Fengshenbang LM
1.0.0
중국어 | 영어
Fengshenbang 1.0 : 오픈 소스 계획 1.0 중국어 및 영어 이중 언어 논문의 투자는 중국인인지 지능의 인프라가되는 것을 목표로합니다.
Biobart : Tsinghua University 및 Idea Research Institute에서 제공하는 생체 의학 분야의 생성 언어 모델. (
BioNLP 2022)
UNIMC : 제로 샷 시나리오에서 레이블 데이터 세트를 기반으로 한 통합 모델. (
EMNLP 2022)
FMIT : 상대 위치 코딩을 기반으로 한 단일 타워 멀티 모달 명명 된 엔티티 인식 모델. (
COLING 2022)
UNIEX : 통합 추출 작업을위한 자연어 이해 모델. (
ACL 2023)
협력 적 추론 유도 언어 모델을 통한 수학 단어 문제 해결 : 언어 모델에 대한 공동 추론 프레임 워크를 사용하여 수학적 문제 해결. (
ACL 2023)
MVP 튜닝 : 다중 지식 지식 검색을 기반으로 한 매개 변수 효율적인 상식 질문 및 답변 시스템. (
ACL 2023)
| 시리즈 이름 | 필요 | 해당 작업 | 매개 변수 척도 | 주목 |
|---|---|---|---|---|
| Jiang Ziya | 일반적인 | 일반 모델 | > 70 억 매개 변수 | 일반 모델 "Jiang Ziya"시리즈는 번역, 프로그래밍, 텍스트 분류, 정보 추출, 추상, 카피 라이팅 생성, 상식 질문 및 답변 및 수학 계산 기능이 있습니다. |
| 타이 야 | 특정한 | 멀티 모달 | 8 천만에서 10 억 파라미터 | 텍스트 이미지 생성, 단백질 구조 예측, 음성 텍스트 표현 등을 포함한 교차 모달 장면에 적용됩니다. |
| Erlang Shen | 일반적인 | 언어 이해 | 9 천만에서 39 억 개의 매개 변수 | 작업 이해 작업 처리, 오픈 소스 일 때 가장 큰 중국 베팅 모델을 갖추고 2021 년에 소수의 클루와 Zeroclue에 도달하십시오. |
| 웬 잔 | 일반적인 | 언어 생성 | 1 억 ~ 35 억 매개 변수 | 생성 작업에 중점을두고 GPT2 등과 같은 다양한 매개 변수로 다중 세대 모델을 제공합니다. |
| 조명 | 일반적인 | 언어 변환 | 7 천만에서 50 억 파라미터 | 기계 번역, 텍스트 요약 등과 같은 소스 텍스트에서 대상 텍스트 유형으로 변환하는 다양한 작업을 처리합니다. |
| Yu Yuan | 특정한 | 필드 | 1 억 ~ 35 억 매개 변수 | 의료, 금융, 법률, 프로그래밍 등과 같은 분야에 적용됩니다. 가장 큰 오픈 소스 GPT2 의료 모델은 현재 |
| -결정할- | 특정한 | 탐구하다 | -알려지지 않은- | 우리는 다양한 기술 회사 및 대학과 NLP와 관련된 실험 모델을 개발하기를 희망합니다. 현재 : Zhou의 왕 |
신의 투자 모델의 링크를 다운로드하십시오
신의 모델 교육 및 미세 조정 코드 스크립트의 조사
신들 모델 훈련 매뉴얼의 조사
인공 지능의 상당한 발전으로 인해 많은 훌륭한 모델, 특히 사전 훈련을 기반으로 한 기본 모델은 새로운 패러다임이되었습니다. 전통적인 AI 모델은 하나 또는 여러 제한된 시나리오에 대한 전용 거대한 데이터 세트에 대해 교육을 받아야하며, 대조적으로, 기본 모델은 광범위한 다운 스트림 작업에 적응할 수 있습니다. 기본 모델은 AI가 낮은 자원 시나리오에서 착륙 할 가능성을 만듭니다.
우리는이 모델의 매개 변수의 양이 연간 10 배의 속도로 성장하고 있음을 관찰합니다. 2018 년에 Bert는 매개 변수량이 1 억 개에 불과했지만 2020 년까지 GPT-3의 매개 변수 부피는 100 억의 순서에 도달했습니다. 이러한 고무적인 추세로 인해 인공 지능, 특히 강력한 일반화 기능의 많은 최첨단 도전이 점차 가능해졌습니다.
오늘날의 기본 모델, 특히 언어 모델은 영어 커뮤니티가 지배하고 있습니다. 동시에, 세계 최대의 음성 언어 (원어민 중)와 같이 중국은 체계적인 연구 자원이 부족하여 중국 필드의 연구 진전이 영어에 비해 약간 지연됩니다.
이 세상에는 답이 필요합니다.
2021 년 11 월 22 일, 중국 분야에서의 연구 진행 상황과 심각한 연구 자원 부족의 문제를 해결하기 위해, 2021 년 11 월 22 일, 창립 아이디어 연구 연구소 (Idea Research Institute)의 회장 인 Shen Xiangyang은 공식적으로 아이디어 컨퍼런스에서 "Fengshen Bang"오픈 소스 시스템이 출시 될 것이라고 아이디어 컨퍼런스에서 공식적으로 발표했다. 우리의 목표는 포괄적이고 표준화 된 사용자 중심 생태계를 구축하는 것입니다. 
"Fengshen Bang Model"은 모든 측면에서 일련의 NLP 관련 미리 훈련 된 대형 모델을 오픈 할 것입니다. NLP 커뮤니티에는 광범위한 연구 작업이 있으며, 이는 일반 및 특별 작업의 두 가지 범주로 나눌 수 있습니다. 전자에는 자연 언어 이해 (NLU), 자연 언어 생성 (NLG) 및 자연 언어 변환 (NLT) 작업이 포함됩니다. 후자는 멀티 모달, 도메인 별 등과 같은 작업을 다룹니다. 우리는 이러한 모든 작업을 고려하고 다운 스트림 작업에 미세 조정 된 관련 모델을 제공하므로 컴퓨팅 리소스가 제한된 사용자가 기본 모델을 쉽게 사용할 수 있습니다. 또한 이러한 모델을 계속 업그레이드하고 최신 데이터와 최신 교육 알고리즘을 지속적으로 통합 할 것을 약속합니다. Idea Research Institute의 노력을 통해 중국인인지 지능을위한 일반 인프라를 구축하고, 중복 건설을 피하고, 전체 사회를위한 컴퓨팅 능력을 절약 할 것입니다.
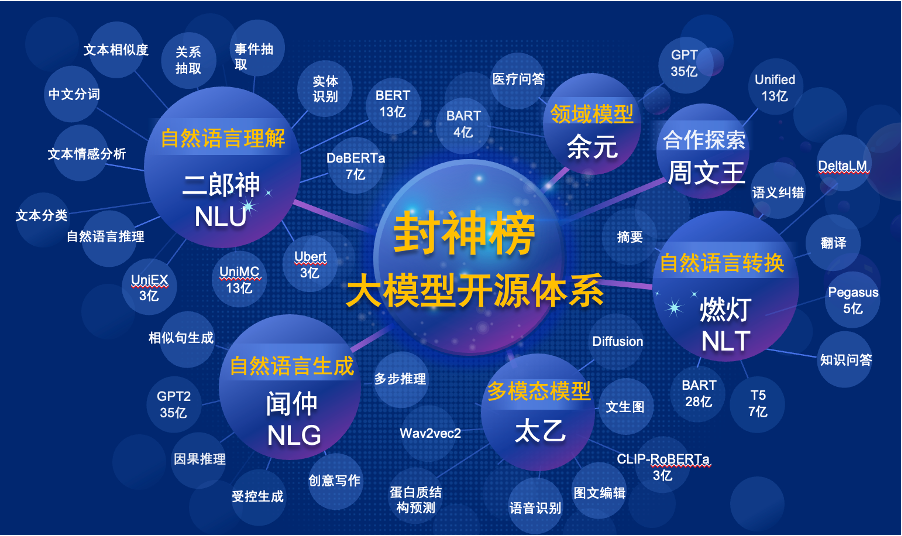
동시에 "Fengshen Bang"은 다양한 회사, 대학 및 기관 이이 오픈 소스 계획에 참여하고 공동으로 대규모 오픈 소스 시스템을 구축하기를 희망합니다. 앞으로 새로운 미리 훈련 된 모델이 필요할 때 먼저이 오픈 소스 모델에서 가장 가까운 모델을 선택하고 교육을 계속 한 다음이 시스템에 새 모델을 오픈 소스로 돌아와야합니다. 이런 식으로 모든 사람은 컴퓨팅 성능이 가장 적은 자체 모델을 얻을 수 있으며 오픈 소스 큰 모델 시스템도 점점 커질 수 있습니다.

더 나은 경험을하기 위해 오픈 소스 커뮤니티를 받아들이려면 신들의 조사의 모든 모델이 전환되고 Huggingface 커뮤니티와 동기화됩니다. 몇 줄의 코드로 신의 조사 모델을 쉽게 사용할 수 있습니다. Idea-CCNL의 Huggingface 커뮤니티에 오신 것을 환영합니다.
일반적인 모델 "Jiang Ziya"시리즈는 번역, 프로그래밍, 텍스트 분류, 정보 추출, 추상, 카피 라이팅 생성, 상식 질문 및 답변 및 수학적 계산 기능이 있습니다. 현재 Jiang Ziya의 일반 모델 (V1/V1.1)은 대규모 사전 훈련, 멀티 태스킹 감독 미세 조정 및 인간 피드백 학습의 3 단계 교육을 완료했습니다. Jiang Ziya 시리즈 모델에는 다음 모델이 포함됩니다.
참조 Ziya-llama-13B-v1
참조 ziya_finenetune
참조 ziya_inference
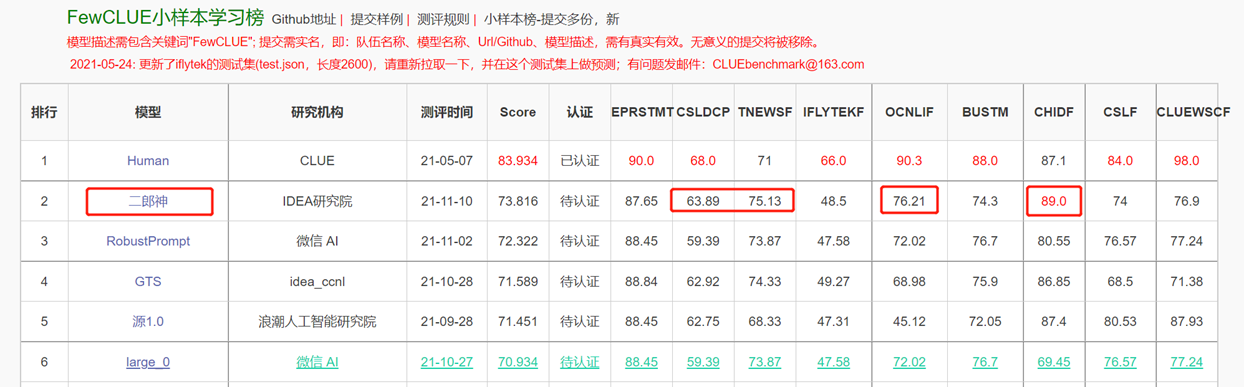
인코더 구조를 가진 양방향 언어 모델은 다양한 자연어 이해 작업을 해결하는 데 중점을 둡니다. 13 억 개의 매개 변수를 가진 Erlang Shen-1.3B 빅 모델은 280g 데이터를 사용하고 32 A100은 14 일 동안 훈련됩니다. 가장 큰 오픈 소스 중국어 버트 큰 모델입니다. 2021 년 11 월 10 일, 그것은 중국어 이해를위한 권위있는 평가 벤치 마크 목록을 1 위를 차지했습니다. 그중에서도 Chid (Idiom Fill-in-the-the-the-the-the-the-the-the-the-the-the-the-blanks), tnews (뉴스 분류) 인간을 능가하고 Chid (Idiom Fill-in-the-Blanks), CSLDCP (징계 문헌 분류) 및 OCNLI (자연 언어 추론)는 단일 작업에서 1 위를 차지하며 작은 샘플 학습 기록이 상쾌합니다. Erlang Shen 시리즈는 모델 척도, 지식 통합, 감독 작업 지원 등으로 계속 최적화됩니다.
2022 년 1 월 24 일, Erlang Shen-MRC는 중국어 이해 평가 Zeroclue에서 Zeroclue 목록을 1 위했습니다. 그중에서도 CSLDCP (징계 문헌 분류), TNEWS (뉴스 분류), IFLYTEK (응용 프로그램 설명 분류), CSL (초록 키워드 인식) 및 CluewSC (소화 참조)가 첫 번째입니다. 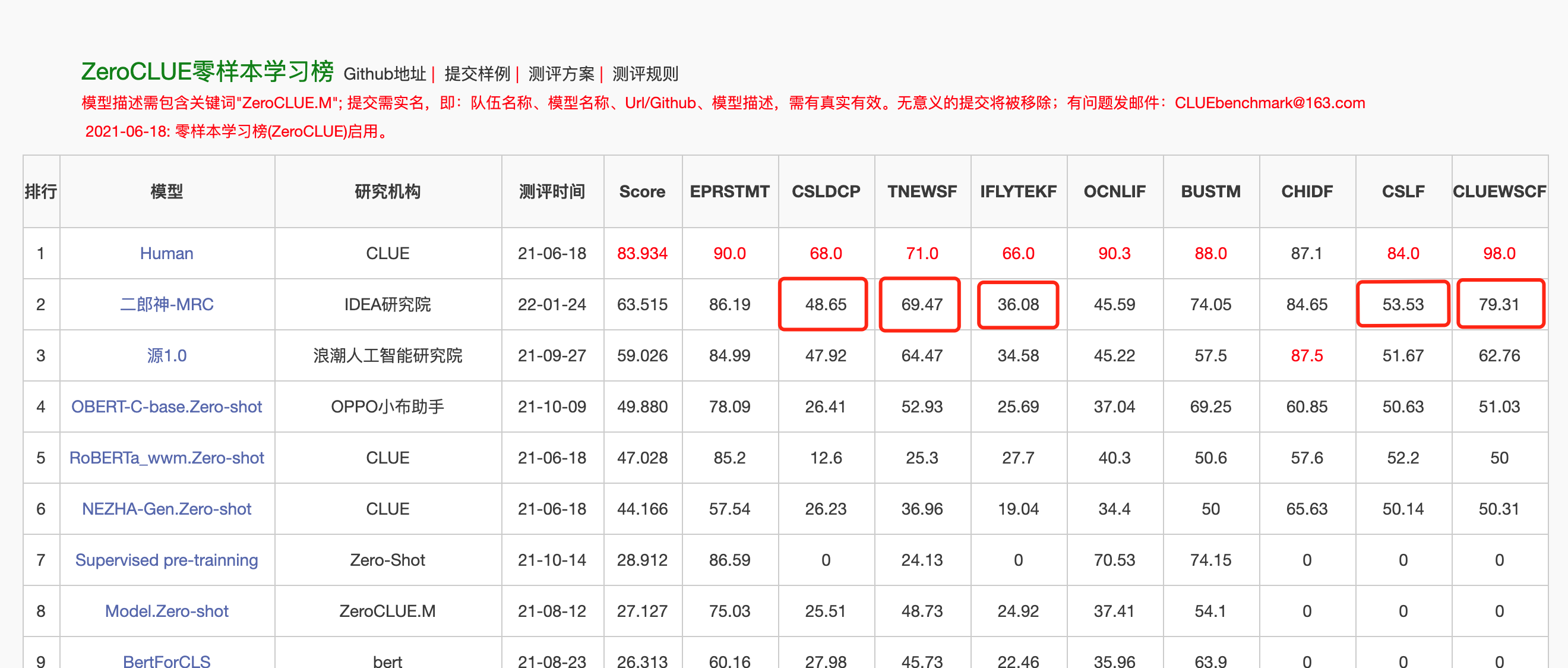
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )개발자가 오픈 소스 모델을 신속하게 사용하도록 촉진하기 위해 여기에 Tnews News Classification Task Data를 사용하여 다운 스트림 작업을위한 Finetune 샘플 스크립트가 다음과 같이 실행됩니다. 여기서 data_path는 tnews 작업 데이터의 데이터 경로 및 다운로드 주소입니다.
1. 먼저 Finetune 샘플 스크립트 Finetune_Classification.sh에서 model_type 및 pretrained_model_path 매개 변수를 수정하십시오. batch_size, data_dir 등과 같은 다른 매개 변수는 자신의 장치에 따라 수정할 수 있습니다.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. 그런 다음 실행 :
sh finetune_classification.sh| 모델 | AFQMC | tnews | Iflytek | ocnli | cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| Roberta-WWM-EXT-LARGE | 0.7514 | 0.5872 | 0.6152 | 0.777 | 0.814 | 0.8914 | 0.86 |
| Erlangshen-Megatronbert-1.3b | 0.7608 | 0.5996 | 0.6234 | 0.7917 | 0.81 | 0.9243 | 0.872 |
Taiyi 시리즈의 모델은 주로 텍스트 이미지 생성, 단백질 구조 예측, 음성 텍스트 표현 등을 포함한 교차 모달 시나리오에서 주로 사용됩니다. 2022 년 11 월 1 일, 신들의 투자는 안정적인 확산 모델의 첫 번째 중국어 버전 "Taiyi 안정 확산"의 원천을 열었습니다.
Taiyi 안정 확산 순수한 중국어 버전
Taiyi 안정된 확산 중국어 및 영어 이중 언어 버전
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| Iron Horse와 Ice River는 Dream, 3D 그림으로 온다. | 비행은 3 천 피트, 유화로 흐릅니다. | 소녀의 등, 일몰, 아름다운 삽화. |
|---|---|---|
 |  |  |
고급 프롬프트
| Iron Horse Ice River는 꿈, 컨셉 페인팅, 공상 과학, 판타지, 3d에 온다 | 중국의 해변 도시, 공상 과학, 미래의 의미, 아름다움, 일러스트레이션. | 그 남자는 밝은 색상과 고대 스타일의 희미한 조명에 있었고 선임 일러스트 레이터와 데스크탑 HD 배경 화면이 작용했습니다. |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
모든 사람이 Fengshen Bang Big Model을 잘 활용하고 대형 모델 및 다운 스트림 응용 프로그램의 지속적인 교육에 참여할 수 있도록 사용자 중심 Fengshen 프레임 워크를 동시에 오픈 소스입니다. 자세한 내용은 Fengshen (Fengshen) 프레임 워크를 참조하십시오.
우리는 Huggingf NLP 필드의 특성과 결합하여 Pytorch-Lightning Fengshen은 기본 프레임 워크로 Pytorch를 사용하여 Fengshen을 재 설계했습니다. Fengshen은 대규모 데이터 (TB 수준 데이터) 및 다양한 다운 스트림 작업의 미세 조정을 기반으로 대형 모델 (10 억 수준 매개 변수)을 사전 훈련하는 데 사용될 수 있습니다. 사용자는 모델 구현 및 혁신에 더 집중하여 구성을 통해 분산 교육을 쉽게 수행하고 비디오 메모리를 저장할 수 있습니다. 동시에, Fengshen은 계속 교육을 위해 Huggingface에서 모델 구조를 직접 사용할 수 있으며, 이는 사용자가 도메인 모델을 마이그레이션 할 수 있도록합니다. Fengshen은 풍부하고 실제 소스 코드 및 Fengshen Bang의 오픈 소스 모델 및 모델 적용을위한 예제를 제공합니다. Fengshen Bang 모델의 교육 및 적용으로 Fengshen 프레임 워크를 계속 최적화 할 것이므로 계속 지켜봐 주시기 바랍니다.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .우리는 프레임 워크를 실행하기 위해 횃불과 cuda 환경을 포함하는 간단한 docker를 제공합니다.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦Investiture Framework는 현재 다양한 다운 스트림 작업에 대한 파이프 라인에 적용되며 명령 줄에서 예측 및 미세 조정의 한 번의 클릭 시작을 지원합니다. 텍스트 분류를 예로 들어보십시오
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddp3 분 안에 시작하십시오
Gods 시리즈의 투자는 데이터 병렬 처리로 시작됩니다.
Gods 시리즈의 투자는 훈련 속도를 높이는 시간입니다.
Gods 시리즈의 투자에서 중국 페가수스 모델의 사전 훈련
The Gods List Series : Finetune Erlang Shen이 우연히 첫 번째로 이겼습니다.
신의 조사 시리즈 : 알고리즘 데모를 신속하게 구축하십시오
2022 AIWIN 세계 인공 지능 혁신 경쟁 : 소규모 샘플 멀티 태스킹 트랙 챔피언십 솔루션
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
CCNL Idea Research Institute의 CCNL 기술 팀은 신들의 투자를위한 오픈 소스 토론 그룹을 만들었습니다. 토론 그룹의 새로운 모델과 일련의 기사를 때때로 업데이트하고 출시 할 것입니다. 아래의 QR 코드를 스캔하거나 WeChat에서 "Fengshenbang-LM"을 검색하여 Fengshen Space에 조수를 추가하여 그룹에 가입하십시오!

우리는 또한 사람들을 계속 모집하고 있으며 이력서를 제출할 수 있습니다!

아파치 라이센스 2.0


