Fengshenbang LM
1.0.0
จีน | ภาษาอังกฤษ
Fengshenbang 1.0 : การลงทุนของแผนโอเพ่นซอร์ส 1.0 กระดาษสองภาษาจีนและอังกฤษมีวัตถุประสงค์เพื่อเป็นโครงสร้างพื้นฐานของข่าวกรองความรู้ความเข้าใจของจีน
Biobart : แบบจำลองภาษากำเนิดสำหรับสาขาวิชาชีวการแพทย์ที่จัดทำโดยมหาวิทยาลัย Tsinghua และสถาบันวิจัยแนวคิด (
BioNLP 2022)
UNIMC : โมเดล Unified ตามชุดข้อมูลฉลากในสถานการณ์ศูนย์ (
EMNLP 2022)
FMIT : แบบจำลองการจดจำเอนทิตีหอคอยเดี่ยวแบบเดี่ยวตามการเข้ารหัสตำแหน่งสัมพัทธ์ (
COLING 2022)
Uniex : รูปแบบการทำความเข้าใจภาษาธรรมชาติสำหรับงานสกัดแบบครบวงจร (
ACL 2023)
การแก้ปัญหาคำศัพท์ทางคณิตศาสตร์ผ่านการให้เหตุผลแบบความร่วมมือแบบจำลองภาษาที่เกิดขึ้น : การแก้ปัญหาทางคณิตศาสตร์โดยใช้กรอบการใช้เหตุผลร่วมกันสำหรับแบบจำลองภาษา (
ACL 2023)
การปรับแต่ง MVP : พารามิเตอร์คำถามสามัญสำนึกที่มีประสิทธิภาพและระบบคำตอบตามการดึงความรู้หลายมุมมอง (
ACL 2023)
| ชื่อซีรีส์ | ความต้องการ | งานที่เกี่ยวข้อง | มาตราส่วนพารามิเตอร์ | คำพูด |
|---|---|---|---|---|
| เจียง Ziya | ทั่วไป | รูปแบบทั่วไป | > พารามิเตอร์ 7 พันล้าน | ซีรีส์ "Jiang Ziya" แบบจำลองทั่วไปมีความสามารถในการแปลการเขียนโปรแกรมการจำแนกประเภทข้อความการสกัดข้อมูลบทคัดย่อการสร้างคำโฆษณาคำถามสามัญสำนึกคำถามและคำตอบและการคำนวณทางคณิตศาสตร์ |
| Taiyi | เฉพาะเจาะจง | หลายรูปแบบ | 80 ล้านถึง 1 พันล้านพารามิเตอร์ | นำไปใช้กับฉากข้ามรูปแบบรวมถึงการสร้างภาพข้อความการทำนายโครงสร้างโปรตีนการแสดงข้อความพูด ฯลฯ |
| Erlang Shen | ทั่วไป | ความเข้าใจภาษา | 90 ล้านถึง 3.9 พันล้านพารามิเตอร์ | จัดการกับงานทำความเข้าใจมีรูปแบบการเดิมพันจีนที่ใหญ่ที่สุดเมื่อโอเพ่นซอร์สไปถึงด้านบนของไม่กี่ตัวและ Zeroclue ในปี 2564 ในปี 2564 |
| เหวินจง | ทั่วไป | การสร้างภาษา | พารามิเตอร์ 100 ล้านถึง 3.5 พันล้าน | มุ่งเน้นไปที่การสร้างงานให้แบบจำลองหลายรุ่นที่มีพารามิเตอร์ที่แตกต่างกันเช่น GPT2 ฯลฯ |
| การส่องแสง | ทั่วไป | การแปลงภาษา | พารามิเตอร์ 70 ล้านถึง 5 พันล้าน | จัดการงานต่าง ๆ ที่แปลงจากข้อความต้นฉบับเป็นประเภทข้อความเป้าหมายเช่นการแปลเครื่องสรุปข้อความ ฯลฯ |
| หยูหยวน | เฉพาะเจาะจง | สนาม | พารามิเตอร์ 100 ล้านถึง 3.5 พันล้าน | มันถูกนำไปใช้กับสาขาต่างๆเช่นการแพทย์การเงินกฎหมายการเขียนโปรแกรม ฯลฯ มีรูปแบบการแพทย์โอเพนซอร์ส GPT2 ที่ใหญ่ที่สุดในปัจจุบัน |
| -พยายามกำหนด- | เฉพาะเจาะจง | สำรวจ | -ไม่ได้รู้จัก- | เราหวังว่าจะพัฒนารูปแบบการทดลองที่เกี่ยวข้องกับ NLP กับ บริษัท เทคโนโลยีและมหาวิทยาลัยต่างๆ ปัจจุบัน: King Wen of Zhou |
ดาวน์โหลดลิงค์ของโมเดล Insidefiture of Gods
การลงทุนของการฝึกอบรมแบบจำลองของเทพเจ้าและสคริปต์รหัสการปรับจูน
คู่มือการฝึกอบรมแบบจำลองของเทพเจ้า
ความก้าวหน้าที่สำคัญในปัญญาประดิษฐ์ได้สร้างโมเดลที่ยอดเยี่ยมมากมายโดยเฉพาะอย่างยิ่งโมเดลพื้นฐานที่ใช้การฝึกอบรมก่อนการฝึกอบรมได้กลายเป็นกระบวนทัศน์ที่เกิดขึ้นใหม่ โมเดล AI แบบดั้งเดิมจะต้องได้รับการฝึกฝนในชุดข้อมูลขนาดใหญ่เฉพาะสำหรับหนึ่งหรือหลายสถานการณ์ที่ จำกัด ในทางตรงกันข้ามโมเดลพื้นฐานสามารถปรับให้เข้ากับงานที่หลากหลาย โมเดลพื้นฐานสร้างความเป็นไปได้ของการลงจอด AI ในสถานการณ์ที่มีทรัพยากรต่ำ
เราสังเกตว่าปริมาณพารามิเตอร์ในโมเดลเหล่านี้เพิ่มขึ้นในอัตรา 10 ครั้งต่อปี ในปีพ. ศ. 2561 เบิร์ตมีเพียง 100 ล้านในปริมาณพารามิเตอร์ แต่ภายในปี 2563 ปริมาณพารามิเตอร์ของ GPT-3 ได้ถึงลำดับ 10 พันล้าน เนื่องจากเทรนด์ที่สร้างแรงบันดาลใจนี้ความท้าทายที่ทันสมัยหลายอย่างในปัญญาประดิษฐ์โดยเฉพาะอย่างยิ่งความสามารถในการวางนัยทั่วไปที่ทรงพลังจึงค่อยๆกลายเป็นไปได้
โมเดลพื้นฐานของวันนี้โดยเฉพาะแบบจำลองภาษากำลังถูกครอบงำโดยชุมชนภาษาอังกฤษ ในเวลาเดียวกันในฐานะที่เป็นภาษาพูดที่ใหญ่ที่สุดในโลก (ในหมู่เจ้าของภาษา) จีนขาดทรัพยากรการวิจัยอย่างเป็นระบบซึ่งทำให้ความคืบหน้าการวิจัยในสาขาจีนล่าช้าเล็กน้อยเมื่อเทียบกับภาษาอังกฤษ
โลกนี้ต้องการคำตอบ
เพื่อแก้ปัญหาความคืบหน้าการวิจัยล่าช้าในสาขาจีนและการขาดแคลนทรัพยากรการวิจัยอย่างรุนแรงเมื่อวันที่ 22 พฤศจิกายน 2564 Shen Xiangyang ประธานสถาบันการวิจัยสถาบันวิจัยความคิดประกาศอย่างเป็นทางการในการประชุม IDEA ว่า เป้าหมายของเราคือการสร้างระบบนิเวศที่ครอบคลุมเป็นมาตรฐานและมีผู้ใช้เป็นศูนย์กลาง
"โมเดล Fengshen Bang" จะเปิดแหล่งข้อมูลชุดขนาดใหญ่ที่ได้รับการฝึกอบรมมาก่อน NLP ในทุกด้าน มีงานวิจัยที่กว้างขวางในชุมชน NLP ซึ่งสามารถแบ่งออกเป็นสองประเภท: งานทั่วไปและพิเศษ อดีตรวมถึงการทำความเข้าใจภาษาธรรมชาติ (NLU) การสร้างภาษาธรรมชาติ (NLG) และงานการแปลงภาษาธรรมชาติ (NLT) หลังครอบคลุมงานเช่นมัลติโมดอลเฉพาะโดเมน ฯลฯ เราพิจารณางานเหล่านี้ทั้งหมดและให้แบบจำลองที่เกี่ยวข้องกับงานที่ได้รับการปรับแต่งในงานดาวน์สตรีมซึ่งทำให้ผู้ใช้ที่มีทรัพยากรคอมพิวเตอร์ จำกัด ใช้แบบจำลองพื้นฐานของเราได้ง่าย และเราสัญญาว่าจะอัพเกรดโมเดลเหล่านี้ต่อไปและรวมข้อมูลล่าสุดและอัลกอริทึมการฝึกอบรมล่าสุดอย่างต่อเนื่อง ด้วยความพยายามของสถาบันวิจัย IDEA เราจะสร้างโครงสร้างพื้นฐานทั่วไปสำหรับหน่วยข่าวกรองความรู้ความเข้าใจของจีนหลีกเลี่ยงการก่อสร้างที่ซ้ำกันและประหยัดพลังการคำนวณสำหรับทั้งสังคม
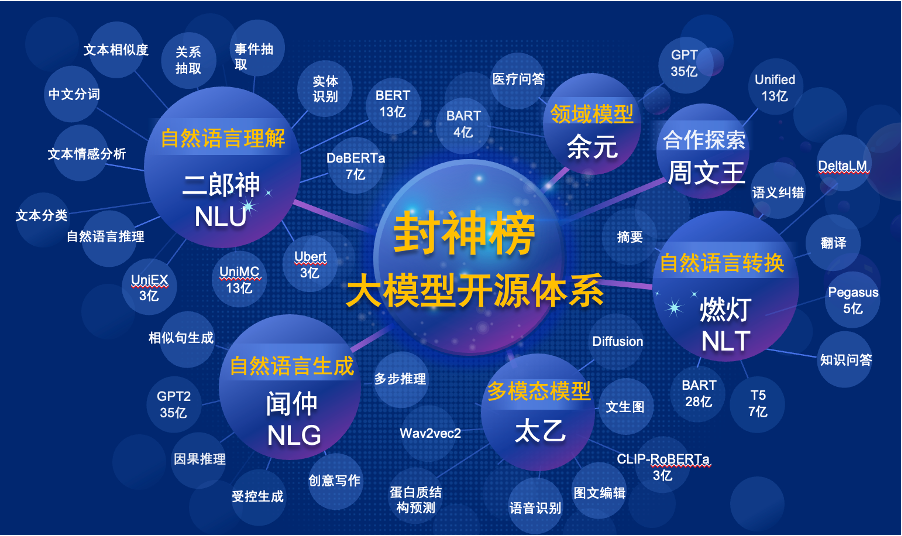
ในเวลาเดียวกัน "Fengshen Bang" ยังหวังว่า บริษัท ต่าง ๆ มหาวิทยาลัยและสถาบันต่าง ๆ จะเข้าร่วมแผนโอเพ่นซอร์สนี้และสร้างระบบโอเพนซอร์สขนาดใหญ่ร่วมกัน ในอนาคตเมื่อเราต้องการรูปแบบที่ผ่านการฝึกอบรมมาก่อนใหม่เราควรเลือกรุ่นที่ใกล้เคียงที่สุดจากโมเดลโอเพ่นซอร์สเหล่านี้ก่อนการฝึกอบรมต่อจากนั้นโอเพนซอร์สโมเดลใหม่กลับไปที่ระบบนี้ ด้วยวิธีนี้ทุกคนสามารถได้รับโมเดลของตัวเองด้วยพลังการคำนวณน้อยที่สุดและระบบโมเดลขนาดใหญ่โอเพนซอร์สก็สามารถใหญ่ขึ้นเรื่อย ๆ

เพื่อที่จะได้รับประสบการณ์ที่ดีขึ้นให้ยอมรับชุมชนโอเพนซอร์สทุกรูปแบบของการสอบสวนของเทพเจ้าจะถูกแปลงและซิงโครไนซ์กับชุมชน Huggingface คุณสามารถใช้แบบจำลองทั้งหมดของการสืบสวนของเทพเจ้าด้วยรหัสไม่กี่บรรทัด ยินดีต้อนรับสู่ชุมชน HuggingFace ของ Idea-CCNL เพื่อดาวน์โหลด
ซีรี่ส์ "Jiang Ziya" แบบจำลองทั่วไปมีความสามารถในการแปลการเขียนโปรแกรมการจำแนกประเภทข้อความการสกัดข้อมูลบทคัดย่อการสร้างคำโฆษณาคำถามสามัญสำนึกคำถามและคำตอบและการคำนวณทางคณิตศาสตร์ ในปัจจุบันโมเดลทั่วไปของ Jiang Ziya (V1/V1.1) ได้เสร็จสิ้นการฝึกอบรมสามขั้นตอน: การฝึกอบรมก่อนการฝึกอบรมแบบหลายงานแบบหลายงานและการเรียนรู้ข้อเสนอแนะของมนุษย์ รุ่น Jiang Ziya Series มีรุ่นต่อไปนี้:
อ้างอิง Ziya-llama-13b-v1
อ้างอิง ziya_finenetune
อ้างอิง ziya_inference
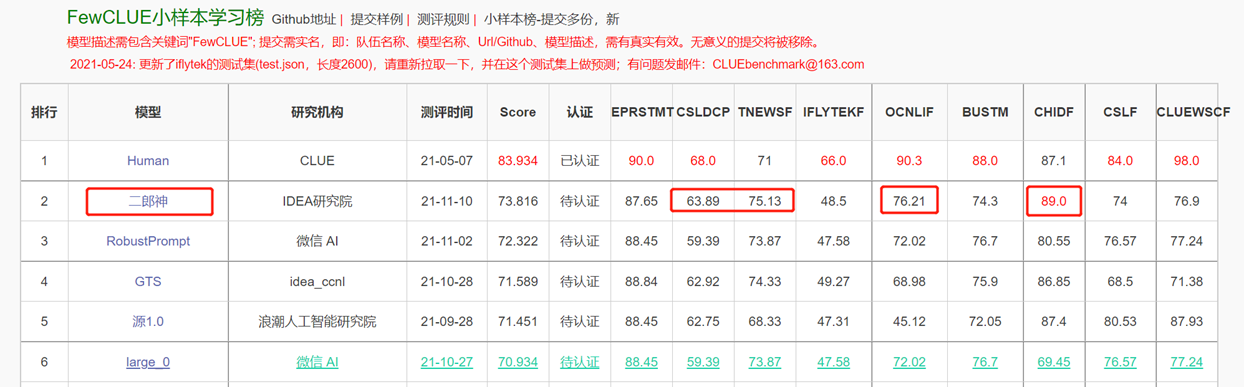
แบบจำลองภาษาสองทางที่มีโครงสร้างเข้ารหัสมุ่งเน้นไปที่การแก้ปัญหาความเข้าใจภาษาธรรมชาติที่หลากหลาย Erlang Shen-1.3b รุ่นใหญ่ที่มีพารามิเตอร์ 1.3 พันล้านใช้ข้อมูล 280 กรัมและ 32 A100s ได้รับการฝึกฝนเป็นเวลา 14 วัน มันเป็นรุ่นใหญ่ที่ใหญ่ที่สุดของจีนเบิร์ตเบิร์ต เมื่อวันที่ 10 พฤศจิกายน 2564 มียอดเกณฑ์มาตรฐานการประเมินที่เชื่อถือได้สำหรับการทำความเข้าใจภาษาจีน ในหมู่พวกเขา chid (สำนวนที่เติมในช่องว่าง), tnews (การจำแนกข่าว) เหนือกว่ามนุษย์, chid (สำนวนการเติมในช่องว่าง), CSLDCP (การจำแนกวรรณกรรมวินัย) และ OCNLI (การใช้เหตุผลภาษาธรรมชาติ) ซีรี่ส์ Erlang Shen จะยังคงปรับให้เหมาะสมในแง่ของมาตราส่วนแบบจำลองการรวมความรู้การช่วยเหลืองานด้านการกำกับดูแล ฯลฯ
เมื่อวันที่ 24 มกราคม 2565 Erlang Shen-MRC ได้เพิ่มรายการ Zeroclue ในการประเมินภาษาจีนการประเมิน Zeroclue ในหมู่พวกเขา CSLDCP (การจำแนกวรรณกรรมวินัย), TNEWS (การจำแนกข่าว), iflytek (การจำแนกคำอธิบายแอปพลิเคชัน), CSL (การจดจำคำหลักนามธรรม) และ Cluewsc (หมายถึงการย่อยอาหาร) เป็นครั้งแรก 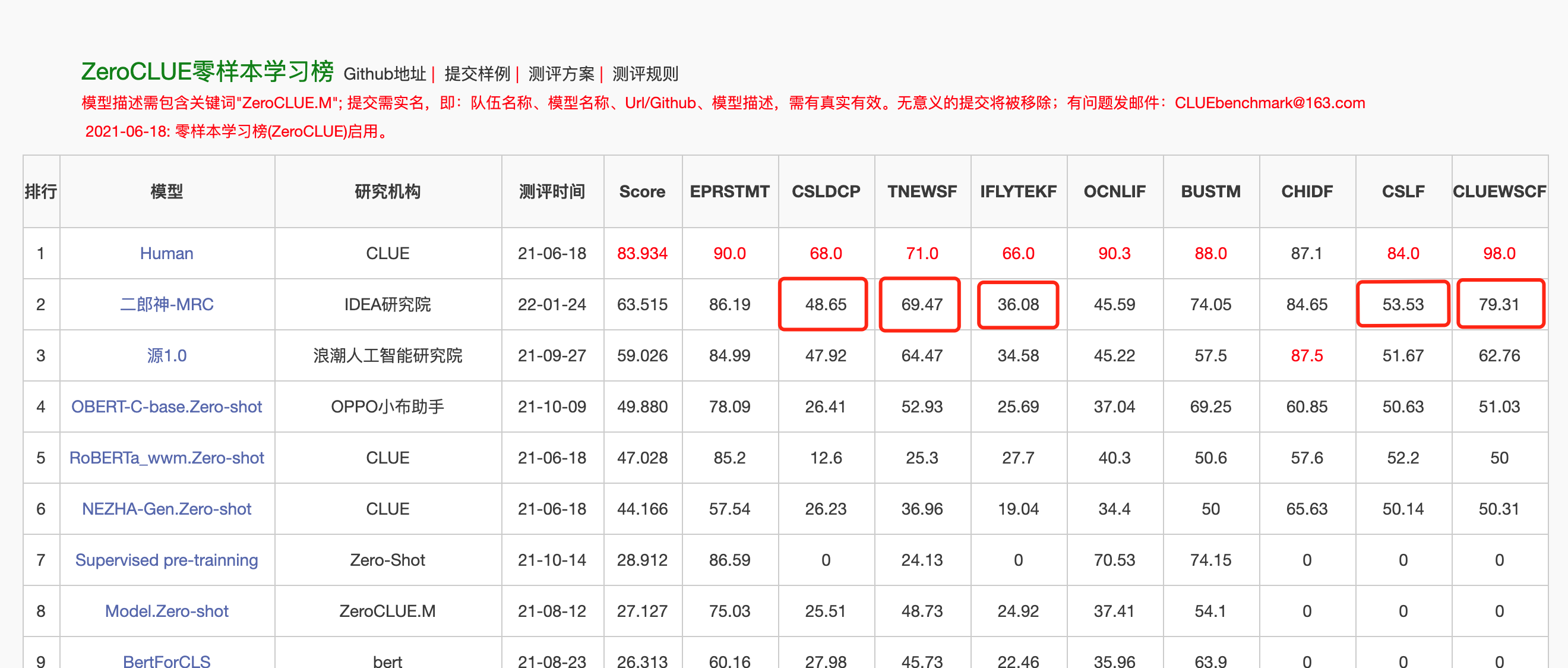
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )เพื่ออำนวยความสะดวกให้กับนักพัฒนาในการใช้โมเดลโอเพ่นซอร์สของเราอย่างรวดเร็วนี่คือสคริปต์ตัวอย่าง Finetune สำหรับงานดาวน์สตรีมโดยใช้ข้อมูลงานการจำแนกประเภท TNEWS ข่าวเกี่ยวกับเบาะแสและสคริปต์จะทำงานดังนี้ โดยที่ Data_Path เป็นเส้นทางข้อมูลและที่อยู่ดาวน์โหลดของข้อมูลงาน TNEWS
1. แรกแก้ไขพารามิเตอร์ model_type และ pretrained_model_path ในสคริปต์ตัวอย่าง finetune finetune_classification.sh พารามิเตอร์อื่น ๆ เช่น batch_size, data_dir ฯลฯ สามารถแก้ไขได้ตามอุปกรณ์ของคุณเอง
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. จากนั้นเรียกใช้:
sh finetune_classification.sh| แบบอย่าง | AFQMC | tnews | iflytek | ocnli | cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| Roberta-WWM-Ext-Large | 0.7514 | 0.5872 | 0.6152 | 0.777 | 0.814 | 0.8914 | 0.86 |
| Erlangshen-Megatronbert -1.3b | 0.7608 | 0.5996 | 0.6234 | 0.7917 | 0.81 | 0.9243 | 0.872 |
ชุดของแบบจำลอง Taiyi ส่วนใหญ่จะใช้ในสถานการณ์ข้ามรูปแบบรวมถึงการสร้างภาพข้อความการทำนายโครงสร้างโปรตีนการเป็นตัวแทนข้อความพูด ฯลฯ ในวันที่ 1 พฤศจิกายน 2565 การลงทุนของเทพเจ้าที่เปิดแหล่งที่มาของแบบจำลองการแพร่กระจายที่มั่นคงของจีน
Taiyi การแพร่กระจายของ Taiyi Pure Pure จีน
Taiyi การแพร่กระจายที่มั่นคงจีนและภาษาอังกฤษสองภาษา
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| ม้าเหล็กและแม่น้ำน้ำแข็งมาถึงความฝันภาพวาด 3 มิติ | การบินไหลลงมาสามพันฟุตซึ่งเป็นภาพวาดสีน้ำมัน | หลังของหญิงสาวพระอาทิตย์ตกภาพประกอบที่สวยงาม |
|---|---|---|
 |  |  |
พรอมต์ขั้นสูง
| Iron Horse Ice River มาสู่ความฝันภาพวาดแนวคิดนิยายวิทยาศาสตร์แฟนตาซี 3D | เมืองริมทะเลของจีนนิยายวิทยาศาสตร์ความรู้สึกแห่งอนาคตความงามภาพประกอบ | ชายคนนั้นอยู่ในแสงสลัวที่มีสีสันสดใสและสไตล์โบราณทำงานโดยนักวาดภาพประกอบอาวุโสและวอลล์เปเปอร์ HD เดสก์ท็อป |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
เพื่อให้ทุกคนใช้ประโยชน์จากรุ่น Fengshen Bang Big และมีส่วนร่วมในการฝึกอบรมอย่างต่อเนื่องของโมเดลขนาดใหญ่และแอพพลิเคชั่นปลายน้ำ สำหรับรายละเอียดโปรดดู: Framework Fengshen (Fengshen)
เราอ้างถึงเฟรมเวิร์กโอเพ่นซอร์สที่ยอดเยี่ยมเช่น HuggingFace, Megatron-LM, Pytorch-Lightning และ Deepspeed เมื่อรวมกับลักษณะของฟิลด์ NLP, Fengshen ที่ออกแบบใหม่ Pytorch-Lightning ที่ออกแบบใหม่สำหรับไปป์ไลน์ที่มี pytorch เป็นเฟรมเวิร์กพื้นฐาน Fengshen สามารถใช้ในการฝึกอบรมแบบจำลองขนาดใหญ่ล่วงหน้า (พารามิเตอร์ระดับ 10 พันล้าน) ตามข้อมูลขนาดใหญ่ (ข้อมูลระดับ TB) และการปรับแต่งของงานดาวน์สตรีมต่างๆ ผู้ใช้สามารถทำการฝึกอบรมแบบกระจายและบันทึกหน่วยความจำวิดีโอผ่านการกำหนดค่าโดยเน้นไปที่การใช้งานแบบจำลองและนวัตกรรมมากขึ้น ในเวลาเดียวกัน Fengshen ยังสามารถใช้โครงสร้างแบบจำลองโดยตรงใน HuggingFace สำหรับการฝึกอบรมอย่างต่อเนื่องซึ่งช่วยให้ผู้ใช้โยกย้ายโมเดลโดเมน Fengshen นำเสนอซอร์สโค้ดที่หลากหลายและแท้จริงและตัวอย่างสำหรับการประยุกต์ใช้โมเดลโอเพนซอร์สและโมเดลของ Fengshen Bang ด้วยการฝึกอบรมและการประยุกต์ใช้โมเดล Fengshen Bang เราจะยังคงปรับแต่งเฟรมเวิร์ก Fengshen ต่อไปดังนั้นคอยติดตาม
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .เราให้บริการนักเทียบท่าเรียบง่ายที่มีสภาพแวดล้อมไฟฉายและ CUDA เพื่อใช้งานกรอบของเรา
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦ขณะนี้กรอบการลงทุนถูกปรับให้เข้ากับท่อสำหรับงานดาวน์สตรีมต่างๆและรองรับการเริ่มต้นทำนายและการคาดการณ์บนบรรทัดคำสั่ง นำการจำแนกข้อความเป็นตัวอย่าง
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpเริ่มต้นในสามนาที
การลงทุนของซีรี่ส์ Gods เริ่มต้นด้วยการขนานของข้อมูล
การลงทุนของซีรี่ส์ Gods เป็นเวลาที่จะเร่งการฝึกอบรมของคุณ
ก่อนการฝึกอบรมของแบบจำลอง Pegasus จีนในซีรีย์การลงทุนของ Gods
ซีรี่ส์ Gods List: Finetune Erlang Shen ได้รับรางวัลแรกโดยไม่ได้ตั้งใจ
Series Investiture of Gods: สร้างตัวอย่างอัลกอริทึมของคุณอย่างรวดเร็ว
2022 Aiwin World Artificial Artificial Innovation Innovation การแข่งขัน: Small Symand Multitasking Track Championship Solution
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
CCNL Technical Technic of Idea Research Institute ได้สร้างกลุ่มการสนทนาโอเพ่นซอร์สสำหรับการลงทุนของเทพเจ้า เราจะอัปเดตและปล่อยรุ่นใหม่และชุดบทความในกลุ่มสนทนาเป็นครั้งคราว กรุณาสแกนรหัส QR ด้านล่างหรือค้นหา "Fengshenbang-LM" บน WeChat เพื่อเพิ่มผู้ช่วยในพื้นที่ Fengshen เพื่อเข้าร่วมกลุ่มเพื่อสื่อสาร!

เรายังคงรับสมัครคนต่อไปยินดีต้อนรับส่งประวัติย่อของเรา!

ใบอนุญาต Apache 2.0


