a PyTorch Tutorial to Image Captioning
1.0.0
Ini adalah tutorial Pytorch untuk menulis captioning .
Ini adalah yang pertama dari serangkaian tutorial yang saya tulis tentang menerapkan model keren sendiri dengan perpustakaan Pytorch yang menakjubkan.
Pengetahuan dasar Pytorch, jaringan saraf konvolusional dan berulang diasumsikan.
Jika Anda baru mengenal Pytorch, pertama -tama baca pembelajaran mendalam dengan Pytorch: Blitz 60 menit dan belajar Pytorch dengan contoh.
Pertanyaan, saran, atau koreksi dapat diposting sebagai masalah.
Saya menggunakan PyTorch 0.4 di Python 3.6 .
27 Jan 2020 : Kode kerja untuk dua tutorial baru telah ditambahkan-super-resolusi dan terjemahan mesin
Tujuan
Konsep
Ringkasan
Pelaksanaan
Pelatihan
Kesimpulan
Pertanyaan yang sering diajukan
Untuk membangun model yang dapat menghasilkan keterangan deskriptif untuk gambar yang kami berikan.
Demi menjaga hal -hal sederhana, mari kita terapkan pertunjukan, hadir, dan beri tahu kertas. Ini sama sekali bukan canggih saat ini, tetapi masih sangat menakjubkan. Implementasi asli penulis dapat ditemukan di sini.
Model ini belajar di mana harus mencari.
Saat Anda menghasilkan keterangan, kata demi kata, Anda dapat melihat tatapan model bergeser di seluruh gambar.
Ini dimungkinkan karena mekanisme perhatiannya , yang memungkinkannya untuk fokus pada bagian gambar yang paling relevan dengan kata yang akan diucapkan selanjutnya.
Berikut adalah beberapa teks yang dihasilkan pada gambar uji yang tidak terlihat selama pelatihan atau validasi:




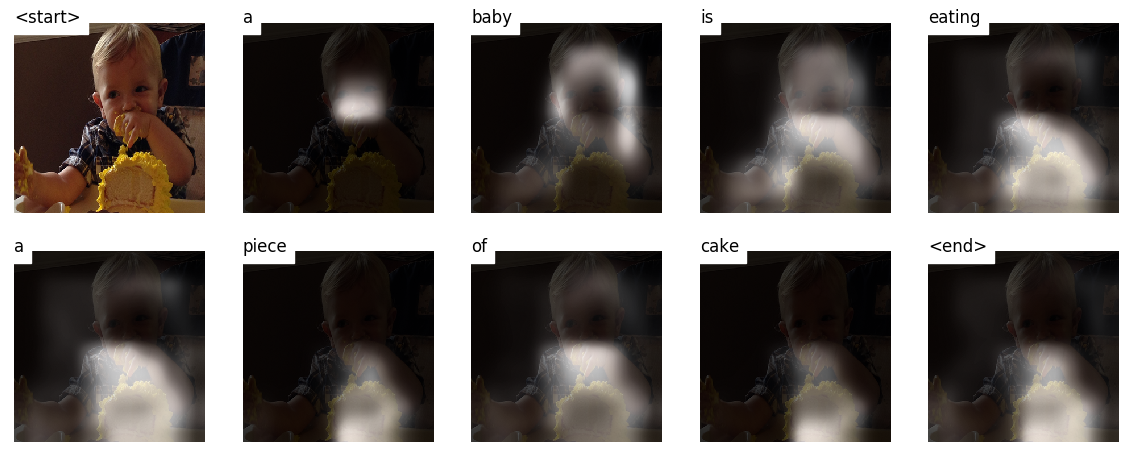

Ada lebih banyak contoh di akhir tutorial.
Captioning gambar . duh.
Arsitektur Encoder-Decoder . Biasanya, model yang menghasilkan urutan akan menggunakan encoder untuk menyandikan input ke dalam bentuk tetap dan dekoder untuk memecahkan kode, kata demi kata, menjadi urutan.
Perhatian . Penggunaan jaringan perhatian tersebar luas dalam pembelajaran yang mendalam, dan dengan alasan yang bagus. Ini adalah cara bagi model untuk memilih hanya bagian -bagian dari pengkodean yang menurutnya relevan dengan tugas yang ada. Mekanisme yang sama yang Anda lihat digunakan di sini dapat digunakan dalam model apa pun di mana output encoder memiliki beberapa titik dalam ruang atau waktu. Dalam captioning gambar, Anda menganggap beberapa piksel lebih penting daripada yang lain. Secara urutan untuk tugas -tugas sequence seperti terjemahan mesin, Anda menganggap beberapa kata lebih penting daripada yang lain.
Transfer pembelajaran . Ini adalah saat Anda meminjam dari model yang ada dengan menggunakan bagian -bagiannya dalam model baru. Ini hampir selalu lebih baik daripada melatih model baru dari awal (yaitu, tidak tahu apa -apa). Seperti yang akan Anda lihat, Anda selalu dapat menyempurnakan pengetahuan tangan kedua ini untuk tugas tertentu yang dihadapi. Menggunakan embeddings kata pretrained adalah contoh yang bodoh tetapi valid. Untuk masalah captioning gambar kami, kami akan menggunakan encoder pretrained, dan kemudian menyempurnakannya sesuai kebutuhan.
Pencarian balok . Di sinilah Anda tidak membiarkan decoder Anda malas dan cukup memilih kata-kata dengan skor terbaik di setiap langkah decode. Pencarian balok berguna untuk masalah pemodelan bahasa apa pun karena menemukan urutan yang paling optimal.
Di bagian ini, saya akan menyajikan ikhtisar model ini. Jika Anda sudah terbiasa dengan itu, Anda dapat melewatkan langsung ke bagian implementasi atau kode yang dikomentari.
Encoder mengkodekan gambar input dengan 3 saluran warna menjadi gambar yang lebih kecil dengan saluran "terpelajar" .
Gambar yang disandikan lebih kecil ini adalah representasi ringkasan dari semua yang berguna dalam gambar asli.
Karena kami ingin menyandikan gambar, kami menggunakan Convolutional Neural Networks (CNNS).
Kami tidak perlu melatih enkoder dari awal. Mengapa? Karena sudah ada CNN yang dilatih untuk mewakili gambar.
Selama bertahun -tahun, orang telah membangun model yang luar biasa bagus dalam mengklasifikasikan gambar menjadi salah satu dari seribu kategori. Masuk akal bahwa model -model ini menangkap esensi gambar dengan sangat baik.
Saya telah memilih untuk menggunakan jaringan residu 101 berlapis yang dilatih pada tugas klasifikasi Imagenet , sudah tersedia di Pytorch. Seperti yang dinyatakan sebelumnya, ini adalah contoh pembelajaran transfer. Anda memiliki opsi untuk menyempurnakannya untuk meningkatkan kinerja.

Model -model ini secara progresif membuat representasi yang lebih kecil dan lebih kecil dari gambar asli, dan setiap representasi selanjutnya lebih "dipelajari", dengan sejumlah besar saluran. Pengkodean akhir yang dihasilkan oleh Encoder ResNet-101 kami memiliki ukuran 14x14 dengan 2048 saluran, yaitu, tensor ukuran 2048, 14, 14 .
Saya mendorong Anda untuk bereksperimen dengan arsitektur pra-terlatih lainnya. Makalah ini menggunakan VGGNET, juga pretrained di ImageNet, tetapi tanpa penyetelan. Either way, modifikasi diperlukan. Karena lapisan terakhir atau dua model ini adalah lapisan linier yang digabungkan dengan aktivasi softmax untuk klasifikasi, kami melepaskannya.
Tugas decoder adalah untuk melihat gambar yang dikodekan dan menghasilkan tulisan demi kata .
Karena menghasilkan urutan, itu harus menjadi jaringan saraf berulang (RNN). Kami akan menggunakan LSTM.
Dalam pengaturan yang khas tanpa perhatian, Anda bisa rata -rata gambar yang dikodekan di semua piksel. Anda kemudian dapat memberi makan ini, dengan atau tanpa transformasi linier, menjadi decoder sebagai keadaan tersembunyi pertama dan menghasilkan keterangan. Setiap kata yang diprediksi digunakan untuk menghasilkan kata berikutnya.
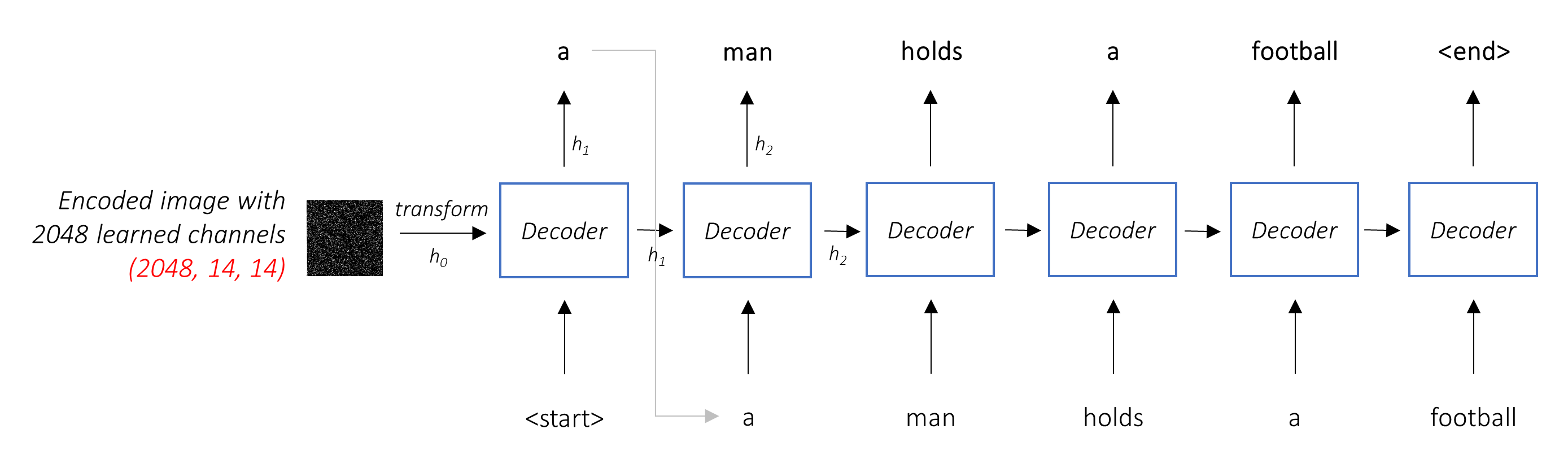
Dalam pengaturan dengan perhatian, kami ingin decoder dapat melihat berbagai bagian gambar pada titik yang berbeda dalam urutan . Misalnya, saat menghasilkan kata football dalam diri a man holds a football , decoder akan tahu untuk fokus - Anda dapat menebaknya - sepak bola!
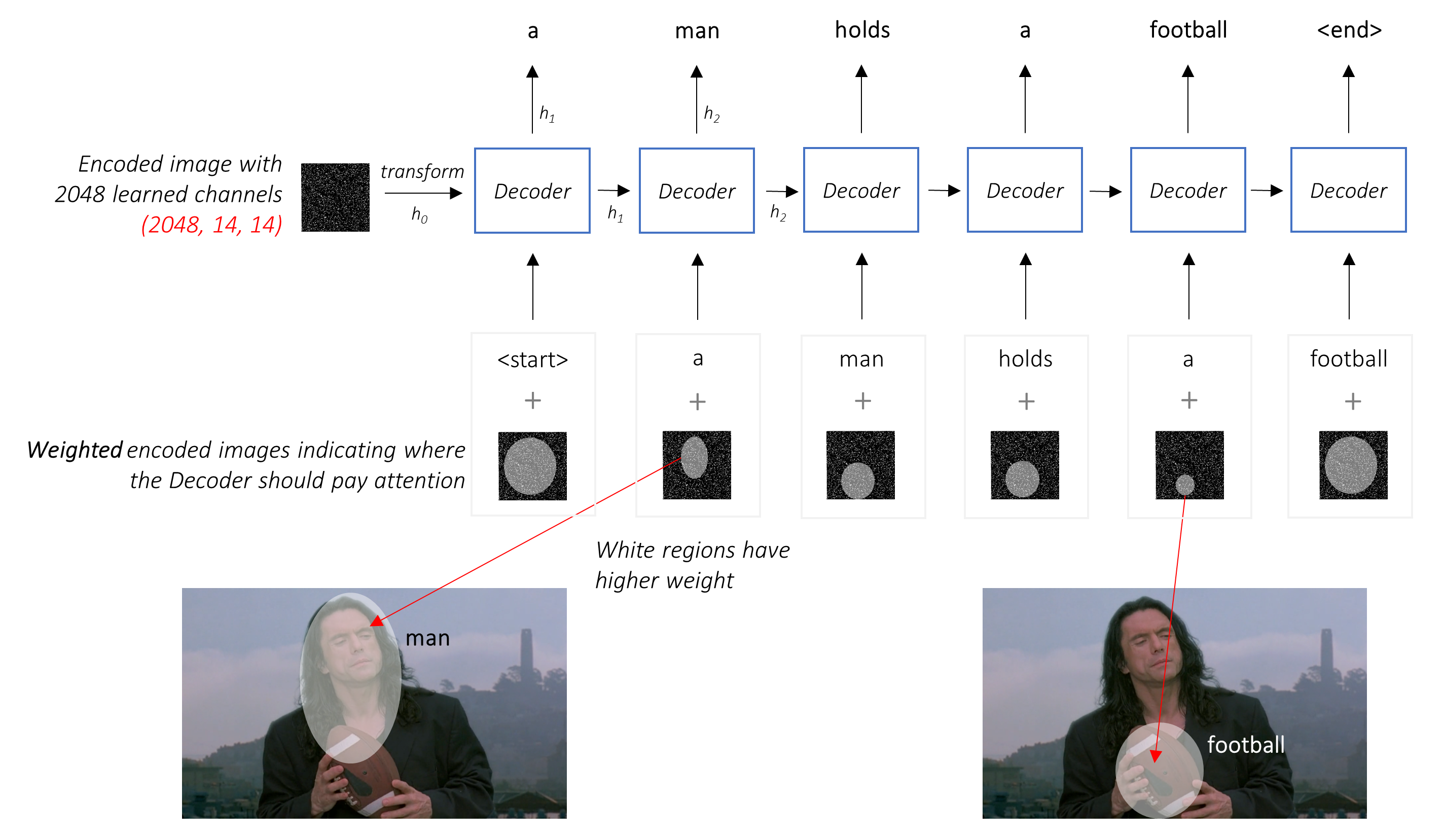
Alih -alih rata -rata sederhana, kami menggunakan rata -rata tertimbang di semua piksel, dengan bobot piksel penting lebih besar. Representasi bobot gambar ini dapat digabungkan dengan kata yang dihasilkan sebelumnya pada setiap langkah untuk menghasilkan kata berikutnya.
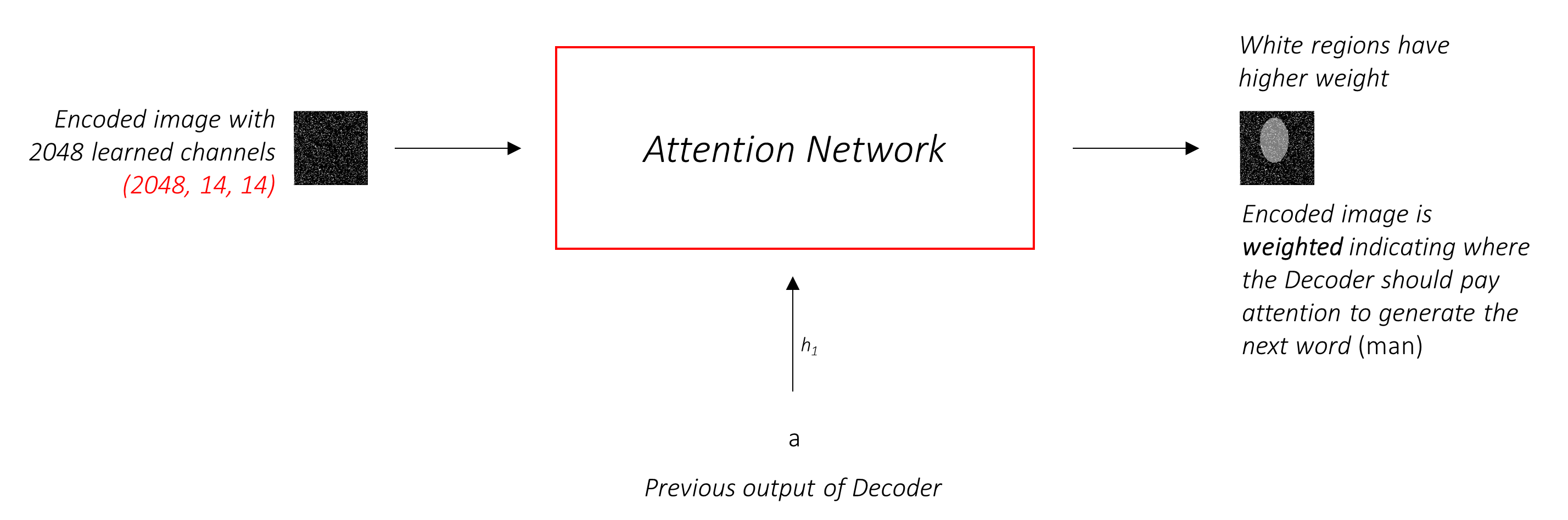
Jaringan perhatian menghitung bobot ini .
Secara intuitif, bagaimana Anda memperkirakan pentingnya bagian tertentu dari suatu gambar? Anda perlu menyadari urutan yang telah Anda hasilkan sejauh ini , sehingga Anda dapat melihat gambar dan memutuskan apa yang perlu digambarkan selanjutnya. Misalnya, setelah Anda menyebutkan a man , logis untuk menyatakan bahwa ia holding a football .
Inilah yang dilakukan oleh mekanisme perhatian - ia mempertimbangkan urutan yang dihasilkan sejauh ini, dan menghadiri bagian dari gambar yang perlu digambarkan selanjutnya.
Kami akan menggunakan perhatian lembut , di mana bobot piksel bertambah hingga 1. Jika ada piksel P pada gambar yang dikodekan kami, maka pada setiap waktu t -
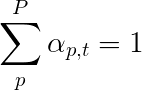
Anda dapat menafsirkan seluruh proses ini sebagai menghitung probabilitas bahwa piksel adalah tempat untuk menghasilkan kata berikutnya .
Mungkin sekarang seperti apa jaringan gabungan kami.
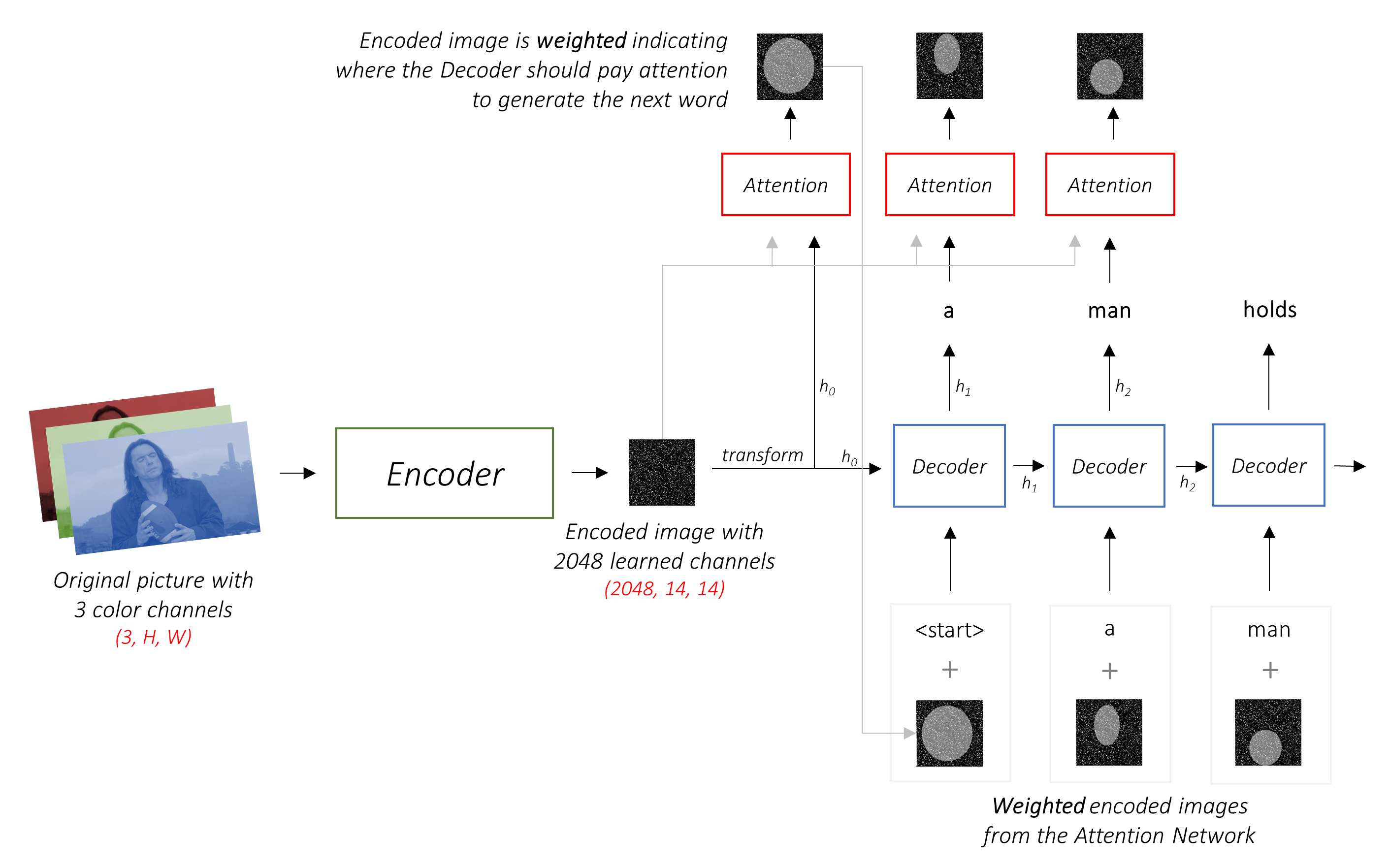
h (dan keadaan sel C ) untuk dekoder LSTM.Kami menggunakan lapisan linier untuk mengubah output decoder menjadi skor untuk setiap kata dalam kosakata.
Opsi langsung - dan serakah - adalah memilih kata dengan skor tertinggi dan menggunakannya untuk memprediksi kata berikutnya. Tapi ini tidak optimal karena sisa urutan bergantung pada kata pertama yang Anda pilih. Jika pilihan itu bukan yang terbaik, segala sesuatu yang mengikuti adalah sub-optimal. Dan itu bukan hanya kata pertama - setiap kata dalam urutan memiliki konsekuensi bagi orang -orang yang menggantikannya.
Mungkin sangat terjadi bahwa jika Anda memilih kata terbaik ketiga pada langkah pertama itu, dan kata terbaik kedua pada langkah kedua, dan seterusnya ... itu akan menjadi urutan terbaik yang bisa Anda hasilkan.
Akan lebih baik jika kita entah bagaimana tidak bisa memutuskan sampai kita telah menyelesaikan decoding sepenuhnya, dan memilih urutan yang memiliki skor keseluruhan tertinggi dari sekeranjang urutan kandidat .
Pencarian balok melakukan persis seperti ini.
k atas.k kedua untuk masing -masing kata pertama k ini.k [kata pertama, kata kedua] yang mempertimbangkan skor aditif.k ini, pilih k Kata -kata ketiga, pilih kombinasi k [kata pertama, kata kedua, kata ketiga].k berakhir, pilih urutan dengan skor keseluruhan terbaik. 
Seperti yang Anda lihat, beberapa urutan (mogok) mungkin gagal lebih awal, karena mereka tidak berhasil mencapai k atas pada langkah berikutnya. Setelah sekuens k (digarisbawahi) menghasilkan token <end> , kami memilih yang dengan skor tertinggi.
Bagian di bawah ini secara singkat menjelaskan implementasi.
Mereka dimaksudkan untuk memberikan beberapa konteks, tetapi detail paling baik dipahami langsung dari kode , yang cukup banyak dikomentari.
Saya menggunakan dataset MSCOCO '14. Anda harus mengunduh gambar pelatihan (13GB) dan validasi (6GB).
Kami akan menggunakan pelatihan, validasi, dan pemisahan tes Andrej Karpathy. File zip ini berisi teks. Anda juga akan menemukan pemisahan dan keterangan untuk kumpulan data Flicker8K dan Flicker30K, jadi jangan ragu untuk menggunakan ini alih -alih MSCOCO jika yang terakhir terlalu besar untuk komputer Anda.
Kami akan membutuhkan tiga input.
Karena kami menggunakan encoder pretrained, kami perlu memproses gambar ke dalam bentuk enkoder pretrain ini biasa.
Model imagenet pretrained tersedia sebagai bagian dari modul torchvision Pytorch. Halaman ini merinci preprocessing atau transformasi yang perlu kita lakukan - nilai piksel harus dalam kisaran [0,1] dan kita harus menormalkan gambar dengan rata -rata dan standar deviasi dari saluran RGB gambar imagenet.
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]Juga, Pytorch mengikuti konvensi NCHW, yang berarti dimensi saluran (c) harus mendahului dimensi ukuran.
Kami akan mengubah ukuran semua gambar MSCOCO menjadi 256x256 untuk keseragaman.
Oleh karena itu, gambar yang diumpankan ke model harus merupakan tensor Float dari dimensi N, 3, 256, 256 , dan harus dinormalisasi dengan rata -rata yang disebutkan di atas dan standar deviasi. N adalah ukuran batch.
Keterangan adalah target dan input decoder karena setiap kata digunakan untuk menghasilkan kata berikutnya.
Namun, untuk menghasilkan kata pertama, kita membutuhkan kata nol , <start> .
Pada kata terakhir, kita harus memprediksi <end> decoder harus belajar untuk memprediksi akhir dari keterangan. Ini diperlukan karena kita perlu tahu kapan harus berhenti decoding selama inferensi.
<start> a man holds a football <end>
Karena kita melewati keterangan di sekitar sebagai tensor ukuran tetap, kita perlu memadukan teks (yang secara alami memiliki panjang yang bervariasi) dengan panjang yang sama dengan token <pad> .
<start> a man holds a football <end> <pad> <pad> <pad>....
Selain itu, kami membuat word_map yang merupakan pemetaan indeks untuk setiap kata dalam korpus, termasuk token <start> , <end> , dan <pad> . Pytorch, seperti perpustakaan lainnya, membutuhkan kata -kata yang dikodekan sebagai indeks untuk mencari embeddings untuk mereka atau untuk mengidentifikasi tempat mereka dalam skor kata yang diprediksi.
9876 1 5 120 1 5406 9877 9878 9878 9878....
Oleh karena itu, teks yang diumpankan ke model harus merupakan tensor Int dimensi N, L di mana L adalah panjang empuk.
Karena keterangannya empuk, kita perlu melacak panjang setiap teks. Ini adalah panjang aktual + 2 (untuk token <start> dan <end> ).
Panjang keterangan juga penting karena Anda dapat membangun grafik dinamis dengan pytorch. Kami hanya memproses urutan hingga panjangnya dan tidak membuang komputasi pada <pad> s.
Oleh karena itu, panjang keterangan yang diumpankan ke model harus merupakan Int intension N .
Lihat create_input_files() di utils.py .
Ini membaca data yang diunduh dan menyimpan file berikut -
I, 3, 256, 256 , di mana I adalah jumlah gambar dalam perpecahan. Nilai piksel masih dalam kisaran [0, 255], dan disimpan sebagai Int 8-bit yang tidak ditandatangani.N_c * I mengkodekan teks , di mana N_c adalah jumlah teks sampel per gambar. Keterangan ini dalam urutan yang sama dengan gambar dalam file HDF5. Oleh karena itu, keterangan i akan sesuai dengan gambar i // N_c th.N_c * I Caption Lengths . Nilai i -i adalah panjang dari keterangan i , yang sesuai dengan gambar i // N_c th.word_map , kamus word-to-index. Sebelum kami menyimpan file -file ini, kami memiliki opsi untuk hanya menggunakan teks yang lebih pendek dari ambang batas, dan untuk bin lebih sering kata -kata ke dalam token <unk> .
Kami menggunakan file HDF5 untuk gambar karena kami akan membacanya langsung dari disk selama pelatihan / validasi. Mereka terlalu besar untuk masuk ke RAM sekaligus. Tapi kami memuat semua teks dan panjangnya ke dalam memori.
Lihat CaptionDataset dalam datasets.py .
Ini adalah subclass dari Dataset Pytorch. Dibutuhkan metode __len__ yang didefinisikan, yang mengembalikan ukuran dataset, dan metode __getitem__ yang mengembalikan i , keterangan, dan panjang caption.
Kami membaca gambar dari disk, mengonversi piksel menjadi [0,255], dan menormalkannya di dalam kelas ini.
Dataset akan digunakan oleh Pytorch DataLoader di train.py untuk membuat dan memberi makan batch data ke model untuk pelatihan atau validasi.
Lihat Encoder di models.py .
Kami menggunakan resnet-101 pretrained yang sudah tersedia dalam modul torchvision Pytorch. Buang dua lapisan terakhir (pooling dan lapisan linier), karena kita hanya perlu menyandikan gambar, dan tidak mengklasifikasikannya.
Kami menambahkan lapisan AdaptiveAvgPool2d() untuk mengubah ukuran pengkodean ke ukuran tetap . Ini memungkinkan untuk memberi makan gambar ukuran variabel ke encoder. (Namun, kami mengubah ukuran gambar input kami menjadi 256, 256 karena kami harus menyimpannya bersama sebagai satu tensor.)
Karena kami mungkin ingin menyempurnakan encoder, kami menambahkan metode fine_tune() yang memungkinkan atau menonaktifkan perhitungan gradien untuk parameter encoder. Kami hanya menyempurnakan blok konvolusional 2 hingga 4 di resnet , karena blok konvolusional pertama biasanya akan mempelajari sesuatu yang sangat mendasar untuk pemrosesan gambar, seperti mendeteksi garis, tepi, kurva, dll. Kami tidak mengacaukan fondasi.
Lihat Attention di models.py .
Jaringan perhatian sederhana - hanya terdiri dari lapisan linier dan beberapa aktivasi.
Lapisan linier terpisah mengubah kedua gambar yang dikodekan (diratakan ke N, 14 * 14, 2048 ) dan keadaan tersembunyi (output) dari dekoder ke dimensi yang sama , yaitu. Ukuran perhatian. Mereka kemudian ditambahkan dan diaktifkan Relu. Lapisan linier ketiga mengubah hasil ini menjadi dimensi 1 , di mana kita menerapkan softmax untuk menghasilkan bobot alpha .
Lihat DecoderWithAttention di models.py .
Output dari encoder diterima di sini dan diratakan ke dimensi N, 14 * 14, 2048 . Ini hanya nyaman dan mencegah harus membentuk kembali tensor beberapa kali.
Kami menginisialisasi keadaan tersembunyi dan sel LSTM menggunakan gambar yang dikodekan dengan metode init_hidden_state() , yang menggunakan dua lapisan linier terpisah.
Pada awalnya, kami mengurutkan N dan teks dengan mengurangi panjang judul . Ini agar kita hanya dapat memproses waktu yang valid , yaitu, bukan memproses <pad> s.
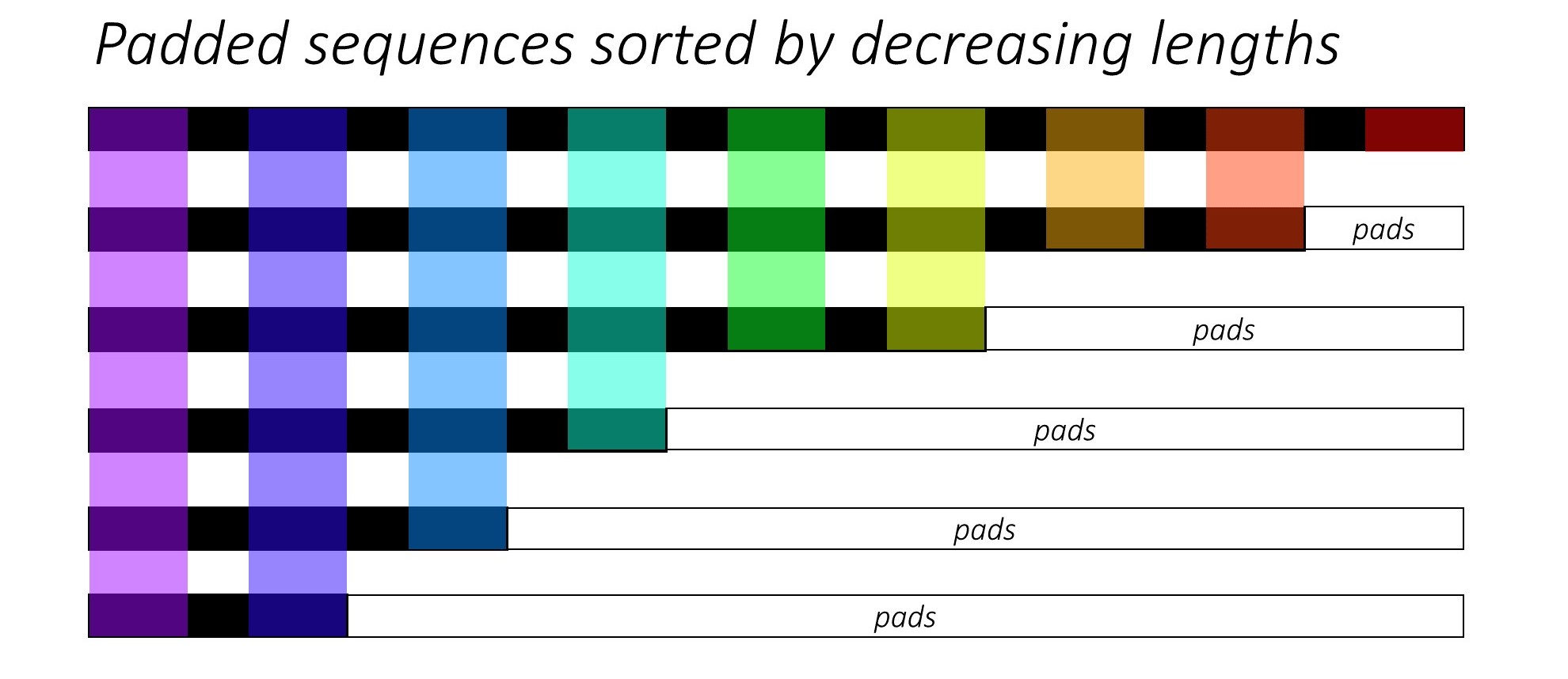
Kita dapat mengulangi setiap waktu, memproses hanya daerah berwarna, yang merupakan ukuran batch efektif N_t pada waktu itu. Penyortiran memungkinkan N_t teratas pada waktu mana pun untuk menyelaraskan dengan output dari langkah sebelumnya. Pada timestep ketiga, misalnya, kami hanya memproses 5 gambar teratas, menggunakan 5 output teratas dari langkah sebelumnya.
Iterasi ini dilakukan secara manual dalam for untuk pytorch LSTMCell alih -alih iterasi secara otomatis tanpa loop dengan LSTM Pytorch. Ini karena kita perlu menjalankan mekanisme perhatian antara setiap langkah decode. LSTMCell adalah operasi timestep tunggal, sedangkan LSTM akan mengulangi beberapa waktu terus -menerus dan memberikan semua output sekaligus.
Kami menghitung bobot dan pengkodean tertimbang perhatian di setiap waktu dengan jaringan perhatian. Di bagian 4.2.1 dari makalah ini, mereka merekomendasikan untuk menyampaikan pengkodean yang ditobatkan melalui filter atau gerbang . Gerbang ini adalah transformasi linier teraktivasi sigmoid dari keadaan tersembunyi decoder sebelumnya. Penulis menyatakan bahwa ini membantu jaringan perhatian lebih menekankan pada objek pada gambar.
Kami menggabungkan pengkodean tertimbang yang disaring ini dengan embedding dari kata sebelumnya ( <start> untuk memulai), dan jalankan LSTMCell untuk menghasilkan keadaan tersembunyi yang baru (atau output) . Lapisan linier mengubah keadaan tersembunyi baru ini menjadi skor untuk setiap kata dalam kosakata , yang disimpan.
Kami juga menyimpan bobot yang dikembalikan oleh jaringan perhatian di setiap waktu. Anda akan segera mengerti mengapa.
Sebelum Anda mulai, pastikan untuk menyimpan file data yang diperlukan untuk pelatihan, validasi, dan pengujian. Untuk melakukan ini, jalankan konten create_input_files.py setelah mengarahkannya ke file karpathy json dan folder gambar yang berisi folder train2014 dan val2014 yang diekstraksi dari data yang diunduh Anda.
Lihat train.py .
Parameter untuk model (dan melatihnya) berada di awal file, sehingga Anda dapat dengan mudah memeriksa atau memodifikasinya jika Anda ingin.
Untuk melatih model Anda dari awal , jalankan file ini -
python train.py
Untuk melanjutkan pelatihan di pos pemeriksaan , arahkan ke file yang sesuai dengan parameter checkpoint di awal kode.
Perhatikan bahwa kami melakukan validasi di akhir setiap zaman pelatihan.
Karena kami menghasilkan urutan kata, kami menggunakan CrossEntropyLoss . Anda hanya perlu mengirimkan skor mentah dari lapisan akhir dalam dekoder, dan fungsi kerugian akan melakukan operasi softmax dan log.
Para penulis makalah ini merekomendasikan menggunakan kerugian kedua - " regularisasi stokastik ganda ". Kita tahu jumlah bobot menjadi 1 pada waktu tertentu. Tapi kami juga mendorong bobot pada satu piksel p untuk berjumlah ke 1 di semua waktu T -
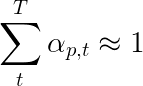
Ini berarti kami ingin model menghadiri setiap piksel selama menghasilkan seluruh urutan. Oleh karena itu, kami mencoba meminimalkan perbedaan antara 1 dan jumlah bobot piksel di semua waktu .
Kami tidak menghitung kerugian di daerah empuk . Cara mudah untuk menyingkirkan bantalan adalah dengan menggunakan pytorch's pack_padded_sequence() , yang meratakan tensor dengan waktu sambil mengabaikan daerah empuk. Anda sekarang dapat mengumpulkan kerugian atas tensor yang rata ini.
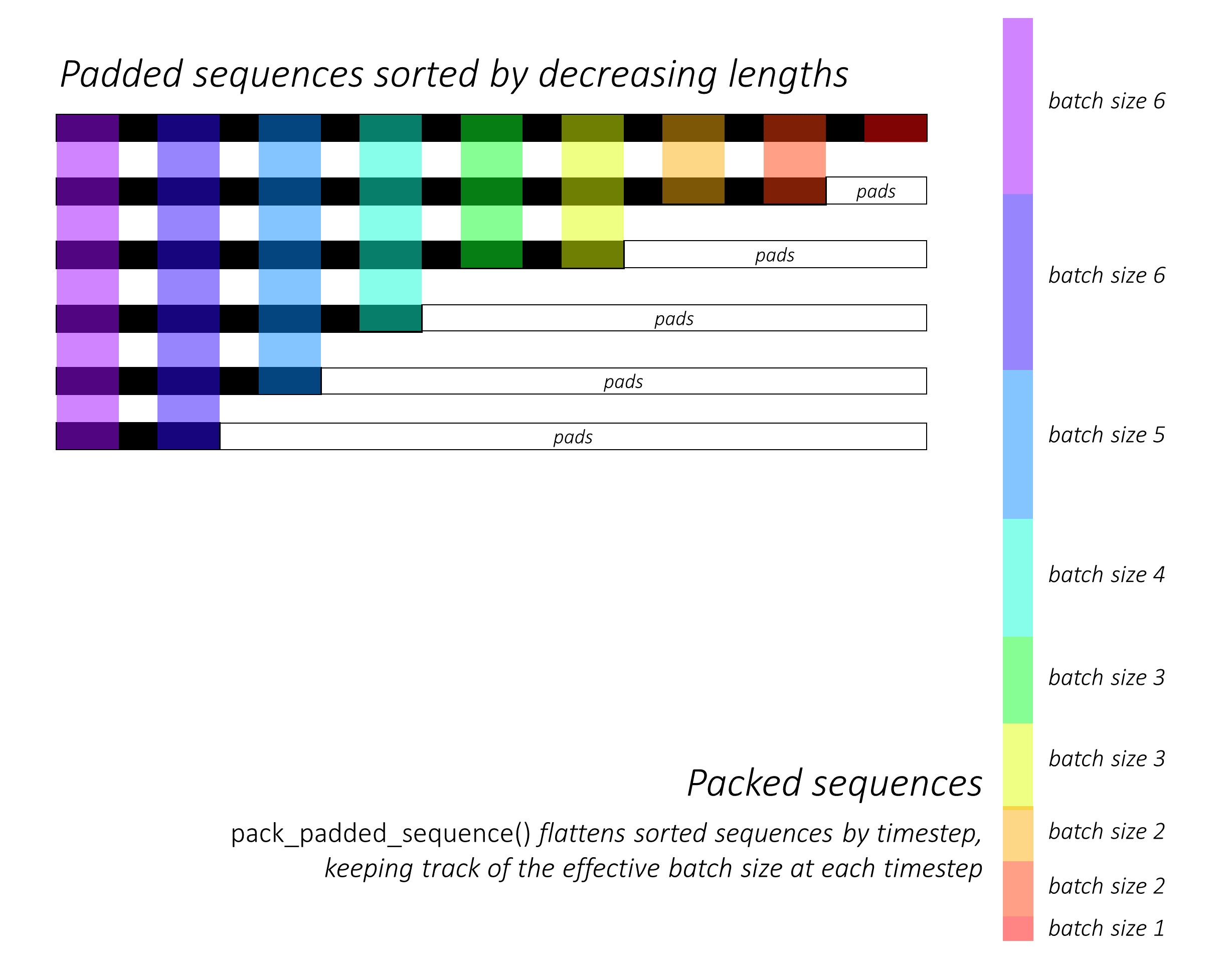
Catatan - Fungsi ini sebenarnya digunakan untuk melakukan batching dinamis yang sama (yaitu, hanya memproses ukuran batch yang efektif di setiap waktu) yang kami lakukan dalam dekoder kami, saat menggunakan RNN atau LSTM di Pytorch. Dalam hal ini, Pytorch menangani grafik panjang variabel dinamis secara internal. Anda dapat melihat contoh di dynamic_rnn.py dalam tutorial saya yang lain tentang pelabelan urutan. Kami akan menggunakan fungsi ini bersama dengan LSTM dalam dekoder kami jika kami tidak secara manual iterasi karena jaringan perhatian.
Untuk mengevaluasi kinerja model pada set validasi, kami akan menggunakan metrik evaluasi evaluasi evaluasi bilingual otomatis (BLEU). Ini mengevaluasi keterangan yang dihasilkan terhadap keterangan referensi. Untuk setiap keterangan yang dihasilkan, kami akan menggunakan semua teks N_c yang tersedia untuk gambar itu sebagai teks referensi.
Para penulis pertunjukan, menghadiri dan memberi tahu Paper mengamati bahwa korelasi antara kehilangan dan skor Bleu rusak setelah suatu titik, jadi mereka merekomendasikan untuk menghentikan pelatihan sejak awal ketika skor Bleu mulai menurun, bahkan jika kerugian terus berkurang.
Saya menggunakan alat bleu yang tersedia di modul NLTK.
Perhatikan bahwa ada kritik yang cukup besar terhadap skor Bleu karena tidak selalu berkorelasi baik dengan penilaian manusia. Para penulis juga melaporkan skor meteor karena alasan ini, tetapi saya belum menerapkan metrik ini.
Saya sarankan Anda berlatih secara bertahap.
Saya pertama kali melatih decoder, yaitu tanpa menyempurnakan encoder, dengan ukuran batch 80 . Saya berlatih untuk 20 zaman, dan skor Bleu-4 memuncak sekitar 23.25 pada zaman ke-13. Saya menggunakan pengoptimal Adam() dengan tingkat pembelajaran awal 4e-4 .
Saya melanjutkan dari pos pemeriksaan zaman ke-13 yang memungkinkan penyetelan penyandian dengan ukuran batch 32 . Ukuran batch yang lebih kecil adalah karena model sekarang lebih besar karena mengandung gradien encoder. Dengan fine-tuning, skor naik menjadi 24.29 hanya dalam sekitar 3 zaman. Pelatihan yang berkelanjutan mungkin akan mendorong skor sedikit lebih tinggi tetapi saya harus melakukan GPU saya di tempat lain.
Perbedaan penting untuk dibuat di sini adalah bahwa saya masih memasok kebenaran tanah sebagai input pada setiap decode-langkah selama validasi, terlepas dari kata yang terakhir dihasilkan . Ini disebut pemaksaan guru . Meskipun ini biasanya digunakan selama pelatihan untuk mempercepat proses, seperti yang kami lakukan, kondisi selama validasi harus meniru kondisi inferensi nyata sebanyak mungkin. Saya belum menerapkan inferensi batched - di mana setiap kata dalam keterangan dihasilkan dari kata yang dihasilkan sebelumnya, dan berakhir setelah memukul token <end> .
Karena saya memaksa guru selama validasi, skor Bleu diukur di atas pada keterangan yang dihasilkan tidak mencerminkan kinerja nyata. Faktanya, skor Bleu adalah metrik yang dirancang untuk membandingkan teks yang dihasilkan secara alami dengan keterangan kebenaran tanah dengan panjang yang berbeda. Setelah inferensi batch diimplementasikan, yaitu tidak ada guru yang memaksa, stopping dini dengan skor Bleu akan benar-benar 'tepat'.
Dengan pemikiran ini, saya menggunakan eval.py untuk menghitung skor Bleu-4 yang benar dari pos pemeriksaan model ini pada set validasi dan tes tanpa pemaksaan guru, pada ukuran balok yang berbeda-
| Ukuran balok | Validasi Bleu-4 | Uji Bleu-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
Skor tes lebih tinggi dari hasil dalam kertas, dan bisa karena bagaimana kalkulator Bleu kami diparameterisasi, fakta bahwa saya menggunakan encoder resnet, dan sebenarnya menyempurnakan enkoder-bahkan jika hanya sedikit.
Juga, ingat-ketika menyempurnakan selama pembelajaran transfer, selalu lebih baik menggunakan tingkat pembelajaran yang jauh lebih kecil dari apa yang awalnya digunakan untuk melatih model pinjaman. Ini karena modelnya sudah cukup dioptimalkan, dan kami tidak ingin mengubah sesuatu yang terlalu cepat. Saya menggunakan Adam() untuk enkoder juga, tetapi dengan tingkat pembelajaran 1e-4 , yang merupakan sepersepuluh dari nilai default untuk pengoptimal ini.
Pada Titan X (Pascal), butuh 55 menit per zaman tanpa penyetelan, dan 2,5 jam dengan penyesuaian pada ukuran batch yang dinyatakan.
Anda dapat mengunduh model pretrained ini dan word_map yang sesuai di sini.
Perhatikan bahwa pos pemeriksaan ini harus dimuat langsung dengan Pytorch, atau diteruskan ke caption.py - lihat di bawah.
Lihat caption.py .
Selama inferensi, kami tidak dapat secara langsung menggunakan metode forward() dalam dekoder karena menggunakan pemaksaan guru. Sebaliknya, kita benar -benar perlu memberi makan kata yang dihasilkan sebelumnya ke LSTM di setiap waktu .
caption_image_beam_search() Membaca gambar, mengkodekannya, dan menerapkan lapisan dalam dekoder dalam urutan yang benar, saat menggunakan kata yang dihasilkan sebelumnya sebagai input ke LSTM di setiap waktu. Ini juga menggabungkan pencarian balok.
visualize_att() dapat digunakan untuk memvisualisasikan keterangan yang dihasilkan bersama dengan bobot pada setiap waktu seperti yang terlihat dalam contoh.
Untuk menulis gambar dari baris perintah, arahkan ke gambar, model post checkpoint, peta kata (dan secara opsional, ukuran balok) sebagai berikut -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
Atau, gunakan fungsi dalam file sesuai kebutuhan.
Lihat juga eval.py , yang mengimplementasikan proses ini untuk menghitung skor Bleu pada set validasi, dengan atau tanpa pencarian balok.





Tes Turing Tommy - Anda tahu AI tidak benar -benar AI karena belum menonton ruangan dan tidak mengenali kebesaran ketika melihatnya.

Anda mengatakan perhatian lembut . Apakah ada, um, perhatian yang sulit ?
Ya, pertunjukan, hadir dan memberi tahu Paper menggunakan kedua varian, dan decoder dengan perhatian "keras" berkinerja sedikit lebih baik.
Dalam perhatian lembut , yang kami gunakan di sini, Anda menghitung bobot alpha dan menggunakan rata -rata tertimbang dari fitur di semua piksel. Ini adalah operasi deterministik dan dapat dibedakan.
Dalam perhatian yang sulit , Anda memilih untuk hanya mencicipi beberapa piksel dari distribusi yang ditentukan oleh alpha . Perhatikan bahwa pengambilan sampel probabilistik semacam itu bersifat non-deterministik atau stokastik , yaitu input spesifik tidak akan selalu menghasilkan output yang sama. Tetapi karena keturunan gradien mengandaikan bahwa jaringan tersebut deterministik (dan karenanya dapat dibedakan), pengambilan sampel dikerjakan ulang untuk menghilangkan stokastiknya. Pengetahuan saya tentang hal ini cukup dangkal pada saat ini - saya akan memperbarui jawaban ini ketika saya memiliki pemahaman yang lebih rinci.
Bagaimana cara menggunakan jaringan perhatian untuk tugas NLP seperti model urutan ke urutan?
Sama seperti Anda menggunakan CNN untuk menghasilkan pengkodean dengan fitur di setiap piksel, Anda akan menggunakan RNN untuk menghasilkan fitur yang dikodekan pada setiap posisi kata IE dalam input.
Tanpa perhatian, Anda akan menggunakan output encoder pada waktu terakhir sebagai pengkodean untuk seluruh kalimat, karena itu juga akan berisi informasi dari waktu sebelumnya. Output terakhir encoder sekarang menanggung beban karena harus menyandikan seluruh kalimat secara bermakna, yang tidak mudah, terutama untuk kalimat yang lebih lama.
Dengan perhatian, Anda akan menghadiri waktu dalam waktu dalam output encoder, menghasilkan bobot untuk setiap waktu/kata, dan mengambil rata -rata tertimbang untuk mewakili kalimat. Dalam urutan tugas untuk mendaftar seperti terjemahan mesin, Anda akan menghadiri kata -kata yang relevan dalam input saat Anda menghasilkan setiap kata dalam output.
Anda juga bisa menggunakan perhatian tanpa decoder. Misalnya, jika Anda ingin mengklasifikasikan teks, Anda dapat menghadiri kata -kata penting dalam input hanya sekali untuk melakukan klasifikasi.
Bisakah kita menggunakan pencarian balok selama pelatihan?
Tidak dengan fungsi kerugian saat ini, tapi ya. Ini tidak umum sama sekali.
Apa yang dipaksakan guru?
Guru memaksa adalah ketika kita menggunakan keterangan kebenaran sebagai input ke decoder di setiap waktu, dan bukan kata yang dihasilkannya dalam waktu sebelumnya. Adalah umum untuk memaksa guru selama pelatihan karena itu bisa berarti konvergensi model yang lebih cepat. Tetapi juga dapat belajar bergantung pada diberitahu jawaban yang benar, dan menunjukkan beberapa ketidakstabilan dalam praktik.
Akan sangat ideal untuk berlatih menggunakan guru memaksa hanya beberapa waktu, berdasarkan probabilitas. Ini disebut pengambilan sampel yang dijadwalkan.
(Saya berencana untuk menambahkan opsi).
Dapatkah saya menggunakan embeddings kata pretrain (sarung tangan, cbow, skipgram, dll.) Alih -alih mempelajarinya dari awal?
Ya, Anda bisa, dengan metode load_pretrained_embeddings() di kelas Decoder . Anda juga dapat memilih untuk menyempurnakan (atau tidak) dengan metode fine_tune_embeddings() .
Setelah membuat decoder di train.py , Anda harus menyediakan vektor pretrained untuk load_pretrained_embeddings() ditumpuk dalam urutan yang sama seperti pada word_map . Untuk kata -kata yang tidak Anda miliki vektor pretrained, seperti <start> , Anda dapat menginisialisasi embeddings secara acak seperti yang kami lakukan di init_weights() . Saya merekomendasikan penyempurnaan untuk mempelajari vektor yang lebih bermakna untuk vektor yang diinisialisasi secara acak ini.
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False Pastikan juga untuk mengubah parameter emb_dim dari nilai saat ini dari 512 ke ukuran embeddings pra-terlatih Anda. Ini harus secara otomatis menyesuaikan ukuran input LSTM decoder untuk mengakomodasi mereka.
Bagaimana cara melacak tensor mana yang memungkinkan gradien dihitung?
Dengan rilis Pytorch 0.4 , tensor pembungkus sebagai Variable S tidak lagi diperlukan. Sebagai gantinya, tensor memiliki atribut requires_grad , yang memutuskan apakah dilacak oleh autograd , dan oleh karena itu apakah gradien dihitung untuk itu selama propagasi back.
requires_grad akan diatur ke False .requires_grad akan diatur ke True .torch.nn sudah akan memiliki requires_grad yang ditetapkan ke True .Bagaimana cara menghitung semua skor Bleu (yaitu Bleu-1 ke Bleu-4) selama evaluasi?
Anda harus memodifikasi kode di eval.py untuk melakukan ini. Silakan lihat jawaban luar biasa ini oleh KMario23 untuk penjelasan yang jelas dan terperinci.


