Fengshenbang LM
1.0.0
中文| English
Fengshenbang 1.0 : 封神榜開源計劃1.0中英雙語總論文,旨在成為中文認知智能的基礎設施。
BioBART : 由清華大學和IDEA研究院一起提供的生物醫療領域的生成語言模型。 (
BioNLP 2022)
UniMC : 針對zero-shot場景下基於標籤數據集的統一模型。 (
EMNLP 2022)
FMIT : 基於相對位置編碼的單塔多模態命名實體識別模型。 (
COLING 2022)
UniEX : 統一抽取任務的自然語言理解模型。 (
ACL 2023)
Solving Math Word Problems via Cooperative Reasoning induced Language Models :使用語言模型的協同推理框架解決數學問題。 (
ACL 2023)
MVP-Tuning : 基於多視角知識檢索的參數高效常識問答系統。 (
ACL 2023)
| 系列名稱 | 需求 | 適用任務 | 參數規模 | 備註 |
|---|---|---|---|---|
| 姜子牙 | 通用 | 通用大模型 | >70億參數 | 通用大模型“姜子牙”系列,具備翻譯,編程,文本分類,信息抽取,摘要,文案生成,常識問答和數學計算等能力 |
| 太乙 | 特定 | 多模態 | 8千萬-10億參數 | 應用於跨模態場景,包括文本圖像生成,蛋白質結構預測, 語音-文本表示等 |
| 二郎神 | 通用 | 語言理解 | 9千萬-39億參數 | 處理理解任務,擁有開源時最大的中文bert模型,2021登頂FewCLUE和ZeroCLUE |
| 聞仲 | 通用 | 語言生成 | 1億-35億參數 | 專注於生成任務,提供了多個不同參數量的生成模型,例如GPT2等 |
| 燃燈 | 通用 | 語言轉換 | 7千萬-50億參數 | 處理各種從源文本轉換到目標文本類型的任務,例如機器翻譯,文本摘要等 |
| 餘元 | 特定 | 領域 | 1億-35億參數 | 應用於領域,如醫療,金融,法律,編程等。擁有目前最大的開源GPT2醫療模型 |
| -待定- | 特定 | 探索 | -未知- | 我們希望與各技術公司和大學一起開發NLP相關的實驗模型。目前已有:周文王 |
封神榜模型下載鏈接
封神榜模型訓練和微調代碼腳本
封神榜模型訓練手冊
人工智能的顯著進步產生了許多偉大的模型,特別是基於預訓練的基礎模型成為了一種新興的範式。傳統的AI模型必須要在專門的巨大的數據集上為一個或幾個有限的場景進行訓練,相比之下,基礎模型可以適應廣泛的下游任務。基礎模型造就了AI在低資源的場景下落地的可能。
我們觀察到這些模型的參數量正在以每年10倍的速度增長。 2018年的BERT,在參數量僅有1億量級,但是到了2020年,GPT-3的參數量就已達到百億的量級。由於這一鼓舞人心的趨勢,人工智能中的許多前沿挑戰,尤其是強大的泛化能力,逐漸變得可以被實現。
如今的基礎模型,尤其是語言模型,正在被英文社區主導著。與此同時,中文作為這個世界上最大的口語語種(母語者中),卻缺乏系統性的研究資源支撐,這使得中文領域的研究進展相較於英文來說有些滯後。
這個世界需要一個答案。
為了解決中文領域研究進展滯後和研究資源嚴重不足的問題,2021年11月22日,IDEA研究院創院理事長沈向洋在IDEA大會上正式宣布,開啟“封神榜”開源體系——一個以中文驅動的基礎生態系統,其中包括了預訓練大模型,特定任務的微調應用,基準和數據集等。我們的目標是構建一個全面的,標準化的,以用戶為中心的生態系統。 
“封神榜模型”將全方面的開源一系列NLP相關的預訓練大模型。 NLP社區中有著廣泛的研究任務,這些任務可以被分為兩類:通用任務和特殊任務。前者包括了自然語言理解(NLU),自然語言生成(NLG)和自然語言轉換(NLT)任務。後者涵蓋了多模態,特定領域等任務。我們考慮了所有的這些任務,並且提供了在下游任務上微調好的相關模型,這使得計算資源有限的用戶也可以輕鬆使用我們的基礎模型。而且我們承諾,將對這些模型做持續的升級,不斷融合最新的數據和最新的訓練算法。通過IDEA研究院的努力,打造中文認知智能的通用基礎設施,避免重複建設,為全社會節省算力。
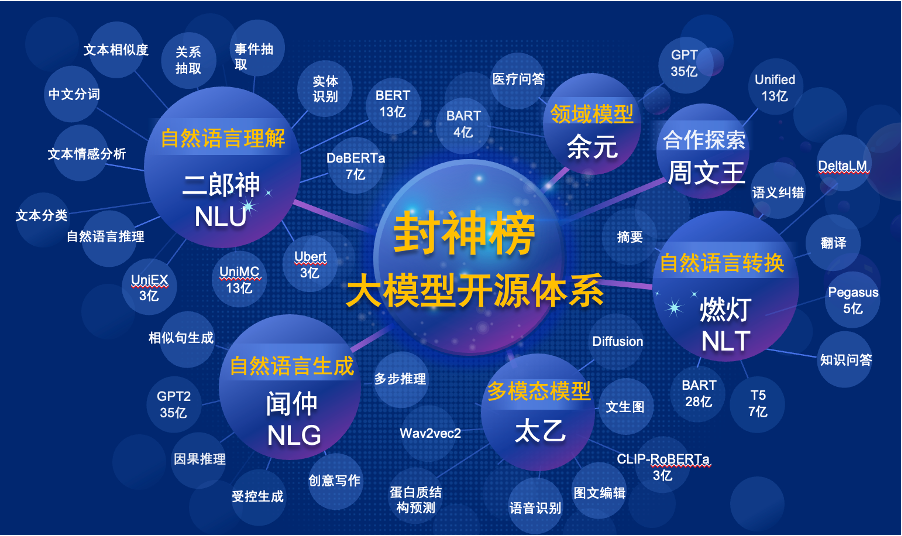
同時,“封神榜”也希望各個公司、高校、機構加入到這個開源計劃中,一起共建大模型開源體系。未來,當我們需要一個新的預訓練模型,都應該是首先從這些開源大模型中選取一個最接近的,做繼續訓練,然後再把新的模型開源回這個體系。這樣,每個人用最少的算力,就能得到自己的模型,同時這個開源大模型體係也能越來越大。

為了更好的體驗,擁抱開源社區,封神榜的所有模型都轉化並同步到了Huggingface社區,你可以通過幾行代碼就能輕鬆使用封神榜的所有模型,歡迎來IDEA-CCNL的huggingface社區下載。
通用大模型“姜子牙”系列,具備翻譯,編程,文本分類,信息抽取,摘要,文案生成,常識問答和數學計算等能力。目前姜子牙通用大模型(v1/v1.1)已完成大規模預訓練、多任務有監督微調和人類反饋學習三階段的訓練過程。姜子牙系列模型包含以下模型:
參考Ziya-LLaMA-13B-v1
參考ziya_finetune
參考ziya_inference
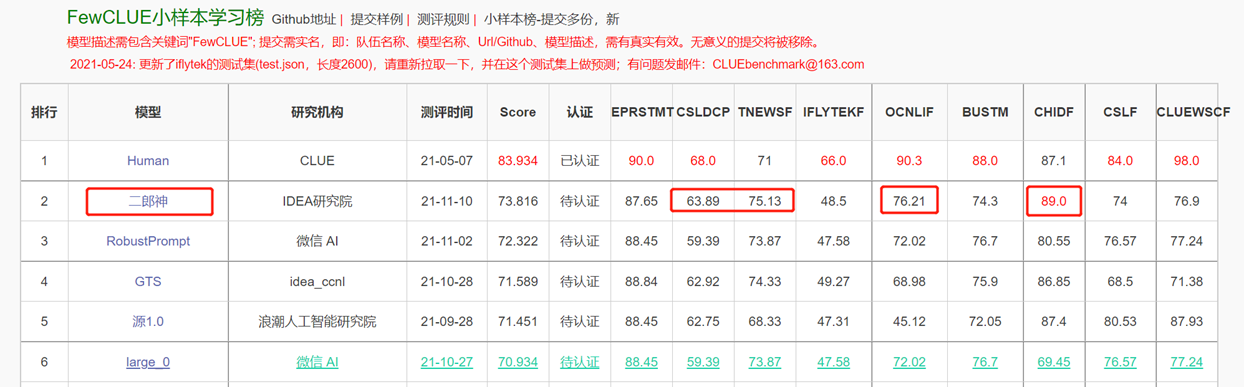
Encoder結構為主的雙向語言模型,專注於解決各種自然語言理解任務。 13億參數的二郎神-1.3B大模型,採用280G數據,32張A100訓練14天,是最大的開源中文Bert大模型。 2021年11月10日在中文語言理解權威評測基準FewCLUE 榜單上登頂。其中,CHID(成語填空)、TNEWS(新聞分類)超過人類,CHID(成語填空)、CSLDCP(學科文獻分類)、OCNLI(自然語言推理)單任務第一,刷新小樣本學習記錄。二郎神系列會持續在模型規模、知識融入、監督任務輔助等方向不斷優化。
2022年1月24日,二郎神-MRC在中文語言理解評測零樣本ZeroCLUE榜單上登頂。其中,CSLDCP(學科文獻分類)、TNEWS(新聞分類),IFLYTEK(應用描述分類)、CSL(摘要關鍵字識別)、CLUEWSC(指代消解)單任務均為第一。 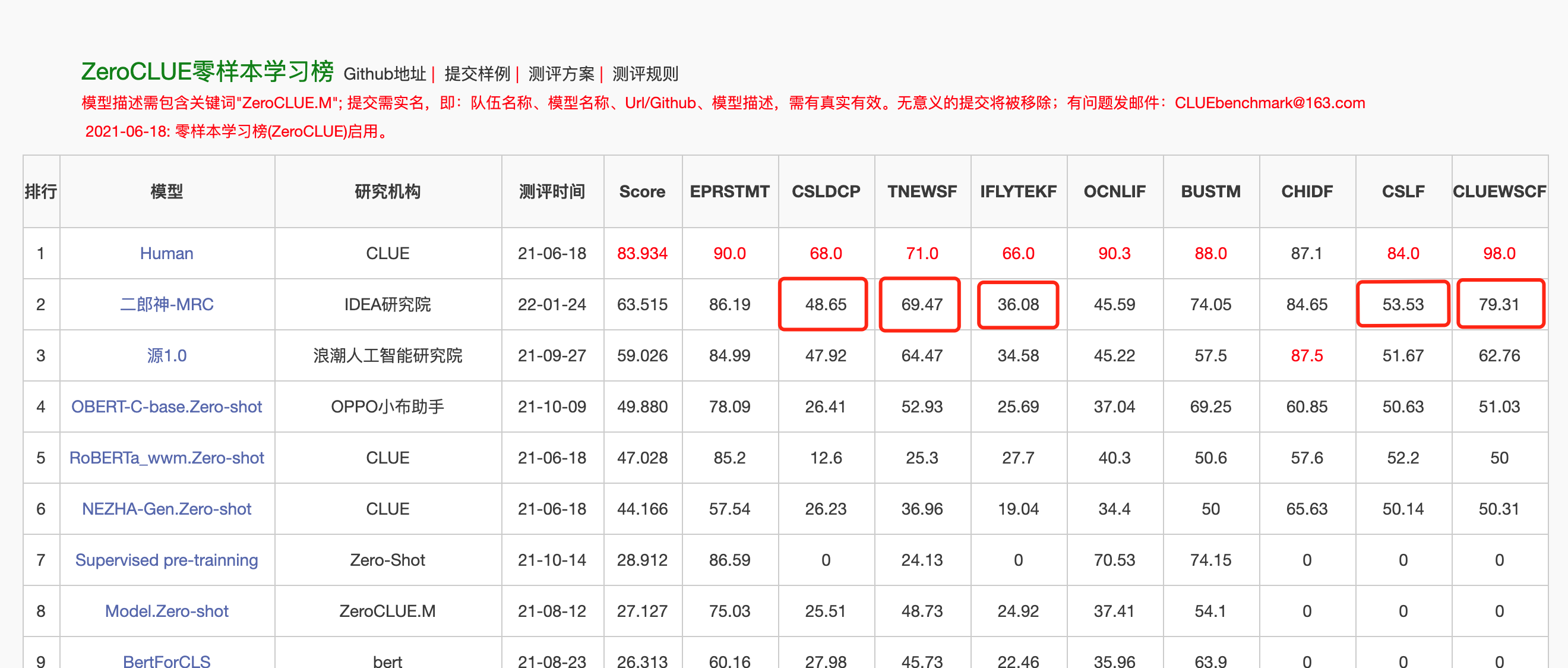
Huggingface 二郎神-1.3B
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )為了便於開發者快速使用我們的開源模型,這裡提供了一個下游任務的finetune示例腳本,使用的CLUE上的tnews新聞分類任務數據,運行腳本如下。其中DATA_PATH為數據路徑,tnews任務數據的下載地址.
1、首先修改finetune示例腳本finetune_classification.sh中的model_type和pretrained_model_path參數。其他如batch_size、data_dir等參數可根據自己的設備修改。
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2、然後運行:
sh finetune_classification.sh| 模型 | afqmc | tnews | iflytek | ocnli | cmnli | wsc | csl |
|---|---|---|---|---|---|---|---|
| roberta-wwm-ext-large | 0.7514 | 0.5872 | 0.6152 | 0.777 | 0.814 | 0.8914 | 0.86 |
| Erlangshen-MegatronBert-1.3B | 0.7608 | 0.5996 | 0.6234 | 0.7917 | 0.81 | 0.9243 | 0.872 |
太乙系列模型主要應用於跨模態場景,包括文本圖像生成,蛋白質結構預測, 語音-文本表示等。 2022年11月1日,封神榜開源了第一個中文版本的stable diffusion 模型“太乙Stable Diffusion”。
太乙Stable Diffusion 純中文版本
太乙Stable Diffusion 中英雙語版本
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| 鐵馬冰河入夢來,3D繪畫。 | 飛流直下三千尺,油畫。 | 女孩背影,日落,唯美插畫。 |
|---|---|---|
 |  |  |
Advanced Prompt
| 鐵馬冰河入夢來,概念畫,科幻,玄幻,3D | 中國海邊城市,科幻,未來感,唯美,插畫。 | 那人卻在燈火闌珊處,色彩艷麗,古風,資深插畫師作品,桌面高清壁紙。 |
|---|---|---|
 |  |  |
https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/IDEA-CCNL/stable-diffusion-webui/blob/master/README.md
https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/stable_diffusion_dreambooth
為了讓大家用好封神榜大模型,參與大模型的繼續訓練和下游應用,我們同步開源了以用戶為中心的FengShen(封神)框架。詳情請見:FengShen(封神)框架。
我們參考了HuggingFace, Megatron-LM, Pytorch-Lightning, DeepSpeed等優秀的開源框架,結合NLP領域的特點, 以Pytorch為基礎框架,Pytorch-Lightning為Pipeline重新設計了FengShen。 FengShen可以應用在基於海量數據(TB級別數據)的大模型(百億級別參數)預訓練以及各種下游任務的微調,用戶可以通過配置的方式很方便地進行分佈式訓練和節省顯存的技術,更加聚焦在模型實現和創新。同時FengShen也能直接使用HuggingFace中的模型結構進行繼續訓練,方便用戶進行領域模型遷移。 FengShen針對封神榜開源的模型和模型的應用,提供豐富、真實的源代碼和示例。隨著封神榜模型的訓練和應用,我們也會不斷優化FengShen框架,敬請期待。
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .我們提供一個簡單的包含torch、cuda環境的docker來運行我們的框架。
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦封神框架目前在適配各種下游任務的Pipeline,支持命令行一鍵啟動Predict、Finetuning。 以Text Classification為例
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddp三分鐘上手封神
封神榜系列之從數據並行開始大模型訓練
封神榜系列之是時候給你的訓練提提速了
封神榜系列之中文pegasus模型預訓練
封神榜系列:finetune一下二郎神就不小心拿下了第一
封神榜系列之快速搭建你的算法demo
2022AIWIN世界人工智能創新大賽:小樣本多任務賽道冠軍方案
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
IDEA研究院CCNL技術團隊已創建封神榜開源討論群,我們將在討論群中不定期更新發布封神榜新模型與系列文章。請掃描下面二維碼或者微信搜索“fengshenbang-lm”,添加封神空間小助手進群交流!

我們也在持續招人,歡迎投遞簡歷!

Apache License 2.0


