a PyTorch Tutorial to Image Captioning
1.0.0
Dies ist ein Pytorch -Tutorial für Bildunterschriften .
Dies ist das erste in einer Reihe von Tutorials, die ich über die Implementierung von coolen Modellen mit der erstaunlichen Pytorch -Bibliothek selbst schreibe.
Grundkenntnisse über Pytorch-, Faltungs- und wiederkehrende neuronale Netzwerke werden angenommen.
Wenn Sie neu in Pytorch sind, lesen Sie zuerst Deep Learning mit Pytorch: A 60 -minütiges Blitz und Lernen von Pytorch mit Beispielen.
Fragen, Vorschläge oder Korrekturen können als Probleme veröffentlicht werden.
Ich verwende PyTorch 0.4 in Python 3.6 .
27. Januar 2020 : Der Arbeitscode für zwei neue Tutorials wurde hinzugefügt-Superauflösung und maschinelle Übersetzung
Objektiv
Konzepte
Überblick
Durchführung
Ausbildung
Schlussfolgerung
Häufig gestellte Fragen
Um ein Modell zu erstellen, das eine beschreibende Bildunterschrift für ein Bild erzeugen kann, werden wir es bereitgestellt.
Lassen Sie uns die Show implementieren, teilnehmen und Papier erzählen . Dies ist keineswegs der aktuelle hochmoderne, aber immer noch verdammt erstaunlich. Die ursprüngliche Implementierung der Autoren finden Sie hier.
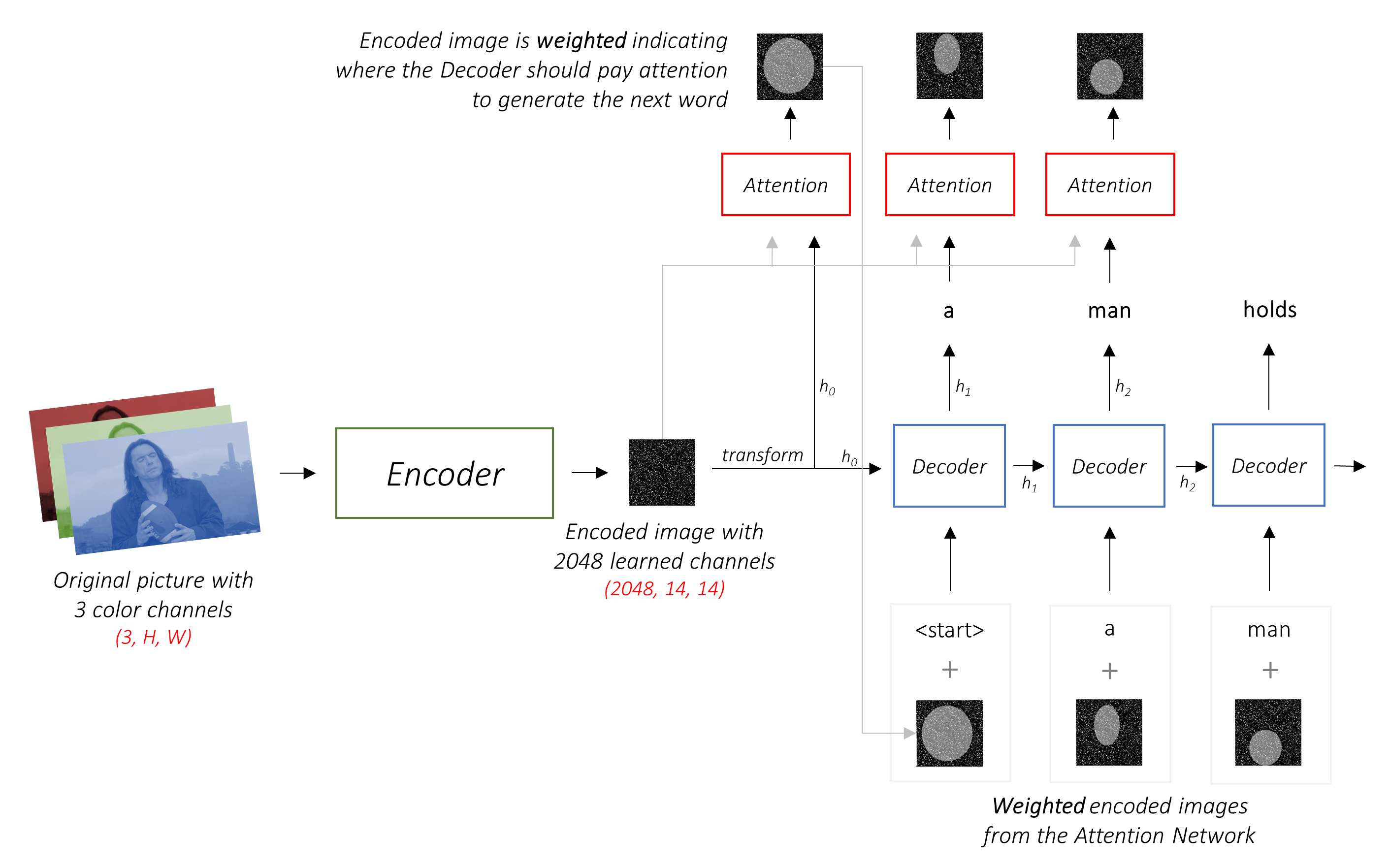
Dieses Modell lernt , wo man nachsehen soll.
Wenn Sie eine Bildunterschrift, Wort für Wort erzeugen, können Sie sehen, wie sich der Blick des Modells über das Bild verlagert.
Dies ist aufgrund seines Aufmerksamkeitsmechanismus möglich, der es ihm ermöglicht, sich auf das Bild zu konzentrieren, das für das Wort am relevantesten ist, das es als nächstes aussprechen wird.
Hier sind einige Untertitel, die auf Testbildern generiert werden, die während des Trainings oder der Validierung nicht zu sehen sind:




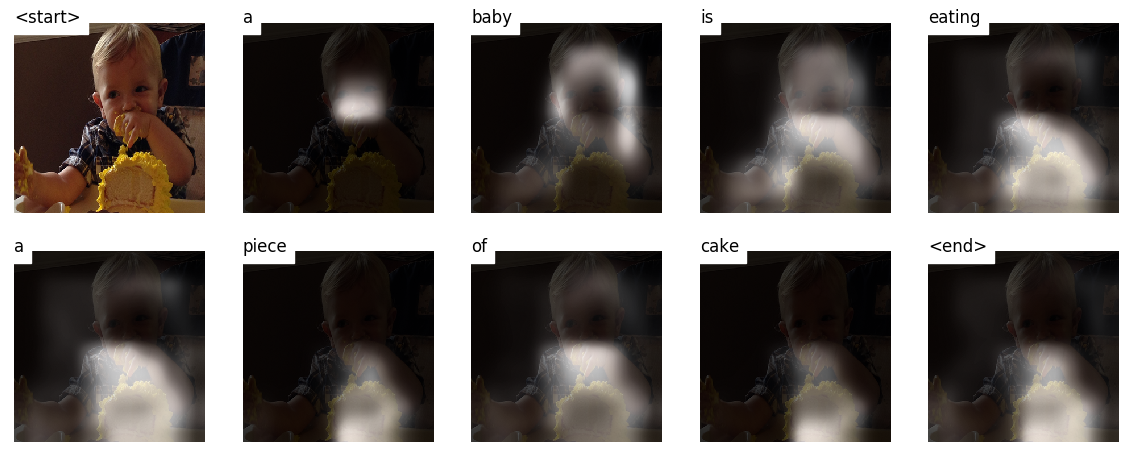

Am Ende des Tutorials gibt es weitere Beispiele.
Bildunterschrift . Duh.
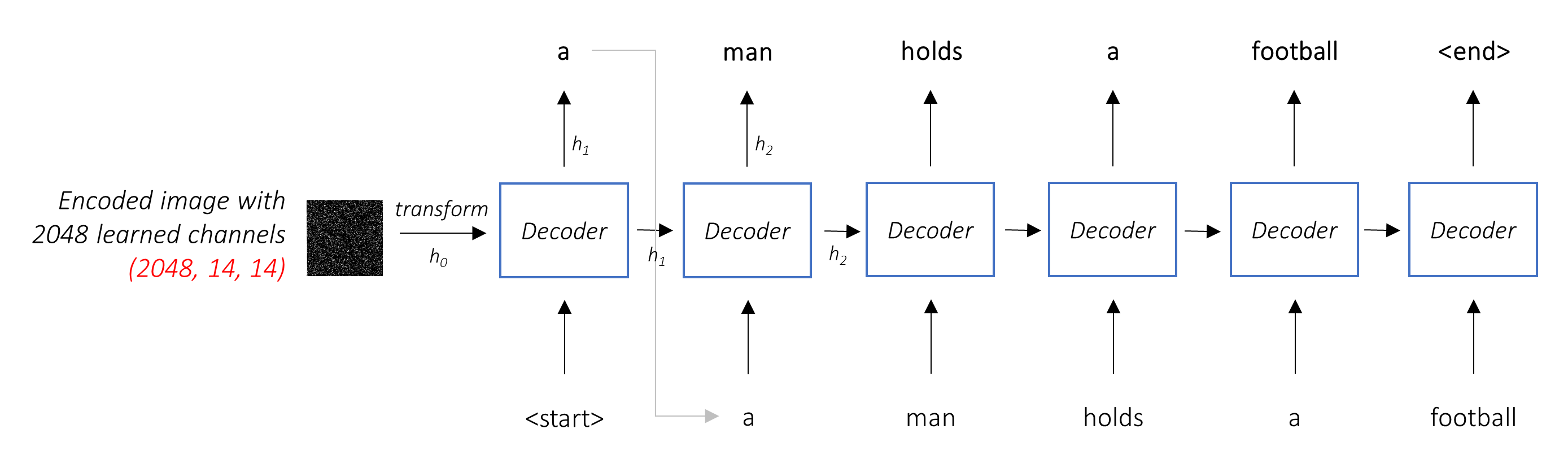
Encoder-Decoder-Architektur . Normalerweise verwendet ein Modell, das Sequenzen erzeugt, einen Encoder, um die Eingabe in eine feste Form und einen Decoder zu codieren, um ihn, Wort für Wort, in eine Sequenz zu dekodieren.
Aufmerksamkeit . Der Einsatz von Aufmerksamkeitsnetzwerken ist aus gutem Grund weit verbreitet. Dies ist eine Möglichkeit für ein Modell, nur die Teile der Codierung auszuwählen, die es für die jeweilige Aufgabe relevant hält. Der gleiche Mechanismus, den Sie hier sehen, kann in jedem Modell verwendet werden, bei dem die Ausgabe des Encoders mehrere Punkte in Raum oder Zeit hat. Bei Bildunterschriften betrachten Sie einige Pixel wichtiger als andere. Nach Abfolge von Sequenzaufgaben wie maschineller Übersetzung betrachten Sie einige Wörter wichtiger als andere.
Übertragungslernen . In diesem Fall leihen Sie sich von einem vorhandenen Modell aus, indem Sie Teile davon in einem neuen Modell verwenden. Dies ist fast immer besser, als ein neues Modell von Grund auf zu trainieren (dh nichts zu wissen). Wie Sie sehen werden, können Sie dieses Gebrauchswissen immer auf die jeweilige Aufgabe einstellen. Die Verwendung von vorgezogenem Wort Einbettungen ist ein dummes, aber gültiges Beispiel. Für unser Bildunterschriftsproblem werden wir einen vorbereiteten Encoder verwenden und sie dann nach Bedarf fein abteilen.
Strahlsuche . Hier lassen Sie Ihren Decoder nicht faul sein und wählen Sie einfach die Wörter mit der besten Punktzahl bei jedem Decodes-Schritt aus. Die Strahlsuche ist für jedes Sprachmodellierungsproblem nützlich, da sie die optimalste Sequenz findet.
In diesem Abschnitt werde ich einen Überblick über dieses Modell geben. Wenn Sie bereits vertraut sind, können Sie direkt zum Implementierungsabschnitt oder zum Kommentarcode überspringen.
Der Encoder codiert das Eingabebild mit 3 Farbkanälen in ein kleineres Bild mit "gelernten" Kanälen .
Dieses kleinere codierte Bild ist eine zusammenfassende Darstellung von allem, was im Originalbild nützlich ist.
Da wir Bilder codieren wollen, verwenden wir Faltungs- neuronales Netzwerke (CNNs).
Wir müssen keinen Encoder von Grund auf schützen. Warum? Weil es bereits CNNs gibt, um Bilder darzustellen.
Seit Jahren bauen Menschen Modelle, die außerordentlich gut darin sind, ein Bild in eine von tausend Kategorien zu klassifizieren. Es liegt auf der Hand, dass diese Modelle die Essenz eines Bildes sehr gut erfassen.
Ich habe mich für das 101 geschichtete Restnetzwerk entschieden, das auf der ImageNet -Klassifizierungsaufgabe trainiert wurde und bereits in Pytorch verfügbar ist. Wie bereits erwähnt, ist dies ein Beispiel für das Lernen von Transfer. Sie haben die Möglichkeit, die Leistung zu verbessern.

Diese Modelle erzeugen zunehmend immer kleinere Darstellungen des Originalbildes, und jede nachfolgende Darstellung ist mehr "gelernt" mit einer größeren Anzahl von Kanälen. Die endgültige Kodierung, die von unserem Resnet-101-Encoder erzeugt wird, hat eine Größe von 14x14 mit 2048 Kanälen, dh einen Tensor 2048, 14, 14 Größe.
Ich ermutige Sie, mit anderen vorgeborenen Architekturen zu experimentieren. Das Papier verwendet ein VGGNet, das ebenfalls auf ImageNet vorbereitet ist, jedoch ohne Feinabstimmung. In jedem Fall sind Änderungen erforderlich. Da die letzten oder zwei dieser Modelle lineare Schichten in Verbindung mit Softmax -Aktivierung zur Klassifizierung sind, ziehen wir sie weg.
Die Aufgabe des Decoders ist es, das codierte Bild zu betrachten und ein Bildunterschrift für Wort zu generieren .
Da es eine Sequenz erzeugt, müsste es ein wiederkehrendes neuronales Netzwerk (RNN) sein. Wir werden ein LSTM verwenden.
In einer typischen Einstellung ohne Aufmerksamkeit können Sie das codierte Bild einfach über alle Pixel hinweg durchdurchschnittlich durchschnittlich. Sie könnten dies dann mit oder ohne lineare Transformation in den Decoder als erster versteckter Zustand füttern und die Bildunterschrift erzeugen. Jedes vorhergesagte Wort wird verwendet, um das nächste Wort zu generieren.
In einer Einstellung mit Aufmerksamkeit möchten wir, dass der Decoder an verschiedenen Stellen in der Sequenz verschiedene Teile des Bildes betrachten kann. Während zum Beispiel das Wort football in a man holds a football generiert, würde sich der Decoder wissen, worauf Sie sich - Sie erraten - den Fußball konzentrierten!
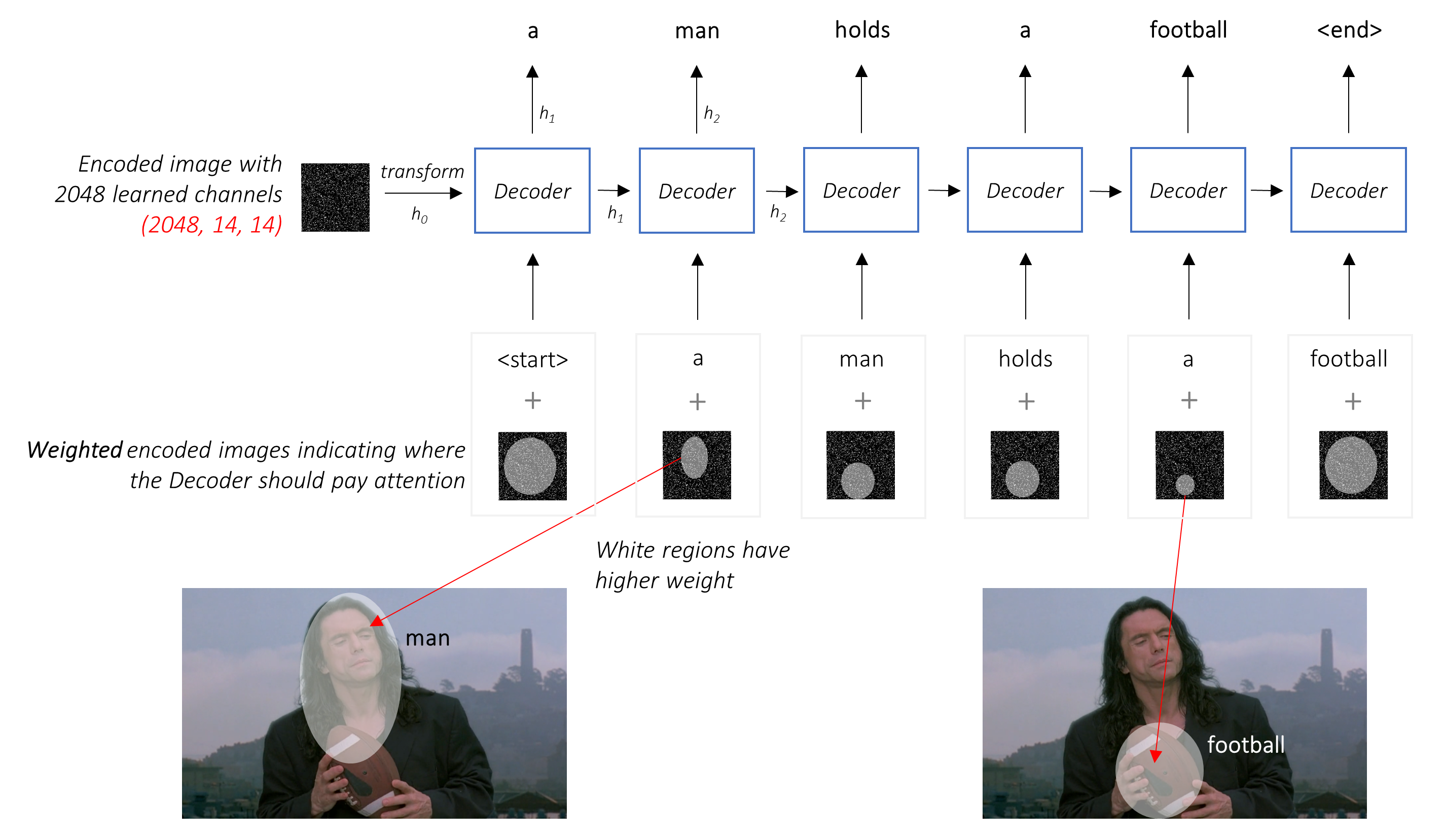
Anstelle des einfachen Durchschnitts verwenden wir den gewichteten Durchschnitt über alle Pixel, wobei die Gewichte der wichtigen Pixel größer sind. Diese gewichtete Darstellung des Bildes kann bei jedem Schritt mit dem zuvor erzeugten Wort verkettet werden, um das nächste Wort zu erzeugen.
Das Aufmerksamkeitsnetzwerk berechnet diese Gewichte .
Wie würden Sie intuitiv die Bedeutung eines bestimmten Teils eines Bildes schätzen? Sie müssten sich der bisher generierten Sequenz bewusst sein, damit Sie sich das Bild ansehen und entscheiden können, was als nächstes beschrieben werden muss. Nachdem Sie beispielsweise a man erwähnt haben, ist es logisch zu erklären, dass er holding a football .
Genau das macht der Aufmerksamkeitsmechanismus - er berücksichtigt die bisher erzeugte Sequenz und befasst sich mit dem Teil des Bildes, der als nächstes beschrieben werden muss.
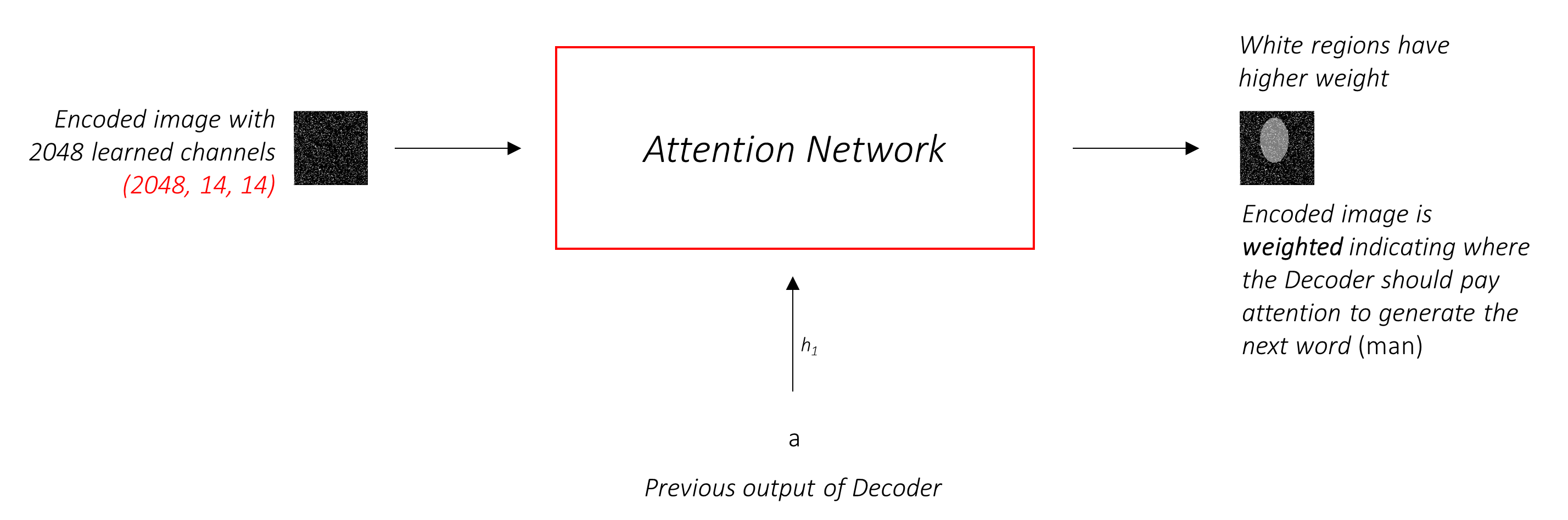
Wir werden weiche Aufmerksamkeit verwenden, wobei die Gewichte der Pixel zu 1 addieren. Wenn es P in unserem codierten Bild gibt, dann bei jedem Zeitschritt t -
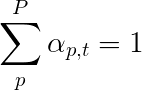
Sie können diesen gesamten Prozess als Berechnung der Wahrscheinlichkeit interpretieren, dass ein Pixel der Ort ist, um das nächste Wort zu generieren .
Es könnte inzwischen klar sein, wie unser kombiniertes Netzwerk aussieht.
h (und Zellzustand C ) für den LSTM -Decoder zu erstellen.Wir verwenden eine lineare Ebene, um die Ausgabe des Decoders für jedes Wort im Wortschatz in eine Punktzahl zu verwandeln.
Die unkomplizierte und gierige Option wäre, das Wort mit der höchsten Punktzahl zu wählen und es zu verwenden, um das nächste Wort vorherzusagen. Dies ist jedoch nicht optimal, da der Rest der Sequenz nach dem ersten Wort, das Sie auswählen, abhängt. Wenn diese Wahl nicht die beste ist, ist alles, was folgt, suboptimal. Und es ist nicht nur das erste Wort - jedes Wort in der Sequenz hat Konsequenzen für diejenigen, die es Erfolg haben.
Es könnte sehr gut passieren, dass, wenn Sie bei diesem ersten Schritt das drittbeste Wort und das zweitbeste Wort im zweiten Schritt und so weiter ... die beste Sequenz sein könnten, die Sie generieren könnten.
Es wäre am besten, wenn wir uns irgendwie nicht entscheiden könnten, bis wir die Dekodierung vollständig beendet haben und die Sequenz auswählen könnten, die die höchste Gesamtpunktzahl aus einem Korb mit Kandidatensequenzen aufweist .
Die Strahlsuche macht genau das.
k -Kandidaten.k -ersten Wörter k zweite Wörter.k [erste Wort, zweites Wort] Kombinationen unter Berücksichtigung von additiven Bewertungen.k zweiten Wörter k dritte Wörter aus, wählen Sie das obere k [erste Wort, zweites Wort, drittes Wort] Kombinationen.k -Sequenzen die Sequenz mit der besten Gesamtpunktzahl. 
Wie Sie sehen können, scheitern einige Sequenzen (gestreift) möglicherweise früh, da sie beim nächsten Schritt nicht nach oben k schafft. Sobald k -Sequenzen (unterstrichen) das <end> -Token generieren, wählen wir die mit der höchsten Punktzahl.
Die folgenden Abschnitte beschreiben kurz die Implementierung.
Sie sollen einen gewissen Kontext liefern, aber Details werden am besten direkt aus dem Code verstanden , was ziemlich stark kommentiert wird.
Ich verwende den Datensatz von MSCOCO '14. Sie müssten das Training (13 GB) und die Validierungsbilder (6 GB) herunterladen.
Wir werden die Ausbildung, Validierung und Prüfung von Andrej Karpathy verwenden. Diese ZIP -Datei enthält die Bildunterschriften. Sie finden auch Splits und Untertitel für die Datensätze Flicker8K und Flicker30K. Verwenden Sie diese also anstelle von MSCOCO, wenn dieser zu groß für Ihren Computer ist.
Wir brauchen drei Eingänge.
Da wir einen vorbereiteten Encoder verwenden, müssten wir die Bilder in die Form verarbeiten, an die dieser vorbereitete Encoder gewöhnt ist.
Vorbereitete ImageNet -Modelle, die als Teil des torchvision -Moduls von Pytorch erhältlich sind. Diese Seite beschreibt die Vorverarbeitung oder Transformation, die wir durchführen müssen - Pixelwerte müssen sich im Bereich [0,1] befinden, und wir müssen das Bild dann durch den Mittelwert und die Standardabweichung der RGB -Kanäle der ImageNet -Bilder normalisieren.
mean = [ 0.485 , 0.456 , 0.406 ]
std = [ 0.229 , 0.224 , 0.225 ]Außerdem folgt Pytorch der NCHW -Konvention, was bedeutet, dass die Dimension der Kanäle (c) den Größenabmessungen vorausgehen muss.
Wir werden alle MSCOCO -Bilder auf 256x256 für einheitliche Größe ändern.
Daher müssen Bilder, die dem Modell gefüttert werden, ein Float der Dimension N, 3, 256, 256 sein und müssen durch den vorgenannten Mittelwert und die Standardabweichung normalisiert werden. N ist die Chargengröße.
Bildunterschriften sind sowohl das Ziel als auch die Eingaben des Decoders, da jedes Wort zum Erzeugen des nächsten Wortes verwendet wird.
Um das erste Wort zu generieren, brauchen wir jedoch ein Nullenwort , <start> .
Beim letzten Wort sollten wir den <end> vorhersagen, dass der Decoder das Ende einer Bildunterschrift vorhersagen muss. Dies ist notwendig, da wir wissen müssen, wann wir während der Schlussfolgerung einstellen müssen.
<start> a man holds a football <end>
Da wir die Bildunterschriften als Tensoren der festen Größe übergeben, müssen wir mit <pad> -Marken auf die gleiche Länge auf die gleiche Länge auftreten (die von Natur aus unterschiedlich lang sind).
<start> a man holds a football <end> <pad> <pad> <pad>....
Darüber hinaus erstellen wir eine word_map , die für jedes Wort im Korpus eine Indexzuordnung ist, einschließlich der Token <start> , <end> und <pad> . Pytorch braucht wie andere Bibliotheken Wörter, die als Indizes kodiert werden, um Einbettungen für sie nachzuschlagen oder ihren Platz in den vorhergesagten Wortwerten zu identifizieren.
9876 1 5 120 1 5406 9877 9878 9878 9878....
Daher müssen Bildunterschriften, die dem Modell gespeist, ein Int -Tensor der Dimension N, L wobei L die gepolsterte Länge ist.
Da die Bildunterschriften gepolstert sind, müssten wir die Längen jeder Beschriftung im Auge behalten. Dies ist die tatsächliche Länge + 2 (für die <start> und <end> Token).
Bildunterschriftenlängen sind ebenfalls wichtig, da Sie dynamische Diagramme mit Pytorch erstellen können. Wir verarbeiten nur eine Sequenz bis zu ihrer Länge und verschwenden keine Berechnung auf der <pad> .
Daher müssen die am Modell gespeistlichen Beschriftungslängen ein Int -Tensor der Dimension N sein .
Siehe create_input_files() in utils.py .
Dies liest die heruntergeladenen Daten und speichert die folgenden Dateien - -
I, 3, 256, 256 Tensor , wobei I die Anzahl der Bilder im Split ist. Pixelwerte liegen noch im Bereich [0, 255] und werden als nicht signiert 8-Bit Int s gespeichert.N_c * I codierten Bildunterschriften , wobei N_c die Anzahl der pro Bild abgetasteten Untertitel ist. Diese Bildunterschriften sind in der gleichen Reihenfolge wie die Bilder in der HDF5 -Datei. Daher entspricht die i -Th -Bildunterschrift dem i // N_c th -Bild.N_c * I -Bildunterschriftenlängen . Der Wert von i th ist die Länge der i -Th -Bildunterschrift, die dem i // N_c th -Bild entspricht.word_map , das Wort-zu-Index-Wörterbuch enthält . Bevor wir diese Dateien speichern, haben wir die Option, nur Bildunterschriften zu verwenden, die kürzer als eine Schwelle sind, und weniger häufige Wörter in ein <unk> -Token abzubacken.
Wir verwenden HDF5 -Dateien für die Bilder, da wir sie während des Trainings / der Validierung direkt von der Festplatte lesen. Sie sind einfach zu groß, um sie auf einmal in RAM zu passen. Aber wir laden alle Untertitel und ihre Längen in den Speicher.
Siehe CaptionDataset in datasets.py .
Dies ist eine Unterklasse von Pytorch Dataset . Es benötigt eine __len__ -Methode definiert, die die Größe des Datensatzes zurückgibt, und eine __getitem__ -Methode, die das i , Bildunterschriften- und Bildunterschriftenlänge zurückgibt.
Wir lesen Bilder von der Festplatte, konvertieren Pixel in [0,255] und normalisieren sie in dieser Klasse.
Der Dataset wird von einem Pytorch DataLoader in train.py verwendet, um Datenstapel von Daten für Schulungen oder Validierung zu erstellen und zu füttern.
Siehe Encoder in models.py .
Wir verwenden einen vorgezogenen Resnet-101, der bereits im torchvision -Modul von Pytorch erhältlich ist. Verwerfen Sie die letzten beiden Ebenen (Pooling und lineare Ebenen), da wir das Bild nur codieren müssen und es nicht klassifizieren müssen.
Wir fügen eine AdaptiveAvgPool2d() -Schicht hinzu, um die Codierung einer festen Größe zu ändern . Dies ermöglicht es, Bilder mit variabler Größe in den Encoder zu füttern. (Wir haben jedoch die Größe unserer Eingangsbilder auf 256, 256 gegründet, weil wir sie als einzelne Tensor zusammen speichern mussten.)
Da wir den Encoder möglicherweise fein abstellen möchten, fügen wir eine fine_tune() -Methode hinzu, die die Berechnung von Gradienten für die Parameter des Encoders aktiviert oder deaktiviert. Wir haben nur die Feinabschneidblöcke 2 bis 4 im RESNET , da der erste Faltungsblock in der Regel etwas sehr Grundlegendes für die Bildverarbeitung gelernt hätte, wie z.
Siehe Attention in models.py .
Das Aufmerksamkeitsnetzwerk ist einfach - es besteht nur aus linearen Schichten und einigen Aktivierungen.
Trennende lineare Schichten transformieren sowohl das codierte Bild (abgeflacht auf N, 14 * 14, 2048 ) als auch den versteckten Zustand (Ausgabe) vom Decoder in die gleiche Dimension , d. H. die Aufmerksamkeitsgröße. Sie werden dann hinzugefügt und Relu aktiviert. Eine dritte lineare Schicht transformiert dieses Ergebnis in eine Dimension von 1 , woraufhin wir den Softmax auftragen, um die Gewichte alpha zu erzeugen.
Siehe DecoderWithAttention in models.py .
Die Ausgabe des Encoders wird hier empfangen und in Abmessungen N, 14 * 14, 2048 abgeflacht. Dies ist einfach bequem und verhindert, dass der Tensor mehrmals neu gestaltet wird.
Wir initialisieren den versteckten und zelligen Zustand des LSTM mit dem codierten Bild mit der Methode init_hidden_state() , die zwei separate lineare Schichten verwendet.
Zu Beginn sortieren wir die N Bilder und Bildunterschriften, indem wir die Beschriftungslängen verringern . Dies ist so, dass wir nur gültige Zeitschritte verarbeiten können, dh die <pad> s nicht verarbeiten.
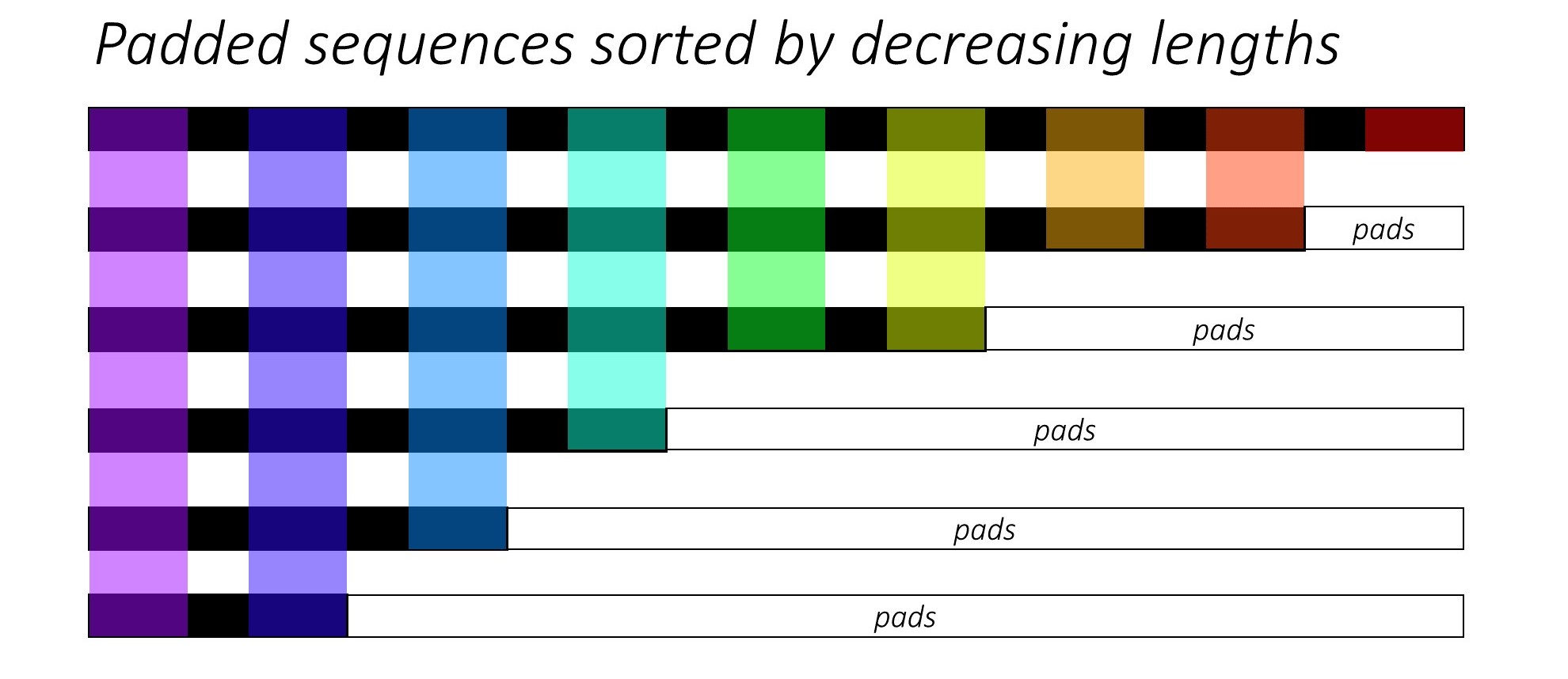
Wir können über jeden Zeitschritt iterieren und nur die farbigen Regionen verarbeiten, die die effektive Chargengröße N_t an diesem Zeitschritt sind. Die Sortierung ermöglicht es dem oberen N_t an jedem Zeitschritt, sich mit den Ausgängen aus dem vorherigen Schritt auszurichten. Zum dritten Zeitschritt verarbeiten wir beispielsweise nur die Top 5 Bilder mit den Top 5 Ausgängen aus dem vorherigen Schritt.
Diese Iteration wird manuell in einer for Schleife mit einem Pytorch LSTMCell durchgeführt, anstatt automatisch ohne Schleife mit einem Pytorch LSTM zu iterieren. Dies liegt daran, dass wir den Aufmerksamkeitsmechanismus zwischen den einzelnen Dekodierungsschritten ausführen müssen. Ein LSTMCell ist ein einzelner Zeitschritt, während ein LSTM über mehrere Zeitschritte ständig iteriert und alle Ausgaben gleichzeitig bereitgestellt wird.
Wir berechnen die Gewichte und die aufmerksamkeitsstarke Codierung an jedem Zeitschritt mit dem Aufmerksamkeitsnetzwerk. In Abschnitt 4.2.1 des Papiers empfehlen sie, die aufmerksamkeitsstarke Codierung durch einen Filter oder Tor zu übergeben . Dieses Tor ist eine sigmoid aktivierte lineare Transformation des früheren versteckten Zustands des Decoders. Die Autoren geben an, dass dies dem Aufmerksamkeitsnetzwerk hilft, die Objekte im Bild mehr Wert zu legen.
Wir verkettet diese gefilterte aufmerksamkeitsgewichtige Codierung mit der Einbettung des vorherigen Wortes ( <start> zu beginnen) und führen die LSTMCell aus, um den neuen versteckten Zustand (oder die Ausgabe) zu generieren . Eine lineare Schicht verwandelt diesen neuen versteckten Zustand für jedes Wort im gespeicherten Wortschatz in jedes Wort .
Wir speichern auch die vom Aufmerksamkeitsnetzwerk zurückgegebenen Gewichte an jedem Zeitschritt. Sie werden sehen, warum früh genug.
Stellen Sie vor Beginn sicher, dass Sie die erforderlichen Datendateien für Schulungen, Validierung und Prüfung speichern. Führen Sie dazu den Inhalt von create_input_files.py aus, nachdem Sie sie auf die Karpathy JSON -Datei und den Bildordner mit den Ordnern Extrahiertes train2014 und val2014 aus Ihren heruntergeladenen Daten hingewiesen haben.
Siehe train.py .
Die Parameter für das Modell (und das Training) liegen am Anfang der Datei, sodass Sie diese problemlos überprüfen oder ändern können, wenn Sie dies wünschen.
Um Ihr Modell von Grund auf neu zu trainieren , führen Sie einfach diese Datei aus - aus.
python train.py
Um das Training an einem Kontrollpunkt wieder aufzunehmen , verweisen Sie auf die entsprechende Datei mit dem checkpoint -Parameter am Anfang des Codes.
Beachten Sie, dass wir am Ende jeder Trainingspoche die Validierung durchführen.
Da wir eine Abfolge von Wörtern erzeugen, verwenden wir CrossEntropyLoss . Sie müssen die Rohwerte nur aus der letzten Ebene im Decoder einreichen, und die Verlustfunktion führt die Softmax- und Protokollvorgänge aus.
Die Autoren des Papiers empfehlen einen zweiten Verlust - eine " doppelt stochastische Regularisierung ". Wir kennen die Gewichte bei einem bestimmten Zeitschritt auf 1. Wir ermutigen aber auch die Gewichte bei einem einzelnen Pixel p , über alle Zeitschritte zu summieren. T -
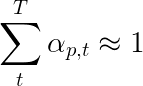
Dies bedeutet, dass das Modell im Laufe der Erzeugung der gesamten Sequenz sich um jedes Pixel kümmert. Daher versuchen wir, die Differenz zwischen 1 und der Summe der Gewichte eines Pixels über alle Zeitschritte zu minimieren .
Wir berechnen keine Verluste über die gepolsterten Regionen . Eine einfache Möglichkeit, die Pads loszuwerden, besteht darin, Pytorchs pack_padded_sequence() zu verwenden, der den Tensor durch Zeitschritt flacht und gleichzeitig die gepolsterten Regionen ignoriert. Sie können jetzt den Verlust über diesen abgeflachten Tensor zusammenhängen.
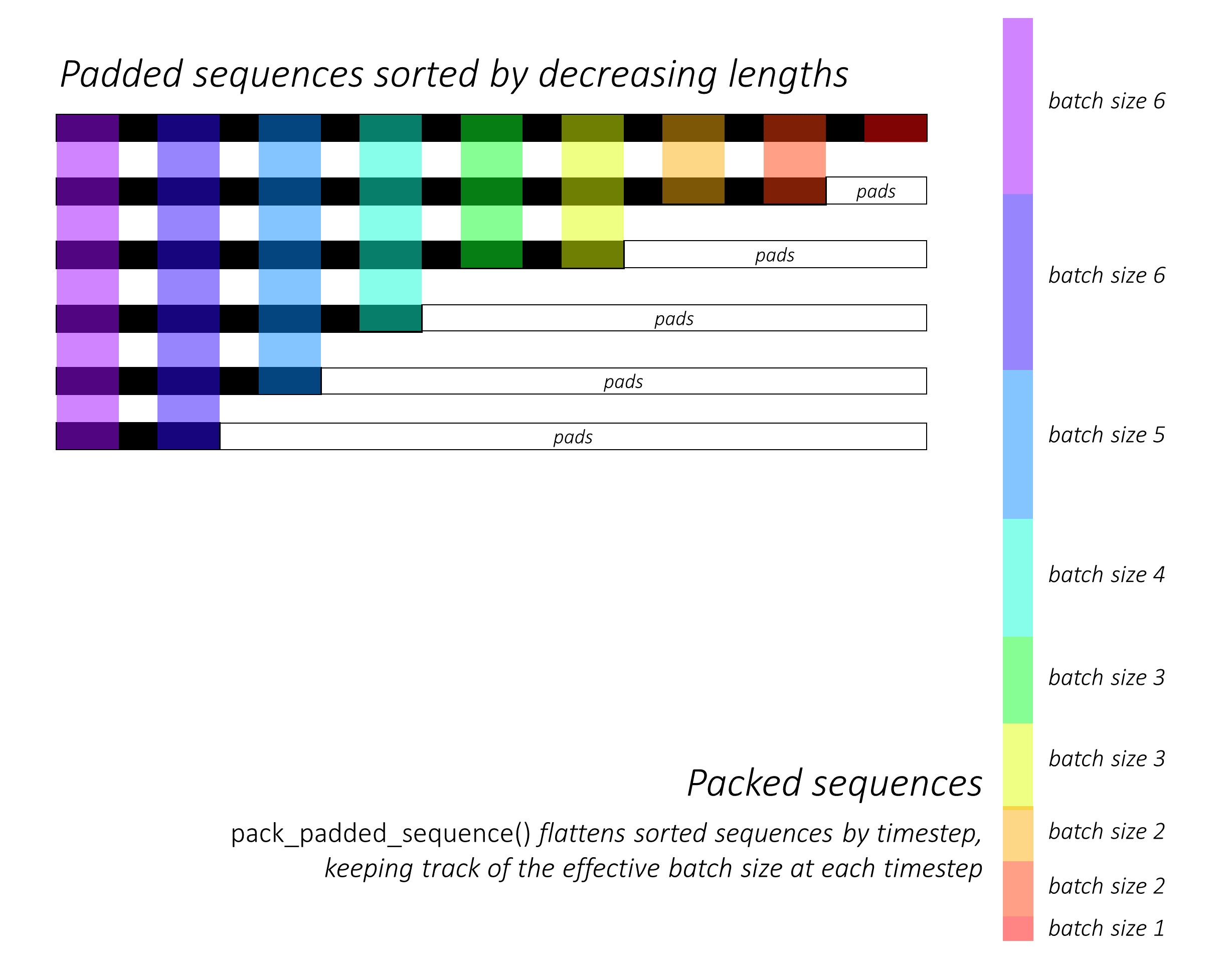
HINWEIS - Diese Funktion wird tatsächlich verwendet, um dieselbe dynamische Charge durchzuführen (dh nur die effektive Chargengröße bei jedem Zeitschritt), den wir in unserem Decoder bei Verwendung eines RNN oder LSTM in Pytorch durchgeführt haben. In diesem Fall verarbeitet Pytorch die dynamischen Grafiken mit variabler Länge intern. In meinem anderen Tutorial zur Sequenzmarkierung können Sie ein Beispiel in dynamic_rnn.py sehen. Wir hätten diese Funktion zusammen mit einem LSTM in unserem Decoder verwendet, wenn wir wegen des Aufmerksamkeitsnetzwerks nicht manuell iteriert würden.
Um die Leistung des Modells am Validierungssatz zu bewerten, verwenden wir die BLEU -Bewertungsmetrik der automatisierten zweisprachigen Bewertungsstuddy (BLEU). Dies bewertet eine generierte Bildunterschrift gegen Referenzunterschriften. Für jede generierte Bildunterschrift verwenden wir alle für dieses Bild verfügbaren N_c -Bildunterschriften als Referenzunterschriften.
Die Autoren der Show, teilnehmen und erzählen , dass die Korrelation zwischen dem Verlust und dem Bleu -Score nach einem Punkt zusammenbricht. Daher empfehlen sie, das Training frühzeitig zu stoppen, wenn sich der BLEU -Score zu verschlechtern, auch wenn der Verlust weiter abnimmt.
Ich habe das im NLTK -Modul verfügbare Bleu -Tool verwendet.
Beachten Sie, dass die Bleu -Punktzahl erheblich kritisiert wird, da er nicht immer gut mit dem menschlichen Urteilsvermögen korreliert. Die Autoren melden auch die Meteor -Scores aus diesem Grund, aber ich habe diese Metrik nicht implementiert.
Ich empfehle Ihnen, stufenweise zu trainieren.
Ich habe zuerst nur den Decoder trainiert, dh ohne den Encoder mit einer Chargengröße von 80 . Ich trainierte für 20 Epochen, und die BLEU-4-Punktzahl erreichte in der 13. Epoche einen Höhepunkt bei etwa 23.25 . Ich habe den Adam() Optimierer mit einer anfänglichen Lernrate von 4e-4 verwendet.
Ich setzte mich vom 13. Epoch-Checkpoint fort und ermöglichte die Feinabstimmung des Encoders mit einer Chargengröße von 32 . Die kleinere Chargengröße liegt daran, dass das Modell jetzt größer ist, da es die Gradienten des Encoders enthält. Bei Feinabstimmung stieg die Punktzahl in fast 3 Epochen auf 24.29 . Das fortgesetzte Training hätte die Partitur wahrscheinlich etwas höher geschoben, aber ich musste meine GPU anderswo begehen.
Eine wichtige Unterscheidung hier ist, dass ich die Grundwahrheit als Eingabe bei jedem Dekodierungsschritt während der Validierung immer noch liefere, unabhängig vom zuletzt generierten Wort . Dies wird als Lehrerzweck bezeichnet. Während dies während des Trainings häufig verwendet wird, um den Prozess wie wir zu beschleunigen, müssen die Bedingungen während der Validierung reale Inferenzbedingungen so weit wie möglich imitieren. Ich habe noch keine angegriffene Inferenz implementiert - wobei jedes Wort in der Bildunterschrift aus dem zuvor erzeugten Wort generiert wird, und beendet beim Treffer des <end> -Tokens.
Da ich während der Validierung Lehrer-Vorsorge habe, spiegelt der oben gemessene BLEU-Wert auf den resultierenden Bildunterschriften keine echte Leistung wider. Tatsächlich ist der BLEU-Score eine Metrik, die zum Vergleich natürlicher Bildunterschriften mit Bodenwahrheitsunterschriften unterschiedlicher Länge ausgelegt ist. Sobald die Inferenz implementiert ist, ist der Erzwingen kein Lehrer, der frühzeitig mit dem Bleu-Score stößt.
In diesem Sinne habe ich eval.py verwendet, um die richtigen BLEU-4-Werte dieses Modellkontrollpunkts für die Validierungs- und Testsätze ohne Lehrerzweck in verschiedenen Strahlgrößen zu berechnen.
| Strahlgröße | Validierung BLEU-4 | Test BLEU-4 |
|---|---|---|
| 1 | 29.98 | 30.28 |
| 3 | 32.95 | 33.06 |
| 5 | 33.17 | 33.29 |
Die Testbewertung ist höher als das Ergebnis des Papiers und könnte darauf zurückzuführen sein, wie unsere Bleu-Taschenrechner parametrisiert sind, die Tatsache, dass ich einen Resnet-Encoder verwendet habe und den Encoder tatsächlich fein abgestimmt hat-auch wenn nur ein wenig.
Denken Sie auch daran, dass es immer besser ist, bei der Feinabstimmung während des Transferlernens immer besser zu verwenden, um das geliehene Modell zu trainieren. Dies liegt daran, dass das Modell bereits ziemlich optimiert ist und wir nichts zu schnell ändern möchten. Ich habe Adam() auch für den Encoder verwendet, aber mit einer Lernrate von 1e-4 , die ein Zehntel des Standardwerts für diesen Optimierer ist.
Bei einem Titan X (Pascal) dauerte es 55 Minuten pro Epoche ohne Feinabstimmung und 2,5 Stunden mit Feinabstimmung an den angegebenen Chargengrößen.
Sie können dieses vorgezogene Modell und das entsprechende word_map hier herunterladen.
Beachten Sie, dass dieser Kontrollpunkt direkt mit Pytorch geladen oder an caption.py - siehe unten übergeben werden sollte.
Siehe caption.py .
Während der Inferenz können wir die forward() -Methode im Decoder nicht direkt anwenden, da der Lehrerzweck verwendet wird. Vielmehr müssten wir das zuvor erzeugte Wort an jedem Zeitschritt der LSTM füttern .
caption_image_beam_search() liest ein Bild, codiert es und wendet die Ebenen im Decoder in der richtigen Reihenfolge an, während das zuvor generierte Wort als Eingabe zum LSTM an jedem Zeitschritt verwendet wird. Es enthält auch Strahlsuche.
visualize_att() kann verwendet werden, um die erzeugte Bildunterschrift zusammen mit den Gewichten bei jedem Zeitschritt zu visualisieren, wie in den Beispielen zu sehen ist.
Um ein Bild aus der Befehlszeile zu beschreiben , zeigen
python caption.py --img='path/to/image.jpeg' --model='path/to/BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' --word_map='path/to/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json' --beam_size=5
Verwenden Sie alternativ die Funktionen in der Datei nach Bedarf.
Siehe auch eval.py , der diesen Prozess zur Berechnung der BLEU -Punktzahl im Validierungssatz mit oder ohne Strahlsuche implementiert.





Der Turing Tommy -Test - Sie wissen, dass Ai nicht wirklich KI ist, weil er den Raum nicht gesehen hat und die Größe nicht erkennt, wenn es ihn sieht.

Sie sagten weiche Aufmerksamkeit. Gibt es schwere Aufmerksamkeit?
Ja, die Show, die Teilnahme und das Tell -Papier verwendet beide Varianten, und der Decoder mit "harter" Aufmerksamkeit führt geringfügig besser.
In weicher Aufmerksamkeit, die wir hier verwenden, berechnen Sie die Gewichte alpha und verwenden den gewichteten Durchschnitt der Merkmale über alle Pixel hinweg. Dies ist eine deterministische, differenzierbare Operation.
In schwieriger Aufmerksamkeit entscheiden Sie sich dafür, nur einige Pixel aus einer von alpha definierten Verteilung zu probieren. Beachten Sie, dass eine solche probabilistische Abtastung nicht deterministisch oder stochastisch ist, dh ein spezifischer Eingang erzeugt nicht immer den gleichen Ausgang. Da der Gradientenabstieg jedoch voraussetzt, dass das Netzwerk deterministisch (und daher differenzierbar) ist, wird die Probenahme überarbeitet, um seine Stochastizität zu beseitigen. Mein Wissen darüber ist zu diesem Zeitpunkt ziemlich oberflächlich - ich werde diese Antwort aktualisieren, wenn ich ein detaillierteres Verständnis habe.
Wie verwende ich ein Aufmerksamkeitsnetzwerk für eine NLP -Aufgabe wie eine Sequenz zum Sequenzmodell?
Ähnlich wie Sie ein CNN verwenden, um eine Codierung mit Funktionen an jedem Pixel zu generieren, verwenden Sie ein RNN, um codierte Funktionen bei jeder Zeitposition der Zeit in der Eingabe zu generieren.
Ohne Aufmerksamkeit würden Sie die Ausgabe des Encoders zum letzten Zeitschritt als Codierung für den gesamten Satz verwenden, da es auch Informationen aus früheren Zeitschritt enthalten würde. Die letzte Ausgabe des Encoders trägt jetzt die Belastung, den gesamten Satz sinnvoll zu kodieren, was insbesondere für längere Sätze nicht einfach ist.
Mit Aufmerksamkeit würden Sie die Zeitschritte in der Ausgabe des Encoders besuchen, die Gewichte für jeden Zeitschritt/Wort erzeugen und den gewichteten Durchschnitt nehmen, um den Satz darzustellen. In einer Sequenz zur Sequenzaufgabe wie maschineller Übersetzung würden Sie sich um die relevanten Wörter in der Eingabe kümmern, wenn Sie jedes Wort in der Ausgabe erzeugen.
Sie könnten auch ohne Decoder die Aufmerksamkeit verwenden. Wenn Sie beispielsweise Text klassifizieren möchten, können Sie sich nur einmal um die wichtigen Wörter in der Eingabe kümmern, um die Klassifizierung durchzuführen.
Können wir während des Trainings eine Strahlsuche verwenden?
Nicht mit der aktuellen Verlustfunktion, aber ja. Dies ist überhaupt nicht üblich.
Was erzwingt Lehrer?
Der Lehrerzwang ist, wenn wir die Bodenwahrheitsunterschriften als Eingabe zum Decoder bei jedem Zeitschritt verwenden und nicht das Wort, das sie im vorherigen Zeitschritt erzeugt hat. Während des Trainings ist es für die Lehrerkraft üblich, da es eine schnellere Konvergenz des Modells bedeuten könnte. Es kann aber auch lernen, abhängig davon, die richtige Antwort zu erhalten, und in der Praxis eine gewisse Instabilität aufweisen.
Es wäre ideal, den Lehrer zu trainieren, der nur einige Zeit auf der Grundlage einer Wahrscheinlichkeit erzwingt. Dies wird als geplante Stichprobe bezeichnet.
(Ich habe vor, die Option hinzuzufügen).
Kann ich vorgezogene Wortbettendings (Handschuh, CBOW, Skipgram usw.) verwenden, anstatt sie von Grund auf neu zu lernen?
Ja, Sie könnten mit der Methode load_pretrained_embeddings() in der Decoder -Klasse. Sie können sich auch mit der Methode fine_tune_embeddings() für eine Feinabstimmung (oder nicht) entscheiden.
Nachdem Sie den Decoder in train.py erstellt haben, sollten Sie den vorbereiteten Vektoren in der gleichen load_pretrained_embeddings() wie in der word_map stapeln. Für Wörter, für die Sie keine vorbereiteten Vektoren haben, wie <start> , können Sie die Einbettungen nach dem Zufallsprinzip initialisieren, wie wir es in init_weights() getan haben. Ich empfehle Feinabstimmung, um aussagekräftigere Vektoren für diese zufällig initialisierten Vektoren zu erfahren.
decoder = DecoderWithAttention ( attention_dim = attention_dim ,
embed_dim = emb_dim ,
decoder_dim = decoder_dim ,
vocab_size = len ( word_map ),
dropout = dropout )
decoder . load_pretrained_embeddings ( pretrained_embeddings ) # pretrained_embeddings should be of dimensions (len(word_map), emb_dim)
decoder . fine_tune_embeddings ( True ) # or False Stellen Sie außerdem sicher, dass Sie den Parameter emb_dim von seinem aktuellen Wert von 512 in die Größe Ihrer vorgeborenen Einbettungen ändern. Dies sollte automatisch die Eingangsgröße des Decoder -LSTM anpassen, um sie zu erhalten.
Wie kann ich den Überblick über die Tensoren ermöglichen, dass Gradienten berechnet werden?
Mit der Freisetzung von Pytorch 0.4 ist das Wickeln von Tensoren als Variable S nicht mehr erforderlich. Stattdessen haben Tensoren das Attribut für requires_grad , das entscheidet, ob es von autograd verfolgt wird und daher während der Rückpropagation Gradienten dafür berechnet werden.
requires_grad , um auf False festgelegt zu werden.requires_grad , um auf True zu sorgen.torch.nn -Ebenen sind True haben bereits requires_grad .Wie berechne ich während der Bewertung alle Blend-(-dh BLEU-1 zu BLEU-4) -Werdern?
Sie müssten den Code in eval.py ändern. Eine klare und detaillierte Erklärung finden Sie in dieser hervorragenden Antwort von KMARIO23.


