Fengshenbang LM
1.0.0
Chino | Inglés
Fengshenbang 1.0 : La inversión del plan de código abierto 1.0 El papel bilingüe chino e inglés tiene como objetivo convertirse en la infraestructura de la inteligencia cognitiva china.
Biobart : modelo de lenguaje generativo para el campo de la biomedicina proporcionado por la Universidad de Tsinghua y el Instituto de Investigación de Idea. (
BioNLP 2022)
UNIMC : un modelo unificado basado en conjuntos de datos de etiquetas en escenarios de disparo cero. (
EMNLP 2022)
FMIT : modelo de reconocimiento de entidad multimodal de torre única basado en la codificación de posición relativa. (
COLING 2022)
UNIEX : un modelo de comprensión del lenguaje natural para tareas de extracción unificada. (
ACL 2023)
Resolver problemas de palabras matemáticas a través de modelos de lenguaje inducidos por razonamiento cooperativo : resolución de problemas matemáticos utilizando un marco de razonamiento colaborativo para modelos de idiomas. (
ACL 2023)
Autorización de MVP : un sistema de preguntas y respuestas de sentido común eficiente de parámetros basado en la recuperación de conocimiento multiperspectiva. (
ACL 2023)
| Nombre de la serie | necesidad | Tareas aplicables | Escala de parámetros | Observación |
|---|---|---|---|---|
| Jiang Ziya | General | Modelo general | > 7 mil millones de parámetros | La serie del modelo general "Jiang Ziya" tiene la capacidad de traducir, programación, clasificación de texto, extracción de información, resumen, generación de redacción, pregunta y respuesta de sentido común, y cálculos matemáticos. |
| Taiyi | específico | Multimodal | 80 millones a 1 mil millones de parámetros | Aplicado a escenas intermodales, incluida la generación de imágenes de texto, predicción de la estructura de proteínas, representación del texto del habla, etc. |
| Erlang Shen | General | Comprensión del lenguaje | 90 millones a 3.9 mil millones de parámetros | Manejar las tareas de comprensión, tenga el modelo de apuesta chino más grande cuando se abre de código abierto, llegue a la parte superior de pocoscles y zeroClue en 2021 |
| Wen zhong | General | Generación de idiomas | 100 millones a 3.5 mil millones de parámetros | Centrarse en las tareas de generación, proporcionando modelos de generación múltiple con diferentes parámetros, como GPT2, etc. |
| Iluminación | General | Conversión de idiomas | 70 millones a 5 mil millones de parámetros | Manejar varias tareas que se convierten del texto de origen al tipo de texto de destino, como traducción automática, resumen de texto, etc. |
| Yu Yuan | específico | campo | 100 millones a 3.5 mil millones de parámetros | Se aplica a campos como médico, finanzas, leyes, programación, etc. tiene el modelo médico GPT2 más grande de código abierto actualmente |
| -Tre para ser determinado | específico | explorar | -desconocido- | Esperamos desarrollar modelos experimentales relacionados con PNL con varias compañías de tecnología y universidades. Actualmente: King Wen de Zhou |
Descargar enlace del modelo Investiture of Gods
Investitura de la capacitación modelo de los dioses y scripts de código de ajuste fino
Manual de capacitación de modelos de investidura de dioses
Los avances significativos en la inteligencia artificial han producido muchos modelos excelentes, especialmente los modelos básicos basados en el entrenamiento previo se han convertido en un paradigma emergente. Los modelos tradicionales de IA deben estar entrenados en un gran conjunto de datos dedicado para uno o varios escenarios limitados, en contraste, los modelos subyacentes pueden adaptarse a una amplia gama de tareas aguas abajo. El modelo básico crea la posibilidad de aterrizar AI en escenarios de baja recursos.
Observamos que la cantidad de parámetros en estos modelos está creciendo a una tasa de 10 veces al año. En 2018, el Bert tenía solo 100 millones en el volumen de parámetros, pero para 2020, el volumen de parámetros de GPT-3 había alcanzado el orden de 10 mil millones. Debido a esta tendencia inspiradora, muchos desafíos de vanguardia en la inteligencia artificial, especialmente las poderosas capacidades de generalización, se han vuelto posibles gradualmente.
Los modelos básicos de hoy, especialmente los modelos de idiomas, están siendo dominados por la comunidad inglesa. Al mismo tiempo, como el idioma hablado más grande del mundo (entre los hablantes nativos), los chinos carecen de recursos de investigación sistemáticos, lo que hace que la investigación progrese en el campo de los chinos un poco en comparación con el inglés.
Este mundo necesita una respuesta.
In order to solve the problems of lagging research progress in the Chinese field and serious shortage of research resources, on November 22, 2021, Shen Xiangyang, chairman of the founding institute of IDEA Research Institute, officially announced at the IDEA conference that the "Fengshen Bang" open source system will be launched - a basic ecosystem driven by Chinese, including pre-trained large models, fine-tuning applications for specific tasks, benchmarks and data sets, etc. Our goal es construir un ecosistema integral, estandarizado y centrado en el usuario. 
El "Modelo Fengshen Bang" se abrirá en una serie de grandes modelos pre-entrenados relacionados con PNL en todos los aspectos. Hay extensas tareas de investigación en la comunidad de PNL, que se pueden dividir en dos categorías: tareas generales y especiales. El primero incluye la comprensión del lenguaje natural (NLU), la generación del lenguaje natural (NLG) y las tareas de conversión del lenguaje natural (NLT). Esta última cubre tareas como multimodal, específica de dominio, etc. Consideramos todas estas tareas y proporcionamos modelos relacionados ajustados en tareas aguas abajo, lo que facilita que los usuarios con recursos informáticos limitados utilicen nuestro modelo básico. Y prometemos continuar actualizando estos modelos e integrar continuamente los últimos datos y los últimos algoritmos de capacitación. A través de los esfuerzos del Instituto de Investigación de Idea, construiremos una infraestructura general para la inteligencia cognitiva china, evitaremos la construcción duplicada y ahorraremos el poder informático para toda la sociedad.
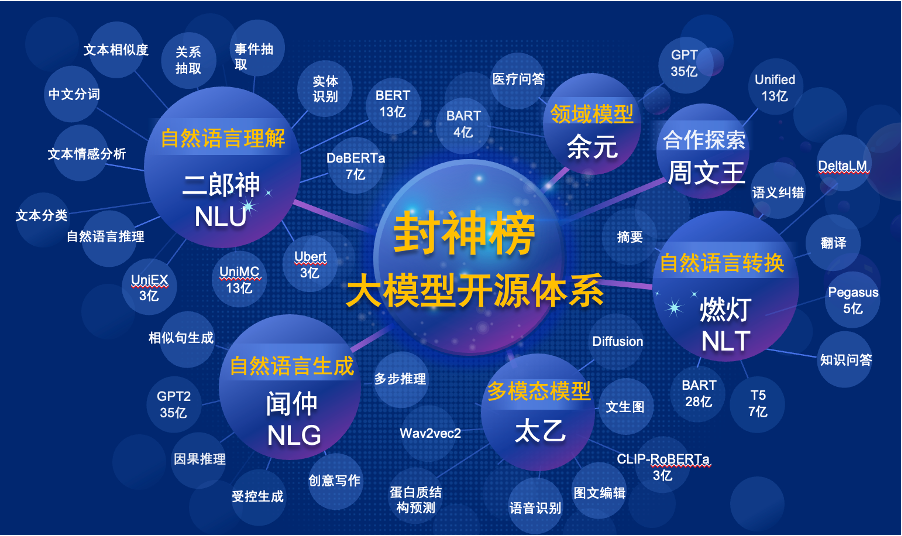
Al mismo tiempo, el "Fengshen Bang" también espera que varias empresas, universidades e instituciones se unan a este plan de código abierto y construyan conjuntamente un sistema de código abierto a gran escala. En el futuro, cuando necesitamos un nuevo modelo previamente capacitado, primero debemos seleccionar el más cercano de estos modelos de código abierto, continuar entrenando y luego el código abierto del nuevo modelo a este sistema. De esta manera, todos pueden obtener su propio modelo con la menor potencia informática, y el sistema de modelos de gran código abierto también puede ser cada vez más grande.

Para tener una mejor experiencia, adoptar la comunidad de código abierto, todos los modelos de la investigación de los dioses se convierten y sincronizan a la comunidad de Huggingface. Puede usar fácilmente todos los modelos de la investigación de los dioses con algunas líneas de código. Bienvenido a la comunidad Huggingface de Idea-CCNL para descargar.
La serie Modelo general "Jiang Ziya" tiene la capacidad de traducir, programar, clasificación de texto, extracción de información, resumen, generación de redacción, pregunta y respuesta de sentido común, y cálculo matemático. En la actualidad, el modelo general de Jiang Ziya (V1/V1.1) ha completado tres etapas de entrenamiento: pre-entrenamiento a gran escala, aprendizaje de retroalimentación de múltiples tareas y retroalimentación humana. Los modelos de la serie Jiang Ziya incluyen los siguientes modelos:
Referencia Ziya-llama-13b-V1
Referencia ziya_finenetune
Referencia ziya_inferencia
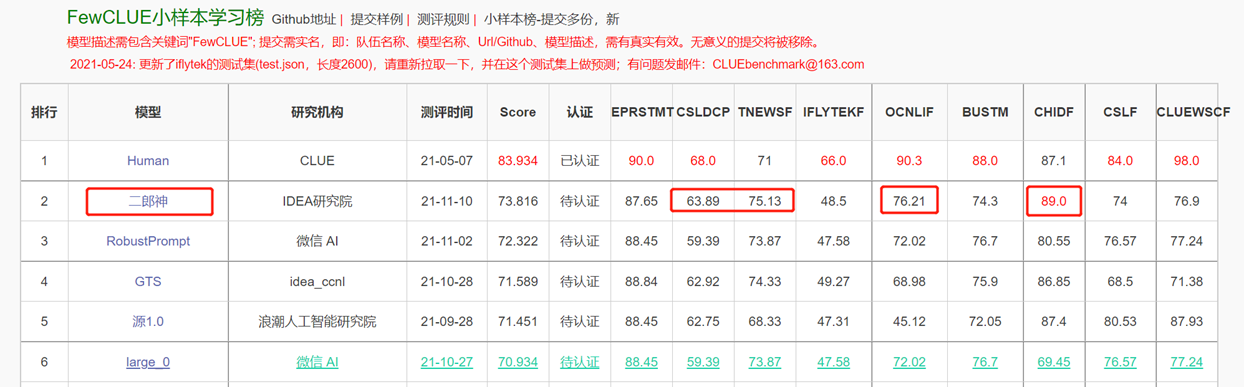
El modelo de lenguaje bidireccional con estructura del codificador se centra en resolver varias tareas de comprensión del lenguaje natural. El modelo Erlang Shen-1.3b Big Big con 1.3 mil millones de parámetros usa datos de 280 g y 32 A100 están entrenados durante 14 días. Es el modelo chino Bert Big Big más grande de código abierto. El 10 de noviembre de 2021, encabezó la lista del punto de referencia de evaluación autorizada para la comprensión del idioma chino. Entre ellos, CHID (Idiom relleno en blanco), TNews (clasificación de noticias) superó a los humanos, CHID (relleno de idiomas de idiomas en blanco), CSLDCP (clasificación de literatura disciplina) y Ocnli (razonamiento del lenguaje natural) tienen el primer lugar en tareas individuales, y el registro de aprendizaje de muestra pequeña está refrescada. La serie Erlang Shen continuará optimizándose en términos de escala de modelo, integración del conocimiento, asistencia de tareas de supervisión, etc.
El 24 de enero de 2022, Erlang Shen-MRC encabezó la lista de ZeroClue en la evaluación de comprensión del idioma chino ZeroClue. Entre ellos, CSLDCP (Clasificación de la literatura de disciplina), TNEWS (clasificación de noticias), IFLYTEK (clasificación de descripción de la aplicación), CSL (reconocimiento de palabras clave abstractas) y CLUEWSC (referencia a la digestión) son todos los primeros. 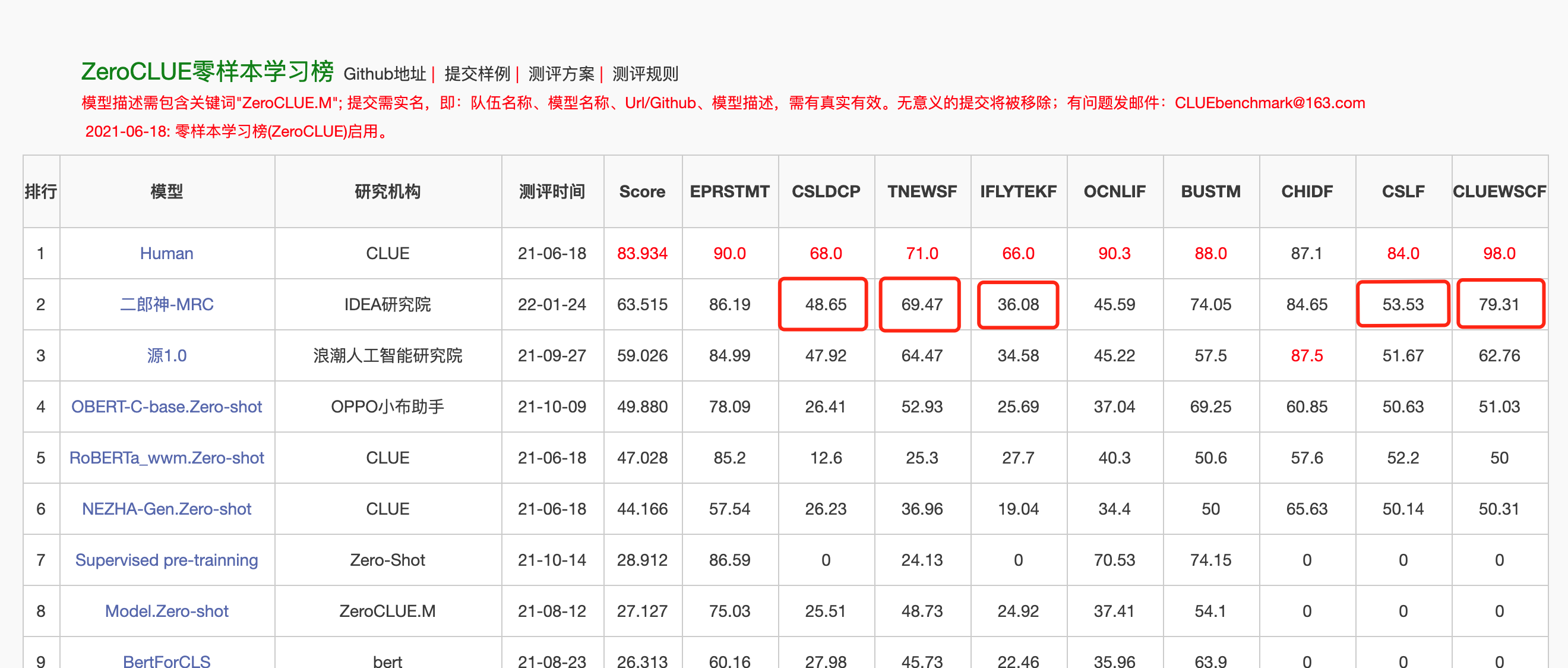
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )Para facilitar a los desarrolladores usar rápidamente nuestro modelo de código abierto, aquí hay un script de muestra de Finetune para tareas aguas abajo, utilizando los datos de tareas de clasificación de noticias TNEWS en la pista, y el script se ejecuta de la siguiente manera. Donde data_path es la ruta de datos y la dirección de descarga de los datos de la tarea TNEWS.
1. Primero modifique los parámetros Model_Type y Pretraned_Model_Path en el script de muestra Finetune finetune_classification.sh. Otros parámetros como Batch_Size, Data_Dir, etc. se pueden modificar de acuerdo con su propio dispositivo.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. Luego corre:
sh finetune_classification.sh| Modelo | AFQMC | TNEWS | iflytek | ocnli | cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| Roberta-wwm-ext-large | 0.7514 | 0.5872 | 0.6152 | 0.777 | 0.814 | 0.8914 | 0.86 |
| Erlangshen-megatronbert-1.3b | 0.7608 | 0.5996 | 0.6234 | 0.7917 | 0.81 | 0.9243 | 0.872 |
La serie de modelos Taiyi se usa principalmente en escenarios intermodales, incluida la generación de imágenes de texto, la predicción de la estructura de proteínas, la representación del texto del habla, etc. El 1 de noviembre de 2022, la investidura de los dioses abrió la fuente de la primera versión china del modelo de difusión estable "Difusión estable" Taiyi ".
Versión china pura de difusión estable taiyi
Versión bilingüe china e inglesa de difusión estable de Taiyi
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| Iron Horse y Ice River llegan a soñar, pintura en 3D. | El vuelo fluye por tres mil pies, una pintura al óleo. | La espalda de la niña, el atardecer, la hermosa ilustración. |
|---|---|---|
 |  |  |
Avanzado
| Iron Horse Ice River viene a los sueños, pintura conceptual, ciencia ficción, fantasía, 3D | Ciudad costera de China, ciencia ficción, sentido futurista, belleza, ilustración. | El hombre estaba en las luces tenues, con colores brillantes y estilo antiguo, obras de ilustradores senior y fondos de pantalla HD de escritorio. |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
Para permitir que todos aprovechen el modelo de Fengshen Bang Big y participen en la capacitación continua del modelo grande y las aplicaciones aguas abajo, simultáneamente abrimos el marco de Fengshen centrado en el usuario. Para más detalles, consulte: Marco Fengshen (Fengshen).
Nos referimos a excelentes marcos de código abierto como Huggingface, Megatron-LM, Pytorch-Lightning y Deepsede. Combinado con las características del campo NLP, Pytorch-Lightning rediseñó Fengshen para tuberías con Pytorch como marco básico. Fengshen se puede utilizar para pre-entrenamiento de modelos grandes (parámetros de 10 mil millones de niveles) basados en datos masivos (datos de nivel de TB) y ajuste de varias tareas aguas abajo. Los usuarios pueden realizar fácilmente capacitación distribuida y guardar la memoria de video a través de la configuración, centrándose más en la implementación y la innovación del modelo. Al mismo tiempo, Fengshen también puede usar directamente la estructura del modelo en Huggingface para una capacitación continua, lo que facilita a los usuarios a migrar modelos de dominio. Fengshen proporciona código fuente rico y real y ejemplos para la aplicación de modelos de código abierto y modelos de Fengshen Bang. Con la capacitación y aplicación del modelo Fengshen Bang, continuaremos optimizando el marco de Fengshen, así que estad atentos.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .Proporcionamos un Docker simple que incluye entornos de antorcha y Cuda para ejecutar nuestro marco.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦El marco de la inversión se adapta actualmente a la tubería para varias tareas aguas abajo, y admite el inicio de predicción y finecir de un solo clic en la línea de comando. Tome la clasificación de texto como ejemplo
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpEmpiece en tres minutos
La serie Investiture of the Gods comienza con el paralelismo de datos
La serie Investiture of the Gods es el momento de acelerar su entrenamiento
Prerreineado del modelo chino de Pegaso en la serie Investmity of the Gods
Serie de Listas de Gods: Finetune Erlang Shen ganó accidentalmente el primer lugar
Investiture of Gods Series: Construyendo rápidamente su algoritmo de demostración
2022 Competencia de innovación de inteligencia artificial de Aiwin World: Solución de campeonato de pista multitarea de muestra pequeña
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
El equipo técnico de CCNL del Instituto de Investigación Idea ha creado un grupo de discusión de código abierto para la investidura de los dioses. Actualizaremos y lanzaremos nuevos modelos y series de artículos en el grupo de discusión de vez en cuando. ¡Escanee el código QR a continuación o busque "Fengshenbang-LM" en WeChat para agregar el asistente al espacio de Fengshen para unirse al grupo para comunicarse!

También seguimos reclutando personas, ¡bienvenidos para enviar nuestros currículums!

Licencia de Apache 2.0


