a PyTorch Tutorial to Image Captioning
1.0.0
Este es un tutorial de Pytorch para el subtítulos .
Esta es la primera de una serie de tutoriales que escribo sobre la implementación de modelos geniales por su cuenta con la increíble Biblioteca Pytorch.
Se asume el conocimiento básico de las redes neuronales de Pytorch, convolucionales y recurrentes.
Si eres nuevo en Pytorch, primero lea el aprendizaje profundo con Pytorch: un bombardeo de 60 minutos y aprendizaje de Pytorch con ejemplos.
Las preguntas, sugerencias o correcciones se pueden publicar como problemas.
Estoy usando PyTorch 0.4 en Python 3.6 .
27 de enero de 2020 : Se ha agregado código de trabajo para dos tutoriales nuevos: súper resolución y traducción automática
Objetivo
Conceptos
Descripción general
Implementación
Capacitación
Inferencia
Preguntas frecuentes
Para construir un modelo que pueda generar una leyenda descriptiva para una imagen, le proporcionamos.
En aras de mantener las cosas simples, implementemos el programa, asistir y contar el papel. Este es de ninguna manera el estado actual del arte, pero sigue siendo bastante sorprendente. La implementación original de los autores se puede encontrar aquí.
Este modelo aprende dónde mirar.
A medida que genera un título, palabra por palabra, puede ver la mirada del modelo cambiando a través de la imagen.
Esto es posible debido a su mecanismo de atención , que le permite centrarse en la parte de la imagen más relevante para la palabra que va a pronunciar a continuación.
Aquí hay algunos subtítulos generados en las imágenes de prueba no vistas durante el entrenamiento o la validación:




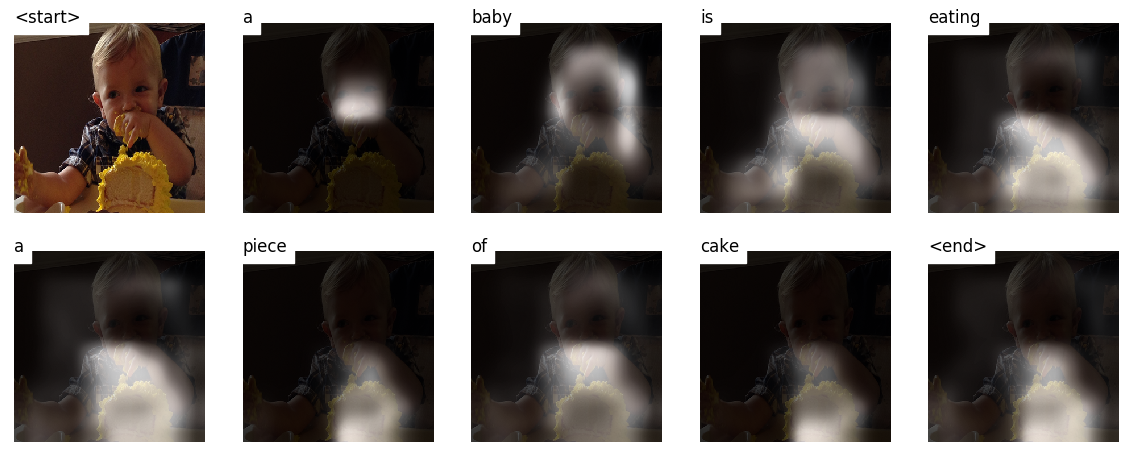

Hay más ejemplos al final del tutorial.
Subtítulos de imagen . duh.
Arquitectura del codificador codificador . Por lo general, un modelo que genera secuencias usará un codificador para codificar la entrada en una forma fija y un decodificador para decodificarlo, palabra por palabra, en una secuencia.
Atención . El uso de redes de atención está muy extendida en el aprendizaje profundo y con buenas razones. Esta es una forma para que un modelo elija solo aquellas partes de la codificación que cree que es relevante para la tarea en cuestión. El mismo mecanismo que ve empleado aquí puede usarse en cualquier modelo donde la salida del codificador tenga múltiples puntos en el espacio o el tiempo. En el subtítulos de imágenes, considera algunos píxeles más importantes que otros. En secuencia a tareas de secuencia como la traducción automática, considera algunas palabras más importantes que otras.
Transferir el aprendizaje . Esto es cuando tomas prestado de un modelo existente usando partes de él en un nuevo modelo. Esto casi siempre es mejor que entrenar un nuevo modelo desde cero (es decir, no sabiendo nada). Como verá, siempre puede ajustar este conocimiento de segunda mano a la tarea específica en cuestión. El uso de incrustaciones de palabras previas al detenido es un ejemplo tonto pero válido. Para nuestro problema de subtítulos de imagen, usaremos un codificador previamente provocado y luego lo ajustaremos según sea necesario.
Búsqueda de haz . Aquí es donde no deja que su decodificador sea perezoso y simplemente elija las palabras con la mejor puntuación en cada paso de decodificación. La búsqueda del haz es útil para cualquier problema de modelado de lenguaje porque encuentra la secuencia más óptima.
En esta sección, presentaré una descripción general de este modelo. Si ya está familiarizado con él, puede omitir directamente a la sección de implementación o al código comentado.
El codificador codifica la imagen de entrada con 3 canales de color en una imagen más pequeña con canales "aprendidos" .
Esta imagen codificada más pequeña es una representación resumida de todo lo que es útil en la imagen original.
Como queremos codificar imágenes, utilizamos redes neuronales convolucionales (CNN).
No necesitamos entrenar a un codificador desde cero. ¿Por qué? Porque ya hay CNN entrenados para representar imágenes.
Durante años, las personas han estado construyendo modelos que son extraordinariamente buenos para clasificar una imagen en una de las mil categorías. Es lógico razonar que estos modelos capturen muy bien la esencia de una imagen.
He elegido usar la red residual de 101 capas capacitada en la tarea de clasificación de ImageNet , ya disponible en Pytorch. Como se dijo anteriormente, este es un ejemplo de aprendizaje de transferencia. Tiene la opción de ajustarlo para mejorar el rendimiento.

Estos modelos crean progresivamente representaciones cada vez más pequeñas de la imagen original, y cada representación posterior es más "aprendida", con un mayor número de canales. La codificación final producida por nuestro codificador ResNet-101 tiene un tamaño de 14x14 con 2048 canales, es decir, un tensor de tamaño 2048, 14, 14 .
Te animo a que experimente con otras arquitecturas previamente capacitadas. El documento usa un VGGNet, también previamente en Imagenet, pero sin ajuste. De cualquier manera, las modificaciones son necesarias. Dado que la última capa o dos de estos modelos son capas lineales junto con la activación de Softmax para la clasificación, las eliminamos.
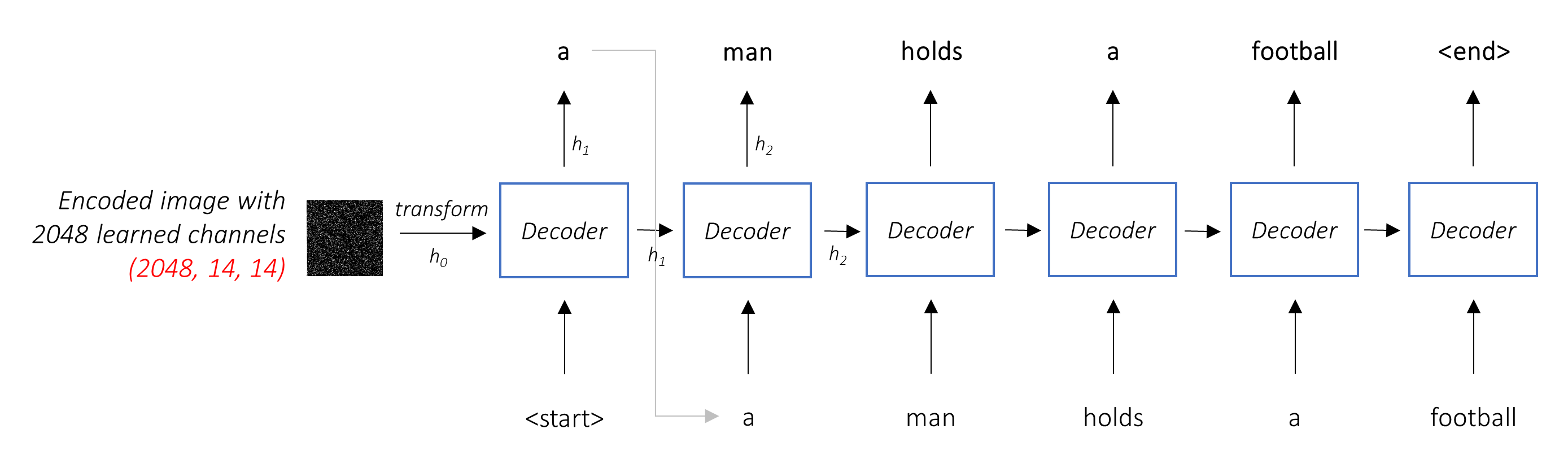
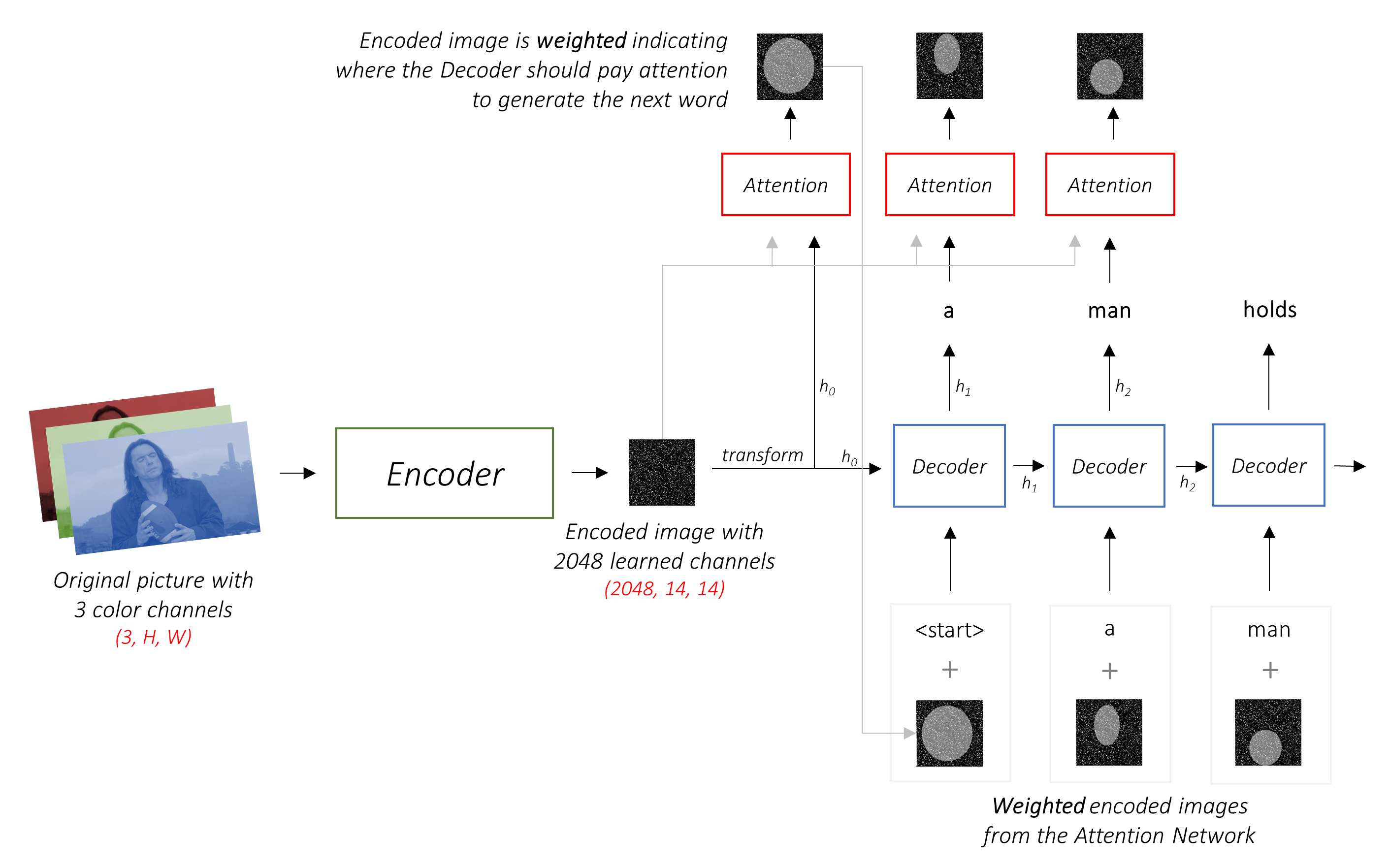
El trabajo del decodificador es mirar la imagen codificada y generar una palabra por palabra .
Dado que está generando una secuencia, necesitaría ser una red neuronal recurrente (RNN). Usaremos un LSTM.
En un entorno típico sin atención, simplemente podría promediar la imagen codificada en todos los píxeles. Luego podría alimentar esto, con o sin una transformación lineal, en el decodificador como su primer estado oculto y generar la leyenda. Cada palabra predicha se usa para generar la siguiente palabra.
En un entorno con atención, queremos que el decodificador pueda mirar diferentes partes de la imagen en diferentes puntos de la secuencia . Por ejemplo, mientras generar la palabra football en a man holds a football , el decodificador sabría concentrarse en, lo adivinó, ¡el fútbol!
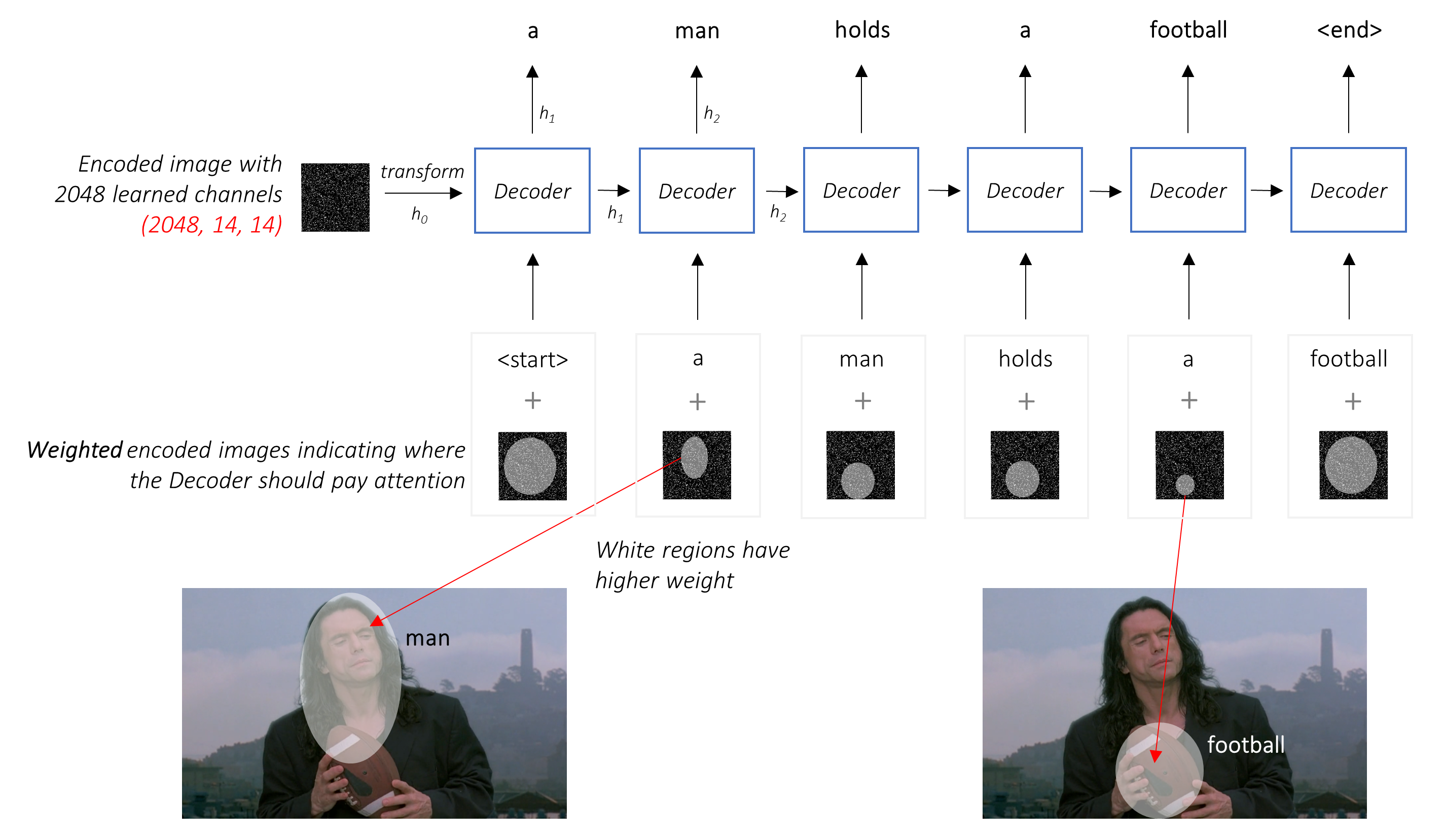
En lugar del promedio simple, usamos el promedio ponderado en todos los píxeles, siendo mayores los pesos de los píxeles importantes. Esta representación ponderada de la imagen se puede concatenar con la palabra generada previamente en cada paso para generar la siguiente palabra.
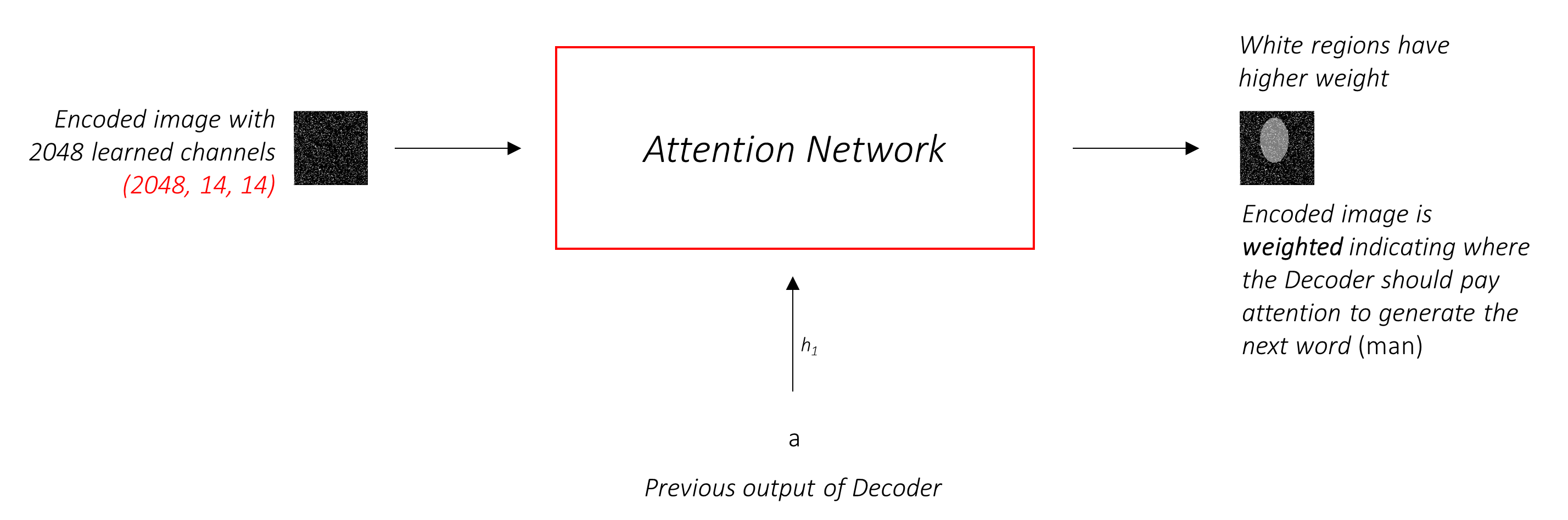
La red de atención calcula estos pesos .
Intuitivamente, ¿cómo estimaría la importancia de una parte determinada de una imagen? Debería ser consciente de la secuencia que ha generado hasta ahora , para que pueda mirar la imagen y decidir qué necesita describir a continuación. Por ejemplo, después de mencionar a man , es lógico declarar que está holding a football .
Esto es exactamente lo que hace el mecanismo de atención: considera la secuencia generada hasta ahora y atiende a la parte de la imagen que necesita describir a continuación.
Usaremos una atención suave , donde los pesos de los píxeles se suman a 1. Si hay pxeles P en nuestra imagen codificada, entonces en cada tiempo de tiempo t
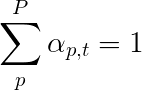
Podría interpretar todo este proceso como calcular la probabilidad de que un píxel sea el lugar para buscar generar la siguiente palabra .
Puede estar claro a estas alturas cómo se ve nuestra red combinada.
h (y el estado celular C ) inicial para el decodificador LSTM.Usamos una capa lineal para transformar la salida del decodificador en una puntuación para cada palabra en el vocabulario.
La opción directa y codiciosa sería elegir la palabra con la puntuación más alta y usarla para predecir la siguiente palabra. Pero esto no es óptimo porque el resto de la secuencia depende de esa primera palabra que elija. Si esa elección no es la mejor, todo lo que sigue es subóptimo. Y no es solo la primera palabra: cada palabra en la secuencia tiene consecuencias para las que la tienen éxito.
Bien podría suceder que si hubiera elegido la tercera mejor palabra en ese primer paso, y la segunda mejor palabra en el segundo paso, y así sucesivamente ... esa sería la mejor secuencia que podría generar.
Sería mejor si de alguna manera no pudiéramos decidir hasta que hayamos terminado de decodificar por completo, y elegir la secuencia que tenga la puntuación general más alta de una canasta de secuencias candidatas .
Beam Search hace exactamente esto.
kk segundas palabras para cada una de estas k primeras palabras.k [Primera palabra, segunda palabra] considerando las puntuaciones aditivas.k Second Words, elija k Terceras palabras, elija las combinaciones k [primera palabra, segunda palabra, tercera palabra].k , elija la secuencia con la mejor puntuación general. 
Como puede ver, algunas secuencias (eliminadas) pueden fallar temprano, ya que no llegan a la parte superior k en el siguiente paso. Una vez que las secuencias k (subrayadas) generan el token <end> , elegimos el que tiene la puntuación más alta.
Las secciones a continuación describen brevemente la implementación.
Están destinados a proporcionar algún contexto, pero los detalles se entienden mejor directamente del código , que se comenta bastante.
Estoy usando el conjunto de datos MSCOCO '14. Debería descargar las imágenes de capacitación (13 GB) y validación (6GB).
Usaremos las divisiones de entrenamiento, validación y prueba de Andrej Karpathy. Este archivo zip contiene los subtítulos. También encontrará divisiones y subtítulos para los conjuntos de datos Flicker8k y Flicker30k, así que siéntase libre de usarlos en lugar de mscoco si este último es demasiado grande para su computadora.
Necesitaremos tres entradas.
Dado que estamos utilizando un codificador previo al estado previo, tendríamos que procesar las imágenes en la forma a la que está acostumbrado a este codificador previo.
Modelos de Imagenet previos a la aparición disponibles como parte del módulo torchvision de Pytorch. Esta página detalla el preprocesamiento o la transformación que debemos realizar: los valores de píxeles deben estar en el rango [0,1] y luego debemos normalizar la imagen por la desviación media y estándar de los canales RGB de las imágenes de ImageNet.
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]Además, Pytorch sigue la convención NCHW, lo que significa que la dimensión de los canales (c) debe preceder a las dimensiones de tamaño.
Cambiaremos todas las imágenes de MSCOCO a 256x256 para la uniformidad.
Por lo tanto, las imágenes alimentadas al modelo deben ser un tensor Float de la dimensión N, 3, 256, 256 , y deben normalizarse por la media mencionada y la desviación estándar. N es el tamaño de lote.
Los subtítulos son tanto el objetivo como las entradas del decodificador, ya que cada palabra se usa para generar la siguiente palabra.
Sin embargo, para generar la primera palabra, necesitamos una palabra cero , <start> inicio>.
En la última palabra, debemos predecir <end> el decodificador debe aprender a predecir el final de un subtítulo. Esto es necesario porque necesitamos saber cuándo dejar de decodificar durante la inferencia.
<start> a man holds a football <end>
Dado que pasamos los subtítulos como tensores de tamaño fijo, necesitamos almohadillas (que son naturalmente de longitud variable) a la misma longitud con tokens <pad> .
<start> a man holds a football <end> <pad> <pad> <pad>....
Además, creamos un word_map que es una asignación de índice para cada palabra en el corpus, incluidos los tokens <start> , <end> y <pad> . Pytorch, como otras bibliotecas, necesita palabras codificadas como índices para buscar incrustaciones para ellos o para identificar su lugar en las puntuaciones de palabras predichas.
9876 1 5 120 1 5406 9877 9878 9878 9878....
Por lo tanto, los subtítulos alimentados al modelo deben ser un Int de dimensión N, L donde L es la longitud acolchada.
Dado que los subtítulos están acolchados, tendríamos que realizar un seguimiento de las longitudes de cada leyenda. Esta es la longitud real + 2 (para los tokens <start> y <end> ).
Las longitudes de subtítulos también son importantes porque puede construir gráficos dinámicos con Pytorch. Solo procesamos una secuencia hasta su longitud y no desperdiciamos el cálculo en el <pad> S.
Por lo tanto, las longitudes de subtítulos alimentadas al modelo deben ser un Int de dimensión N .
Ver create_input_files() en utils.py .
Esto lee los datos descargados y guarda los siguientes archivos -
I, 3, 256, 256 , donde I es el número de imágenes en la división. Los valores de píxeles todavía están en el rango [0, 255], y se almacenan como Int sin firmar de 8 bits.N_c * I , donde N_c es el número de subtítulos muestreados por imagen. Estos subtítulos están en el mismo orden que las imágenes en el archivo HDF5. Por lo tanto, el subtítulo i th corresponderá a la imagen i // N_c th.N_c * I El valor i es la longitud de i ley, que corresponde a la imagen i // N_c th.word_map , el diccionario de palabra a índice. Antes de guardar estos archivos, tenemos la opción de usar solo subtítulos que son más cortos que un umbral, y de agrupar palabras menos frecuentes en un <unk> .
Usamos archivos HDF5 para las imágenes porque los leeremos directamente desde el disco durante la capacitación / validación. Simplemente son demasiado grandes para encajar en RAM a la vez. Pero cargamos todos los subtítulos y sus longitudes en la memoria.
Ver CaptionDataset en datasets.py .
Esta es una subclase del Dataset Pytorch. Necesita un método __len__ definido, que devuelve el tamaño del conjunto de datos, y un método __getitem__ que devuelve la i th imagen, leyenda y longitud de subtítulos.
Leemos imágenes del disco, convertimos píxeles a [0,255] y las normalizamos dentro de esta clase.
El Dataset será utilizado por un Pytorch DataLoader en train.py para crear y alimentar lotes de datos al modelo para su entrenamiento o validación.
Ver Encoder en models.py .
Utilizamos un resnet-101 pretranado ya disponible en el módulo torchvision de Pytorch. Deseche las dos últimas capas (agrupación y capas lineales), ya que solo necesitamos codificar la imagen y no clasificarla.
Agregamos una capa AdaptiveAvgPool2d() para cambiar el tamaño de la codificación a un tamaño fijo . Esto permite alimentar imágenes de tamaño variable al codificador. (Sin embargo, redimensionamos nuestras imágenes de entrada a 256, 256 porque tuvimos que almacenarlas juntas como un solo tensor).
Dado que es posible que deseemos ajustar el codificador, agregamos un método fine_tune() que habilita o deshabilita el cálculo de gradientes para los parámetros del codificador. Solo afinamos los bloques convolucionales 2 a 4 en el resnet , porque el primer bloque convolucional generalmente habría aprendido algo muy fundamental para el procesamiento de imágenes, como detectar líneas, bordes, curvas, etc. No nos metemos con las bases.
Ver Attention en models.py .
La red de atención es simple: se compone de solo capas lineales y un par de activaciones.
Las capas lineales separadas transforman tanto la imagen codificada (aplanada a N, 14 * 14, 2048 ) como el estado oculto (salida) del decodificador a la misma dimensión , a saber. el tamaño de atención. Luego se agregan y se activan. Una tercera capa lineal transforma este resultado en una dimensión de 1 , con lo cual aplicamos el Softmax para generar los pesos alpha .
Ver DecoderWithAttention en models.py .
La salida del codificador se recibe aquí y se aplana a las dimensiones N, 14 * 14, 2048 . Esto es conveniente y evita tener que remodelar el tensor varias veces.
Inicializamos el estado oculto y celular del LSTM utilizando la imagen codificada con el método init_hidden_state() , que utiliza dos capas lineales separadas.
Al principio, ordenamos las N imágenes y subtítulos disminuyendo las longitudes de los subtítulos . Esto es para que podamos procesar solo times de tiempo válidos , es decir, no procesar los <pad> s.
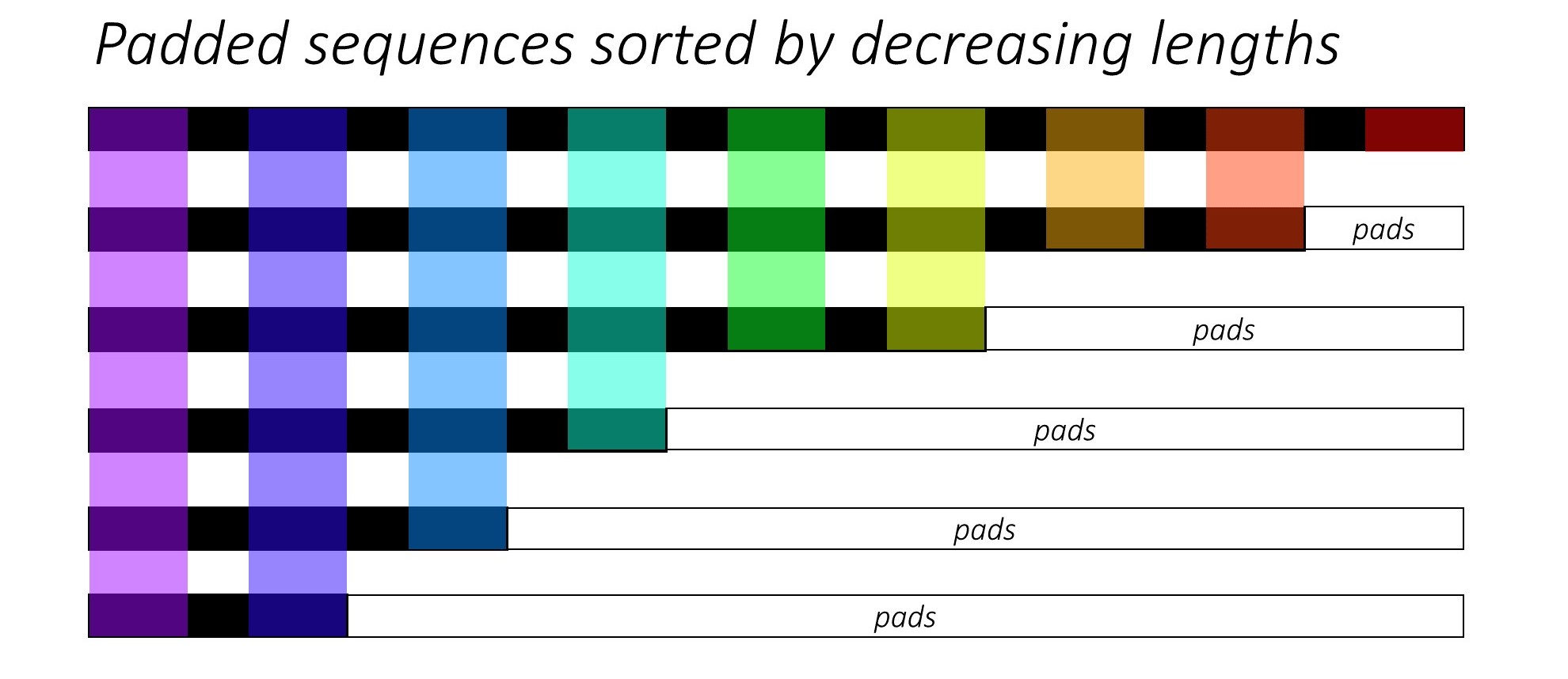
Podemos iterar sobre cada paso de tiempo, procesando solo las regiones de colores, que son el tamaño de lote efectivo N_t en ese momento de tiempo. La clasificación permite que el N_t superior en cualquier paso de tiempo se alinee con las salidas del paso anterior. En el tercer tiempo de tiempo, por ejemplo, procesamos solo las 5 imágenes principales, utilizando las 5 salidas principales del paso anterior.
Esta iteración se realiza manualmente en un bucle for con un pytorch LSTMCell en lugar de iterarse automáticamente sin un bucle con un pytorch LSTM . Esto se debe a que necesitamos ejecutar el mecanismo de atención entre cada paso de decodificación. Un LSTMCell es una operación de tiempo de tiempo único, mientras que un LSTM iteraría continuamente sobre múltiples times y proporcionaría todas las salidas a la vez.
Calculamos los pesos y la codificación ponderada en la atención en cada paso de tiempo con la red de atención. En la sección 4.2.1 del documento, recomiendan pasar la codificación ponderada de atención a través de un filtro o puerta . Esta puerta es una transformación lineal activada por sigmoide del estado oculto anterior del decodificador. Los autores afirman que esto ayuda a la red de atención a poner más énfasis en los objetos en la imagen.
Concatenamos esta codificación de atención filtrada con la incrustación de la palabra anterior ( <start> para comenzar), y ejecutamos el LSTMCell para generar el nuevo estado oculto (o salida) . Una capa lineal transforma este nuevo estado oculto en puntajes para cada palabra en el vocabulario , que se almacena.
También almacenamos los pesos devueltos por la red de atención en cada paso de tiempo. Verás por qué pronto.
Antes de comenzar, asegúrese de guardar los archivos de datos requeridos para capacitación, validación y pruebas. Para hacer esto, ejecute el contenido de create_input_files.py después de señalarlo al archivo Karpathy JSON y la carpeta de imagen que contiene las carpetas extraídas train2014 y val2014 de sus datos descargados.
Ver train.py .
Los parámetros para el modelo (y la capacitación) están al comienzo del archivo, por lo que puede verificarlos o modificarlos fácilmente si lo desea.
Para entrenar a su modelo desde cero , simplemente ejecute este archivo -
python train.py
Para reanudar la capacitación en un punto de control , apunte al archivo correspondiente con el parámetro de checkpoint al comienzo del código.
Tenga en cuenta que realizamos validación al final de cada época de entrenamiento.
Como estamos generando una secuencia de palabras, usamos CrossEntropyLoss . Solo necesita enviar las puntuaciones sin procesar desde la capa final en el decodificador, y la función de pérdida realizará las operaciones SoftMax y Log.
Los autores del documento recomiendan usar una segunda pérdida: una " regularización doblemente estocástica ". Conocemos la suma de los pesos a 1 en un paso de tiempo dado. Pero también alentamos los pesos en un solo píxel p a sumar a 1 en todos los times de TimesPs T
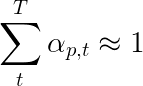
Esto significa que queremos que el modelo atienda cada píxel en el transcurso de la generación de toda la secuencia. Por lo tanto, tratamos de minimizar la diferencia entre 1 y la suma de los pesos de un píxel en todos los puntos de tiempo .
No calculamos pérdidas sobre las regiones acolchadas . Una manera fácil de deshacerse de las almohadillas es usar Pytorch pack_padded_sequence() , que aplana el tensor por tiempo de tiempo mientras ignora las regiones acolchadas. Ahora puede agregar la pérdida sobre este tensor aplanado.
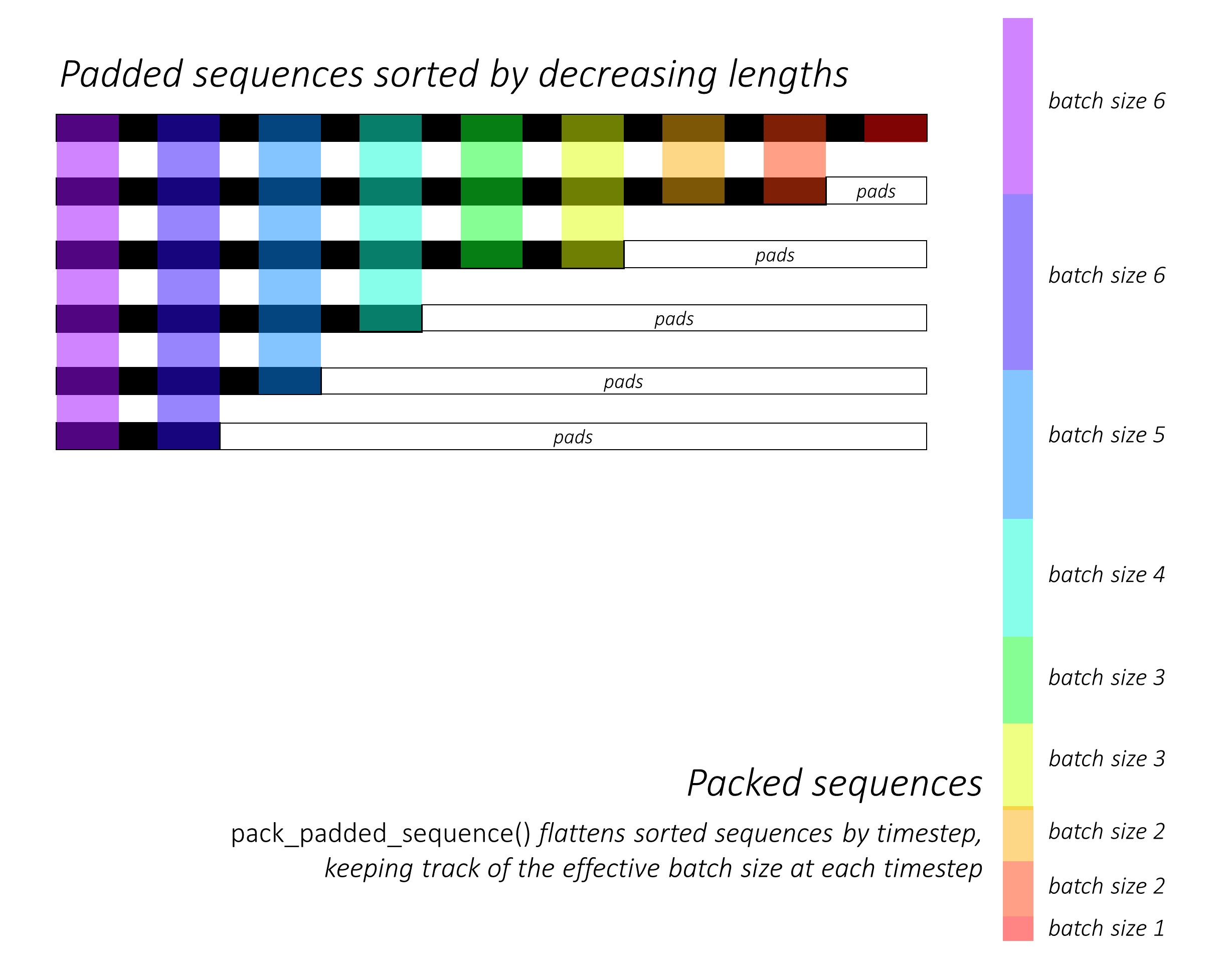
Nota : esta función se usa en realidad para realizar el mismo lote dinámico (es decir, procesar solo el tamaño de lote efectivo en cada paso de tiempo) que realizamos en nuestro decodificador, cuando usamos un RNN o LSTM en Pytorch. En este caso, Pytorch maneja los gráficos dinámicos de longitud variable internamente. Puede ver un ejemplo en dynamic_rnn.py en mi otro tutorial sobre etiquetado de secuencia. Hubiéramos utilizado esta función junto con un LSTM en nuestro decodificador si no estuviéramos iterando manualmente debido a la red de atención.
Para evaluar el rendimiento del modelo en el conjunto de validación, utilizaremos la métrica de evaluación de evaluación bilingüe automatizada (BLEU). Esto evalúa un subtítulo generado contra los subtítulos de referencia. Para cada título generado, utilizaremos todos los subtítulos N_c disponibles para esa imagen como subtítulos de referencia.
Los autores del programa, asisten y dicen que el papel observa que la correlación entre la pérdida y la puntuación de BLU se descomponen después de un punto, por lo que recomiendan dejar de entrenar desde el principio cuando la puntuación BLU comienza a degradarse, incluso si la pérdida continúa disminuyendo.
Utilicé la herramienta Bleu disponible en el módulo NLTK.
Tenga en cuenta que hay una considerable crítica de la puntuación BLU porque no siempre se correlaciona bien con el juicio humano. Los autores también informan los puntajes de meteoros por este motivo, pero no he implementado esta métrica.
Te recomiendo entrenar en etapas.
Primero entrené solo al decodificador, es decir, sin ajustar el codificador, con un tamaño de lote de 80 . Entrené para 20 épocas, y la puntuación BLUU-4 alcanzó su punto máximo en aproximadamente 23.25 en la 13ª época. Usé el optimizador Adam() con una tasa de aprendizaje inicial de 4e-4 .
Continué desde el 13º punto de control de la época permitiendo el ajuste fino del codificador con un tamaño de lote de 32 . El tamaño de lote más pequeño se debe a que el modelo ahora es más grande porque contiene los gradientes del codificador. Con el ajuste fino, el puntaje aumentó a 24.29 en solo 3 épocas. El entrenamiento continuo probablemente habría empujado el puntaje un poco más alto, pero tuve que cometer mi GPU en otro lugar.
Una distinción importante para hacer aquí es que todavía estoy suministrando la verdad en tierra como la entrada en cada paso de decodificación durante la validación, independientemente de la palabra última generada . Esto se llama Foring de Maestro . Si bien esto se usa comúnmente durante el entrenamiento para acelerar el proceso, como lo estamos haciendo, las condiciones durante la validación deben imitar las condiciones de inferencia real tanto como sea posible. Todavía no he implementado una inferencia por lotes, donde cada palabra en el título se genera a partir de la palabra generada anteriormente, y termina al tocar el token <end> .
Como estoy forzado por el maestro durante la validación, la puntuación BLUU medida anteriormente en los subtítulos resultantes no refleja un rendimiento real. De hecho, la puntuación BLUU es una métrica diseñada para comparar los subtítulos generados con subtítulos de verdad en tierra de diferente longitud. Una vez que se implementa la inferencia por lotes, es decir, ningún forzador de maestros, parecer temprano con la puntuación BLEU será realmente "apropiado".
Con esto en mente, utilicé eval.py para calcular las puntuaciones BLEU-4 correctas de este punto de control del modelo en los conjuntos de validación y prueba sin forzar al maestro, a diferentes tamaños de haz,
| Tamaño del haz | Validación bleu-4 | Prueba bleu-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
La puntuación de prueba es más alta que el resultado en el documento, y podría deberse a cómo se parametrizan nuestras calculadoras de Bleu, el hecho de que utilicé un codificador Resnet y, en realidad, afiné el codificador, incluso si solo un poco.
Además, recuerde: al ajustar el aprendizaje de la transferencia, siempre es mejor usar una tasa de aprendizaje considerablemente más pequeña de lo que se usó originalmente para entrenar el modelo prestado. Esto se debe a que el modelo ya está bastante optimizado, y no queremos cambiar nada demasiado rápido. También usé Adam() para el codificador, pero con una tasa de aprendizaje de 1e-4 , que es una décima parte del valor predeterminado para este optimizador.
En un Titan X (Pascal), tomó 55 minutos por época sin ajustar, y 2.5 horas con ajuste fino en los tamaños de lotes establecidos.
Puede descargar este modelo previo a la petróleo y el word_map correspondiente aquí.
Tenga en cuenta que este punto de control debe cargarse directamente con Pytorch, o pasar a caption.py : ver a continuación.
Ver caption.py .
Durante la inferencia, no podemos usar directamente el método forward() en el decodificador porque utiliza el forzamiento de maestros. Más bien, en realidad tendríamos que alimentar la palabra generada previamente a la LSTM en cada paso de tiempo .
caption_image_beam_search() lee una imagen, la codifica y aplica las capas en el decodificador en el orden correcto, mientras se usa la palabra generada previamente como la entrada al LSTM en cada paso de tiempo. También incorpora la búsqueda del haz.
visualize_att() se puede usar para visualizar el título generado junto con los pesos en cada paso de tiempo como se ve en los ejemplos.
Para subtitular una imagen desde la línea de comando, apunte a la imagen, el punto de control del modelo, el mapa de palabras (y opcionalmente, el tamaño del haz) de la siguiente manera.
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
Alternativamente, use las funciones en el archivo según sea necesario.
Consulte también eval.py , que implementa este proceso para calcular la puntuación BLU en el conjunto de validación, con o sin búsqueda de haz.





La prueba Turing Tommy : sabes que la IA no es realmente AI porque no ha visto la habitación y no reconoce la grandeza cuando lo ve.

Dijiste una suave atención. ¿Hay, um, una atención dura ?
Sí, el programa de asistencia, asistencia y digitación usa ambas variantes, y el decodificador con atención "dura" funciona marginalmente mejor.
En una atención suave , que usamos aquí, está calculando los pesos alpha y utilizando el promedio ponderado de las características en todos los píxeles. Esta es una operación determinista y diferenciable.
En dura atención, está eligiendo probar algunos píxeles de una distribución definida por alpha . Tenga en cuenta que cualquier muestreo probabilístico no es determinista o estocástico , es decir, una entrada específica no siempre producirá la misma salida. Pero dado que el descenso de gradiente presupone que la red es determinista (y, por lo tanto, diferenciable), el muestreo se reelabora para eliminar su estocasticidad. Mi conocimiento de esto es bastante superficial en este momento: actualizaré esta respuesta cuando tenga una comprensión más detallada.
¿Cómo uso una red de atención para una tarea NLP como un modelo de secuencia a secuencia?
Al igual que usa un CNN para generar una codificación con características en cada píxel, usaría un RNN para generar características codificadas en cada posición de palabra de tiempo, es decir, en la entrada.
Sin atención, usaría la salida del codificador en el último tiempo de tiempo como la codificación para toda la oración, ya que también contendría información de times de tiempo anteriores. La última salida del codificador ahora tiene la carga de tener que codificar la oración completa de manera significativa, lo que no es fácil, especialmente para oraciones más largas.
Con la atención, asistiría sobre los times en la salida del codificador, generando pesos para cada paso de tiempo/palabra, y tomaría el promedio ponderado para representar la oración. En una tarea de secuencia a secuencia, como la traducción automática, atenderá las palabras relevantes en la entrada a medida que genere cada palabra en la salida.
También podría usar la atención sin un decodificador. Por ejemplo, si desea clasificar el texto, puede atender las palabras importantes en la entrada solo una vez para realizar la clasificación.
¿Podemos usar la búsqueda de haz durante el entrenamiento?
No con la función de pérdida actual, pero sí. Esto no es común en absoluto.
¿Qué es el forzador del maestro?
El forzamiento del maestro es cuando usamos los subtítulos de la verdad de tierra como la entrada al decodificador en cada paso de tiempo, y no la palabra que generó en el tiempo de tiempo anterior. Es común a la fuerza del maestro durante la capacitación, ya que podría significar una convergencia más rápida del modelo. Pero también puede aprender a depender de que le digan la respuesta correcta y exhibir cierta inestabilidad en la práctica.
Sería ideal entrenar con el uso de maestros solo algunas veces, según una probabilidad. Esto se llama muestreo programado.
(Planeo agregar la opción).
¿Puedo usar incrustaciones de palabras previas a la aparición (guante, cbow, skipgram, etc.) en lugar de aprenderlos desde cero?
Sí, podría, con el método load_pretrained_embeddings() en la clase Decoder . También puede optar por ajustar (o no) con el método fine_tune_embeddings() .
Después de crear el decodificador en train.py , debe proporcionar los vectores previos a la aparición a load_pretrained_embeddings() apilados en el mismo orden que en word_map . Para las palabras para las que no tiene vectores previos a los vectores previos, como <start> , puede inicializar las incrustaciones al azar como lo hicimos en init_weights() . Recomiendo ajustar a los vectores más significativos para estos vectores inicializados al azar.
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False También asegúrese de cambiar el parámetro emb_dim desde su valor actual de 512 al tamaño de sus incrustaciones previamente capacitadas. Esto debería ajustar automáticamente el tamaño de entrada del decodificador LSTM para acomodarlos.
¿Cómo llevo un seguimiento de los tensores que permiten calcular los gradientes?
Con la liberación de Pytorch 0.4 , ya no se requiere tensores de envoltura como Variable S. En cambio, los tensores tienen el atributo requires_grad , que decide si autograd rastrea y, por lo tanto, si los gradientes se calculan durante el retroceso.
requires_grad establecerá en False .requires_grad se establecerá en True .torch.nn ya tendrán requires_grad establecidas en True .¿Cómo calculo todos los puntajes Bleu (es decir, Bleu-1 a Bleu-4) durante la evaluación?
Debería modificar el código en eval.py para hacer esto. Consulte esta excelente respuesta de KMario23 para obtener una explicación clara y detallada.


