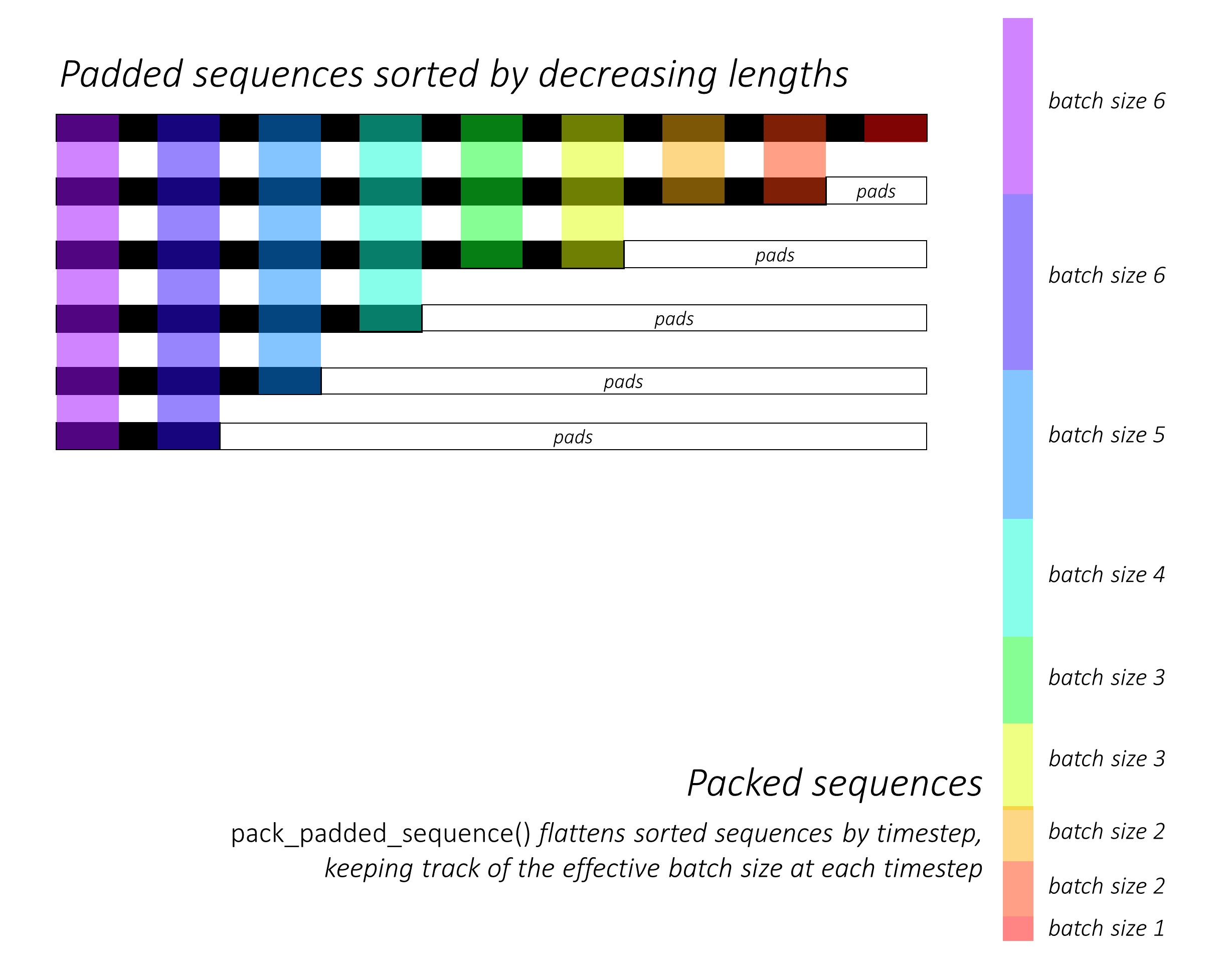
หมายเหตุ - ฟังก์ชั่นนี้ใช้จริงเพื่อดำเนินการแบทช์แบบไดนามิกเดียวกัน (เช่นการประมวลผลเฉพาะขนาดแบทช์ที่มีประสิทธิภาพในแต่ละช่วงเวลา) ที่เราดำเนินการในตัวถอดรหัสของเราเมื่อใช้ RNN หรือ LSTM ใน Pytorch ในกรณีนี้ Pytorch จัดการกราฟความยาวตัวแปรแบบไดนามิกภายใน คุณสามารถดูตัวอย่างใน dynamic_rnn.py ในบทช่วยสอนอื่นของฉันเกี่ยวกับการติดฉลากลำดับ เราจะใช้ฟังก์ชั่นนี้พร้อมกับ LSTM ในตัวถอดรหัสของเราหากเราไม่ได้ทำซ้ำด้วยตนเองเนื่องจากเครือข่ายความสนใจ
ในการประเมินประสิทธิภาพของโมเดลในชุดการตรวจสอบความถูกต้องเราจะใช้ตัวชี้วัดการประเมินผลการประเมินสองภาษาอัตโนมัติ (BLEU) สิ่งนี้จะประเมินคำอธิบายภาพที่สร้างขึ้นกับคำอธิบายอ้างอิง สำหรับคำบรรยายภาพแต่ละคำอธิบายเราจะใช้คำอธิบายภาพ N_c ทั้งหมดที่มีอยู่สำหรับภาพนั้นเป็นคำอธิบายภาพอ้างอิง
ผู้เขียนของ การแสดงเข้าร่วมและบอก กระดาษสังเกตว่าความสัมพันธ์ระหว่างการสูญเสียและคะแนน Bleu แบ่งลงหลังจากจุดหนึ่งดังนั้นพวกเขาจึงแนะนำให้หยุดการฝึกอบรมในช่วงต้นเมื่อคะแนน Bleu เริ่มลดลงแม้ว่าการสูญเสียจะลดลง
ฉันใช้เครื่องมือ BLEU ที่มีอยู่ในโมดูล NLTK
โปรดทราบว่ามีการวิพากษ์วิจารณ์อย่างมากเกี่ยวกับคะแนน Bleu เพราะมันไม่ได้มีความสัมพันธ์ที่ดีกับการตัดสินของมนุษย์เสมอไป ผู้เขียนยังรายงานคะแนนดาวตกด้วยเหตุผลนี้ แต่ฉันไม่ได้ใช้ตัวชี้วัดนี้
ฉันขอแนะนำให้คุณฝึกอบรมในขั้นตอน
ฉันได้รับการฝึกฝนเฉพาะตัวถอดรหัสเท่านั้นคือโดยไม่ต้องปรับแต่งเครื่องเข้ารหัสด้วยขนาดแบทช์ 80 ฉันได้รับการฝึกฝนมา 20 ยุคและคะแนน Bleu-4 สูงสุดที่ประมาณ 23.25 ในยุคที่ 13 ฉันใช้เครื่องมือเพิ่มประสิทธิภาพ Adam() ด้วยอัตราการเรียนรู้เริ่มต้น 4e-4
ฉันดำเนินการต่อจากจุดตรวจ Epoch ครั้งที่ 13 ที่อนุญาตให้ปรับแต่งเครื่องเข้ารหัสได้อย่างละเอียดด้วยขนาดแบทช์ 32 ขนาดแบทช์ที่เล็กกว่านั้นเป็นเพราะรุ่นนี้มีขนาดใหญ่ขึ้นเนื่องจากมีการไล่ระดับสีของตัวเข้ารหัส ด้วยการปรับแต่งคะแนนเพิ่มขึ้นเป็น 24.29 ในประมาณ 3 ยุค การฝึกอบรมอย่างต่อเนื่องอาจทำให้คะแนนสูงขึ้นเล็กน้อย แต่ฉันต้องทำ GPU ของฉันที่อื่น
ความแตกต่างที่สำคัญที่จะทำที่นี่คือฉันยังคงให้ความจริงพื้นดินเป็นอินพุตในแต่ละขั้นตอนการถอดรหัสในระหว่างการตรวจสอบ โดยไม่คำนึงถึงคำที่สร้างขึ้นล่าสุด สิ่งนี้เรียกว่า การบังคับครู ในขณะที่สิ่งนี้มักใช้ในระหว่างการฝึกอบรมเพื่อเร่งกระบวนการตามที่เรากำลังทำเงื่อนไขในระหว่างการตรวจสอบจะต้องเลียนแบบเงื่อนไขการอนุมานที่แท้จริงให้มากที่สุด ฉันยังไม่ได้ใช้การอนุมานแบบแบทช์ - โดยที่แต่ละคำในคำบรรยายใต้ภาพถูกสร้างขึ้นจากคำที่สร้างขึ้นก่อนหน้านี้และสิ้นสุดลงเมื่อกดโทเค็น <end>
เนื่องจากฉันกำลังบังคับใช้ครูในระหว่างการตรวจสอบคะแนน BLEU ที่วัดได้ข้างต้นบนคำบรรยายภาพที่เกิดขึ้น ไม่ได้ สะท้อนถึงประสิทธิภาพที่แท้จริง ในความเป็นจริงคะแนน Bleu เป็นตัวชี้วัดที่ออกแบบมาสำหรับการเปรียบเทียบคำอธิบายภาพที่สร้างขึ้นตามธรรมชาติกับคำบรรยายภาพความจริงที่มีความยาวแตกต่างกัน เมื่อมีการใช้การอนุมานแบบแบทช์แล้วเช่นไม่มีครูบังคับการหยุดก่อนด้วยคะแนน Bleu จะ 'เหมาะสม' อย่างแท้จริง
ด้วยสิ่งนี้ในใจฉันใช้ eval.py เพื่อคำนวณคะแนน Bleu-4 ที่ถูกต้องของจุดตรวจสอบรุ่นนี้ในชุดการตรวจสอบและทดสอบ โดยไม่ ต้องบังคับครูที่ขนาดลำแสงที่แตกต่างกัน-
| ขนาดลำแสง | การตรวจสอบความถูกต้อง Bleu-4 | ทดสอบ bleu-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
คะแนนการทดสอบสูงกว่าผลลัพธ์ในกระดาษและอาจเป็นเพราะวิธีการที่เครื่องคิดเลข Bleu ของเราได้รับการกำหนดค่าพารามิเตอร์ความจริงที่ว่าฉันใช้ตัวเข้ารหัส resnet และปรับแต่งเครื่องเข้ารหัสได้จริง
นอกจากนี้โปรดจำไว้ว่า-เมื่อการปรับแต่งระหว่างการเรียนรู้การถ่ายโอนมันจะดีกว่าที่จะใช้อัตราการเรียนรู้ที่เล็กกว่าสิ่งที่เคยใช้ในการฝึกอบรมแบบจำลองที่ยืมมา นี่เป็นเพราะโมเดลได้รับการปรับให้เหมาะสมแล้วและเราไม่ต้องการเปลี่ยนแปลงอะไรเร็วเกินไป ฉันใช้ Adam() สำหรับตัวเข้ารหัสเช่นกัน แต่ด้วยอัตราการเรียนรู้ 1e-4 ซึ่งเป็นหนึ่งในสิบของค่าเริ่มต้นสำหรับเครื่องมือเพิ่มประสิทธิภาพนี้
บน Titan X (Pascal) ใช้เวลา 55 นาทีต่อยุคโดยไม่ต้องปรับแต่งและ 2.5 ชั่วโมงด้วยการปรับแต่งที่ขนาดแบทช์ที่ระบุไว้
คุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมนี้และ word_map ที่เกี่ยวข้องได้ที่นี่
โปรดทราบว่าควรโหลดด่านตรวจสอบโดยตรงด้วย pytorch หรือส่งผ่านไปยัง caption.py - ดูด้านล่าง
ดู caption.py
ในระหว่างการอนุมานเรา ไม่สามารถ ใช้วิธี forward() โดยตรงในตัวถอดรหัสเพราะใช้การบังคับครู แต่เราจะต้อง ป้อนคำที่สร้างขึ้นก่อนหน้านี้ให้กับ LSTM ในแต่ละครั้ง
caption_image_beam_search() อ่านรูปภาพเข้ารหัสและใช้เลเยอร์ในตัวถอดรหัสตามลำดับที่ถูกต้องในขณะที่ใช้คำที่สร้างขึ้นก่อนหน้านี้เป็นอินพุตไปยัง LSTM ในแต่ละช่วงเวลา นอกจากนี้ยังรวมเอาการค้นหาลำแสง
visualize_att() สามารถใช้เพื่อแสดงภาพคำอธิบายภาพที่สร้างขึ้นพร้อมกับน้ำหนักในแต่ละช่วงเวลาตามที่เห็นในตัวอย่าง
ในการ อธิบายภาพ จากบรรทัดคำสั่งให้ชี้ไปที่ภาพจุดตรวจสอบโมเดลแผนที่คำ (และเป็นทางเลือกขนาดลำแสง) ดังนี้ -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
หรือใช้ฟังก์ชั่นในไฟล์ตามต้องการ
ดู eval.py ซึ่งใช้กระบวนการนี้สำหรับการคำนวณคะแนน Bleu ในชุดการตรวจสอบความถูกต้องโดยมีหรือไม่มีการค้นหาลำแสง





การทดสอบทอมมี่ ทัวริง - คุณรู้ว่า AI ไม่ใช่ AI จริงๆเพราะมันไม่ได้ดู ห้อง และไม่รู้จักความยิ่งใหญ่เมื่อเห็นมัน

คุณบอกว่าให้ ความสนใจ อย่างนุ่มนวล มีอืมให้ ความสนใจ อย่างหนัก ?
ใช่ การแสดงเข้าร่วมและบอก กระดาษใช้ทั้งสองสายพันธุ์และตัวถอดรหัสด้วยความสนใจ "ยาก" ทำงานได้ดีขึ้นเล็กน้อย
ด้วยความสนใจ อย่างนุ่มนวล ซึ่งเราใช้ที่นี่คุณกำลังคำนวณน้ำหนัก alpha และใช้ค่าเฉลี่ยถ่วงน้ำหนักของคุณสมบัติในทุกพิกเซล นี่คือการดำเนินการที่กำหนดและแตกต่างกันได้
ในความสนใจ อย่างหนัก คุณกำลังเลือกที่จะลองชิมพิกเซลบางส่วนจากการกระจายที่กำหนดโดย alpha โปรดทราบว่าการสุ่มตัวอย่างความน่าจะเป็นดังกล่าวนั้นไม่ได้กำหนดหรือ สุ่ม เช่นอินพุตเฉพาะจะไม่สร้างเอาต์พุตเดียวกันเสมอไป แต่เนื่องจากการสืบเชื้อสายการไล่ระดับสีสันนิษฐานว่าเครือข่ายมีการกำหนด (และแตกต่างกัน) การสุ่มตัวอย่างจะถูกทำใหม่เพื่อลบความสุ่ม ความรู้ของฉันเกี่ยวกับเรื่องนี้ค่อนข้างผิวเผิน ณ จุดนี้ - ฉันจะอัปเดตคำตอบนี้เมื่อฉันมีความเข้าใจอย่างละเอียดมากขึ้น
ฉันจะใช้เครือข่ายความสนใจสำหรับงาน NLP เช่นแบบจำลองลำดับเพื่อลำดับได้อย่างไร
เช่นเดียวกับที่คุณใช้ CNN เพื่อสร้างการเข้ารหัสด้วยคุณสมบัติในแต่ละพิกเซลคุณจะใช้ RNN เพื่อสร้างคุณสมบัติที่เข้ารหัสในแต่ละตำแหน่งของคำเช่นคำศัพท์ในอินพุต
หากไม่ได้รับความสนใจคุณจะใช้เอาต์พุตของตัวเข้ารหัสในช่วงเวลาสุดท้ายเป็นการเข้ารหัสสำหรับประโยคทั้งหมดเนื่องจากมันจะมีข้อมูลจากการจับเวลาก่อนหน้านี้ เอาท์พุทสุดท้ายของเข้ารหัสตอนนี้มีภาระในการเข้ารหัสประโยคทั้งหมดอย่างมีความหมายซึ่งไม่ใช่เรื่องง่ายโดยเฉพาะอย่างยิ่งสำหรับประโยคที่ยาวขึ้น
ด้วยความสนใจคุณจะเข้าร่วมช่วงเวลาในเอาท์พุทของตัวเข้ารหัสสร้างน้ำหนักสำหรับแต่ละครั้ง/คำและใช้ค่าเฉลี่ยถ่วงน้ำหนักเพื่อเป็นตัวแทนประโยค ในลำดับการจัดลำดับงานเช่นการแปลของเครื่องคุณจะเข้าร่วมกับคำที่เกี่ยวข้องในอินพุตในขณะที่คุณสร้างแต่ละคำในเอาต์พุต
คุณสามารถใช้ความสนใจได้โดยไม่ต้องถอดรหัส ตัวอย่างเช่นหากคุณต้องการจำแนกข้อความคุณสามารถเข้าร่วมกับคำสำคัญในอินพุตเพียงครั้งเดียวเพื่อทำการจำแนกประเภท
เราสามารถใช้การค้นหาลำแสงระหว่างการฝึกอบรมได้หรือไม่?
ไม่ใช่กับฟังก์ชั่นการสูญเสียปัจจุบัน แต่ใช่ นี่ไม่ใช่เรื่องธรรมดาเลย
ครูบังคับอะไร?
การบังคับให้ครูคือเมื่อเราใช้คำอธิบายความจริงพื้นฐานเป็นอินพุตของตัวถอดรหัสในแต่ละช่วงเวลาและไม่ใช่คำที่สร้างขึ้นในช่วงเวลาก่อนหน้า เป็นเรื่องธรรมดาสำหรับครู-กำลังในระหว่างการฝึกอบรมเนื่องจากอาจหมายถึงการบรรจบกันของแบบจำลองที่เร็วขึ้น แต่มันยังสามารถเรียนรู้ที่จะขึ้นอยู่กับการบอกคำตอบที่ถูกต้องและแสดงความไม่แน่นอนในทางปฏิบัติ
มันจะเหมาะอย่างยิ่งที่จะฝึกอบรมโดยใช้ครูบังคับให้ใช้เวลาเพียงบางส่วนเท่านั้นตามความน่าจะเป็น สิ่งนี้เรียกว่าการสุ่มตัวอย่างตามกำหนดเวลา
(ฉันวางแผนที่จะเพิ่มตัวเลือก)
ฉันสามารถใช้การฝังคำที่ผ่านการฝึกอบรม (ถุงมือ, cbow, skipgram ฯลฯ ) แทนที่จะเรียนรู้ตั้งแต่เริ่มต้นได้หรือไม่?
ใช่คุณทำได้ด้วยวิธี load_pretrained_embeddings() ในคลาส Decoder คุณสามารถเลือกที่จะปรับแต่ง (หรือไม่) ด้วยวิธี fine_tune_embeddings()
หลังจากสร้างตัวถอดรหัสใน train.py คุณควรจัดเตรียมเวกเตอร์ที่ถูกปรับสภาพให้กับ load_pretrained_embeddings() ซ้อนกันในลำดับเดียวกับใน word_map สำหรับคำพูดที่คุณไม่มีเวกเตอร์ที่ถูกเตรียมไว้เช่น <start> คุณสามารถเริ่มต้นการฝังตัวแบบสุ่มเหมือนที่เราทำใน init_weights() ฉันขอแนะนำให้ปรับแต่งเพื่อเรียนรู้เวกเตอร์ที่มีความหมายมากขึ้นสำหรับเวกเตอร์ที่เริ่มต้นแบบสุ่มเหล่านี้
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False ตรวจสอบให้แน่ใจว่าได้เปลี่ยนพารามิเตอร์ emb_dim จากค่าปัจจุบันที่ 512 เป็นขนาดของการฝังตัวที่ผ่านการฝึกอบรมล่วงหน้าของคุณ สิ่งนี้ควรปรับขนาดอินพุตของตัวถอดรหัส LSTM โดยอัตโนมัติเพื่อรองรับ
ฉันจะติดตามว่าเทนเซอร์ใดที่อนุญาตให้คำนวณการไล่ระดับสีได้อย่างไร
ด้วยการเปิดตัว pytorch 0.4 การห่อเทนเซอร์เป็น Variable S ไม่จำเป็นต้องใช้อีกต่อไป แต่เทนเซอร์มีแอตทริบิวต์ requires_grad ซึ่งตัดสินใจว่ามีการติดตามโดย autograd หรือไม่และดังนั้นจึงคำนวณว่าการไล่ระดับสีจะถูกคำนวณในระหว่างการ backpropagation หรือไม่
requires_grad จะถูกตั้งค่าเป็น Falserequires_grad เป็น Truetorch.nn จะต้องตั้ง True requires_grad ไว้แล้วฉันจะคำนวณคะแนน Bleu ทั้งหมด (เช่น Bleu-1 ถึง Bleu-4) ได้อย่างไรในระหว่างการประเมินผลได้อย่างไร
คุณต้องแก้ไขรหัสใน eval.py เพื่อทำสิ่งนี้ โปรดดูคำตอบที่ยอดเยี่ยมนี้โดย Kmario23 สำหรับคำอธิบายที่ชัดเจนและมีรายละเอียด


