a PyTorch Tutorial to Image Captioning
1.0.0
이것은 이미지 캡션을위한 Pytorch 튜토리얼 입니다.
이것은 놀라운 Pytorch 라이브러리와 함께 멋진 모델을 구현하는 것에 대해 제가 쓰고있는 일련의 튜토리얼 중 첫 번째입니다.
Pytorch, Convolutional 및 Reburrent Neural Networks에 대한 기본 지식이 가정됩니다.
Pytorch를 처음 사용하는 경우 먼저 Pytorch : 60 분 블리츠와 학습 Pytorch를 사용하여 딥 러닝을 읽으십시오.
질문, 제안 또는 수정 사항은 문제로 게시 할 수 있습니다.
Python 3.6 에서 PyTorch 0.4 사용하고 있습니다.
2020 년 1 월 27 일 : 두 개의 새로운 튜토리얼에 대한 작업 코드가 추가되었습니다.
목적
개념
개요
구현
훈련
추론
자주 묻는 질문
우리가 제공하는 이미지에 대한 설명 캡션을 생성 할 수있는 모델을 구축하려면.
일을 단순하게 유지하기 위해 쇼를 구현하고 참석하고 종이를 말합시다 . 이것은 결코 현재의 최첨단이 아니지만 여전히 꽤 놀랍습니다. 저자의 원래 구현은 여기에서 찾을 수 있습니다.
이 모델은 어디에서 볼 수 있는지 배웁니다.
단어별로 캡션을 생성하면 이미지를 가로 질러 모델의 시선이 이동하는 것을 볼 수 있습니다.
이는 주의 메커니즘으로 인해 가능하며, 이는 다음에 완전 할 단어와 가장 관련이있는 이미지의 일부에 초점을 맞출 수 있습니다.
다음은 교육 또는 검증 중에 보이지 않는 테스트 이미지에서 생성 된 일부 캡션입니다.




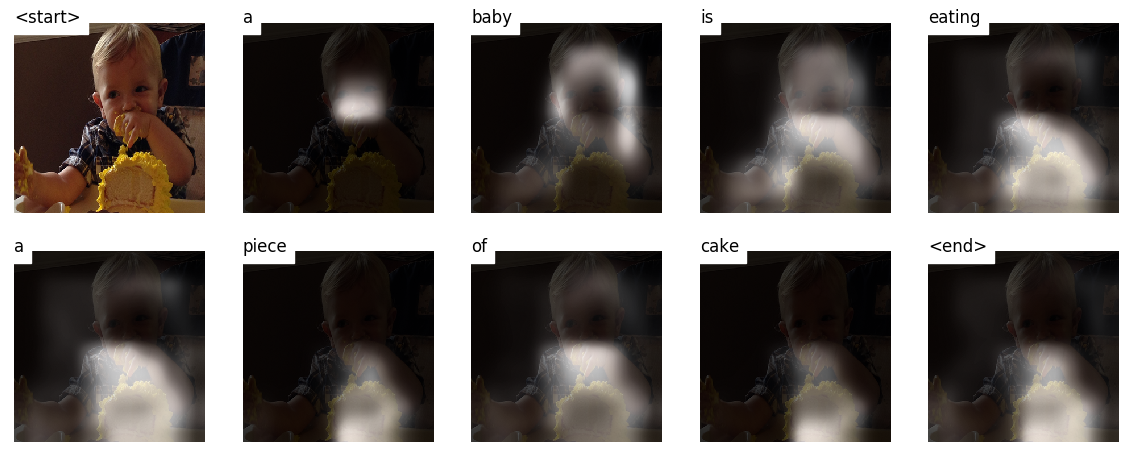

튜토리얼 끝에 더 많은 예가 있습니다.
이미지 캡션 . 듀.
인코더 디코더 아키텍처 . 일반적으로, 시퀀스를 생성하는 모델은 인코더를 사용하여 입력을 고정 된 형태로 인코딩하고 디코더를 디코더로 단어별로 디코딩하여 단어로 시퀀스로 디코딩합니다.
주목 . 주의 네트워크의 사용은 딥 러닝에서 널리 퍼져 있으며 그럴만 한 이유가 있습니다. 이것은 모델이 인코딩의 부분 만 선택하는 방법입니다. 여기서 사용되는 동일한 메커니즘은 인코더의 출력이 공간이나 시간에 여러 포인트를 갖는 모든 모델에서 사용할 수 있습니다. 이미지 캡션에서는 일부 픽셀이 다른 픽셀보다 더 중요하다고 생각합니다. 기계 번역과 같은 시퀀스 작업을 순서대로, 일부 단어는 다른 단어보다 더 중요하다고 생각합니다.
전송 학습 . 이것은 새로운 모델에서 일부를 사용하여 기존 모델에서 빌릴 때입니다. 이것은 새로운 모델을 처음부터 훈련시키는 것보다 거의 항상 낫습니다 (예 : 아무것도 아는 것). 보시다시피,이 중고 지식을 항상 특정 작업에 미세 조정할 수 있습니다. 사전에 사전 단어 임베딩을 사용하는 것은 바보이지만 유효한 예입니다. 이미지 캡션 문제의 경우 사전에 포기한 인코더를 사용한 다음 필요에 따라 미세 조정합니다.
빔 검색 . 이곳은 디코더를 게으르지 않고 각 디코드 단계에서 가장 좋은 점수를 가진 단어를 선택하는 곳입니다. 빔 검색은 가장 최적의 순서를 찾기 때문에 모든 언어 모델링 문제에 유용합니다.
이 섹션에서는이 모델에 대한 개요를 제시하겠습니다. 이미 익숙한 경우 구현 섹션 또는 주석 코드로 바로 건너 뛸 수 있습니다.
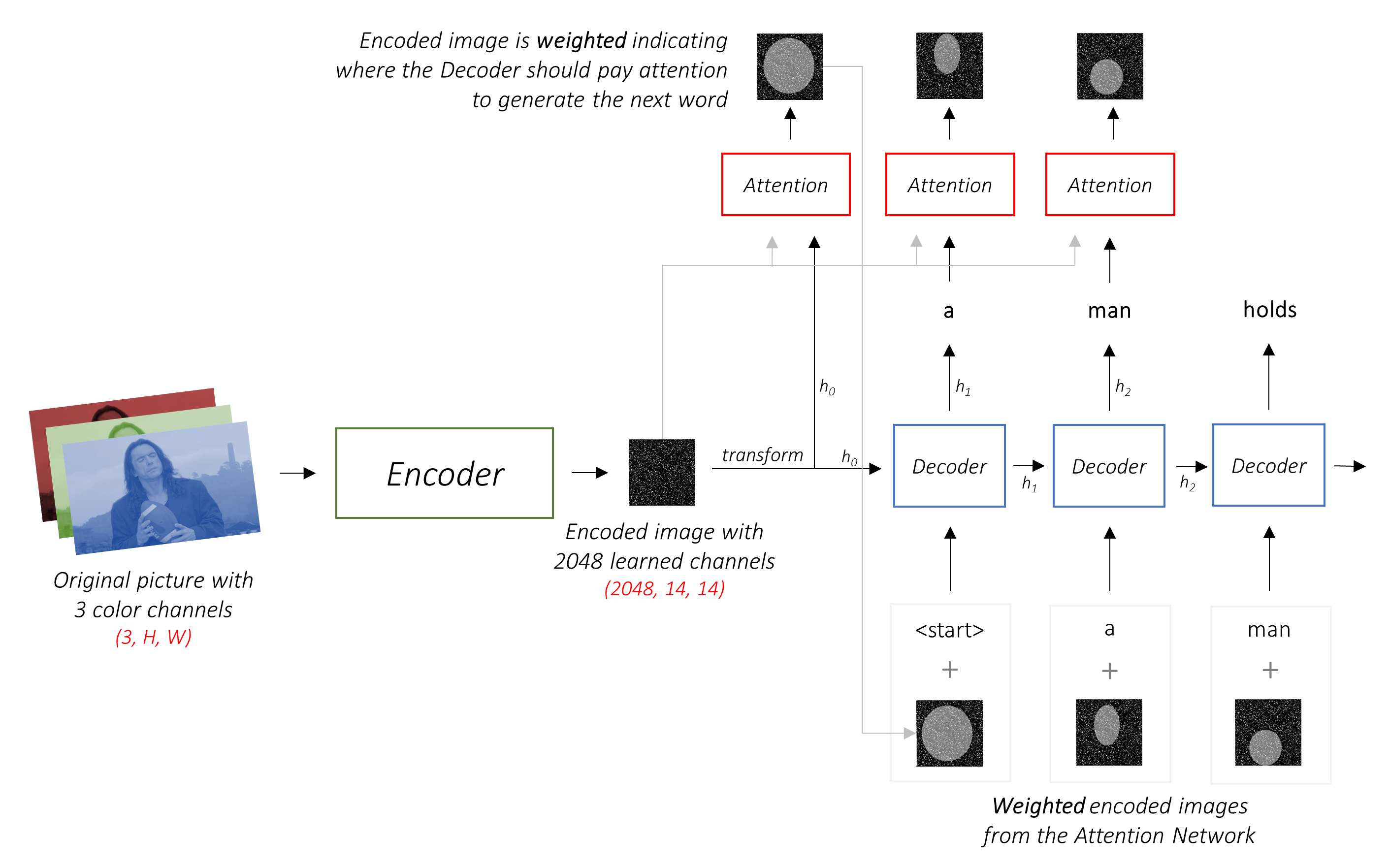
인코더는 3 개의 컬러 채널을 사용하여 입력 이미지를 "학습 된"채널을 사용하여 작은 이미지로 인코딩합니다 .
이 작은 인코딩 된 이미지는 원본 이미지에 유용한 모든 것의 요약 표현입니다.
우리는 이미지를 인코딩하고 싶기 때문에 CNN (Convolutional Neural Networks)을 사용합니다.
우리는 처음부터 인코더를 훈련시킬 필요가 없습니다. 왜? 이미 이미지를 표현하도록 훈련 된 CNN이 있기 때문입니다.
수년 동안 사람들은 이미지를 천 범주 중 하나로 분류하는 데 능숙한 모델을 구축 해 왔습니다. 이 모델들이 이미지의 본질을 매우 잘 포착한다고 추론합니다.
이미 Pytorch에서 사용할 수있는 ImageNet 분류 작업에 대해 훈련 된 101 계층 잔류 네트워크를 사용하기로 결정했습니다. 앞서 언급했듯이 이것은 전송 학습의 예입니다. 성능을 향상시키기 위해 미세 조정할 수있는 옵션이 있습니다.

이 모델은 원본 이미지의 작고 작은 표현을 점진적으로 생성하며, 각 후속 표현은 더 많은 수의 채널을 사용하여 "학습"됩니다. RESNET-101 인코더에서 생성 한 최종 인코딩은 2048 채널, 즉 2048, 14, 14 크기 텐서를 갖는 14x14 크기입니다.
다른 미리 훈련 된 아키텍처를 실험하는 것이 좋습니다. 이 논문은 vggnet을 사용하며 Imagenet에서는 사전에 사전을 사용하지만 미세 조정은 없습니다. 어느 쪽이든, 수정이 필요하다. 이 모델 중 마지막 층 또는 두 개의 층은 분류를 위해 SoftMax 활성화와 결합 된 선형 층이므로 제거합니다.
디코더의 임무는 인코딩 된 이미지를보고 단어별로 캡션 단어를 생성하는 것 입니다.
시퀀스를 생성하기 때문에 재발 성 신경망 (RNN)이어야합니다. LSTM을 사용할 것입니다.
주의가없는 일반적인 설정에서는 모든 픽셀에서 인코딩 된 이미지를 평균화 할 수 있습니다. 그런 다음 선형 변환의 유무에 관계없이이를 최초의 숨겨진 상태로 디코더로 공급하고 캡션을 생성 할 수 있습니다. 각 예측 된 단어는 다음 단어를 생성하는 데 사용됩니다.
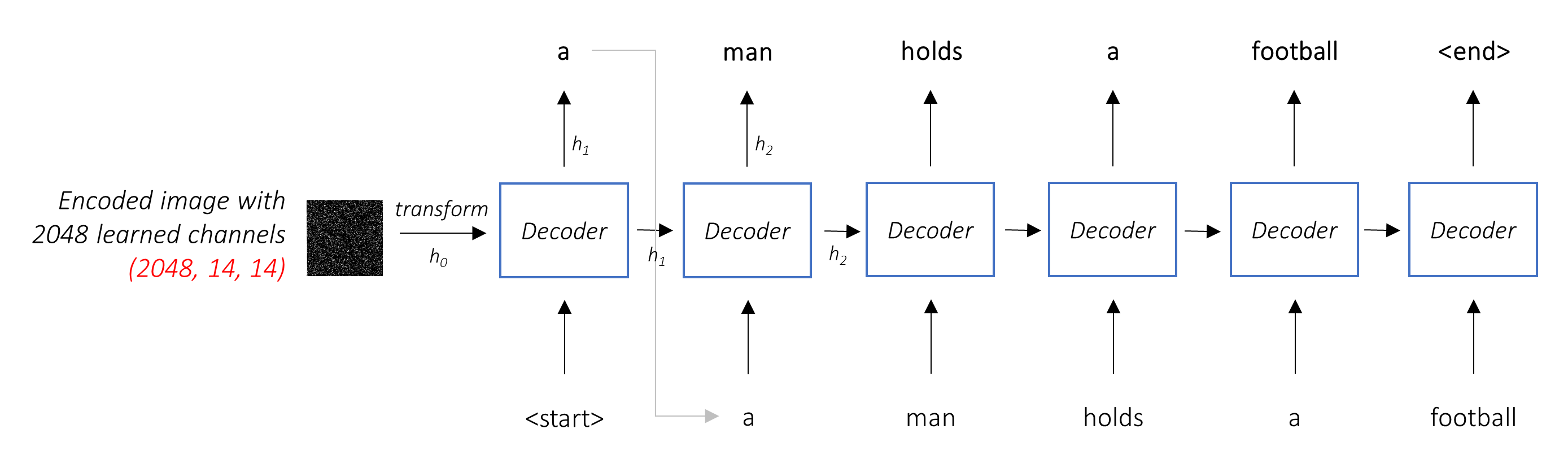
주의를 기울인 설정에서 디코더가 이미지의 다른 부분을 시퀀스의 다른 지점에서 볼 수 있기를 원합니다. 예를 들어, a man holds a football 에게 football 단어를 생성하는 동안 축구를 보유하고 있지만, 디코더는 축구에 집중하는 것을 알고있을 것입니다 - 축구!
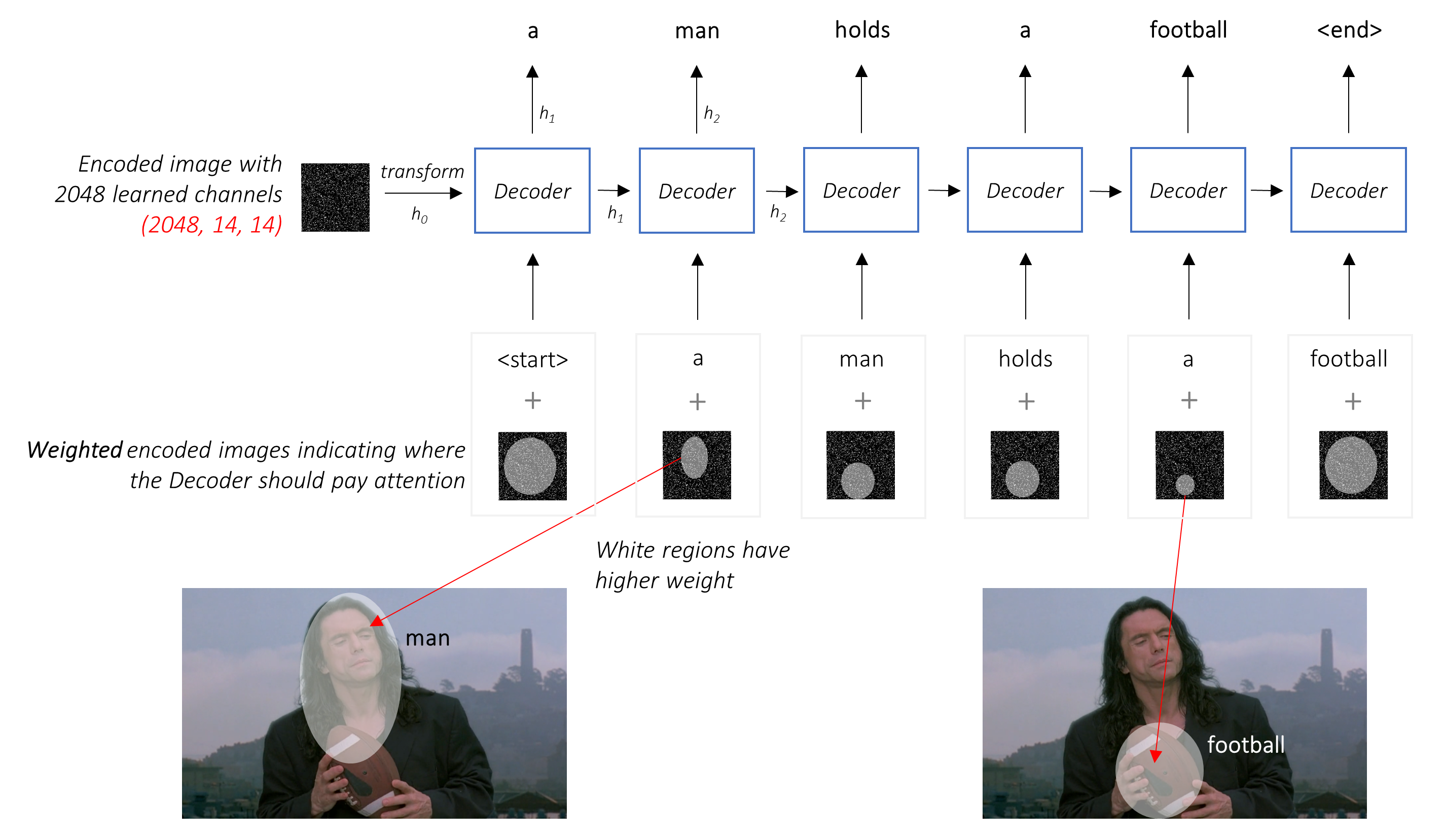
단순한 평균 대신 모든 픽셀에서 가중 평균을 사용하며 중요한 픽셀의 가중치가 더 큽니다. 이미지 의이 가중 표현은 각 단계에서 이전에 생성 된 단어와 연결하여 다음 단어를 생성 할 수 있습니다.
주의 네트워크는 이러한 가중치를 계산합니다 .
직관적으로, 이미지의 특정 부분의 중요성을 어떻게 추정 하시겠습니까? 지금까지 생성 한 순서를 알고 있어야하므로 이미지를보고 다음에 설명해야 할 필요가 있는지 결정할 수 있습니다. 예를 들어, 당신이 a man 언급 한 후에, 그가 holding a football 선언하는 것은 논리적입니다.
이것이 바로 관심 메커니즘이하는 일입니다. 지금까지 생성 된 시퀀스를 고려하고 다음을 설명 해야하는 이미지의 일부에 참석합니다 .
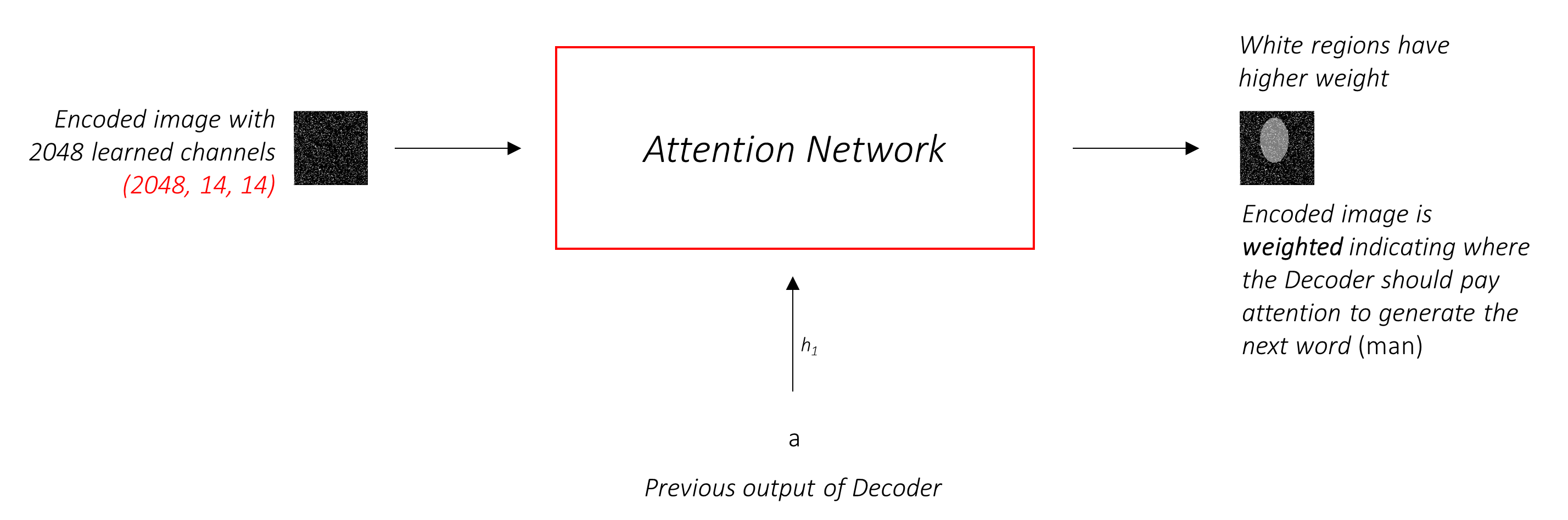
우리는 픽셀의 무게가 최대 1으로 추가되는 소프트 주의를 사용합니다. 인코딩 된 이미지에 P 픽셀이 있으면 각 타임 스테프 t -
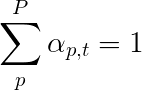
이 전체 프로세스를 픽셀이 다음 단어를 생성 할 확률 을 계산하는 것으로 해석 할 수 있습니다.
이제 우리의 결합 된 네트워크의 모습이 분명 할 수 있습니다.
h (및 셀 상태 C )를 생성합니다.우리는 선형 레이어를 사용하여 어휘의 각 단어에 대한 디코더의 출력을 점수로 변환합니다.
간단하고 욕심 많은 옵션은 점수가 가장 높은 단어를 선택하고 다음 단어를 예측하는 데 사용하는 것입니다. 그러나 나머지 시퀀스는 당신이 선택한 첫 번째 단어에 달려 있기 때문에 이것은 최적이 아닙니다. 그 선택이 최고가 아니라면, 뒤 따르는 모든 것이 차선책입니다. 그리고 그것은 첫 번째 단어만이 아닙니다. 순서의 각 단어는 성공한 단어에 결과가 있습니다.
첫 번째 단계에서 세 번째 최고의 단어를 선택하고 두 번째 단계에서 두 번째 로 좋은 단어를 선택했다면 ... 그것은 당신이 생성 할 수있는 최고의 순서 일 것입니다.
우리가 완전히 디코딩을 완료 할 때까지 어떻게 든 결정할 수 없고 후보 시퀀스 바스켓에서 전체 점수가 가장 높은 시퀀스를 선택할 수 있다면 가장 좋습니다.
빔 검색은 정확히 수행합니다.
k 후보를 고려하십시오.k 각각의 첫 단어에 대해 k 두 번째 단어를 생성하십시오.k [첫 번째 단어, 두 번째 단어] 조합을 선택하십시오.k 세 k 단어를 선택하고 상단 k [첫 번째 단어, 두 번째 단어, 세 번째 단어] 조합을 선택하십시오.k 시퀀스가 종료 된 후에는 최상의 전체 점수로 시퀀스를 선택하십시오. 
보시다시피, 일부 시퀀스 (파업)는 다음 단계에서 상단 k 로 만들지 않기 때문에 일찍 실패 할 수 있습니다. k 시퀀스 (밑줄이 밑줄)가 <end> 토큰을 생성하면 점수가 가장 높은 토큰을 선택합니다.
아래 섹션은 구현을 간단히 설명합니다.
그것들은 어떤 맥락을 제공하기위한 것이지만, 세부 사항은 코드에서 직접 이해되는 것이 가장 좋습니다 .
MSCOCO '14 데이터 세트를 사용하고 있습니다. 교육 (13GB) 및 검증 (6GB) 이미지를 다운로드해야합니다.
우리는 Andrej Karpathy의 훈련, 검증 및 테스트 분할을 사용할 것입니다. 이 zip 파일에는 캡션이 포함되어 있습니다. 또한 Flicker8k 및 Flicker30K 데이터 세트의 스플릿 및 캡션을 찾을 수 있으므로 후자가 컴퓨터에 비해 너무 큰 경우 MSCoco 대신에 사용하십시오.
세 가지 입력이 필요합니다.
사전에 사전 인코더를 사용하고 있기 때문에이 사기꾼 인코더가 익숙한 형태로 이미지를 처리해야합니다.
Pytorch의 torchvision 모듈의 일부로 사용할 수있는 사전 상주 된 ImageNet 모델. 이 페이지는 우리가 수행 해야하는 전처리 또는 변환을 자세히 설명합니다. 픽셀 값은 [0,1] 범위에 있어야하며 ImageNet Image 'RGB 채널의 평균 및 표준 편차로 이미지를 정규화해야합니다.
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]또한 Pytorch는 NCHW 컨벤션을 따릅니다. 이는 채널 차원 (c)이 크기 치수보다 우선해야 함을 의미합니다.
균일 성을 위해 모든 MSCoco 이미지를 256x256으로 크기를 조정합니다.
따라서 모델에 공급 된 이미지는 Dimension N, 3, 256, 256 의 Float 텐서 여야하며 , 상기 평균 및 표준 편차에 의해 정규화되어야합니다. N 은 배치 크기입니다.
캡션은 각 단어가 다음 단어를 생성하는 데 사용되므로 디코더의 대상과 입력입니다.
그러나 첫 번째 단어를 생성하려면 Zeroth 단어 <start> 가 필요합니다.
마지막으로, <end> 디코더는 캡션의 끝을 예측하는 법을 배워야합니다. 추론 중에 디코딩을 멈출 때를 알아야하기 때문에 이것은 필요합니다.
<start> a man holds a football <end>
캡션을 고정 크기 텐서로 전달하기 때문에 <pad> 토큰으로 캡션 (자연스럽게 다양한 길이의 캡션)을 패드해야합니다.
<start> a man holds a football <end> <pad> <pad> <pad>....
또한 <start> , <end> 및 <pad> 토큰을 포함하여 코퍼스의 각 단어에 대한 인덱스 매핑 인 word_map 만듭니다. Pytorch는 다른 라이브러리와 마찬가지로 다른 라이브러리와 마찬가지로 그들을 위해 임베딩을 찾거나 예측 된 단어 점수에서 자신의 위치를 식별하기위한 지수로 인코딩 된 단어가 필요합니다.
9876 1 5 120 1 5406 9877 9878 9878 9878....
따라서 모델에 공급 된 캡션은 치수 N, L 의 Int 여야합니다. L 패딩 길이입니다.
캡션이 패딩되므로 각 캡션의 길이를 추적해야합니다. 이것은 실제 길이 + 2 ( <start> 및 <end> 토큰의 경우)입니다.
캡션 길이는 Pytorch로 동적 그래프를 만들 수 있기 때문에 중요합니다. 우리는 길이까지 시퀀스 만 처리하고 <pad> 에서 계산을 낭비하지 않습니다.
따라서 모델에 공급되는 캡션 길이는 Int N 의 텐서 여야합니다 .
utils.py 의 create_input_files() 참조하십시오.
다운로드 된 데이터를 읽고 다음 파일을 저장합니다.
I, 3, 256, 256 텐서에서 분할에 대한 이미지를 포함하는 HDF5 파일 . I 분할의 이미지 수입니다. 픽셀 값은 여전히 범위 [0, 255]에 있으며 서명되지 않은 8 비트 Int 로 저장됩니다.N_c * I 인코딩 된 캡션 목록이있는 각 분할에 대한 JSON 파일 . 여기서 N_c 이미지 당 샘플링 된 캡션 수입니다. 이 캡션은 HDF5 파일의 이미지와 동일한 순서입니다. 따라서 i 캡션은 i // N_c th 이미지에 해당합니다.N_c * I 캡션 길이 목록이있는 각 분할에 대한 JSON 파일 . i th 값은 i tha 캡션의 길이이며, 이는 i // N_c th 이미지에 해당합니다.word_map , Word-to-Index Dictionary가 포함 된 JSON 파일 . 이 파일을 저장하기 전에 임계 값보다 짧은 캡션 만 사용하고 <unk> 토큰으로 덜 빈번한 단어를 사용하는 옵션이 있습니다.
우리는 훈련 / 검증 중에 디스크에서 직접 읽을 것이기 때문에 이미지에 HDF5 파일을 사용합니다. 그들은 단순히 한 번에 RAM에 맞을 수 없을 정도로 너무 커집니다. 그러나 우리는 모든 캡션과 길이를 메모리에로드합니다.
datasets.py 의 CaptionDataset 참조하십시오.
이것은 Pytorch Dataset 의 서브 클래스입니다. 데이터 세트의 크기를 반환하는 __len__ 방법과 i th 이미지, 캡션 및 캡션 길이를 반환하는 __getitem__ 메소드가 필요합니다.
디스크에서 이미지를 읽고 픽셀을 [0,255]로 변환 하고이 클래스 내에서 정상화합니다.
Dataset train.py 의 Pytorch DataLoader 에서 교육 또는 검증을 위해 모델에 데이터 배치를 생성하고 공급하기 위해 사용됩니다.
models.py 의 Encoder 참조하십시오.
우리는 이미 Pytorch의 torchvision 모듈에서 사용할 수있는 사전 취사 RESNET-101을 사용합니다. 이미지를 인코딩하면서 분류하지 않기 때문에 마지막 두 층 (풀링 및 선형 레이어)을 폐기하십시오.
인코딩을 고정 크기로 크기로 조정하기 위해 AdaptiveAvgPool2d() 레이어를 추가합니다. 따라서 가변 크기의 이미지를 인코더에 공급할 수 있습니다. (그러나 우리는 입력 이미지를 단일 텐서로 함께 보관해야했기 때문에 입력 이미지를 256, 256 으로 조정했습니다.)
인코더를 미세 조정할 수 있으므로 인코더 매개 변수에 대한 기울기 계산을 가능하게하거나 비활성화하는 fine_tune() 메소드를 추가합니다. 우리는 RESNET에서 Convolutional Blocks 2에서 4 만 미세 조정합니다 . 첫 번째 Convolutional Block은 일반적으로 선, 가장자리, 곡선 등과 같은 이미지 처리에 매우 근본적인 것을 배웠기 때문입니다. 우리는 기초를 엉망으로 만들지 않습니다.
models.py 의 Attention 참조하십시오.
주의 네트워크는 간단합니다. 선형 레이어와 몇 가지 활성화로 구성됩니다.
별도의 선형 레이어는 인코딩 된 이미지 (평평한 N, 14 * 14, 2048 )와 디코더에서 동일한 치수 (출력)를 동일한 치수로 변환합니다 . 주의 크기. 그런 다음 추가하고 활성화됩니다. 세 번째 선형 레이어는 이 결과를 1의 차원으로 변환하여 SoftMax를 적용하여 무게 alpha 생성합니다.
models.py 의 DecoderWithAttention 참조하십시오.
인코더의 출력은 여기서 수신되어 치수 N, 14 * 14, 2048 로 평평하게됩니다. 이것은 편리하며 텐서를 여러 번 재구성해야합니다.
두 개의 개별 선형 레이어를 사용하는 init_hidden_state() 메소드를 사용하여 인코딩 된 이미지를 사용하여 LSTM의 숨겨진 및 셀 상태를 초기화합니다 .
바로 그 때, 우리는 캡션 길이를 줄여 N 이미지와 캡션을 정렬합니다 . 이것은 우리가 <pad> 를 처리하지 않고 유효한 타임 스텝 만 처리 할 수 있도록하기 위해서.
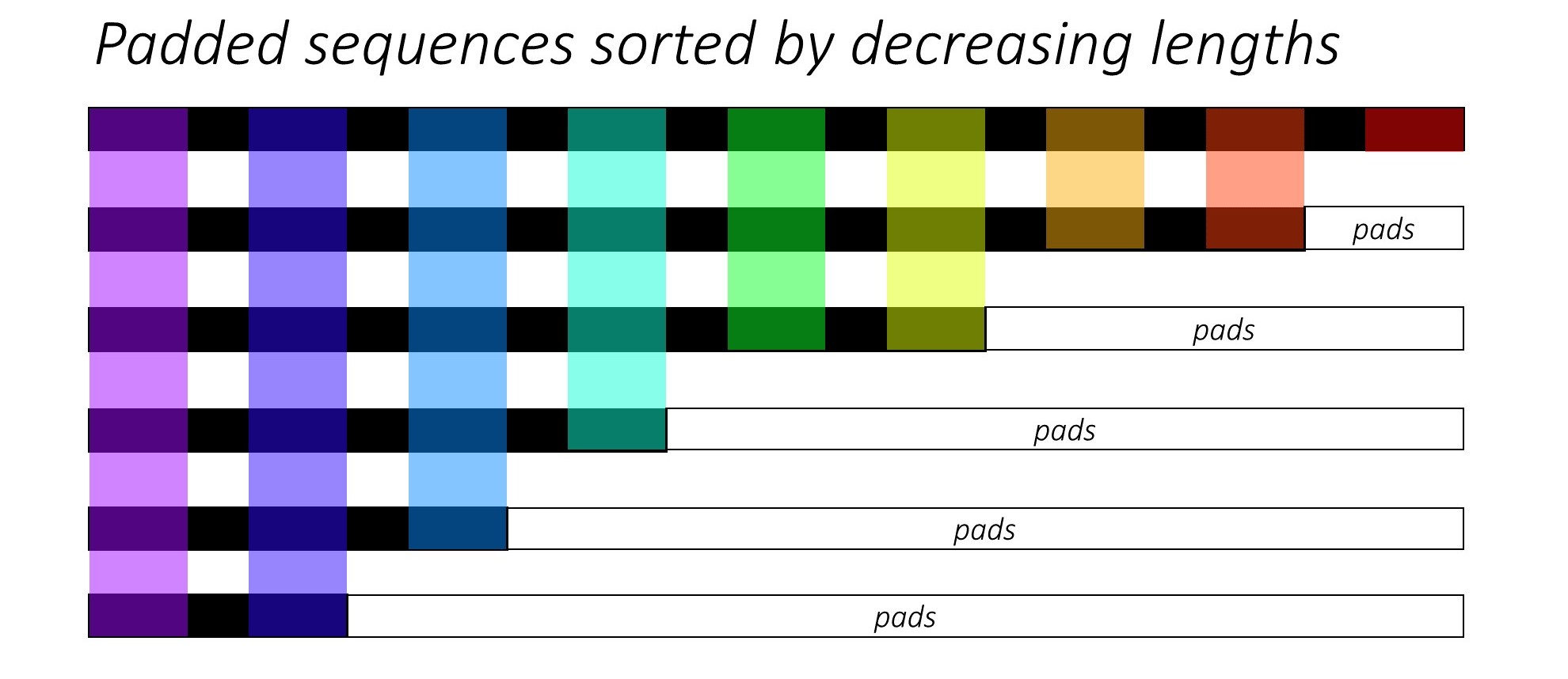
각 타임 스텝을 반복하여 해당 타임 스텝에서 유효 배치 크기 N_t 인 컬러 영역 만 처리 할 수 있습니다. 정렬을 통해 모든 타임 스텝에서 상단 N_t 이전 단계의 출력과 정렬 할 수 있습니다. 예를 들어 세 번째 타임 스텝에서는 이전 단계의 상위 5 개의 출력을 사용하여 상위 5 개의 이미지 만 처리합니다.
이 반복은 pytorch LSTMCell 이있는 루프없이 자동으로 반복하는 대신 pytorch LSTM 을 사용하여 for 루프에서 수동으로 수행됩니다 . 이는 각 디코드 단계 사이의주의 메커니즘을 실행해야하기 때문입니다. LSTMCell 은 단일 타임 스텝 작업 인 반면 LSTM 여러 타임 스텝을 계속 반복하여 한 번에 모든 출력을 제공합니다.
주의 네트워크를 사용하여 각 타임 스텝에서 가중치 및주의 가중 인코딩을 계산합니다 . 논문의 4.2.1 절에서는 필터 또는 게이트를 통해주의 가중 인코딩을 전달하는 것이 좋습니다. 이 게이트는 디코더의 이전 숨겨진 상태의 시그 모이 드 활성화 선형 변환입니다. 저자는 이것이주의 네트워크가 이미지의 객체에 더 강조하는 데 도움이된다고 말합니다.
우리는 이전 단어의 임베딩 ( <start> 시작) 과 함께이 필터링 된주의 가중 인코딩을 연결하고 LSTMCell 실행하여 새로운 숨겨진 상태 (또는 출력)를 생성합니다 . 선형 층은 이 새로운 숨겨진 상태를 어휘의 각 단어에 대한 점수로 변환하여 저장됩니다.
또한 각 타임 스텝에서주의 네트워크에 의해 반환 된 가중치를 저장합니다. 당신은 왜 충분히 충분히 알 수있을 것입니다.
시작하기 전에 교육, 검증 및 테스트에 필요한 데이터 파일을 저장하십시오. 이렇게하려면 Karpathy JSON 파일 및 다운로드 된 데이터에서 추출 된 train2014 및 val2014 폴더를 포함하는 이미지 폴더를 포인트 한 후 create_input_files.py 의 내용을 실행하십시오.
train.py 참조하십시오.
모델 (및 교육)의 매개 변수는 파일의 시작 부분에 있으므로 원하는 경우 쉽게 확인하거나 수정할 수 있습니다.
모델을 처음부터 훈련 시키 려면이 파일을 실행하십시오.
python train.py
체크 포인트에서 교육을 재개 하려면 코드 시작시 checkpoint 매개 변수가있는 해당 파일을 가리 킵니다.
우리는 모든 훈련 시대의 끝에서 검증을 수행합니다.
우리는 일련의 단어를 생성하기 때문에 CrossEntropyLoss 사용합니다. 디코더의 최종 계층에서 원시 점수 만 제출하면 손실 기능이 SoftMax 및 Log 작업을 수행합니다.
이 논문의 저자는 " 이중 확률 론적 정규화 "인 두 번째 손실을 사용하는 것이 좋습니다. 우리는 주어진 타임 스텝에서 가중치를 1로 알고 있습니다. 그러나 우리는 또한 단일 픽셀 p 의 가중치를 모든 타임 스텝 T 에서 1로 1로 장려합니다.
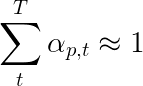
이것은 우리가 전체 시퀀스를 생성하는 과정에서 모든 픽셀에 모델이 참석하기를 원한다는 것을 의미합니다. 따라서 우리는 모든 타임 스텝에서 1과 픽셀 가중치의 합계의 차이를 최소화 하려고 노력합니다.
우리는 패딩 된 지역에서 손실을 계산하지 않습니다 . 패드를 제거하는 쉬운 방법은 Pytorch의 pack_padded_sequence() 사용하는 것입니다. 이제이 평평한 텐서의 손실을 집계 할 수 있습니다.
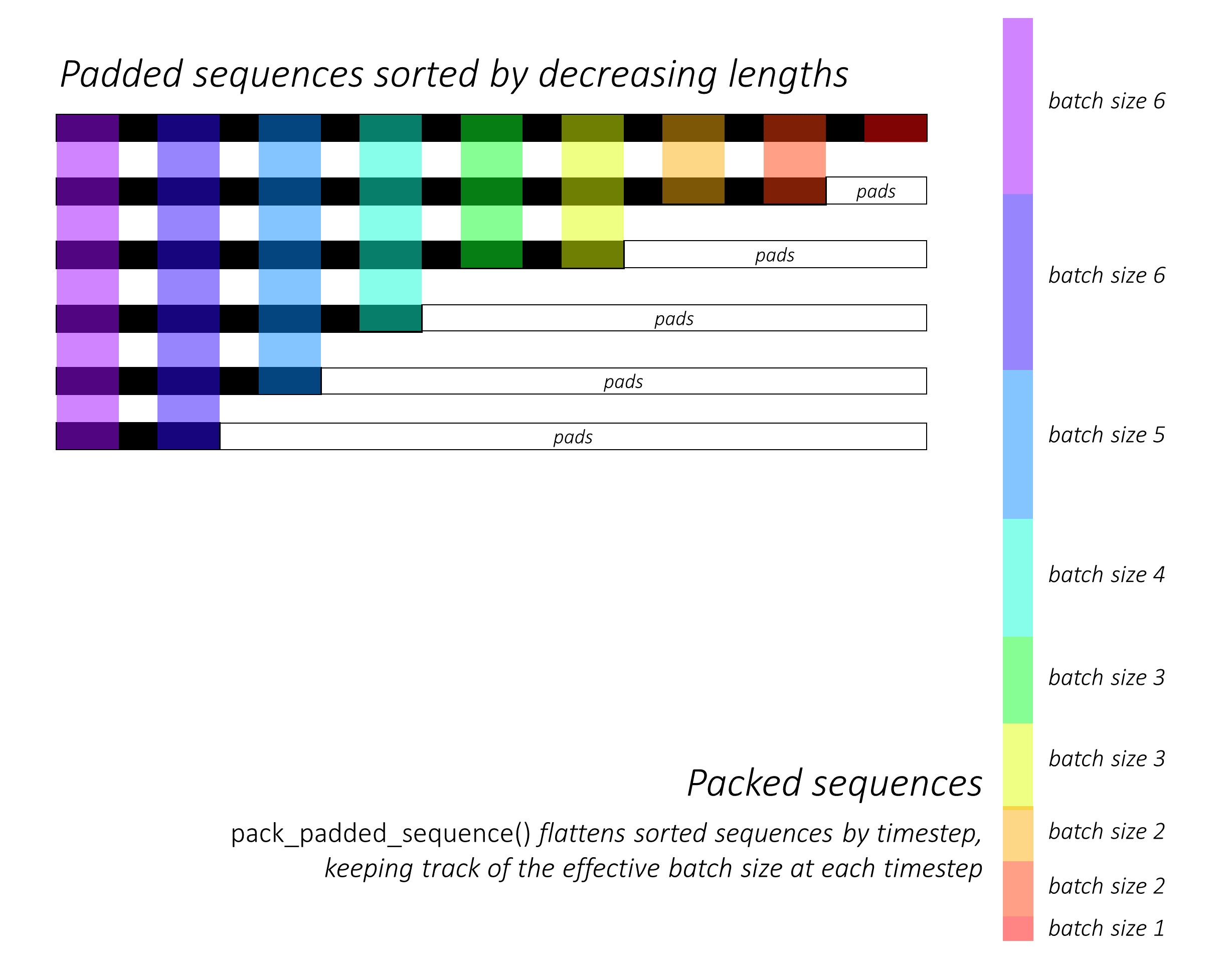
참고 -이 기능은 실제로 Pytorch에서 RNN 또는 LSTM 사용할 때 디코더에서 수행 한 동일한 동적 배치 (즉, 각 타임 스텝에서 유효 배치 크기 만 처리)를 수행하는 데 사용됩니다. 이 경우 Pytorch는 내부적으로 동적 변수 길이 그래프를 처리합니다. Sequence Labeling에 대한 다른 자습서에서 dynamic_rnn.py 의 예를 볼 수 있습니다. 주의 네트워크로 인해 수동으로 반복하지 않으면 디코더의 LSTM 과 함께이 기능을 사용했을 것입니다.
검증 세트에서 모델의 성능을 평가하기 위해 자동화 된 이중 언어 평가 학부 (BLEU) 평가 메트릭을 사용합니다. 이것은 참조 캡션에 대한 생성 된 캡션을 평가합니다. 생성 된 각 캡션에 대해 해당 이미지에 사용 가능한 모든 N_c 캡션을 참조 캡션으로 사용합니다.
쇼의 저자는 참석하고 종이에 대한 지점 이후 손실과 Bleu 점수 사이의 상관 관계가 무너지는 것을 관찰하므로 손실이 계속 감소하더라도 BLEU 점수가 저하되기 시작할 때 조기에 훈련을 중단하는 것이 좋습니다.
NLTK 모듈에서 사용 가능한 BLEU 도구를 사용했습니다.
BLEU 점수에 대한 상당한 비판은 항상 인간의 판단과 잘 관련되어 있지 않기 때문입니다. 저자는 또한 이러한 이유로 유성 점수를보고하지만이 메트릭을 구현하지는 않았습니다.
무대에서 훈련하는 것이 좋습니다.
나는 먼저 디코더, 즉 인코더를 미세 조정하지 않고 배치 크기를 80 으로 훈련시켰다. 나는 20 명의 시대를 훈련 시켰고, Bleu-4 점수는 13 번째 에포크에서 약 23.25 로 정점에 도달했다. 4e-4 의 초기 학습 속도로 Adam() Optimizer를 사용했습니다.
나는 13 번째 epoch 체크 포인트에서 계속해서 배치 크기가 32 인 인코더의 미세 조정을 허용했습니다. 더 작은 배치 크기는 모델이 인코더의 그라디언트를 포함하기 때문에 이제 더 크기 때문에 이제는입니다. 미세 조정으로 점수는 약 3 개의 에포크에서 24.29 로 상승했습니다. 계속되는 훈련은 아마도 점수를 약간 더 높게 추진했을 것입니다. 그러나 나는 다른 곳에서 내 GPU를 커밋해야했습니다.
여기서 만드는 중요한 차이점은 마지막으로 생성 된 단어에 관계없이 유효성 검사 중 각 디코드 단계의 입력으로 지상 진실을 공급하고 있다는 것입니다. 이것을 교사 강제 라고합니다. 이것은 훈련 중에 일반적으로 프로세스 속도를 높이기 위해 사용되지만, 우리가하는 것처럼, 검증 중 조건은 가능한 한 실제 추론 조건을 모방해야합니다. 캡션의 각 단어가 이전에 생성 된 단어에서 생성되고 <end> 토큰을 치면 종료되는 배치 추론을 아직 구현하지 않았습니다.
유효성 검사 중에 교사를 쫓아 내기 때문에 결과 캡션에서 위에서 측정 한 BLEU 점수는 실제 성능을 반영 하지 않습니다 . 실제로, BLEU 점수는 자연적으로 생성 된 캡션을 다른 길이의 진실 캡션과 비교하도록 설계된 메트릭입니다. 배치 된 추론이 구현되면, 즉, 교사의 강제력은 아무도없고, Bleu 점수를 조기에 찍는 것은 진정으로 '적절한'것입니다.
이를 염두에두고 eval.py 사용하여 교사를 강제하지 않고 다양한 빔 크기로 검증 및 테스트 세트 에서이 모델 체크 포인트의 올바른 BLEU-4 점수를 계산했습니다.
| 빔 크기 | 검증 BLEU-4 | Bleu-4를 테스트하십시오 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
테스트 점수는 종이의 결과보다 높으며 BLEU 계산기가 매개 변수화 된 방식, RESNET 인코더를 사용하고 실제로는 인코더를 미세 조정했다는 사실 때문에 약간의 일일 수 있습니다.
또한 전송 학습 중에 미세 조정할 때는 차용 모델을 훈련시키는 데 원래 사용 된 것보다 상당히 작은 학습 속도를 사용하는 것이 항상 좋습니다. 모델이 이미 상당히 최적화되어 있기 때문에 너무 빨리 변경하고 싶지 않기 때문입니다. 인코더에도 Adam() 도 사용했지만 학습 속도는 1e-4 로이 최적화기의 기본값 중 10 분의 1입니다.
타이탄 X (Pascal)에서는 미세 조정없이 에포크 당 55 분, 명시된 배치 크기에서 미세 조정으로 2.5 시간이 걸렸습니다.
이 사기꾼 모델과 해당 word_map 여기에서 다운로드 할 수 있습니다.
이 체크 포인트는 Pytorch와 직접로드하거나 caption.py 로 전달해야합니다. 아래를 참조하십시오.
caption.py 참조하십시오.
추론 중에, 우리는 교사 강제력을 사용하기 때문에 디코더에서 forward() 메소드를 직접 사용할 수 없습니다 . 오히려, 우리는 실제로 각 타임 스텝에서 이전에 생성 된 단어를 LSTM에 공급 해야합니다.
caption_image_beam_search() 이미지를 읽고, 인코딩하고, 디코더의 레이어를 올바른 순서로 적용하고, 이전에 생성 된 단어를 각 타임 스텝에서 LSTM에 입력하여 사용합니다. 또한 빔 검색도 포함합니다.
visualize_att() 예제에서 볼 수있는 각 타임 스텝의 가중치와 함께 생성 된 캡션을 시각화하는 데 사용될 수 있습니다.
명령 줄에서 이미지를 캡션 하려면 이미지, 모델 체크 포인트, 단어 맵 (및 선택적으로 빔 크기)을 가리키십시오.
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
또는 필요에 따라 파일의 함수를 사용하십시오.
또한 빔 검색 유무에 관계없이 검증 세트에서 BLEU 점수를 계산하기위한이 프로세스를 구현하는 eval.py 참조하십시오.





Turing Tommy 테스트 - AI는 방을 보지 않았고 그것을 볼 때 위대함을 인식하지 못하기 때문에 AI가 실제로 AI가 아니라는 것을 알고 있습니다.

당신은 부드러운 관심을 말했다 . 음, 어려운 관심이 있습니까?
그렇습니다. 쇼, 참석 및 종이는 두 변형을 모두 사용하며 "하드"주의를 가진 디코더는 약간 더 잘 수행됩니다.
우리가 여기에서 사용하는 부드러운 주의로, 당신은 가중치 alpha 계산하고 모든 픽셀의 기능의 가중 평균을 사용하고 있습니다. 이것은 결정 론적이고 차별화 가능한 작업입니다.
주의를 기울 이면 alpha 가 정의한 분포에서 일부 픽셀을 샘플링하기로 결정합니다. 이러한 확률 샘플링은 비 결정적이거나 확률 적 이며, 즉 특정 입력이 항상 동일한 출력을 생성하는 것은 아닙니다. 그러나 그라디언트 하강은 네트워크가 결정 론적 (따라서 차별화 가능)을 전제하기 때문에 샘플링은 확률 론성을 제거하기 위해 재 작업됩니다. 이것에 대한 나의 지식은이 시점에서 상당히 피상적입니다 - 나는 더 자세한 이해가있을 때이 답변을 업데이트 할 것입니다.
시퀀스의 시퀀스와 같은 NLP 작업에주의 네트워크를 사용하려면 어떻게합니까?
CNN을 사용하여 각 픽셀에서 기능으로 인코딩을 생성하는 것처럼 RNN을 사용하여 입력의 각 타임 스텝 IE 워드 위치에서 인코딩 된 기능을 생성합니다.
주의를 기울이지 않고 마지막 타임 스텝의 인코딩으로 마지막 타임 스텝에서 인코더의 출력을 사용합니다. 이전 타임 스텝의 정보도 포함되므로. 인코더의 마지막 출력은 이제 전체 문장을 의미있게 인코딩해야한다는 부담을 지니고 있습니다. 특히 더 긴 문장에는 쉽지 않습니다.
주의를 기울이면 인코더 출력의 타임 스텝에 참석하여 각 타임 스텝/워드에 대한 가중치를 생성하고 가중 평균을 사용하여 문장을 나타냅니다. 기계 번역과 같은 시퀀스 작업에 순서대로 출력에서 각 단어를 생성 할 때 입력의 관련 단어에 참석합니다.
디코더 없이도주의를 사용할 수도 있습니다. 예를 들어, 텍스트를 분류하려면 분류를 수행하기 위해 입력의 중요한 단어에 한 번만 참석할 수 있습니다.
훈련 중에 빔 검색을 사용할 수 있습니까?
현재 손실 함수가 아니라 그렇습니다. 이것은 전혀 흔하지 않습니다.
교사의 강제력은 무엇입니까?
교사의 강제는 우리가 지상 진실 캡션을 각 타임 스텝에서 디코더에 입력하여 이전 타임 스텝에서 생성 된 단어가 아닌 경우입니다. 모델의 더 빠른 수렴을 의미 할 수 있기 때문에 훈련 중 교사-포스에 일반적입니다. 그러나 그것은 또한 정답에 의존하는 법을 배울 수 있으며 실제로 불안정성을 나타냅니다.
확률에 따라 일부 시간 만 강요하는 교사를 사용하여 훈련하는 것이 이상적입니다. 이를 예약 샘플링이라고합니다.
(옵션을 추가 할 계획입니다).
사전에 배치 된 단어 임베딩 (글러브, cbow, skipgram 등)을 처음부터 배우는 대신 사용할 수 있습니까?
예, Decoder 클래스에서 load_pretrained_embeddings() 메소드를 사용하여 할 수 있습니다. fine_tune_embeddings() 메소드를 사용하여 미세 조정을 선택할 수도 있습니다.
train.py 에서 디코더를 만든 후에는 word_map 에서와 동일한 순서로 쌓인 load_pretrained_embeddings() 에 사전 취급 된 벡터를 제공해야합니다. <start> 와 같이 사전 치료 된 벡터가없는 단어의 경우 init_weights() 에서했던 것처럼 임베딩을 무작위로 초기화 할 수 있습니다. 무작위로 초기화 된 벡터에 대한보다 의미있는 벡터를 배우기 위해 미세 조정을 권장합니다.
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False 또한 emb_dim 매개 변수를 현재 값 512 에서 미리 훈련 된 임베딩 크기로 변경하십시오. 이로 인해 디코더 LSTM의 입력 크기를 자동으로 조정하여이를 수용해야합니다.
그라디언트를 계산할 수있는 텐서를 추적하려면 어떻게해야합니까?
Pytorch 0.4 가 방출되면 Variable S로 래핑 텐서가 더 이상 필요하지 않습니다. 대신, 텐서에는 requires_grad 속성이 있으며,이 속성은 autograd 에 의해 추적되는지 여부를 결정하며, 따라서 역전 중에 그라디언트가 계산되는지 여부를 결정합니다.
requires_grad False 로 설정됩니다.requires_grad 가 True 로 설정됩니다.torch.nn 층의 매개 변수 인 텐서는 이미 requires_grad True 설정되어 있습니다.평가 중에 모든 BLEU (예 : BLEU-1에서 BLEU-4) 점수를 계산하려면 어떻게해야합니까?
이를 위해 eval.py 에서 코드를 수정해야합니다. 명확하고 자세한 설명은 Kmario23 의이 훌륭한 답변을 참조하십시오.


