a PyTorch Tutorial to Image Captioning
1.0.0
これは、キャプションを画像化するためのPytorchチュートリアルです。
これは、驚くべきPytorchライブラリで自分でクールなモデルを実装することについて書いている一連のチュートリアルの最初のものです。
Pytorch、畳み込みおよび再発性ニューラルネットワークの基本的な知識が想定されています。
Pytorchを初めて使用する場合は、最初にPytorchを使用して深い学習を読んでください。
質問、提案、または修正は問題として投稿できます。
Python 3.6でPyTorch 0.4使用しています。
2020年1月27日:2つの新しいチュートリアルの作業コードが追加されました - 超解像度と機械翻訳
客観的
概念
概要
実装
トレーニング
推論
よくある質問
画像の説明的なキャプションを生成できるモデルを構築するには、それを提供します。
物事をシンプルに保つために、ショーを実装し、出席し、紙を伝えましょう。これは決して現在の最先端ではありませんが、それでもかなり驚くべきことです。著者の元の実装はここにあります。
このモデルは、どこを見るかを学びます。
ワードごとにキャプションを作成すると、モデルの視線が画像全体に移動するのがわかります。
これは、その注意メカニズムのために可能です。これにより、次に発言する言葉に最も関連する画像の部分に焦点を合わせることができます。
トレーニングや検証中に見られないテスト画像で生成されたキャプションを次に示します。




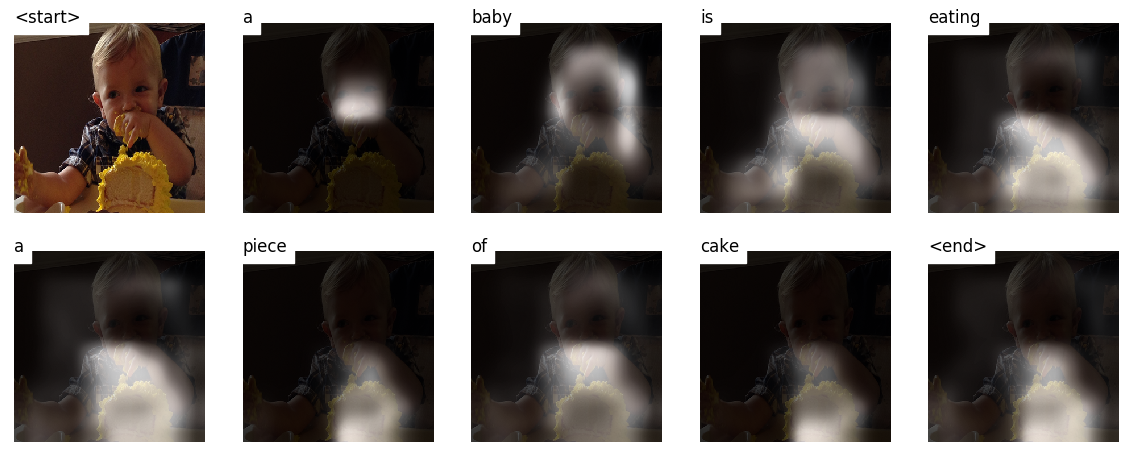

チュートリアルの最後には、その他の例があります。
画像キャプション。ああ。
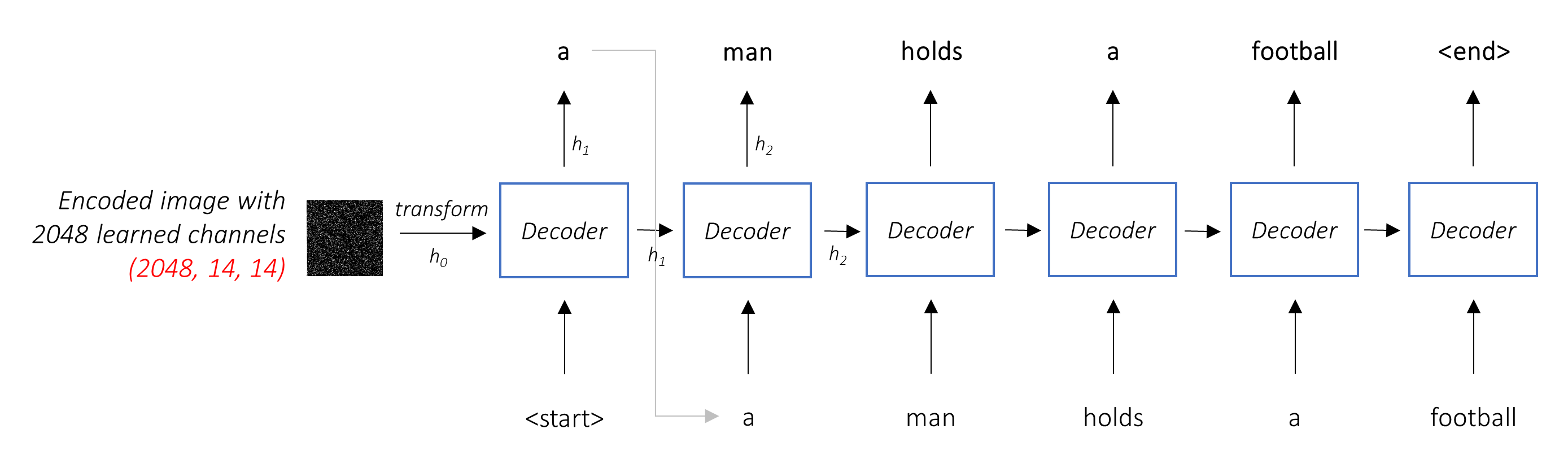
エンコーダデコダーアーキテクチャ。通常、シーケンスを生成するモデルは、エンコーダーを使用して入力を固定フォームにエンコードし、デコーダーを単語ごとにデコードしてシーケンスにデコードします。
注意。注意ネットワークの使用は、深い学習に普及しており、正当な理由があります。これは、モデルが手元のタスクに関連していると考えるエンコードの部分のみを選択する方法です。ここで採用されているのと同じメカニズムは、エンコーダの出力が空間または時間に複数のポイントを持っている任意のモデルで使用できます。画像キャプションでは、他のピクセルよりもいくつかのピクセルが重要であると考えています。機械翻訳のようなシーケンスタスクからシーケンスのタスクでは、他の単語よりも重要な単語を考慮します。
転送学習。これは、新しいモデルの一部を新しいモデルで使用して既存のモデルから借りるときです。これは、新しいモデルをゼロからトレーニングするよりも、ほとんど常に優れています(つまり、何も知らない)。ご覧のとおり、この中古の知識をいつでも手元の特定のタスクに微調整できます。前処理された単語の埋め込みを使用することは、馬鹿げたが有効な例です。画像のキャプションの問題については、事前に処理されたエンコーダーを使用し、必要に応じて微調整します。
ビーム検索。これは、デコーダーを怠zyにさせず、各デコードステップで最高のスコアを持つ単語を選択するだけです。ビーム検索は、最も最適なシーケンスを見つけるため、あらゆる言語モデリングの問題に役立ちます。
このセクションでは、このモデルの概要を説明します。すでに慣れ親しんでいる場合は、実装セクションまたはコメントコードに直接スキップできます。
エンコーダは、3つのカラーチャネルで入力画像を「学習」チャネルを備えた小さな画像にエンコードします。
この小さなエンコードされた画像は、元の画像で役立つすべての要約表現です。
画像をエンコードしたいので、畳み込みニューラルネットワーク(CNNS)を使用します。
エンコーダーをゼロからトレーニングする必要はありません。なぜ?画像を表すために訓練されているCNNSがすでにあるためです。
何年もの間、人々は画像を千のカテゴリのいずれかに分類するのに非常に優れたモデルを構築してきました。これらのモデルが画像の本質を非常によくキャプチャするのは理にかなっています。
Pytorchで既に利用可能なImagenet分類タスクでトレーニングされた101階建ての残差ネットワークを使用することを選択しました。前述のように、これは転送学習の例です。パフォーマンスを改善するために微調整するオプションがあります。

これらのモデルは、元の画像の小さくて小さな表現を徐々に作成し、その後の各表現はより多くのチャネルを備えて「学習」されています。 ResNet-101エンコーダーによって生成される最終エンコーディングのサイズは、2048チャネル、つまり2048, 14, 14サイズのテンソルを備えた14x14です。
他の事前に訓練されたアーキテクチャを試すことをお勧めします。このペーパーでは、vggnetを使用しています。これもImagenetで前提としていますが、微調整はありません。いずれにせよ、変更が必要です。これらのモデルの最後のレイヤーまたは2つのモデルは、分類のためのSoftMaxの活性化と組み合わせた線形層であるため、それらを取り除きます。
デコーダーの仕事は、エンコードされた画像を見て、単語ごとにキャプションを生成することです。
シーケンスを生成しているため、再発性ニューラルネットワーク(RNN)である必要があります。 LSTMを使用します。
注意を払わない典型的な設定では、すべてのピクセルでエンコードされた画像を平均化できます。次に、線形変換の有無にかかわらず、最初の隠された状態としてデコーダーにこれを与え、キャプションを生成できます。予測された各単語は、次の単語を生成するために使用されます。
注意を払った設定では、デコーダーがシーケンスのさまざまなポイントで画像のさまざまな部分を見ることができるようにしたいと考えています。たとえば、 a man holds a footballのfootball言葉を生み出している間、デコーダーはサッカーに焦点を合わせることを知っています - サッカー!
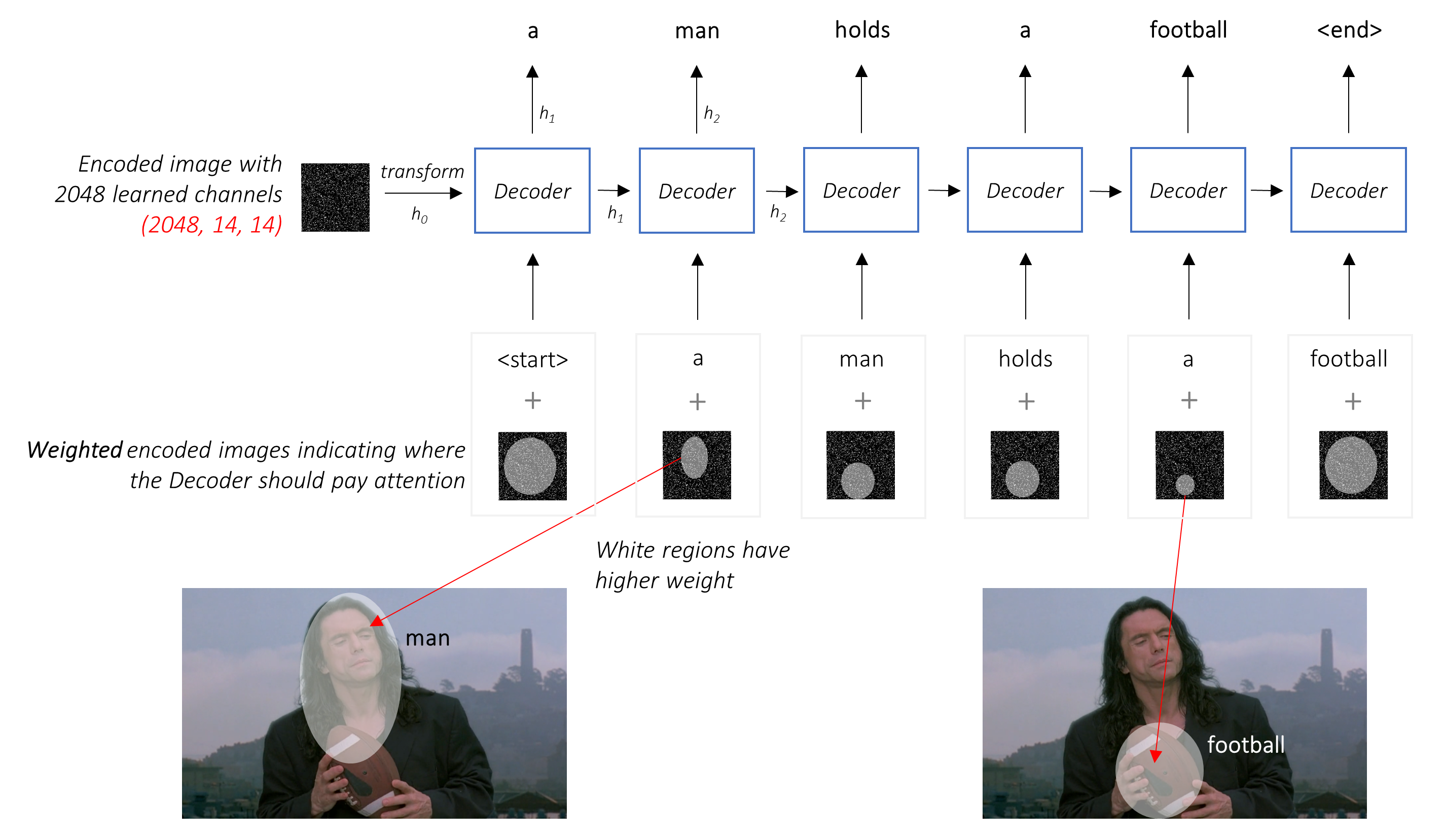
単純な平均の代わりに、すべてのピクセルにわたって加重平均を使用し、重要なピクセルの重みが大きくなります。画像のこの加重表現は、各ステップで以前に生成された単語と連結して、次の単語を生成できます。
注意ネットワークはこれらの重みを計算します。
直感的に、画像の特定の部分の重要性をどのように推定しますか?これまでに生成したシーケンスに注意する必要があるため、画像を見て、次に説明する必要性を決定できます。たとえば、 a manに言及した後、彼がholding a footballことを宣言することは論理的です。
これはまさに注意メカニズムが行うことです。これまでに生成されたシーケンスを考慮し、次に説明する必要がある画像の一部に注意します。
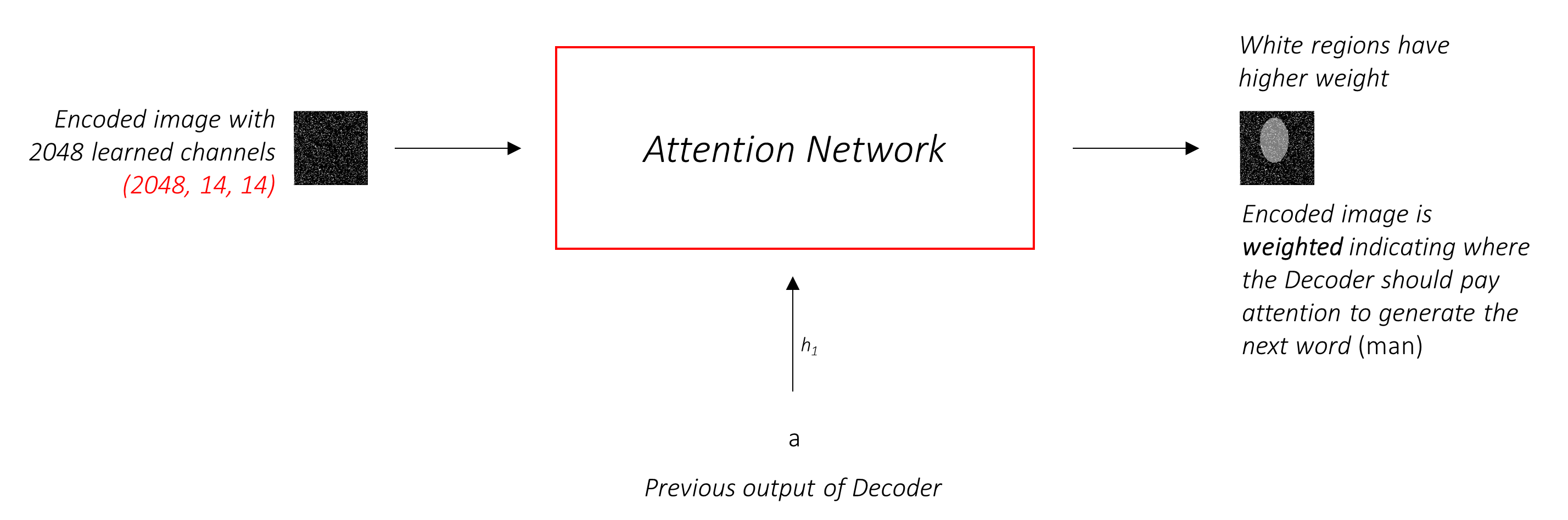
ピクセルの重みが1になるのは、ソフトな注意を使用します。エンコードされた画像にPピクセルがある場合、各タイムステップt - で
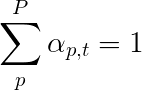
このプロセス全体を、ピクセルが次の単語を生成する場所であるという確率を計算するものとして解釈できます。
私たちの結合されたネットワークがどのように見えるかは今では明らかです。
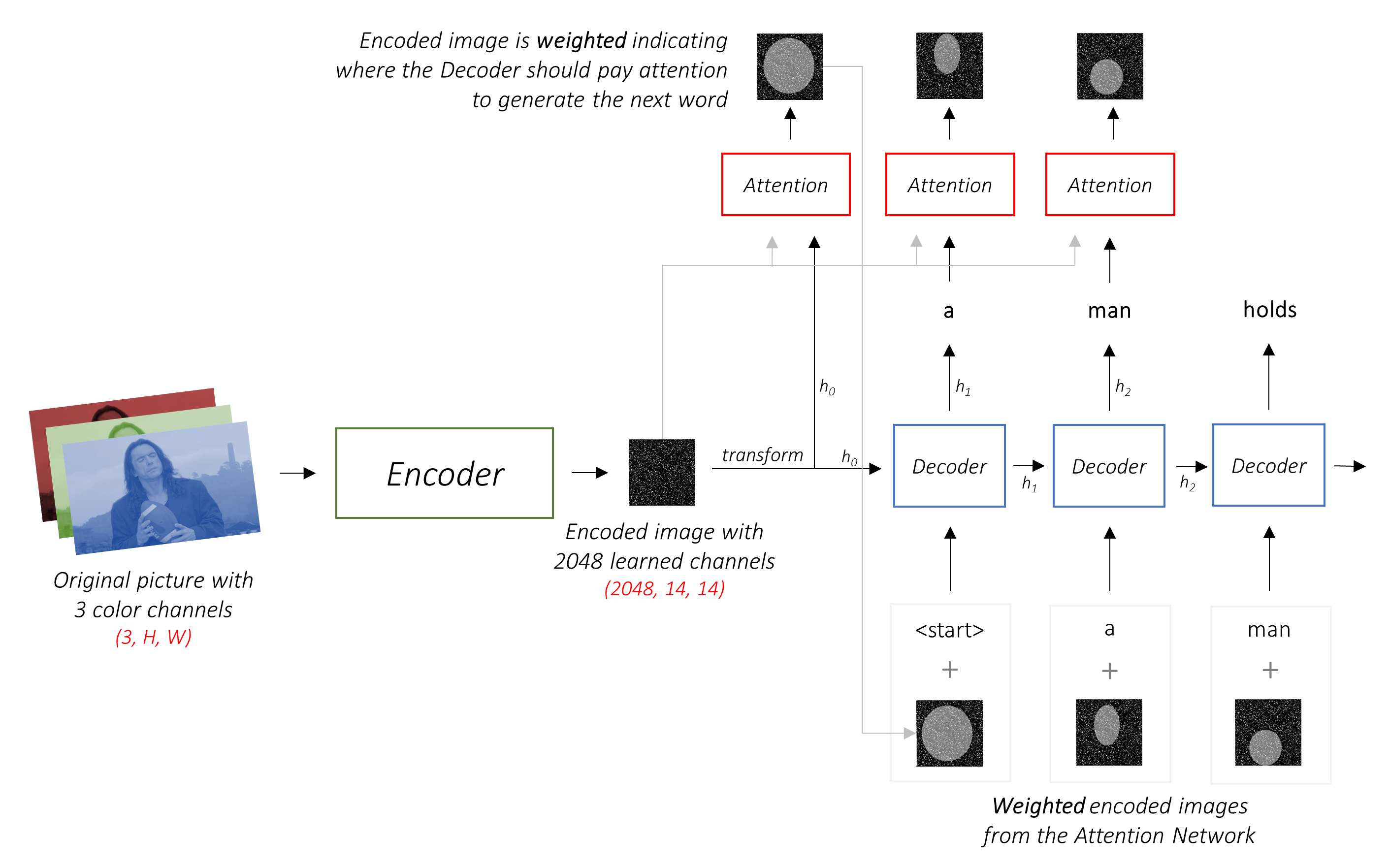
h (およびセル状態C )を作成します。線形層を使用して、デコーダーの出力を語彙の各単語のスコアに変換します。
簡単な、そして貪欲な - オプションは、最高スコアの単語を選択し、それを使用して次の単語を予測することです。しかし、これは最適ではありません。これは、シーケンスの残りの部分が最初に選択した単語にかかっているためです。その選択が最高でない場合、続くすべてが最適です。そして、それは最初の単語だけではありません。シーケンス内の各単語は、それを引き継ぐものに結果をもたらします。
その最初のステップで3番目の最高の単語を選択し、2番目のステップで2番目に最高の単語など、それが生成できる最高のシーケンスになると非常によく起こるかもしれません。
完全にデコードが完了し、候補シーケンスのバスケットから最高の総合スコアを持つシーケンスを選択するまで、どういうわけか決定できない場合が最善です。
ビーム検索はまさにこれを行います。
k候補を検討してください。k最初の単語のそれぞれに対してk 2番目の単語を生成します。k [最初の単語、2番目の単語]の組み合わせを選択します。k 2番目の単語のそれぞれについて、 k 3番目の単語を選択し、トップk [最初の単語、2番目の単語、3番目の単語]の組み合わせを選択します。kシーケンスが終了したら、最高の総合スコアでシーケンスを選択します。 
ご覧のとおり、いくつかのシーケンス(ストリックアウト)は、次のステップでトップkに到達しないため、早期に失敗する可能性があります。 kシーケンス(下線付き)が<end>トークンを生成すると、最高スコアのあるシーケンスを選択します。
以下のセクションでは、実装について簡単に説明します。
それらはいくつかのコンテキストを提供することを目的としていますが、詳細はコードから直接理解されるのが最もよくありますが、これは非常に重くコメントされています。
MSCOCO '14データセットを使用しています。トレーニング(13GB)と検証(6GB)画像をダウンロードする必要があります。
Andrej Karpathyのトレーニング、検証、およびテストスプリットを使用します。このzipファイルにはキャプションが含まれています。また、Flicker8KおよびFlicker30Kデータセットの分割とキャプションが見つかりますので、コンピューターには後者が大きすぎる場合は、MSCOCOの代わりにこれらを使用してください。
3つの入力が必要です。
前処理されたエンコーダーを使用しているため、この前処理されたエンコーダーが慣れている形式に画像を処理する必要があります。
Pytorchのtorchvisionモジュールの一部として利用可能な事前に保護されたImagenetモデル。このページは、実行する必要がある前処理または変換の詳細を示します。ピクセル値は範囲[0,1]にある必要があり、イメージネット画像のRGBチャネルの平均と標準偏差によって画像を正規化する必要があります。
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]また、PytorchはNCHW条約に従います。つまり、チャネル寸法(c)がサイズの寸法に先行する必要があります。
すべてのMSCOCO画像を256x256にサイズ変更して、均一にします。
したがって、モデルに供給された画像は、寸法N, 3, 256, 256のFloatテンソルでなければならず、前述の平均および標準偏差によって正規化する必要があります。 Nはバッチサイズです。
各単語を使用して次の単語を生成するため、キャプションはデコーダーのターゲットと入力の両方です。
ただし、最初の単語を生成するには、 Zeroth Word、 <start>が必要です。
最後の単語では、 <end>デコーダーがキャプションの終了を予測することを学習する必要があると予測する必要があります。これは、推論中にデコードをいつ停止するかを知る必要があるため、必要です。
<start> a man holds a football <end>
固定サイズのテンソルとしてキャプションを渡すため、 <pad>トークンを使用してキャプション(自然にさまざまな長さの長さ)を同じ長さにパッドする必要があります。
<start> a man holds a football <end> <pad> <pad> <pad>....
さらに、 <start> 、 <end> 、 <pad>トークンなど、コーパス内の各単語のインデックスマッピングであるword_mapを作成します。 Pytorchは、他のライブラリと同様に、インデックスとしてエンコードされた単語を必要とし、それらの埋め込みを検索したり、予測された単語スコアでその場所を特定したりします。
9876 1 5 120 1 5406 9877 9878 9878 9878....
したがって、モデルに供給されたキャプションは、寸法N, LのIntテンソルでなければなりません。ここで、 Lはパッド入りの長さです。
キャプションはパッドであるため、各キャプションの長さを追跡する必要があります。これは実際の長さ + 2です( <start>および<end>トークンの場合)。
キャプションの長さも重要です。これは、Pytorchで動的なグラフを構築できるためです。その長さまでのシーケンスのみを処理し、 <pad> sで計算を無駄にしないでください。
したがって、モデルに供給されたキャプションの長さは、寸法NのIntでなければなりません。
utils.pyのcreate_input_files()を参照してください。
これにより、ダウンロードされたデータが読み取られ、次のファイルが保存されます。
I, 3, 256, 256テンソルの各分割の画像を含むHDF5ファイル。 I分割の画像の数です。ピクセル値はまだ範囲[0、255]であり、符号なしの8ビットIntとして保存されます。N_c * Iエンコードされたキャプションのリストを使用した各分割のJSONファイル。N_C N_c画像ごとにサンプリングされたキャプションの数です。これらのキャプションは、HDF5ファイルの画像と同じ順序です。したがって、 i THキャプションはi // N_c th画像に対応します。N_c * Iキャプション長のリストを使用して、各分割のJSONファイル。 i Th値は、 i THキャプションの長さであり、 i // N_c th画像に対応します。word_map 、Word-to-Index辞書を含むJSONファイル。これらのファイルを保存する前に、しきい値よりも短いキャプションのみを使用するオプションがあり、 <unk>に頻度の低い単語を使用するオプションがあります。
トレーニング /検証中にディスクから直接読み取るため、画像にHDF5ファイルを使用します。それらは、一度にラムに収まるには大きすぎます。しかし、すべてのキャプションとその長さをメモリにロードします。
datasets.pyのCaptionDataset参照してください。
これは、Pytorch Datasetのサブクラスです。データセットのサイズを返す__len__メソッドと、 i番目の画像、キャプション、およびキャプションの長さを返す__getitem__メソッドが必要です。
ディスクから画像を読み、ピクセルを[0,255]に変換し、このクラス内でそれらを正規化します。
Dataset 、 train.pyのPytorch DataLoaderによって使用され、トレーニングまたは検証のためにモデルにデータのバッチを作成およびフィードします。
models.pyのEncoderを参照してください。
Pytorchのtorchvisionモジュールですでに入手可能な前提条件のResNet-101を使用しています。画像をエンコードするだけで分類されないため、最後の2つの層(プーリングと線形層)を廃棄します。
AdaptiveAvgPool2d()レイヤーを追加して、エンコードを固定サイズにサイズ変更します。これにより、可変サイズの画像をエンコーダーにフィードすることができます。 (ただし、入力画像を1つのテンソルとして一緒に保存する必要があったため、入力画像を256, 256にサイズ変更しました。)
エンコーダーを微調整する可能性があるため、エンコーダのパラメーターの勾配の計算を有効または無効にするfine_tune()メソッドを追加します。最初の畳み込みブロックは、通常、ライン、エッジ、曲線などの検出など、画像処理の非常に基本的なことを学んだため、折り畳み式の畳み込みブロック2から4のみを微調整します。
models.pyのAttentionを参照してください。
注意ネットワークはシンプルです。線形層といくつかのアクティベーションのみで構成されています。
個別の線形層は、エンコードされた画像( N, 14 * 14, 2048にフラット化された)と隠された状態(出力)の両方をデコーダーから同じ寸法に変換します。注意サイズ。その後、それらを追加し、reluアクティブ化されます。 3番目の線形層は、この結果を1の寸法に変換し、その結果、ソフトマックスを適用して重みのalphaを生成します。
models.pyのDecoderWithAttention参照してください。
エンコーダーの出力はここで受信され、寸法N, 14 * 14, 2048にフラット化されます。これは便利であり、テンソルを複数回再構築することを防ぎます。
2つの別々の線形層を使用するinit_hidden_state()メソッドを使用して、エンコードされた画像を使用してLSTMの非表示とセルの状態を初期化します。
まさに最初に、キャプションの長さを減らすことにより、 N画像とキャプションを並べ替えます。これは、有効なタイムステップのみを処理できるように、つまり<pad> sを処理できないようにします。
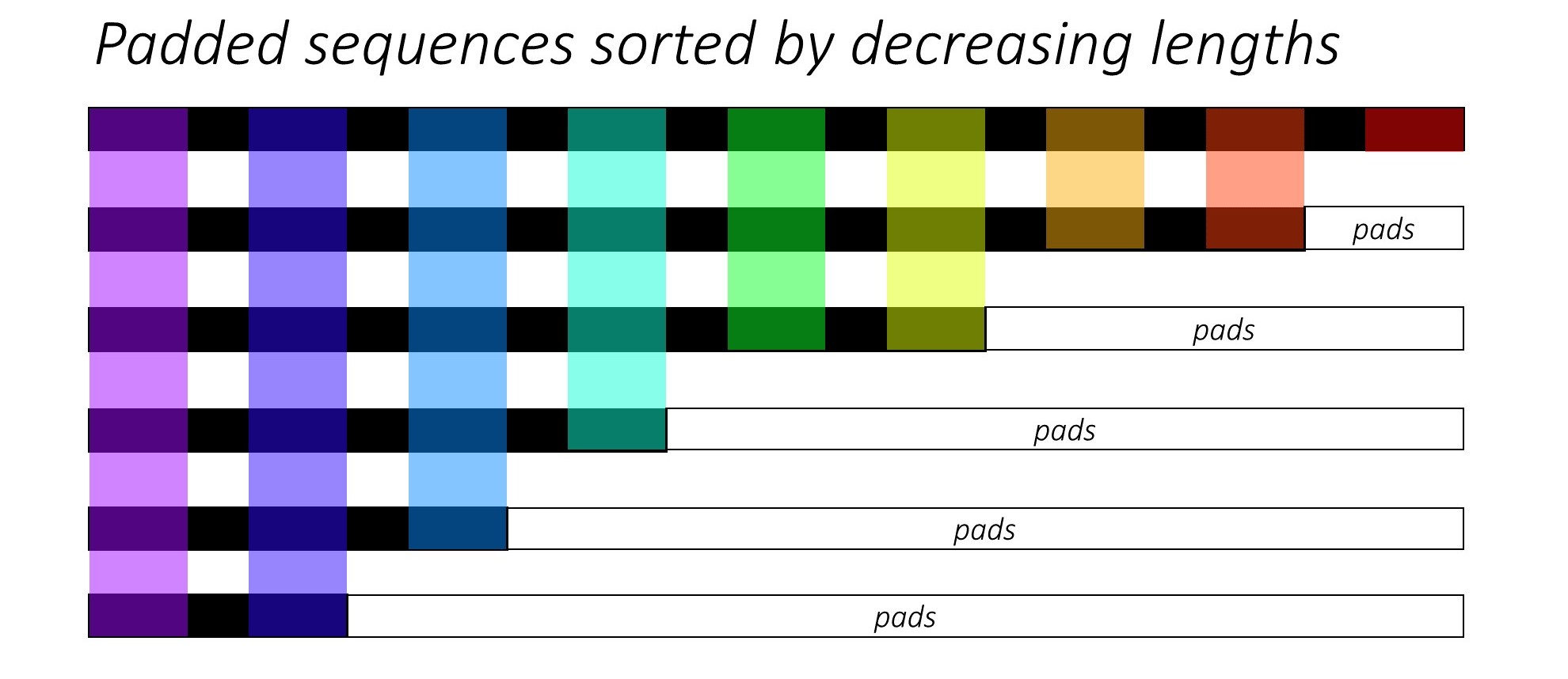
各タイムステップを反復し、そのタイムステップで有効なバッチサイズN_tである色の領域のみを処理できます。ソートにより、任意のタイムステップのトップN_t前のステップからの出力に合わせることができます。たとえば、3番目のTimestepでは、前のステップの上位5つの出力を使用して、上位5つの画像のみを処理します。
この反復は、Pytorch LSTMCellを使用してループなしで自動的に反復するのではなく、Pytorch LSTMを使用してforで手動で実行されます。これは、各デコードステップ間で注意メカニズムを実行する必要があるためです。 LSTMCellは単一のタイムステップ操作ですが、 LSTM複数のタイムステップを継続的に繰り返し、すべての出力を一度に提供します。
注意ネットワークを使用して、各タイムステップでの重みと注意加重エンコードを計算します。論文のセクション4.2.1では、フィルターまたはゲートを通って注意加重エンコードを渡すことをお勧めします。このゲートは、デコーダーの以前の隠された状態のシグモイド活性化線形変換です。著者らは、これが注意ネットワークが画像内のオブジェクトをより重視するのに役立つと述べています。
前の単語の埋め込み( <start>を開始する)でこのフィルタリングされた注意加重エンコードを連結し、 LSTMCellを実行して新しい非表示状態(または出力)を生成します。線形層は、この新しい隠された状態を、ボキャブラリーの各単語のスコアに変換します。
また、各タイムステップに注意ネットワークによって返されたウェイトを保存します。あなたはすぐになぜ十分な理由がわかります。
開始する前に、トレーニング、検証、テストに必要なデータファイルを保存してください。これを行うには、ダウンロードしたデータから抽出されたtrain2014およびval2014フォルダーを含むKarpathy JSONファイルと画像フォルダーを指した後、 create_input_files.pyの内容を実行します。
train.pyを参照してください。
モデルのパラメーター(およびトレーニング)はファイルの先頭にあるため、必要に応じて簡単に確認または変更できます。
モデルをゼロからトレーニングするには、このファイルを実行するだけです。
python train.py
チェックポイントでトレーニングを再開するには、コードの先頭にcheckpointパラメーターを使用して対応するファイルを指します。
すべてのトレーニングエポックの終わりに検証を実行することに注意してください。
単語のシーケンスを生成しているため、 CrossEntropyLossを使用しています。デコーダーの最終層から生のスコアを送信するだけで、損失関数はSoftMaxおよびログ操作を実行します。
論文の著者は、2回目の損失、つまり「二重に確率的な正則化」を使用することを推奨しています。指定されたタイムステップでの重みの合計が1にあることがわかります。ただし、単一のピクセルpの重みをすべてのタイムステップT - にわたって合計することをお勧めします。
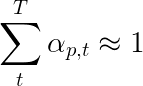
これは、シーケンス全体を生成する過程で、モデルがすべてのピクセルに参加することを望んでいます。したがって、すべてのタイムステップにわたるピクセルの重みの合計の差を最小限に抑えようとします。
パッド入りの領域で損失を計算しません。パッドを取り除く簡単な方法は、pytorchのpack_padded_sequence()を使用することです。これは、パッド付き領域を無視しながらTimestepでテンソルを平らに平らにします。これで、この平らなテンソル上の損失を集約できます。
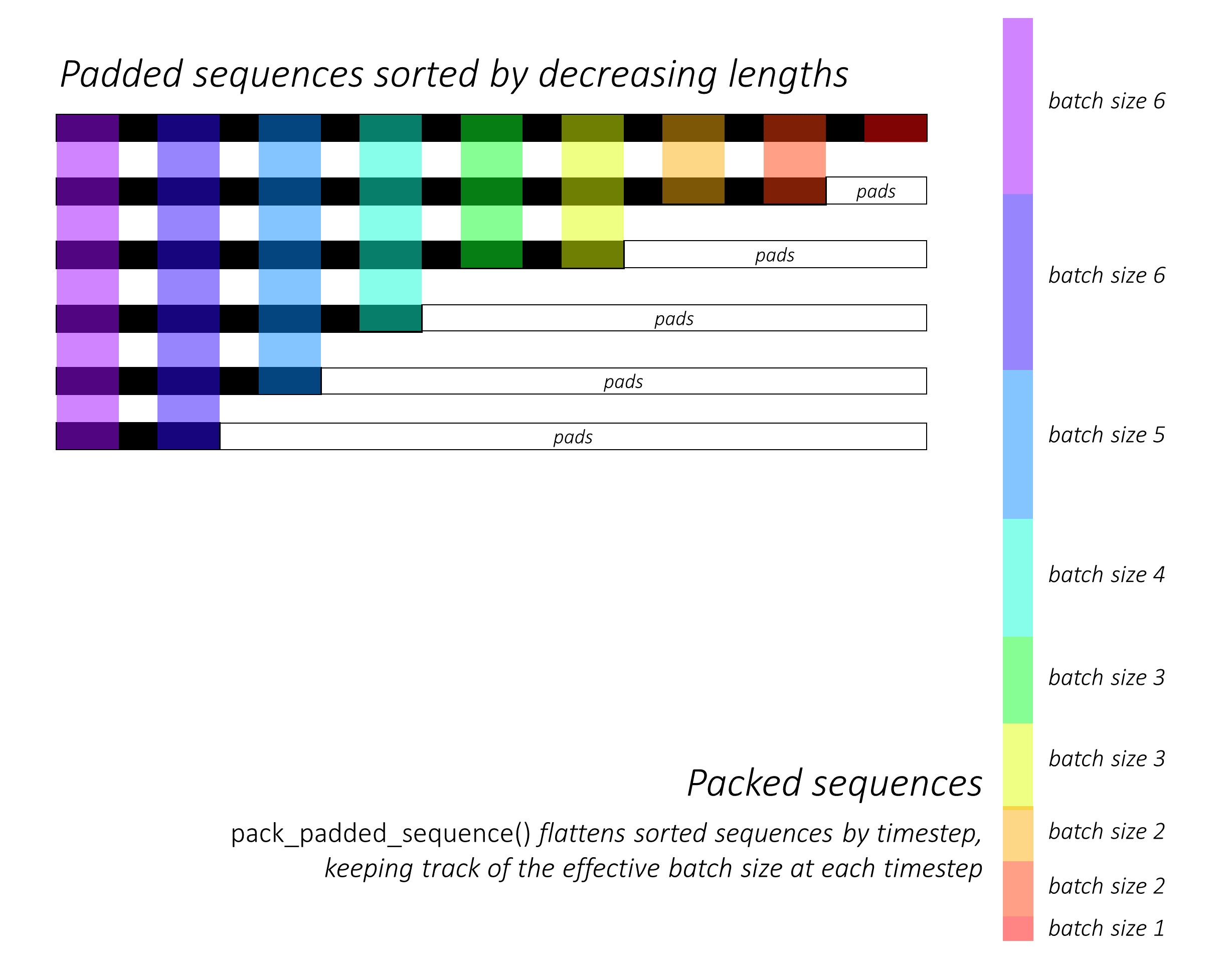
注- この関数RNN 、実際には同じ動的バッチ(つまり、各タイムステップで有効なバッチサイズのみを処理する) LSTM実行するために使用されます。この場合、Pytorchは動的変数長のグラフを内部で処理します。シーケンスラベル付けに関する他のチュートリアルでは、 dynamic_rnn.pyの例を見ることができます。注意ネットワークのために手動で反復していない場合、デコーダーのLSTMとともにこの機能を使用していました。
検証セットでのモデルのパフォーマンスを評価するために、自動化されたバイリンガル評価アンテグ(BLE)評価メトリックを使用します。これにより、参照キャプションに対する生成されたキャプションが評価されます。生成された各キャプションについて、その画像で使用可能なすべてのN_cキャプションを参照キャプションとして使用します。
ショーの著者、出席、そして伝える論文は、損失とBLEUスコアの間の相関がポイントの後に崩壊することを観察しているため、損失が減少し続けていても、ブルースコアが劣化し始めたときに早期にトレーニングを停止することをお勧めします。
NLTKモジュールで利用可能なBLEUツールを使用しました。
BLEUスコアに対してかなりの批判があることに注意してください。なぜなら、それは常に人間の判断とよく相関するとは限らないからです。著者は、この理由で流星スコアも報告していますが、このメトリックを実装していません。
段階的にトレーニングすることをお勧めします。
最初にデコーダーのみをトレーニングしました。つまり、エンコーダーを微調整せずに80のバッチサイズで微調整しました。私は20エポックのために訓練しましたが、Bleu-4スコアは13番目のエポックで約23.25でピークに達しました。 4e-4の初期学習率でAdam()オプティマイザーを使用しました。
13番目のエポックチェックポイントから続けて、バッチサイズが32のエンコーダーを微調整できるようにしました。バッチサイズが小さくなるのは、エンコーダーの勾配が含まれているため、モデルが大きくなったためです。微調整により、スコアはわずか3エポックで24.29に上昇しました。継続的なトレーニングは、おそらくスコアをわずかに高く押し上げたでしょうが、他の場所でGPUをコミットしなければなりませんでした。
ここで重要な区別は、最後に生成された単語に関係なく、検証中に各デコードステップでの入力としてグラウンドトゥルースをまだ提供していることです。これは教師の強制と呼ばれます。これはトレーニング中にプロセスを高速化するために一般的に使用されますが、私たちが行っているように、検証中の条件は実際の推論条件を可能な限り模倣する必要があります。バッチ付き推論はまだ実装していません。キャプション内の各単語が以前に生成された単語から生成され、 <end>トークンを押すと終了します。
私は検証中に教師を監視しているため、結果のキャプションで上記で測定されたBLEUスコアは、実際のパフォーマンスを反映していません。実際、BLEUスコアは、自然に生成されたキャプションを異なる長さの地上真実のキャプションと比較するために設計されたメトリックです。バッチされた推論が実装されると、つまり教師が強制することはありません。BLEUスコアを早期に止めることは本当に「適切」になります。
これを念頭に置いて、 eval.pyを使用して、さまざまなビームサイズで教師の強制をせずに、検証とテストセットのこのモデルチェックポイントの正しいBLEU-4スコアを計算しました -
| ビームサイズ | 検証BLE-4 | BLEU-4をテストします |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
テストスコアは、論文の結果よりも高く、BLEU計算機のパラメーター化方法、ResNetエンコーダーを使用し、実際にエンコーダーを微調整したという事実がある可能性があります。
また、転送学習中に微調整する場合、借りたモデルのトレーニングに最初に使用されていたものよりもかなり小さい学習率を使用する方が常に良いことです。これは、モデルがすでに非常に最適化されており、あまり速く変更したくないためです。エンコーダーにもAdam()を使用しましたが、このオプティマイザーのデフォルト値の10分の1である1e-4の学習率を使用しました。
Titan X(Pascal)では、微調整せずにエポックあたり55分かかり、2.5時間かかり、記載されているバッチサイズで微調整しました。
この前提条件のモデルと対応するword_mapこちらからダウンロードできます。
このチェックポイントはPytorchで直接ロードするか、 caption.pyに渡される必要があることに注意してください。以下を参照してください。
caption.pyを参照してください。
推論中は、教師の強制を使用するため、デコーダー内のforward()メソッドを直接使用することはできません。むしろ、実際には、各タイムステップで以前に生成された単語をLSTMにフィードする必要があります。
caption_image_beam_search() 、画像を読み取り、それをエンコードし、デコーダー内のレイヤーを正しい順序で適用し、各タイムステップのLSTMへの入力として以前に生成された単語を使用します。また、ビーム検索も組み込まれています。
visualize_att()使用して、例に見られるように、各タイムステップの重みとともに生成されたキャプションを視覚化できます。
コマンドラインから画像をキャプションするには、画像、モデルチェックポイント、ワードマップ(およびオプションでは、ビームサイズ)を指します - 次のように -
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
または、必要に応じてファイル内の機能を使用します。
また、ビーム検索の有無にかかわらず、検証セットのBLEUスコアを計算するためのこのプロセスを実装するeval.pyも参照してください。





チューリングトミーテスト- AIは本当にAIではないことを知っています。なぜなら、部屋を見ておらず、それが見たときに偉大さを認識していないからです。

あなたはソフトな注意を言った。ええと、難しい注意はありますか?
はい、ショー、出席、テルテルペーパーでは両方のバリアントを使用し、「ハード」の注意を払ったデコーダーはわずかに優れたパフォーマンスを発揮します。
ここで使用するソフトな注意では、Weights alphaを計算し、すべてのピクセルにわたって機能の加重平均を使用しています。これは、決定論的で微分可能な操作です。
厳しい注意を払って、あなたはalphaによって定義された分布からいくつかのピクセルをサンプリングすることを選択しています。このような確率的サンプリングは、非決定的または確率的であることに注意してください。つまり、特定の入力は常に同じ出力を生成するとは限りません。しかし、勾配降下はネットワークが決定論的(したがって微分可能)であることを前提としているため、サンプリングはその確率性を除去するために再加工されます。この時点でこれについての私の知識はかなり表面的です。より詳細な理解があるときに、この答えを更新します。
シーケンスモデルのシーケンスのようなNLPタスクに注意ネットワークを使用するにはどうすればよいですか?
CNNを使用して各ピクセルで機能を使用してエンコードを生成するのと同じように、RNNを使用して、入力の各タイムステップ、つまりワード位置でエンコードされた機能を生成します。
注意なしでは、以前のタイムステップからの情報も含まれるため、文全体のエンコードとして、最後のタイムステップでエンコーダの出力を使用します。エンコーダの最後の出力は、特に長い文の場合、文章全体を有意義にエンコードしなければならないという負担を負っていますが、これは簡単ではありません。
注意を払って、エンコーダの出力のタイムステップに出席し、各タイムステップ/ワードの重みを生成し、重み付けされた平均をとって文を表すことになります。機械翻訳のようなシーケンスタスクのシーケンスでは、出力内の各単語を生成するときに入力の関連する単語に注意します。
また、デコーダーなしで注意を使用することもできます。たとえば、テキストを分類する場合は、入力の重要な単語に1回だけ参加して分類を実行できます。
トレーニング中にビーム検索を使用できますか?
現在の損失関数ではありませんが、はい。これはまったく一般的ではありません。
教師は何を強制しますか?
教師の強制は、前のタイムステップで生成した単語ではなく、各タイムステップのデコーダーへの入力としてグラウンドトゥルースキャプションを使用する場合です。モデルの収束がより速くなることを意味する可能性があるため、トレーニング中に教師が強化することは一般的です。しかし、それはまた、正しい答えを言われることに依存することを学ぶことができ、実際にある程度の不安定性を示すことができます。
確率に基づいて、教師の強制を使用して一部の時間のみを使用して訓練することが理想的です。これは、スケジュールされたサンプリングと呼ばれます。
(オプションを追加する予定です)。
ゼロから学習する代わりに、前処理された単語の埋め込み(グローブ、cbow、スキップグラムなど)を使用できますか?
はい、 Decoderクラスにload_pretrained_embeddings()メソッドを使用できます。またfine_tune_embeddings()メソッドで微調整する(または微調整しない)こともできます。
train.pyでデコーダーを作成した後、 word_mapと同じ順序で積み重ねられたload_pretrained_embeddings()に前処理されたベクトルを提供する必要があります。 <start>のように、前処理されたベクトルを持っていない単語については、 init_weights()のように埋め込みをランダムに初期化できます。これらのランダムに初期化されたベクトルのより意味のあるベクトルを学ぶために、微調整をお勧めします。
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or Falseまた、 emb_dimパラメーターを現在の値512から事前に訓練された埋め込みのサイズに変更してください。これにより、デコーダーLSTMの入力サイズを自動的に調整して、それらを付属させる必要があります。
どのテンソルが勾配を計算できるかを追跡するにはどうすればよいですか?
Pytorch 0.4のリリースでは、 Variable Sとしてテンソルをラッピングする必要はありません。代わりに、テンソルにはrequires_grad属性があります。これは、 autogradで追跡されるかどうかを決定するため、したがってバックプロパゲーション中に勾配が計算されるかどうかを決定します。
requires_gradがFalseに設定されます。requires_gradのはTrueに設定されます。torch.nnレイヤーのパラメーターであるテンソルは、既にrequires_gradセットをTrueに持っています。評価中にすべてのBleu(つまり、BLEU-1からBLEU-4)スコアを計算するにはどうすればよいですか?
これを行うには、 eval.pyでコードを変更する必要があります。明確で詳細な説明については、KMARIO23によるこの優れた回答をご覧ください。


