Fengshenbang LM
1.0.0
Китайский | Английский
Fengshenbang 1.0 : Инвестиция в План с открытым исходным кодом 1.0 Китайская и английская двуязычная бумага направлена на то, чтобы стать инфраструктурой китайского когнитивного интеллекта.
Biobart : модель генеративного языка для области биомедицины, предоставленной Университетом Цинхуа и Институтом исследований идеи. (
BioNLP 2022)
UNIMC : унифицированная модель, основанная на наборах данных метки в сценариях с нулевым выстрелом. (
EMNLP 2022)
FMIT : Модель распознавания единой башни с именем именованной сущностью на основе относительного кодирования позиции. (
COLING 2022)
Uniex : модель понимания естественного языка для единых задач экстракции. (
ACL 2023)
Решение задач по математике с помощью кооперативных рассуждений, индуцированных языковыми моделями : решение математических задач с использованием основы для совместной мышления для языковых моделей. (
ACL 2023)
MVP-подключение : параметр эффективной системы вопросов и ответов здравого смысла, основанная на многопользовательском поиске знаний. (
ACL 2023)
| Название серии | нуждаться | Применимые задачи | Шкала параметров | Примечание |
|---|---|---|---|---|
| Цзян Зия | Общий | Общая модель | > 7 миллиардов параметров | Общая модель серии «Цзян Зия» обладает способностью переводить, программирование, классификацию текста, извлечение информации, реферат, генерация копирайтинга, вопрос и ответ здравого смысла, а также математические расчеты. |
| Тайи | специфический | Мультимодальный | От 80 миллионов до 1 миллиарда параметров | Применяется к межмодальным сценам, включая генерацию текстовых изображений, прогноз структуры белка, представление речевого текста и т. Д. |
| Эрланг Шен | Общий | Понимание языка | От 90 миллионов до 3,9 миллиарда параметров | Обработка понимания задач, иметь самую большую китайскую модель ставок, когда с открытым исходным кодом, достигайте вершины MASTCLUE и ZeroClue в 2021 году. |
| Вэнь Чжун | Общий | Языковое поколение | От 100 миллионов до 3,5 миллиардов параметров | Сосредоточение внимания на задачах генерации, предоставляя несколько моделей генерации различными параметрами, такими как GPT2 и т. Д. |
| Освещение | Общий | Преобразование языка | От 70 миллионов до 5 миллиардов параметров | Обработка различных задач, которые преобразуют из исходного текста в целевой тип текста, такие как машинный перевод, резюме текста и т. Д. |
| Ю Юань | специфический | поле | От 100 миллионов до 3,5 миллиардов параметров | Он применяется к таким областям, как медицинское, финансы, право, программирование и т. Д. |
| -Полечить | специфический | исследовать | -неизвестный- | Мы надеемся разработать экспериментальные модели, связанные с НЛП с различными технологическими компаниями и университетами. В настоящее время: король Чжоу |
Скачать ссылку на модель инвестирования богов
Инвестиция в модель богов модельной подготовки и сценарии кодекса с тонкой настройкой
Руководство по обучению моделей инвестиций богов
Значительные достижения в области искусственного интеллекта создали много замечательных моделей, особенно основные модели, основанные на предварительном обучении, стали новой парадигмой. Традиционные модели искусственного интеллекта должны быть обучены выделенному огромному набору данных для одного или нескольких ограниченных сценариев, напротив, базовые модели могут адаптироваться к широкому диапазону нижестоящих задач. Основная модель создает возможность посадки ИИ в сценариях с низким ресурсом.
Мы наблюдаем, что количество параметров в этих моделях растет со скоростью 10 раз в год. В 2018 году BERT составлял всего 100 миллионов в объеме параметра, но к 2020 году объем параметров GPT-3 достиг порядка 10 миллиардов. Из-за этой вдохновляющей тенденции многие передовые проблемы в искусственном интеллекте, особенно мощные возможности обобщения, постепенно стали возможными.
Сегодняшние основные модели, особенно языковые модели, доминируют английским сообществом. В то же время, поскольку крупнейший в мире разговорной речь (среди носителей родных) Китай не хватает систематических исследовательских ресурсов, что делает исследования в области китайской области немного отставать по сравнению с английским языком.
Этот мир нуждается в ответе.
Чтобы решить проблемы отставания исследований в области исследований в области китайской области и серьезной нехватки исследовательских ресурсов, 22 ноября 2021 года, Шен Сянгьян, председатель Института исследований идей-основателей, официально объявленного на конференции «Идея», что «Fengshen Bangen» будут запущены в системе открытых исходных исходных исход и т. д. Наша цель-создать комплексную, стандартизированную, ориентированную на пользователь экосистему. 
«Модель Fengshen Bang» откроет серию предварительно обученных крупных моделей, связанных с NLP, во всех аспектах. В сообществе НЛП существуют обширные исследования, которые можно разделить на две категории: общие и особые задачи. Первый включает в себя задачи понимания естественного языка (NLU), генерации естественного языка (NLG) и естественного языка (NLT). Последние охватывают такие задачи, как мультимодальный, специфичный для доменов и т. Д. Мы рассматриваем все эти задачи и предоставляем связанные модели, настраиваемые на нижестоящие задачи, что облегчает пользователям с ограниченными вычислительными ресурсами использовать нашу базовую модель. И мы обещаем продолжать обновлять эти модели и постоянно интегрировать последние данные и последние алгоритмы обучения. Благодаря усилиям исследовательского института идей, мы будем создавать общую инфраструктуру для китайского когнитивного интеллекта, избежать дублирования конструкции и сохранить вычислительную силу для всего общества.
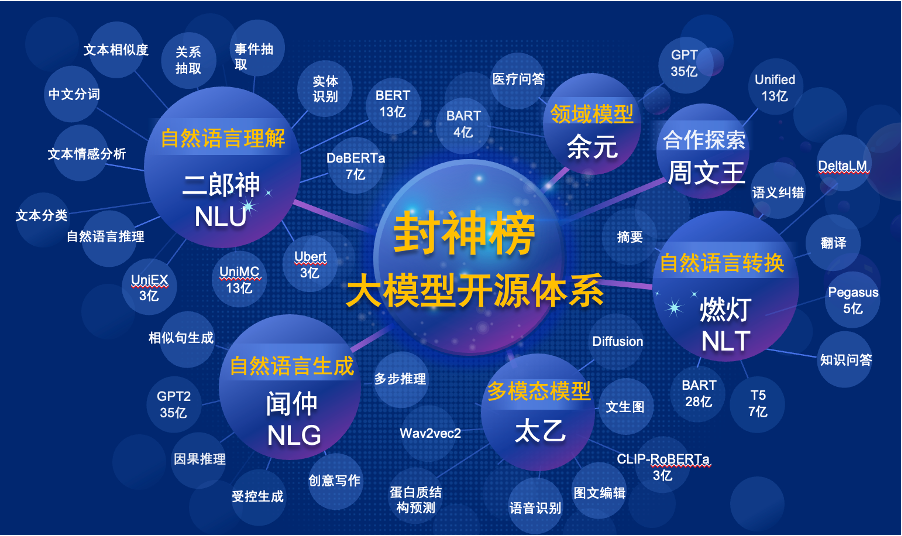
В то же время «Fengshen Bang» также надеется, что различные компании, университеты и учреждения присоединятся к этому плану с открытым исходным кодом и совместно создают крупномасштабную систему с открытым исходным кодом. В будущем, когда нам понадобится новая предварительно обученная модель, мы должны сначала выбрать ближайшую из этих моделей с открытым исходным кодом, продолжить обучение, а затем открыть новую модель обратно в эту систему. Таким образом, каждый может получить свою собственную модель с наименьшей вычислительной мощностью, а система Big Model с открытым исходным кодом также может стать больше и больше.

Чтобы получить лучший опыт, принять сообщество с открытым исходным кодом, все модели исследования богов преобразованы и синхронизируются в сообществе Huggingface. Вы можете легко использовать все модели исследования богов с помощью нескольких строк кода. Добро пожаловать в сообщество Huggingface Community of Idea-CCNL, чтобы загрузить.
Общая модель серии «Цзян Зия» обладает способностью переводить, программирование, классификацию текста, извлечение информации, реферат, генерация копирайтинга, вопрос и ответ здравого смысла, а также математические расчеты. В настоящее время общая модель Цзян Зия (v1/v1.1) завершила три этапа обучения: крупномасштабное предварительное обучение, многозадачный контроль с тонкой настройкой и обучение обратной связи человека. Модели серии Jiang Ziya включают следующие модели:
Ссылка Ziya-Llama-13b-V1
Ссылка ziya_finenetune
Ссылка Ziya_infere
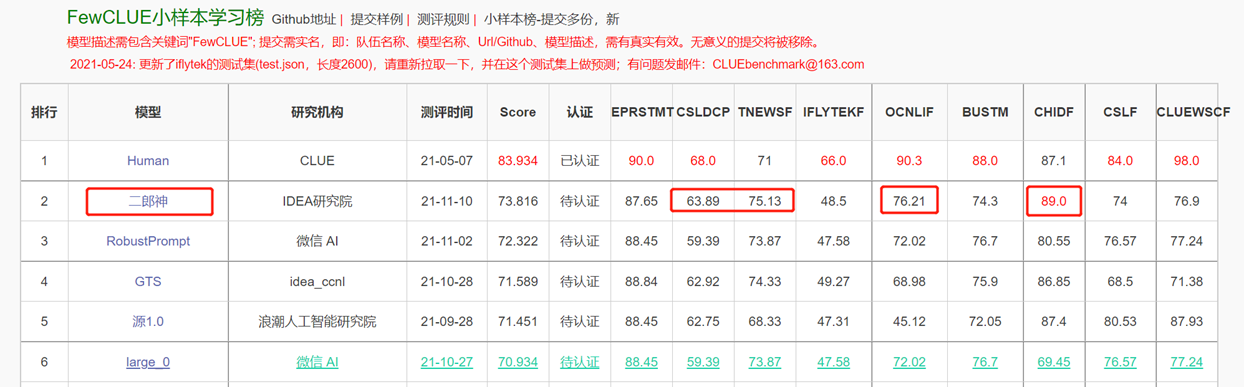
Двусторонняя языковая модель со структурой энкодера сосредоточена на решении различных задач по пониманию естественного языка. Большая модель Erlang Shen-1.3b с параметрами 1,3 миллиарда использует 280 г данных, а 32 A100 обучаются в течение 14 дней. Это самая большая модель BERT BERT BERT с открытым исходным кодом. 10 ноября 2021 года он возглавил список авторитетного эталона оценки для понимания китайского языка. Среди них, Чид (идиома заполняет блуд), Tnews (классификация новостей) превзошел людей, числа (идиома заполняет блыцы), CSLDCP (классификация литературы по дисциплине) и ocnli (рассуждения о естественном языке) занимают первое место в одиночных задачах, и небольшая образовательная запись обновлена. Серия Erlang Shen будет продолжать оптимизировать с точки зрения шкалы моделей, интеграции знаний, помощи в задаче надзора и т. Д.
24 января 2022 года Erlang Shen-MRC возглавил список нулевых значений в китайском языке, понимающий оценку нулевой нулевой оценки. Среди них CSLDCP (классификация литературы по дисциплине), TNEWS (классификация новостей), iflytek (классификация описания приложения), CSL (абстрактное распознавание ключевых слов) и ClueWSC (ссылка на пищеварение) - все первые. 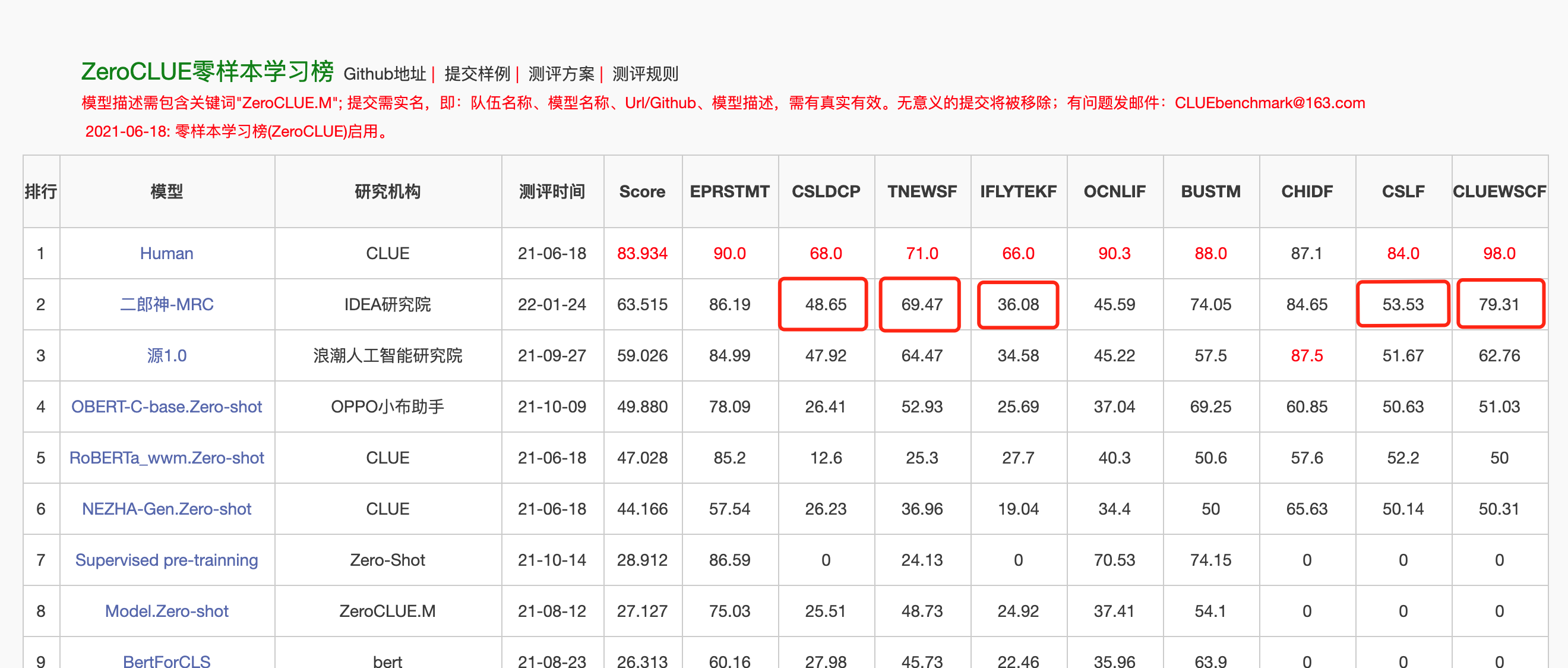
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )Чтобы облегчить разработчикам быстро использовать нашу модель с открытым исходным кодом, вот сценарий образца Finetune для нижестоящих задач, использующий данные задачи классификации TNEWS News для подсказки, и сценарий выполняется следующим образом. Где data_path - это путь данных и адрес загрузки данных задач TNEWS.
1. Сначала изменяйте параметры модели_тип и предварительно образованный Другие параметры, такие как batch_size, data_dir и т. Д., Могут быть изменены в соответствии с вашим собственным устройством.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. Затем беги:
sh finetune_classification.sh| Модель | AFQMC | Tnews | iflytek | ocnli | Cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| Роберта-WWM-Ext-Large | 0,7514 | 0,5872 | 0,6152 | 0,777 | 0,814 | 0,8914 | 0,86 |
| Erlangshen-Megatronbert-1.3b | 0,7608 | 0,5996 | 0,6234 | 0,7917 | 0,81 | 0,9243 | 0,872 |
Серия моделей Taiyi в основном используется в межмодальных сценариях, включая генерацию текстовых изображений, прогноз структуры белка, представление речевого текста и т. Д. 1 ноября 2022 года, инвестиция богов открыла источник первой китайской версии стабильной диффузионной модели «Тайй-стабильная диффузия».
Тайи стабильная диффузия чистая китайская версия
Стабильная диффузионная диффузия Taiyi китайская и английская двуязычная версия
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| Железная лошадь и ледяная река приходят во сне, 3D живопись. | Летающий течет вниз по три тысячи футов, картина маслом. | Девушка спина, закат, красивая иллюстрация. |
|---|---|---|
 |  |  |
Продвинутая подсказка
| Iron Horse Ice River приходит на мечту, концептуальную живопись, научную фантастику, фантазию, 3D | Китайский приморский город, научная фантастика, футуристический смысл, красота, иллюстрация. | Человек был в тусклых огнях, с яркими цветами и древним стилем, работами старших иллюстраторов и настольных обоев HD. |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
Чтобы позволить каждому хорошо использовать большую модель Fengshen Bang и участвовать в непрерывной подготовке приложений Big Model и Lowerstream, мы одновременно открыли, ориентированную на пользователя Fengshen Framework. Для получения подробной информации, пожалуйста, смотрите: Fengshen (Fengshen) Framework.
Мы ссылаемся на отличные рамки с открытым исходным кодом, такие как Hurgingface, Megatron-LM, Pytorch-Lightning и Deepspeed. В сочетании с характеристиками поля NLP, Pytorch-Lighting Mustesing Fengshen для трубопровода с Pytorch в качестве основной структуры. Fengshen может использоваться для предварительного обучения крупных моделей (параметры уровня 10 миллиардов) на основе массовых данных (данные на уровне туберкулеза) и тонкую настройку различных нижестоящих задач. Пользователи могут легко выполнять распределенную подготовку и сохранять видео память посредством конфигурации, сосредоточившись больше на реализации модели и инновациях. В то же время Fengshen также может напрямую использовать структуру модели в Huggingface для продолжения обучения, что облегчает пользователям мигрировать модели доменов. Fengshen предоставляет богатый и реальный исходный код и примеры для применения моделей с открытым исходным кодом и моделей Fengshen Bang. Благодаря обучению и применению модели Fengshen Bang мы будем продолжать оптимизировать феншен -структуру, так что следите за обновлениями.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .Мы предоставляем простой Docker, который включает в себя среды Torch и CUDA для запуска нашей структуры.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦Структура инвестирования в настоящее время адаптирована к конвейеру для различных нижестоящих задач и поддерживает начало прогнозирования и создания одного клика в командной строке. Возьмите текстовую классификацию в качестве примера
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpНачните через три минуты
Инвестиция серии богов начинается с параллелизма данных
Инвестиция в серию богов - время ускорить ваши тренировки
Предварительное обучение китайской модели Pegasus в инвестициях серии богов
Серия списка богов: Finetune Erlang Shen случайно выиграл первое место
Серия инвестиций богов: быстрое создание вашего алгоритма демонстрация
2022 AIWIN World Artificial Intelligence Innovation Competition: небольшая выборка по многозадачному чемпионату
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
Техническая команда CCNL Института исследований идеи создала дискуссионную группу с открытым исходным кодом для инвестирования богов. Мы будем время от времени обновлять и выпускать новые модели и серии статей в дискуссионной группе. Пожалуйста, сканируйте QR-код ниже или найдите «Fengshenbang-LM» на WeChat, чтобы добавить помощника в Fengshen Space, чтобы присоединиться к группе для общения!

Мы также продолжаем набирать людей, добро пожаловать, чтобы представить наши резюме!

Apache License 2.0


