Fengshenbang LM
1.0.0
Cina | Bahasa inggris
Fengshenbang 1.0 : Investasi Rencana Sumber Terbuka 1.0 Kertas Bilingual Cina dan Inggris bertujuan untuk menjadi infrastruktur kecerdasan kognitif Tiongkok.
BioBart : Model Bahasa Generatif untuk Bidang Biomedis yang disediakan oleh Universitas Tsinghua dan Institut Penelitian Ide. (
BioNLP 2022)
UNIMC : Model terpadu berdasarkan set data label dalam skenario nol-shot. (
EMNLP 2022)
FMIT : Model pengenalan entitas multimodal menara tunggal berdasarkan pengkodean posisi relatif. (
COLING 2022)
Uniex : Model pemahaman bahasa alami untuk tugas ekstraksi terpadu. (
ACL 2023)
Memecahkan masalah kata matematika melalui penalaran kooperatif model bahasa yang diinduksi : memecahkan masalah matematika menggunakan kerangka penalaran kolaboratif untuk model bahasa. (
ACL 2023)
MVP-tuning : Sistem tanya jawab dan jawaban yang efisien parameter berdasarkan pengambilan pengetahuan multi-perspektif. (
ACL 2023)
| Nama seri | membutuhkan | Tugas yang berlaku | Skala parameter | Komentar |
|---|---|---|---|---|
| Jiang Ziya | Umum | Model Umum | > 7 miliar parameter | Seri Model Umum "Jiang Ziya" memiliki kemampuan untuk menerjemahkan, pemrograman, klasifikasi teks, ekstraksi informasi, abstrak, generasi copywriting, pertanyaan dan jawaban akal sehat, dan perhitungan matematika. |
| Taiyi | spesifik | Multimodal | 80 juta hingga 1 miliar parameter | Diterapkan pada adegan lintas-modal, termasuk pembuatan gambar teks, prediksi struktur protein, representasi teks-teks, dll. |
| Erlang Shen | Umum | Pemahaman bahasa | 90 juta hingga 3,9 miliar parameter | Menangani tugas pemahaman, memiliki model taruhan Cina terbesar saat open source, mencapai puncak beberapaclue dan nol pada tahun 2021 |
| Wen Zhong | Umum | Generasi Bahasa | 100 juta hingga 3,5 miliar parameter | Berfokus pada tugas pembuatan, menyediakan model generasi dengan parameter yang berbeda, seperti GPT2, dll. |
| Penerangan | Umum | Konversi bahasa | 70 juta hingga 5 miliar parameter | Tangani berbagai tugas yang mengonversi dari teks sumber ke jenis teks target, seperti terjemahan mesin, ringkasan teks, dll. |
| Yu yuan | spesifik | bidang | 100 juta hingga 3,5 miliar parameter | Ini diterapkan pada bidang seperti medis, keuangan, hukum, pemrograman, dll. Memiliki model medis GPT2 open source terbesar saat ini |
| -Cobet ditentukan- | spesifik | mengeksplorasi | -tidak dikenal- | Kami berharap dapat mengembangkan model eksperimental yang terkait dengan NLP dengan berbagai perusahaan teknologi dan universitas. Saat ini: Raja Wen dari Zhou |
Unduh Tautan Model Investasi Dewa
Investasi pelatihan model Dewa dan skrip kode yang menyempurnakan
Investasi Manual Pelatihan Model Dewa
Kemajuan yang signifikan dalam kecerdasan buatan telah menghasilkan banyak model hebat, terutama model dasar berdasarkan pra-pelatihan telah menjadi paradigma yang muncul. Model AI tradisional harus dilatih pada dataset besar khusus untuk satu atau beberapa skenario terbatas, sebaliknya, model yang mendasarinya dapat beradaptasi dengan berbagai tugas hilir. Model dasar menciptakan kemungkinan pendaratan AI dalam skenario sumber daya rendah.
Kami mengamati bahwa jumlah parameter dalam model ini tumbuh pada tingkat 10 kali per tahun. Pada tahun 2018, Bert hanya 100 juta dalam volume parameter, tetapi pada tahun 2020, volume parameter GPT-3 telah mencapai urutan 10 miliar. Karena tren yang menginspirasi ini, banyak tantangan canggih dalam kecerdasan buatan, terutama kemampuan generalisasi yang kuat, secara bertahap menjadi mungkin.
Model dasar saat ini, terutama model bahasa, didominasi oleh komunitas Inggris. Pada saat yang sama, sebagai bahasa lisan terbesar di dunia (di antara penutur asli), Cina tidak memiliki sumber daya penelitian yang sistematis, yang membuat kemajuan penelitian di bidang Cina sedikit lag dibandingkan dengan bahasa Inggris.
Dunia ini membutuhkan jawaban.
Untuk memecahkan masalah kemajuan penelitian yang tertinggal di bidang Cina dan kekurangan sumber daya penelitian yang serius, pada 22 November 2021, Shen Xiangyang, ketua Institute of Idea Research Institute, secara resmi diumumkan pada konferensi IDEA bahwa CHINCHK BERCH "akan diluncurkan-Ekosistem dasar yang dikemukakan oleh China, termasuk China, termasuk China, termasuk TPA TPA, termasuk China, termasuk China, termasuk China, termasuk China, termasuk China, termasuk China, termasuk China, termasuk TPA TPA-DOMPERKS, FENGARKS, TOKICE TOPLASS TOKSICE TOPLING, TOBERKS TOPARKS TOKSI TOPLINGS TOKSI DENGAN TPA YANG DITEMUKAN DOMPEKS TOBER KECUALI, TERMASUK PREAD KECUAL. Set, dll. Tujuan kami adalah membangun ekosistem yang komprehensif, standar, berpusat pada pengguna. 
"Fengshen Bang Model" akan membuka serangkaian model besar yang terkait dengan NLP yang terkait dengan NLP dalam semua aspek. Ada tugas penelitian yang luas di komunitas NLP, yang dapat dibagi menjadi dua kategori: tugas umum dan khusus. Yang pertama termasuk pemahaman bahasa alami (NLU), generasi bahasa alami (NLG) dan tugas konversi bahasa alami (NLT). Yang terakhir mencakup tugas-tugas seperti multimodal, khusus domain, dll. Kami mempertimbangkan semua tugas ini dan menyediakan model terkait yang disesuaikan dengan tugas hilir, yang memudahkan pengguna dengan sumber daya komputasi terbatas untuk menggunakan model dasar kami. Dan kami berjanji untuk terus meningkatkan model -model ini dan terus mengintegrasikan data terbaru dan algoritma pelatihan terbaru. Melalui upaya Idea Research Institute, kami akan membangun infrastruktur umum untuk kecerdasan kognitif Tiongkok, menghindari konstruksi duplikat, dan menghemat kekuatan komputasi untuk seluruh masyarakat.
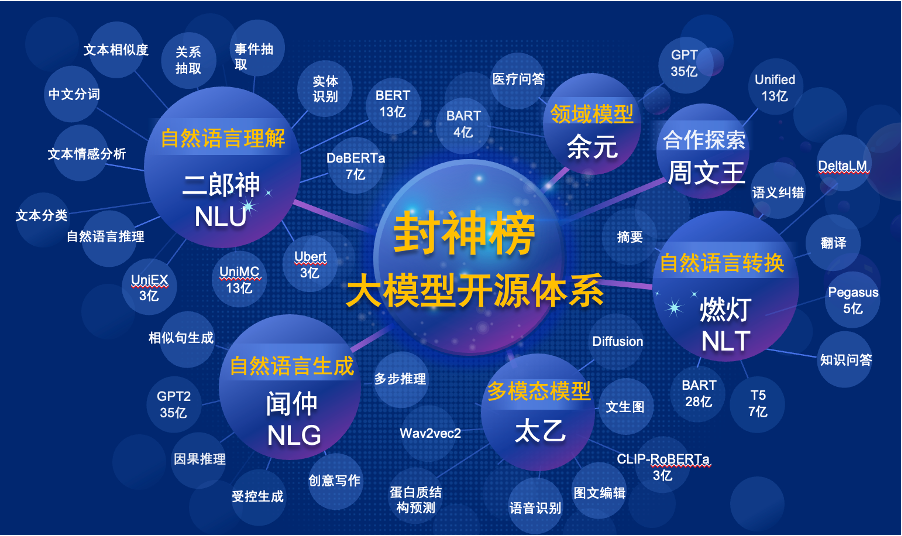
Pada saat yang sama, "Fengshen Bang" juga berharap bahwa berbagai perusahaan, universitas, dan lembaga akan bergabung dengan rencana open source ini dan bersama-sama membangun sistem sumber terbuka skala besar. Di masa depan, ketika kita membutuhkan model pra-terlatih baru, pertama-tama kita harus memilih yang terdekat dari model open source ini, melanjutkan pelatihan, dan kemudian open source model baru kembali ke sistem ini. Dengan cara ini, semua orang bisa mendapatkan model mereka sendiri dengan daya komputasi paling sedikit, dan sistem model besar open source juga bisa menjadi lebih besar dan lebih besar.

Untuk memiliki pengalaman yang lebih baik, merangkul komunitas open source, semua model investigasi para dewa dikonversi dan disinkronkan ke komunitas pelukan. Anda dapat dengan mudah menggunakan semua model investigasi para dewa dengan beberapa baris kode. Selamat datang di komunitas Huggingface Idea-CCNL untuk diunduh.
Seri Model Umum "Jiang Ziya" memiliki kemampuan untuk menerjemahkan, pemrograman, klasifikasi teks, ekstraksi informasi, abstrak, generasi copywriting, pertanyaan dan jawaban akal sehat, dan perhitungan matematika. Saat ini, model umum Jiang Ziya (V1/V1.1) telah menyelesaikan tiga tahap pelatihan: pra-pelatihan skala besar, pelatihan multi-tugas yang diawasi dan pembelajaran umpan balik manusia. Model seri Jiang Ziya termasuk model berikut:
Referensi Ziya-llama-13b-V1
Referensi Ziya_finenetune
Referensi Ziya_inference
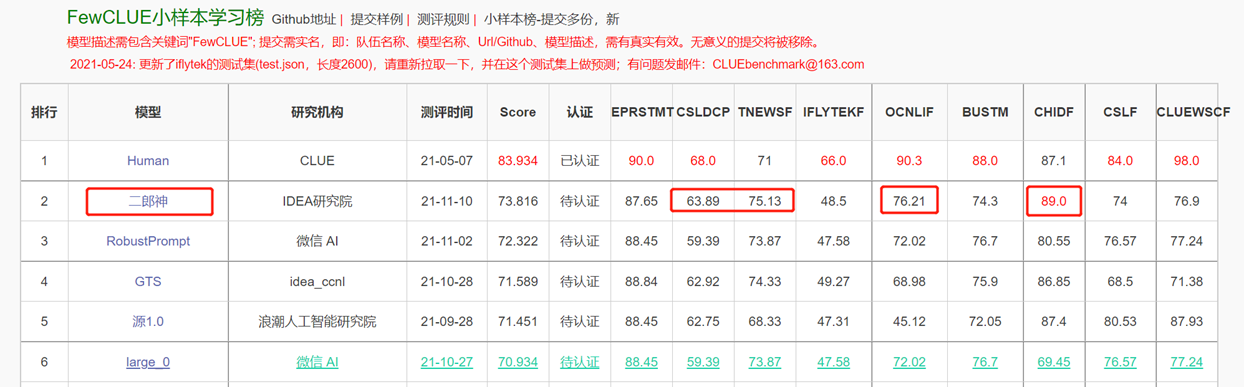
Model bahasa dua arah dengan struktur enkoder difokuskan pada pemecahan berbagai tugas pemahaman bahasa alami. Model besar Erlang Shen-1.3b dengan 1,3 miliar parameter menggunakan data 280g dan 32 A100 dilatih selama 14 hari. Ini adalah model Big Big Tiongkok open source terbesar. Pada 10 November 2021, itu menduduki puncak daftar tolok ukur evaluasi otoritatif untuk pemahaman bahasa Cina. Di antara mereka, CHID (Idiom Fill-in-the-blanks), Tnews (Klasifikasi Berita) melampaui manusia, CHID (Idiom Fill-in-the-Blanks), CSLDCP (Klasifikasi Literatur Disiplin), dan OCNLI (Alasan Bahasa Alami) memiliki tempat pertama dalam tugas tunggal, dan catatan pembelajaran sampel kecil disegarkan. Seri Erlang Shen akan terus mengoptimalkan dalam hal skala model, integrasi pengetahuan, bantuan tugas pengawasan, dll.
Pada 24 Januari 2022, Erlang Shen-Mrc menduduki puncak daftar Zeroclue dalam evaluasi pemahaman bahasa Cina Zeroclue. Di antara mereka, CSLDCP (Klasifikasi Sastra Disiplin), TNEWS (Klasifikasi Berita), IFLYTEK (Klasifikasi Deskripsi Aplikasi), CSL (Pengenalan Kata Kunci Abstrak), dan Cluewsc (mengacu pada pencernaan) adalah semua yang pertama. 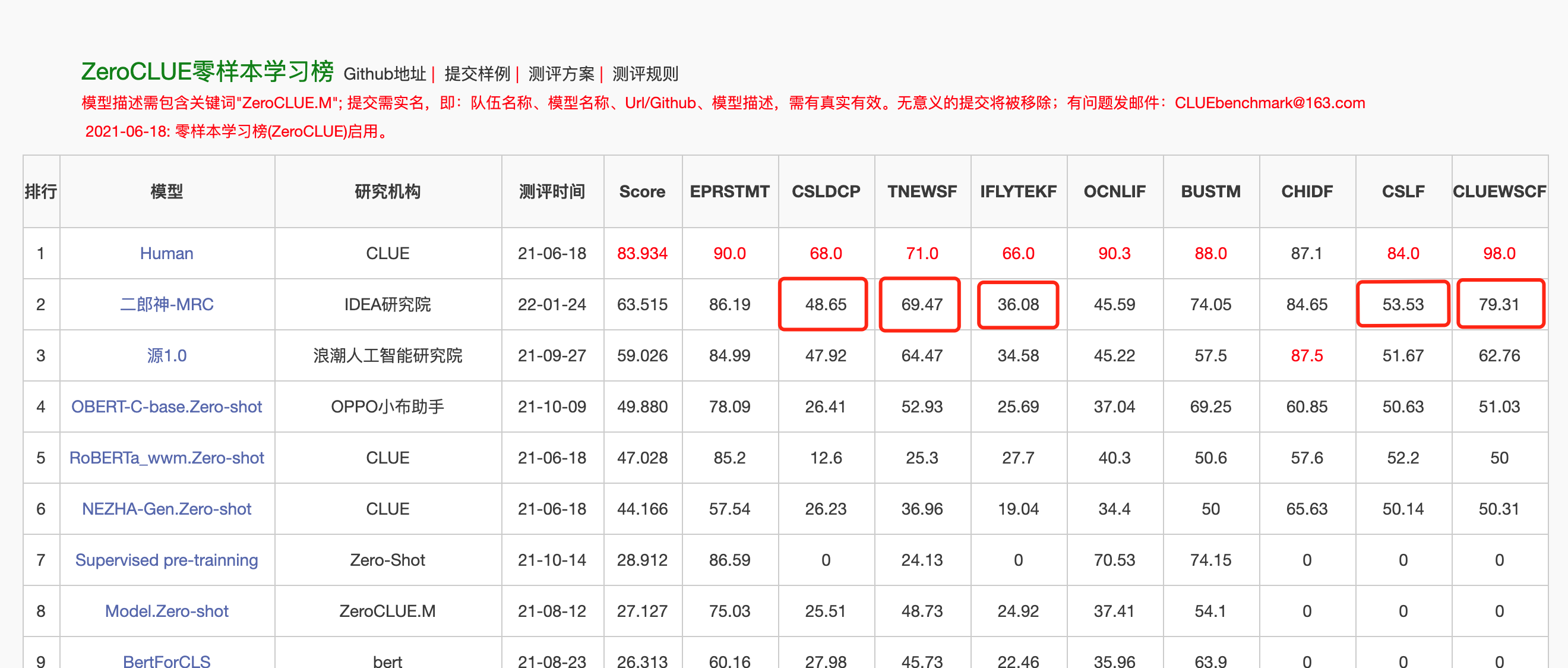
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )Untuk memfasilitasi pengembang untuk dengan cepat menggunakan model open source kami, berikut adalah skrip sampel Finetune untuk tugas hilir, menggunakan data tugas klasifikasi berita TNEWS tentang petunjuk, dan skrip dijalankan sebagai berikut. Di mana data_path adalah jalur data dan alamat unduhan data tugas TNEWS.
1. Pertama ubah parameter model_type dan pretrained_model_path dalam skrip sampel finetune finetune_classification.sh. Parameter lain seperti Batch_Size, data_dir, dll. Dapat dimodifikasi sesuai dengan perangkat Anda sendiri.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. Lalu jalankan:
sh finetune_classification.sh| Model | AFQMC | tnews | Iflytek | ocnli | cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| Roberta-wwm-Ext-Large | 0.7514 | 0,5872 | 0.6152 | 0.777 | 0.814 | 0.8914 | 0.86 |
| Erlangshen-Megatronbert-1.3b | 0.7608 | 0.5996 | 0.6234 | 0.7917 | 0.81 | 0.9243 | 0.872 |
Serangkaian model Taiyi terutama digunakan dalam skenario lintas modal, termasuk pembuatan gambar teks, prediksi struktur protein, representasi teks-teks, dll. Pada tanggal 1 November 2022, investasi para dewa membuka sumber versi Cina pertama dari model difusi stabil "difusi stabil taiyi".
Taiyi Stable Difusion Pure Chinese Versi
Taiyi Stable Difusion Chinese and English Bilingual Version
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| Kuda Besi dan Sungai Es datang untuk bermimpi, lukisan 3D. | Terbang mengalir turun tiga ribu kaki, lukisan minyak. | Punggung gadis, matahari terbenam, ilustrasi yang indah. |
|---|---|---|
 |  |  |
Prompt canggih
| Sungai es kuda besi datang ke mimpi, lukisan konsep, fiksi ilmiah, fantasi, 3d | Kota tepi laut China, fiksi ilmiah, indera futuristik, keindahan, ilustrasi. | Pria itu berada di lampu redup, dengan warna -warna cerah dan gaya kuno, karya ilustrator senior, dan wallpaper desktop HD. |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambbooth
Untuk memungkinkan semua orang memanfaatkan model besar Fengshen Bang dan berpartisipasi dalam pelatihan berkelanjutan dari model besar dan aplikasi hilir, kami secara bersamaan membuka sumber kerangka kerja fengshen yang berpusat pada pengguna. Untuk detailnya, silakan lihat: Kerangka kerja Fengshen (Fengshen).
Kami merujuk pada kerangka kerja open source yang sangat baik seperti HuggingFace, Megatron-LM, Pytorch-Lightning, dan Deepspeed. Dikombinasikan dengan karakteristik bidang NLP, Pytorch-Lightning Fengshen yang didesain ulang untuk pipa dengan Pytorch sebagai kerangka dasar. Fengshen dapat digunakan untuk pra-pelatihan model besar (10 miliar parameter tingkat) berdasarkan data besar (data tingkat TB) dan penyempurnaan berbagai tugas hilir. Pengguna dapat dengan mudah melakukan pelatihan terdistribusi dan menyimpan memori video melalui konfigurasi, lebih fokus pada implementasi model dan inovasi. Pada saat yang sama, Fengshen juga dapat secara langsung menggunakan struktur model di Huggingface untuk pelatihan lanjutan, yang memfasilitasi pengguna untuk memigrasikan model domain. Fengshen memberikan kode sumber yang kaya dan nyata dan contoh -contoh untuk penerapan model open source dan model Fengshen Bang. Dengan pelatihan dan penerapan model Fengshen Bang, kami akan terus mengoptimalkan kerangka kerja Fengshen, jadi tetaplah disini.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .Kami menyediakan pelabuhan sederhana yang mencakup lingkungan obor dan cuda untuk menjalankan kerangka kerja kami.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦Kerangka kerja investasi saat ini disesuaikan dengan pipa untuk berbagai tugas hilir, dan mendukung awal satu klik dari prediksi dan finetuning pada baris perintah. Ambil klasifikasi teks sebagai contoh
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpMulailah dalam tiga menit
Seri Investasi dari Gods dimulai dengan paralelisme data
Seri Investasi dari Gods adalah waktu untuk mempercepat pelatihan Anda
Pra-Pelatihan Model Pegasus Tiongkok dalam Seri Investasi Dewa
Seri Daftar Dewa: Finetune Erlang Shen secara tidak sengaja memenangkan tempat pertama
Seri Investasi Gods: dengan cepat membangun demo algoritma Anda
2022 Kompetisi Inovasi Kecerdasan Buatan Dunia AIWIN: Solusi Kejuaraan Track Multitasking Sampel Kecil
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
Tim Teknis CCNL dari Idea Research Institute telah menciptakan grup diskusi open source untuk Investastion of the Gods. Kami akan memperbarui dan merilis model baru dan serangkaian artikel dalam grup diskusi dari waktu ke waktu. Silakan pindai kode QR di bawah ini atau cari "Fengshenbang-LM" di WeChat untuk menambahkan asisten ke ruang Fengshen untuk bergabung dengan grup untuk berkomunikasi!

Kami juga terus merekrut orang, dipersilakan untuk mengirimkan resume kami!

Lisensi Apache 2.0


