Fengshenbang LM
1.0.0
Chinesisch | Englisch
Fensengenbang 1.0 : Das zweisprachige Investitionen des Open -Source -Planes 1.0 Chinesische und englische Papier zielt darauf ab, die Infrastruktur chinesischer kognitiver Intelligenz zu werden.
Biobart : Generativsprachmodell für das Gebiet der Biomedizin, der von der Tsinghua University und des Ideenforschungsinstituts zur Verfügung gestellt wird. (
BioNLP 2022)
UNIMC : Ein einheitliches Modell, das auf Etikettendatensätzen in Null-Shot-Szenarien basiert. (
EMNLP 2022)
FMIT : Multimodal namens ein Turm -Entitätserkennungsmodell basierend auf der relativen Positionscodierung. (
COLING 2022)
UNIEX : Ein natürliches Sprachverständnismodell für einheitliche Extraktionsaufgaben. (
ACL 2023)
Lösen mathematischer Wortprobleme durch kooperatives Denken induzierte Sprachmodelle : Lösen mathematischer Probleme mit einem kollaborativen Argumentationsrahmen für Sprachmodelle. (
ACL 2023)
MVP-Tuning : Ein parameter effizientes System für den gesunden Menschenverstand, das auf multi-Perspektiven-Wissensabruf basiert. (
ACL 2023)
| Serienname | brauchen | Anwendbare Aufgaben | Parameterskala | Bemerkung |
|---|---|---|---|---|
| Jiang Ziya | Allgemein | Allgemeines Modell | > 7 Milliarden Parameter | Das allgemeine Modell "Jiang Ziya" -Serie kann übersetzt, Programmierung, Textklassifizierung, Informationsextraktion, Zusammenfassung, Erzeugung und Beantwortung des gesunden Menschenverstandes sowie mathematische Berechnungen übersetzt. |
| Taiyi | spezifisch | Multimodal | 80 bis 1 Milliarde Parameter | Angewendet auf Kreuzmodalszenen, einschließlich Textbildgenerierung, Proteinstrukturvorhersage, Sprachtextdarstellung usw. |
| Erlang Shen | Allgemein | Sprachverständnis | 90 bis 3,9 Milliarden Parameter | Übernehmen Sie Verständnisaufgaben, verfügen über das größte chinesische BET -Modell, wenn Open Source die Spitze von Wenigclue und Zeroclue im Jahr 2021 erreichen |
| Wen Zhong | Allgemein | Sprachgenerierung | 100 bis 3,5 Milliarden Parameter | Fokussierung auf Erzeugungsaufgaben und Bereitstellung von Modellen mehrerer Generationen mit unterschiedlichen Parametern wie GPT2 usw. |
| Beleuchtung | Allgemein | Sprachumwandlung | 70 bis 5 Milliarden Parameter | Verwandte verschiedene Aufgaben, die vom Quelltext in den Zieltext -Typ konvertieren, z. B. maschinelle Übersetzung, Textzusammenfassung usw. |
| Yu yuan | spezifisch | Feld | 100 bis 3,5 Milliarden Parameter | Es wird auf Felder wie Medizin, Finanzen, Recht, Programmierung usw. angewendet |
| -Try zu bestimmen- | spezifisch | erkunden | -unbekannt- | Wir hoffen, experimentelle Modelle im Zusammenhang mit NLP mit verschiedenen Technologieunternehmen und Universitäten zu entwickeln. Derzeit: König Wen von Zhou |
Download Link of the Investiture of Gods Model Download
Investieren
Investitur of Gods Model Training Manual
Wichtige Fortschritte in der künstlichen Intelligenz haben viele großartige Modelle hervorgebracht, insbesondere die auf der Vorausbildung basierenden Basismodelle sind zu einem aufstrebenden Paradigma geworden. Traditionelle KI -Modelle müssen für ein oder mehrere begrenzte Szenarien in einem dedizierten riesigen Datensatz trainiert werden. Im Gegensatz dazu können sich die zugrunde liegenden Modelle an eine Vielzahl von nachgeschalteten Aufgaben anpassen. Das Basismodell schafft die Möglichkeit, in Szenarien mit niedrigem Ressourcen zu landen.
Wir stellen fest, dass die Menge an Parametern in diesen Modellen zehnmal pro Jahr wächst. Im Jahr 2018 betrug der Bert nur 100 Millionen im Parametervolumen, aber bis 2020 hatte das Parametervolumen von GPT-3 die Größenordnung von 10 Milliarden erreicht. Aufgrund dieses inspirierenden Trends sind viele hochmoderne Herausforderungen in der künstlichen Intelligenz, insbesondere der leistungsstarken Generalisierungsfähigkeiten, nach und nach möglich.
Die heutigen Grundmodelle, insbesondere Sprachmodelle, werden von der englischen Gemeinschaft dominiert. Gleichzeitig fehlen die chinesischen Forschungsressourcen als die größte gesprochene Sprache der Welt (unter Muttersprachlern), was den Fortschritt der Forschung im chinesischen Bereich im Vergleich zu Englisch ein wenig zurückbleibt.
Diese Welt braucht eine Antwort.
Um die Probleme des Nachverdauers im chinesischen Gebiet zu lösen und am 22. November 2021 einen schwerwiegenden Mangel an Forschungsressourcen zu mangeln, kündigte Shen Xiangyang, Vorsitzender des Gründungsinstituts für Idea Research Institute, offiziell mit der IDEA-Konferenz bekannt, dass das Open-Source-System der "Fengshen Bang" auf den Markt gebracht wird. Sets usw. Unser Ziel ist es, ein umfassendes, standardisiertes, benutzerzentriertes Ökosystem aufzubauen. 
Das "Fengshen Bang-Modell" wird eine Reihe von vorgebliebenen NLP-Modellen in allen Aspekten vorstellen. Es gibt umfangreiche Forschungsaufgaben in der NLP -Community, die in zwei Kategorien unterteilt werden können: allgemeine und spezielle Aufgaben. Ersteres umfasst natürliche Sprachverständnis (NLU), natürliche Sprachgenerierung (NLG) und natürliche Sprachumwandlungen (NLT). Letztere deckt Aufgaben wie multimodal, domänenspezifisch usw. ab. Wir betrachten alle diese Aufgaben und bieten verwandte Modelle, die bei nachgeschalteten Aufgaben fein abgestimmt sind. Und wir versprechen, diese Modelle weiter zu verbessern und kontinuierlich die neuesten Daten und neuesten Trainingsalgorithmen zu integrieren. Durch die Bemühungen des Ideenforschungsinstituts werden wir eine allgemeine Infrastruktur für die chinesische kognitive Intelligenz aufbauen, doppelte Konstruktionen vermeiden und die Rechenleistung für die gesamte Gesellschaft retten.
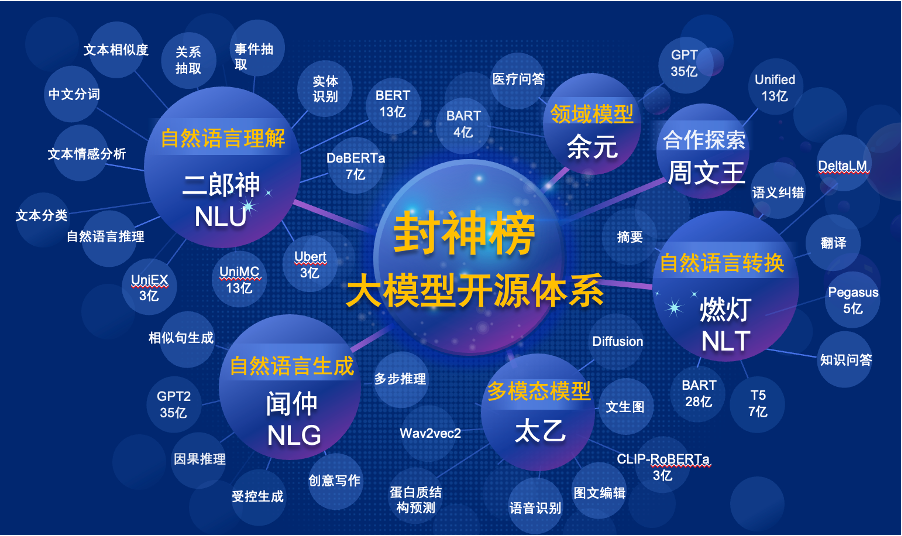
Gleichzeitig hofft der "Fengshen Bang" auch, dass verschiedene Unternehmen, Universitäten und Institutionen an diesem Open-Source-Plan beitreten und gemeinsam ein großes Open-Source-System aufbauen werden. Wenn wir in Zukunft ein neues vorgebildetes Modell benötigen, sollten wir zunächst das nächste aus diesen Open-Source-Modellen auswählen, das Training fortsetzen und dann das neue Modell auf dieses System zurückkehren. Auf diese Weise kann jeder sein eigenes Modell mit der geringsten Rechenleistung erhalten, und das Open -Source -Big -Modellsystem kann auch immer größer werden.

Um eine bessere Erfahrung zu machen, um die Open -Source -Community zu umarmen, werden alle Modelle der Untersuchung der Götter konvertiert und in die Huggingface -Community synchronisiert. Sie können problemlos alle Modelle der Untersuchung der Götter mit ein paar Codezeilen verwenden. Willkommen in der Umarmung der Community von Idea-CCNL zum Herunterladen.
Das allgemeine Modell "Jiang Ziya" -Serie kann übersetzt, Programmierung, Textklassifizierung, Informationsextraktion, Zusammenfassung, Erzeugung und Beantwortung des gesunden Menschenverstandes sowie mathematische Berechnung übersetzt. Gegenwärtig hat Jiang Ziyas allgemeines Modell (V1/V1.1) drei Schulungsstufen abgeschlossen: groß angelegte, multi-tasks überwachte Feinabstimmung und menschliches Feedback-Lernen. Die Modelle der Jiang Ziya -Serie enthalten die folgenden Modelle:
Referenz Ziya-Llama-13b-V1
Referenz Ziya_Finenetune
Referenz Ziya_inference
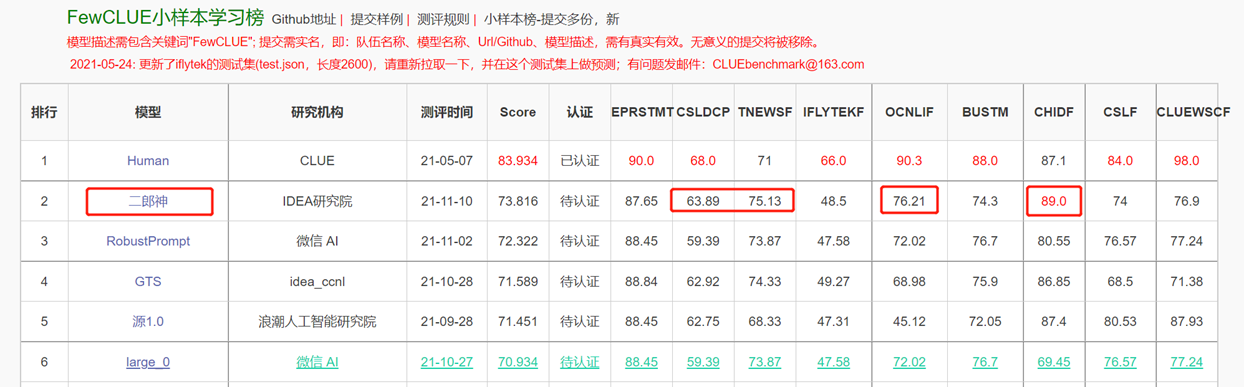
Das Zwei-Wege-Sprachmodell mit Encoderstruktur konzentriert sich auf die Lösung verschiedener Aufgaben des natürlichen Sprachverständnisses. Das Erlang Shen-1.3B Big Model mit 1,3 Milliarden Parametern verwendet 280 g Daten und 32 A100s werden 14 Tage lang geschult. Es ist das größte Open -Source -Chinesische Bert -Modell. Am 10. November 2021 führte es die Liste der maßgeblichen Bewertungsbenchmark für das Verständnis der chinesischen Sprache an. Unter ihnen übertraf Chid (Idiom Fill-in-the-Blanks), Tnews (News-Klassifizierung) Menschen, Chid (Idiom-Füllblätter), CSLDCP (Disziplin-Literaturklassifizierung) und OCNLI (Natural Language Arguming). Die Erlang Shen -Serie wird weiterhin in Bezug auf die Modellskala, die Wissensintegration, die Unterstützung von Überwachungsaufgaben usw. optimieren.
Am 24. Januar 2022 führte Erlang Shen-MRC die Zeroklue-Liste in der chinesischen Sprachverständnis-Bewertung von Zeroclue an. Unter ihnen sind CSLDCP (Disziplin -Literaturklassifizierung), Tnews (Nachrichtenklassifizierung), Iflytek (Klassifizierung der Anwendungsbeschreibung), CSL (abstrakte Schlüsselwörtererkennung) und CLUEWSC (Bezug auf die Verdauung) alle. 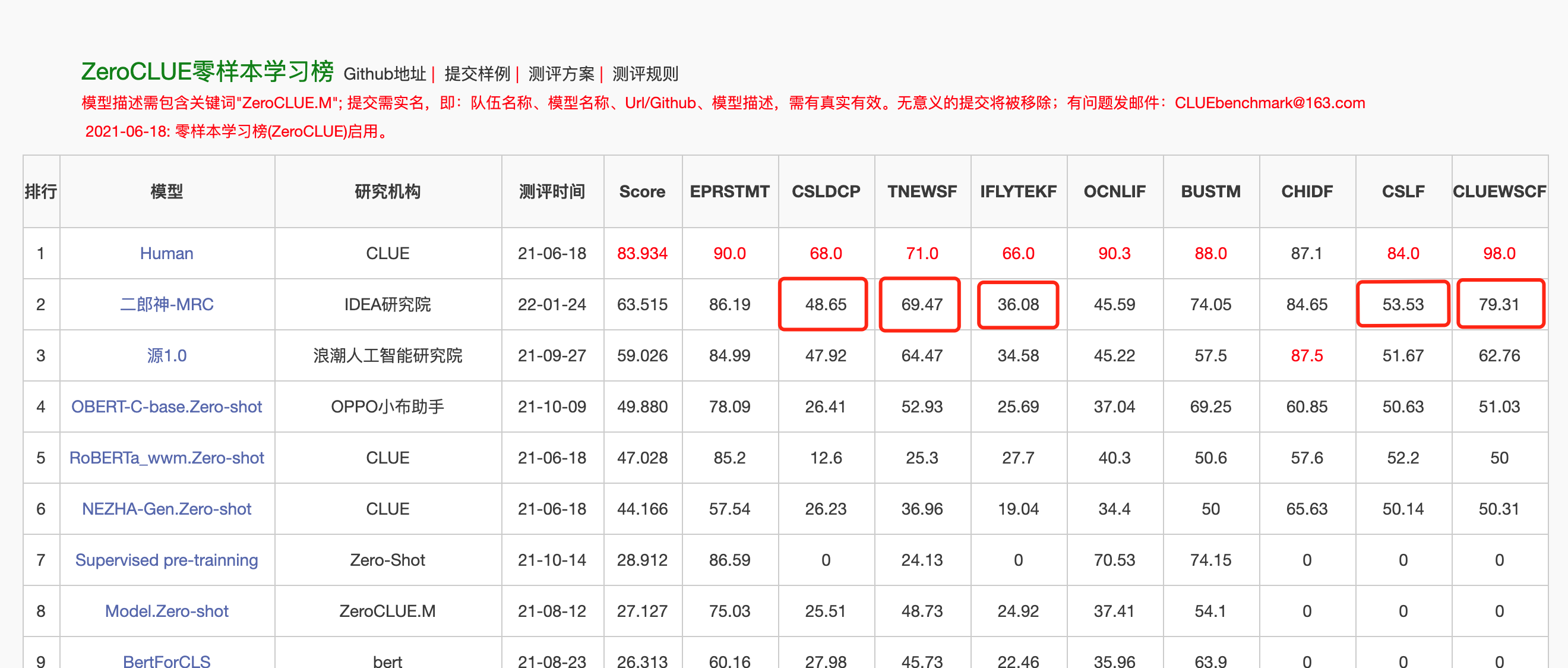
Umarmung. Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )Um Entwicklern dazu zu erleichtern, unser Open -Source -Modell schnell zu verwenden, finden Sie hier ein Finetune -Beispielskript für nachgeschaltete Aufgaben unter Verwendung der Task -Daten der TNEWS -Nachrichten auf Taskdaten auf Hinweis, und das Skript wird wie folgt ausgeführt. Wobei Data_Path der Datenpfad und die Download -Adresse der TNEWS -Aufgabendaten ist.
1. Ändern Sie zuerst die Parameter model_type und voraber_model_path in der Finetune -Sample -Skript -Skript -Figune_Classification.sh. Andere Parameter wie batch_size, data_dir usw. können nach Ihrem eigenen Gerät geändert werden.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. Dann rennen Sie:
sh finetune_classification.sh| Modell | AFQMC | Tnews | Iflytek | ocnli | cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| Roberta-wwm-text-large | 0,7514 | 0,5872 | 0,6152 | 0,777 | 0,814 | 0,8914 | 0,86 |
| Erlangshen-Megatronbert-1.3b | 0,7608 | 0,5996 | 0,6234 | 0,7917 | 0,81 | 0,9243 | 0,872 |
Die Taiyi-Serie von Modellen wird hauptsächlich in quer modalen Szenarien verwendet, einschließlich der Erzeugung von Textbild, der Proteinstrukturvorhersage, der Repräsentation der Sprachtext usw. Am 1. November 2022 öffneten die Investitur der Götter die Quelle der ersten chinesischen Version des stabilen Diffusionsmodells "Taiyi stabiler Differsion".
Taiyi stabile Diffusion reine chinesische Version
Taiyi stabile Diffusion Chinesische und englische zweisprachige Version
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| Iron Horse and Ice River kommt zu Traum, 3D -Gemälde. | Der Flug fließt dreitausend Fuß, ein Ölgemälde. | Rücken des Mädchens, Sonnenuntergang, schöne Illustration. |
|---|---|---|
 |  |  |
Fortgeschrittene Eingabeaufforderung
| Iron Horse Ice River kommt zu Traum, Konzeptmalerei, Science -Fiction, Fantasie, 3D | Chinas Küstenstadt, Science -Fiction, futuristischer Sinn, Schönheit, Illustration. | Der Mann war in den schwachen Lichtern, mit hellen Farben und alten Stilen, Arbeiten von älteren Illustratoren und Desktop -HD -Hintergrundbildern. |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
Um es jedem zu ermöglichen, das Fengshen Bang Big-Modell gut zu nutzen und an der kontinuierlichen Ausbildung des großen Modells und der nachgeschalteten Anwendungen teilzunehmen, haben wir gleichzeitig das benutzerzentrierte Fengshen-Framework offen. Weitere Informationen finden Sie unter: Fengshen (Fengshen) Framework.
Wir verweisen auf hervorragende Open-Source-Frameworks wie Huggingface, Megatron-LM, Pytorch-Lightning und DeepSteed. In Kombination mit den Eigenschaften des NLP-Feldes, pytorch-leuchtende Fengshen für Pipeline mit Pytorch als Grundrahmen. Fengshen kann verwendet werden, um große Modelle (10 Milliarden Parameter) auf der Grundlage massiver Daten (TB-Ebene) und der Feinabstimmung verschiedener nachgeschalteter Aufgaben vorzubilden. Benutzer können einfach verteilte Schulungen durchführen und den Videospeicher durch Konfiguration speichern und sich mehr auf die Modellimplementierung und Innovation konzentrieren. Gleichzeitig kann Fengshen die Modellstruktur auch für das weiteren Training direkt verwenden, was den Benutzern die Migration von Domänenmodellen ermöglicht. Fengshen bietet einen reichen und realen Quellcode und Beispiele für die Anwendung von Open -Source -Modellen und Modellen von Fengshen Bang. Mit der Schulung und Anwendung des Fengshen Bang -Modells werden wir weiterhin das Fengshen -Framework optimieren, also bleiben wir dran.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .Wir bieten einen einfachen Docker mit Torch- und CUDA -Umgebungen, um unseren Rahmen auszuführen.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦Der Investitur-Framework ist derzeit an Pipeline für verschiedene nachgeschaltete Aufgaben angepasst und unterstützt den Ein-Klick-Start für die Vorhersage und Fülle in der Befehlszeile. Nehmen Sie die Textklassifizierung als Beispiel
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpBeginnen Sie in drei Minuten
Die Investitur of the Gods -Serie beginnt mit Datenparallelität
Die Investition der Gods -Serie ist Zeit, Ihr Training zu beschleunigen
Vorausbildung des chinesischen Pegasus-Modells in die Investition der Gods-Serie
Die Gods List Series: Fellune Erlang Shen gewann versehentlich den ersten Platz
Serie Investitur of Gods: Aufbau Ihrer Algorithmus -Demo schnell aufbauen
2022 AIWIN World Artificial Intelligence Innovation Wettbewerb: kleine Beispiel -Multitasking -Streckenmeisterschaftslösung
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
Das technische CCNL -Team des Ideenforschungsinstituts hat eine Open -Source -Diskussionsgruppe für die Investition der Götter geschaffen. Wir werden von Zeit zu Zeit neue Modelle und Artikelreihen in der Diskussionsgruppe aktualisieren und veröffentlichen. Bitte suche den QR-Code unten oder suche nach "fengenshenbang-lm" auf WeChat, um den Assistenten zum Fengshen-Raum hinzuzufügen, um sich der Gruppe anzuschließen, um zu kommunizieren!

Wir rekrutieren auch weiterhin Menschen und möchten unsere Lebensläufe einreichen!

Apache -Lizenz 2.0


