Fengshenbang LM
1.0.0
Chinese | English
Fengshenbang 1.0 : The Investiture of the Open Source Plan 1.0 Chinese and English bilingual paper aims to become the infrastructure of Chinese cognitive intelligence.
BioBART : Generative language model for the field of biomedicine provided by Tsinghua University and IDEA Research Institute. (
BioNLP 2022)
UniMC : A unified model based on label datasets in zero-shot scenarios. (
EMNLP 2022)
FMIT : Single tower multimodal named entity recognition model based on relative position coding. (
COLING 2022)
UniEX : A natural language understanding model for unified extraction tasks. (
ACL 2023)
Solving Math Word Problems via Cooperative Reasoning induced Language Models : Solving mathematical problems using a collaborative reasoning framework for language models. (
ACL 2023)
MVP-Tuning : A parameter efficient common sense question and answer system based on multi-perspective knowledge retrieval. (
ACL 2023)
| Series name | need | Applicable tasks | Parameter scale | Remark |
|---|---|---|---|---|
| Jiang Ziya | General | General model | >7 billion parameters | The general model "Jiang Ziya" series has the ability to translate, programming, text classification, information extraction, abstract, copywriting generation, common sense question and answer, and mathematical calculations. |
| Taiyi | specific | Multimodal | 80 million to 1 billion parameters | Applied to cross-modal scenes, including text image generation, protein structure prediction, speech-text representation, etc. |
| Erlang Shen | General | Language comprehension | 90 million to 3.9 billion parameters | Handle understanding tasks, have the largest Chinese bet model when open source, reach the top of FewCLUE and ZeroCLUE in 2021 |
| Wen Zhong | General | Language Generation | 100 million to 3.5 billion parameters | Focusing on generation tasks, providing multiple generation models with different parameters, such as GPT2, etc. |
| Lighting | General | Language conversion | 70 million to 5 billion parameters | Handle various tasks that convert from source text to target text type, such as machine translation, text summary, etc. |
| Yu Yuan | specific | field | 100 million to 3.5 billion parameters | It is applied to fields such as medical, finance, law, programming, etc. Have the largest open source GPT2 medical model currently |
| -Try to be determined- | specific | explore | -unknown- | We hope to develop experimental models related to NLP with various technology companies and universities. Currently: King Wen of Zhou |
Download link of the Investiture of Gods Model
Investiture of the Gods' Model Training and Fine-Tuning Code Scripts
Investiture of Gods Model Training Manual
Significant advances in artificial intelligence have produced many great models, especially the basic models based on pre-training have become an emerging paradigm. Traditional AI models must be trained on a dedicated huge dataset for one or several limited scenarios, in contrast, the underlying models can adapt to a wide range of downstream tasks. The basic model creates the possibility of AI landing in low-resource scenarios.
We observe that the amount of parameters in these models is growing at a rate of 10 times per year. In 2018, the BERT was only 100 million in the parameter volume, but by 2020, the parameter volume of GPT-3 had reached the order of 10 billion. Due to this inspiring trend, many cutting-edge challenges in artificial intelligence, especially the powerful generalization capabilities, have gradually become possible.
Today's basic models, especially language models, are being dominated by the English community. At the same time, as the world's largest spoken language (among native speakers), Chinese lacks systematic research resources, which makes research progress in the Chinese field lag a bit compared to English.
This world needs an answer.
In order to solve the problems of lagging research progress in the Chinese field and serious shortage of research resources, on November 22, 2021, Shen Xiangyang, chairman of the founding institute of IDEA Research Institute, officially announced at the IDEA conference that the "Fengshen Bang" open source system will be launched - a basic ecosystem driven by Chinese, including pre-trained large models, fine-tuning applications for specific tasks, benchmarks and data sets, etc. Our goal is to build a comprehensive, standardized, user-centric ecosystem. 
The "Fengshen Bang Model" will open source a series of NLP-related pre-trained large models in all aspects. There are extensive research tasks in the NLP community, which can be divided into two categories: general and special tasks. The former includes natural language understanding (NLU), natural language generation (NLG) and natural language conversion (NLT) tasks. The latter covers tasks such as multimodal, domain-specific, etc. We consider all of these tasks and provide related models fine-tuned on downstream tasks, which makes it easy for users with limited computing resources to use our basic model. And we promise to continue to upgrade these models and continuously integrate the latest data and the latest training algorithms. Through the efforts of IDEA Research Institute, we will build a general infrastructure for Chinese cognitive intelligence, avoid duplicate construction, and save computing power for the whole society.
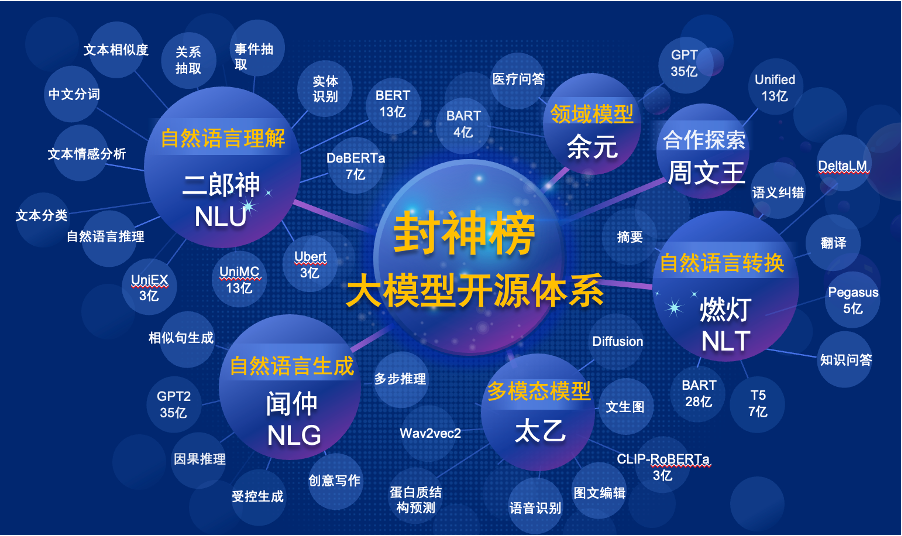
At the same time, the "Fengshen Bang" also hopes that various companies, universities and institutions will join this open source plan and jointly build a large-scale open source system. In the future, when we need a new pre-trained model, we should first select the closest one from these open source models, continue training, and then open source the new model back to this system. In this way, everyone can get their own model with the least computing power, and the open source big model system can also become larger and larger.

In order to have a better experience, embrace the open source community, all the models of the Investigation of the Gods are converted and synchronized to the Huggingface community. You can easily use all the models of the Investigation of the Gods with a few lines of code. Welcome to the huggingface community of IDEA-CCNL to download.
The general model "Jiang Ziya" series has the ability to translate, programming, text classification, information extraction, abstract, copywriting generation, common sense question and answer, and mathematical calculation. At present, Jiang Ziya’s general model (v1/v1.1) has completed three stages of training: large-scale pre-training, multi-task supervised fine-tuning and human feedback learning. The Jiang Ziya series models include the following models:
Reference Ziya-LLaMA-13B-v1
Reference ziya_finenetune
Reference ziya_inference
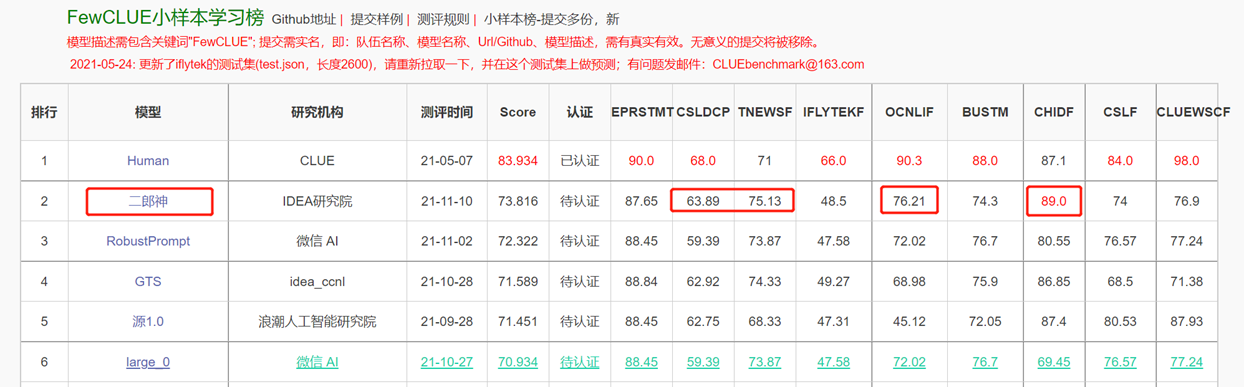
The two-way language model with Encoder structure is focused on solving various natural language comprehension tasks. The Erlang Shen-1.3B big model with 1.3 billion parameters uses 280G data and 32 A100s are trained for 14 days. It is the largest open source Chinese Bert big model. On November 10, 2021, it topped the list of the authoritative evaluation benchmark for Chinese language understanding. Among them, CHID (idiom fill-in-the-blanks), TNEWS (news classification) surpassed humans, CHID (idiom fill-in-the-blanks), CSLDCP (discipline literature classification), and OCNLI (natural language reasoning) have the first place in single tasks, and the small sample learning record is refreshed. The Erlang Shen series will continue to optimize in terms of model scale, knowledge integration, supervision task assistance, etc.
On January 24, 2022, Erlang Shen-MRC topped the ZeroCLUE list in the Chinese Language Understanding Evaluation ZeroCLUE. Among them, CSLDCP (discipline literature classification), TNEWS (news classification), IFLYTEK (application description classification), CSL (abstract keyword recognition), and CLUEWSC (referring to digestion) are all the first. 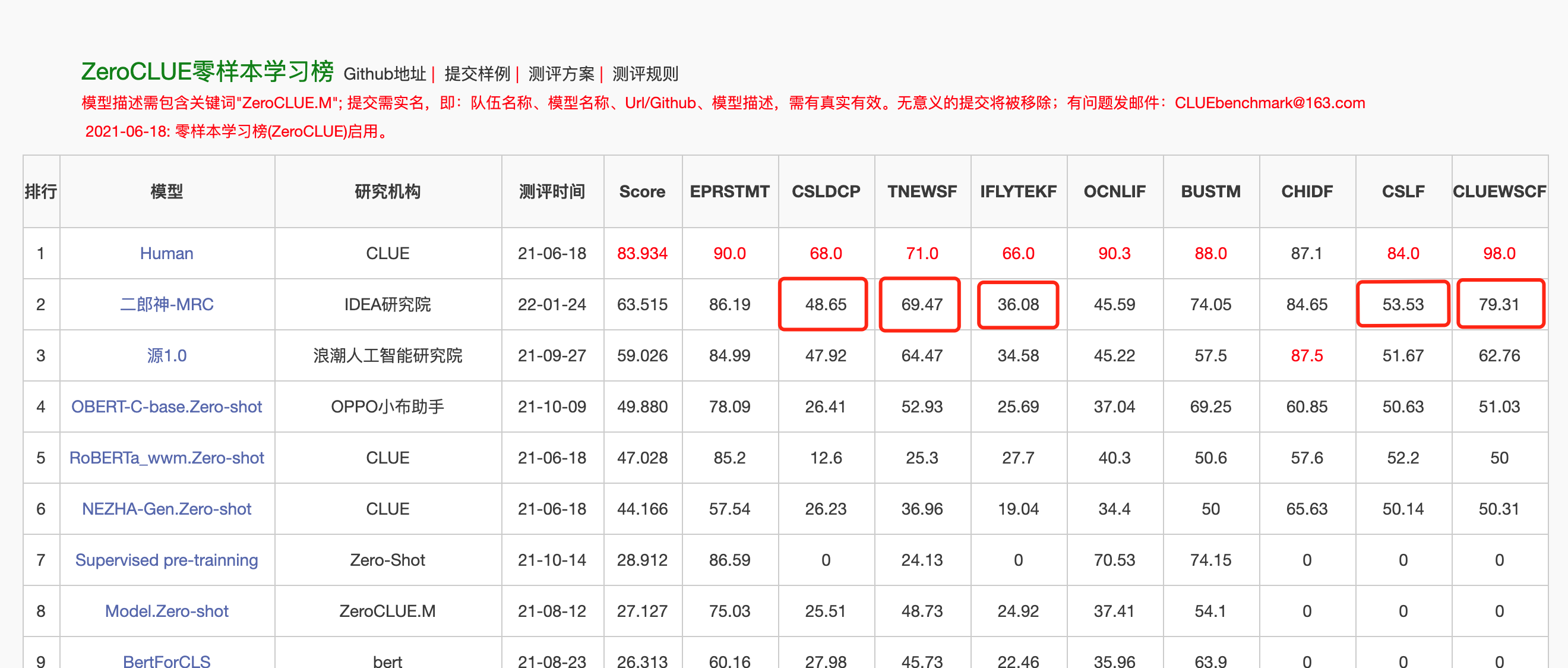
Huggingface Erlang Shen-1.3B
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )In order to facilitate developers to quickly use our open source model, here is a finetune sample script for downstream tasks, using the tnews news classification task data on CLUE, and the script is run as follows. Where DATA_PATH is the data path and the download address of the tnews task data.
1. First modify the model_type and pretrained_model_path parameters in the finetune sample script finetune_classification.sh. Other parameters such as batch_size, data_dir, etc. can be modified according to your own device.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. Then run:
sh finetune_classification.sh| Model | afqmc | tnews | iflytek | ocnli | cmnli | wsc | csl |
|---|---|---|---|---|---|---|---|
| roberta-wwm-ext-large | 0.7514 | 0.5872 | 0.6152 | 0.777 | 0.814 | 0.8914 | 0.86 |
| Erlangshen-MegatronBert-1.3B | 0.7608 | 0.5996 | 0.6234 | 0.7917 | 0.81 | 0.9243 | 0.872 |
The Taiyi series of models are mainly used in cross-modal scenarios, including text image generation, protein structure prediction, speech-text representation, etc. On November 1, 2022, the Investiture of the Gods opened the source of the first Chinese version of the stable diffusion model "Taiyi Stable Diffusion".
Taiyi Stable Diffusion pure Chinese version
Taiyi Stable Diffusion Chinese and English bilingual version
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| Iron Horse and Ice River Comes to Dream, 3D Painting. | The flying flow down three thousand feet, an oil painting. | Girl's back, sunset, beautiful illustration. |
|---|---|---|
 |  |  |
Advanced Prompt
| Iron Horse Ice River Comes to Dream, Concept Painting, Science Fiction, Fantasy, 3D | China's seaside city, science fiction, futuristic sense, beauty, illustration. | The man was in the dim lights, with bright colors and ancient style, works by senior illustrators, and desktop HD wallpapers. |
|---|---|---|
 |  |  |
https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/IDEA-CCNL/stable-diffusion-webuui/blob/master/README.md
https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/stable_diffusion_dreambooth
In order to allow everyone to make good use of the Fengshen Bang big model and participate in the continuous training of the big model and downstream applications, we simultaneously open source the user-centric FengShen framework. For details, please see: FengShen (FengShen) framework.
We refer to excellent open source frameworks such as HuggingFace, Megatron-LM, Pytorch-Lightning, and DeepSpeed. Combined with the characteristics of the NLP field, Pytorch-Lightning redesigned FengShen for Pipeline with Pytorch as the basic framework. FengShen can be used to pre-training large models (10 billion-level parameters) based on massive data (TB-level data) and fine-tuning of various downstream tasks. Users can easily perform distributed training and save video memory through configuration, focusing more on model implementation and innovation. At the same time, FengShen can also directly use the model structure in HuggingFace for continued training, which facilitates users to migrate domain models. FengShen provides rich and real source code and examples for the application of open source models and models of Fengshen Bang. With the training and application of the Fengshen Bang model, we will continue to optimize the FengShen framework, so stay tuned.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .We provide a simple docker that includes torch and cuda environments to run our framework.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦The Investiture Framework is currently adapted to Pipeline for various downstream tasks, and supports one-click start of Predict and Finetuning on the command line. Take Text Classification as an example
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpGet started in three minutes
The Investiture of the Gods Series starts with data parallelism
The Investiture of the Gods Series is time to speed up your training
Pre-training of the Chinese pegasus model in the Investiture of the Gods Series
The Gods List Series: Finetune Erlang Shen accidentally won the first place
Investiture of Gods Series: Quickly Building Your Algorithm Demo
2022 AIWIN World Artificial Intelligence Innovation Competition: Small Sample Multitasking Track Championship Solution
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
The CCNL technical team of IDEA Research Institute has created an open source discussion group for the Investiture of the Gods. We will update and release new models and series of articles in the discussion group from time to time. Please scan the QR code below or search for "fengshenbang-lm" on WeChat to add the assistant to Fengshen Space to join the group to communicate!

We are also continuing to recruit people, welcome to submit our resumes!

Apache License 2.0


