Fengshenbang LM
1.0.0
Chinois | Anglais
Fengshenbang 1.0 : L'investiture du Plan Open Source 1.0 Chinois et le papier bilingue anglais vise à devenir l'infrastructure de l'intelligence cognitive chinoise.
Biobart : modèle de langue générative pour le domaine de la biomédecine fournis par l'Université Tsinghua et Idea Research Institute. (
BioNLP 2022)
UNIMC : un modèle unifié basé sur des ensembles de données d'étiquette dans des scénarios zéro-shot. (
EMNLP 2022)
FMIT : Modèle de reconnaissance d'entité multimodal de tour unique basé sur le codage de position relatif. (
COLING 2022)
UNINEX : Un modèle de compréhension du langage naturel pour les tâches d'extraction unifiées. (
ACL 2023)
Résoudre les problèmes de mots mathématiques via des modèles de langage induits de raisonnement coopératif : résoudre des problèmes mathématiques à l'aide d'un cadre de raisonnement collaboratif pour les modèles de langue. (
ACL 2023)
MVP-Tuning : un système de questions et réponses de bon sens efficace par des paramètres basés sur la récupération des connaissances multi-perspectives. (
ACL 2023)
| Nom de la série | besoin | Tâches applicables | Échelle de paramètre | Remarque |
|---|---|---|---|---|
| Jiang Ziya | Général | Modèle général | > 7 milliards de paramètres | La série générale du modèle "Jiang Ziya" a la capacité de traduire, la programmation, la classification du texte, l'extraction d'informations, le résumé, la génération de rédaction, la question et la réponse du bon sens et les calculs mathématiques. |
| Taiyi | spécifique | Multimodal | 80 à 1 milliard de paramètres | Appliqué aux scènes croisées, notamment la génération d'images texte, la prédiction de la structure des protéines, la représentation du texte de la parole, etc. |
| Erlang Shen | Général | Compréhension du langage | 90 à 3,9 milliards de paramètres | Gérer les tâches de compréhension, avoir le plus grand modèle de pari chinois lorsqu'il est open source, atteindre le sommet de FewClue et Zeroclue en 2021 |
| Wen Zhong | Général | Génération de langue | 100 à 3,5 milliards de paramètres | Se concentrer sur les tâches de génération, en fournissant des modèles de génération multiples avec différents paramètres, tels que GPT2, etc. |
| Éclairage | Général | Conversion linguistique | 70 à 5 milliards de paramètres | Gérez diverses tâches qui se convertissent à partir du texte source en type de texte cible, telles que la traduction automatique, le résumé du texte, etc. |
| Yu Yuan | spécifique | champ | 100 à 3,5 milliards de paramètres | Il est appliqué à des domaines tels que Medical, Finance, Law, Programming, etc. ont le plus grand modèle médical GPT2 Open Source actuellement |
| -Thre à déterminer- | spécifique | explorer | -inconnu- | Nous espérons développer des modèles expérimentaux liés à la PNL avec diverses entreprises technologiques et universités. Actuellement: King Wen de Zhou |
Télécharger le lien du modèle d'investiture des dieux
Investiture de la formation du modèle des dieux et des scripts de code fin
Manuel de formation des modèles d'investiture des dieux
Des progrès importants de l'intelligence artificielle ont produit de nombreux grands modèles, en particulier les modèles de base basés sur la pré-formation sont devenus un paradigme émergent. Les modèles d'IA traditionnels doivent être formés sur un énorme ensemble de données dédié pour un ou plusieurs scénarios limités, en revanche, les modèles sous-jacents peuvent s'adapter à un large éventail de tâches en aval. Le modèle de base crée la possibilité d'atterrissage sur l'IA dans des scénarios à faible ressource.
Nous observons que la quantité de paramètres dans ces modèles augmente à un rythme de 10 fois par an. En 2018, le Bert n'était que de 100 millions dans le volume des paramètres, mais d'ici 2020, le volume des paramètres de GPT-3 avait atteint l'ordre de 10 milliards. En raison de cette tendance inspirante, de nombreux défis de pointe dans l'intelligence artificielle, en particulier les puissantes capacités de généralisation, sont progressivement devenus possibles.
Les modèles de base d'aujourd'hui, en particulier les modèles de langue, sont dominés par la communauté anglaise. Dans le même temps, en tant que plus grande langue parlée au monde (parmi les locuteurs natifs), le chinois manque de ressources de recherche systématiques, ce qui fait que la recherche progresse dans le décalage du domaine chinois par rapport à l'anglais.
Ce monde a besoin d'une réponse.
Afin de résoudre les problèmes de progrès de la recherche en retard dans le domaine chinois et la grave pénurie de ressources de recherche, le 22 novembre 2021, Shen Xiangyang, président de l'Institut de recherche de la Fondation de l'idée, a officiellement annoncé lors de la conférence IDEA que le système de "Fengshen Bang" sera lancé etc. Notre objectif est de construire un écosystème complet et standardisé et centré sur l'utilisateur. 
Le "Fengshen Bang Model" ouvrira une série de grands modèles pré-formés liés aux PNL dans tous les aspects. Il existe de nombreuses tâches de recherche dans la communauté PNL, qui peuvent être divisées en deux catégories: les tâches générales et spéciales. Le premier comprend la compréhension du langage naturel (NLU), la génération du langage naturel (NLG) et les tâches de conversion du langage naturel (NLT). Ce dernier couvre des tâches telles que le multimodal, spécifique au domaine, etc. Nous considérons toutes ces tâches et fournissons des modèles connexes affinés sur des tâches en aval, ce qui facilite les utilisateurs avec des ressources informatiques limitées pour utiliser notre modèle de base. Et nous promettons de continuer à mettre à niveau ces modèles et à intégrer en continu les dernières données et les derniers algorithmes de formation. Grâce aux efforts de l'Idea Research Institute, nous construirons une infrastructure générale pour l'intelligence cognitive chinoise, éviterons la construction en double et économiserons la puissance informatique pour toute la société.
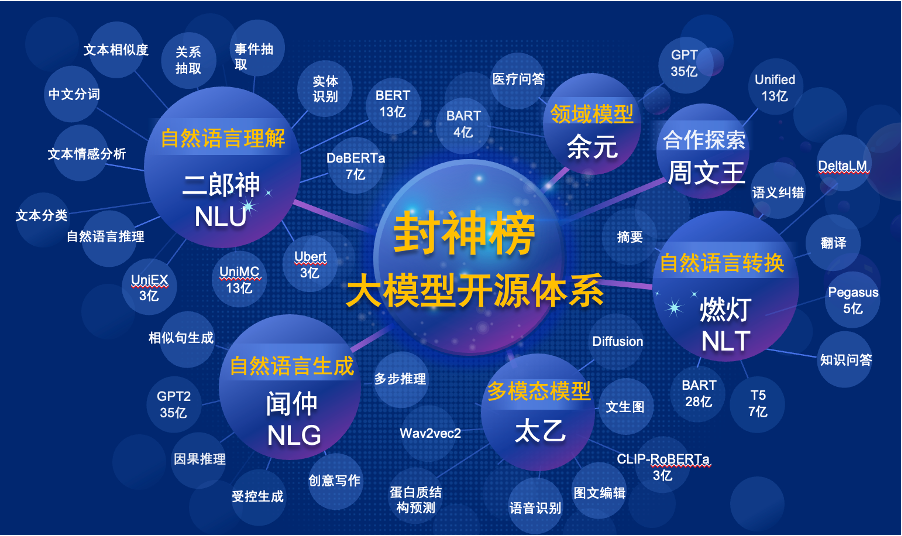
Dans le même temps, le "Fengshen Bang" espère également que diverses entreprises, universités et institutions rejoindront ce plan open source et construisent conjointement un système open source à grande échelle. À l'avenir, lorsque nous avons besoin d'un nouveau modèle pré-formé, nous devons d'abord sélectionner le plus proche parmi ces modèles open source, continuer à la formation, puis en open source le nouveau modèle à ce système. De cette façon, tout le monde peut obtenir son propre modèle avec la puissance la moins informatique, et le système de gros modèle open source peut également devenir de plus en plus grand.

Afin d'avoir une meilleure expérience, d'embrasser la communauté open source, tous les modèles de l'enquête sur les dieux sont convertis et synchronisés à la communauté des étreintes. Vous pouvez facilement utiliser tous les modèles de l'étude des dieux avec quelques lignes de code. Bienvenue dans la communauté HuggingFace d'IDEA-CCNL à télécharger.
La série générale du modèle "Jiang Ziya" a la capacité de traduire, la programmation, la classification du texte, l'extraction d'informations, le résumé, la génération de rédaction, la question et la réponse du bon sens et le calcul mathématique. À l'heure actuelle, le modèle général de Jiang Ziya (V1 / V1.1) a terminé trois étapes de formation: pré-formation à grande échelle, réglage fin à la recherche et apprentissage par la rétroaction humaine multi-tâches. Les modèles de la série Jiang Ziya incluent les modèles suivants:
Référence ziya-llama-13b-v1
Référence ziya_finenenetune
Référence ziya_inference
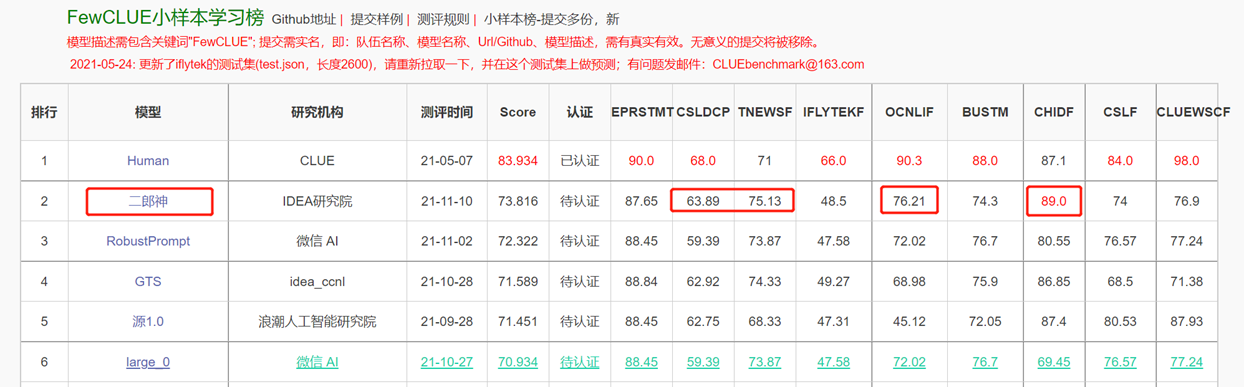
Le modèle de langue bidirectionnelle avec structure de codeur se concentre sur la résolution de diverses tâches de compréhension du langage naturel. Le modèle Big Big Model Erlang Shen-1.3B avec 1,3 milliard de paramètres utilise 280 g de données et 32 A100 sont formés pendant 14 jours. Il s'agit du plus grand modèle Bert Bert chinois open source. Le 10 novembre 2021, il est en tête de la liste de la référence d'évaluation faisant autorité pour la compréhension de la langue chinoise. Parmi eux, le CHID (idiome remplit-les-blandons), les tnews (classification des nouvelles) dépassés, le Chid (idiome remplit-les-blandques), le CSLDCP (classification de la littérature discipline) et l'OCNLI (raisonnement du langage naturel) ont la première place dans des tâches uniques, et le petit enregistrement d'apprentissage de l'échantillon est réapprovisé. La série Erlang Shen continuera d'optimiser en termes d'échelle de modèle, d'intégration des connaissances, d'aide aux tâches de supervision, etc.
Le 24 janvier 2022, Erlang Shen-MRC est en tête de la liste des zéroclues dans l'évaluation de la compréhension de la langue chinoise Zeroclue. Parmi eux, CSLDCP (Discipline Literature Classification), TNEWS (Classification des nouvelles), IFLYTEK (Classification description de l'application), CSL (Résumé Reconnaissance des mots clés) et ClueWSC (se référant à la digestion) sont tous les premiers. 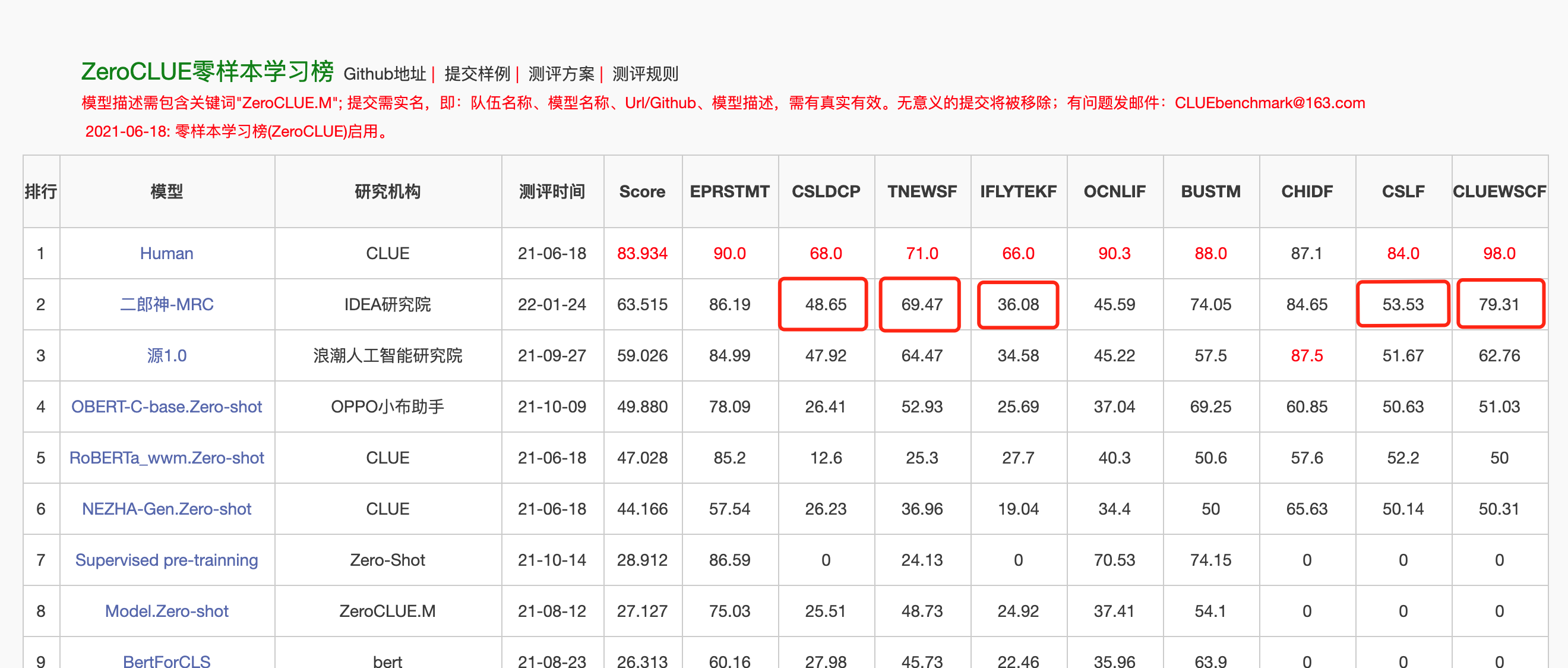
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )Afin de faciliter les développeurs d'utiliser rapidement notre modèle open source, voici un exemple de script Finetune pour les tâches en aval, en utilisant les données de la tâche de classification des nouvelles TNEWS sur l'indice, et le script est exécuté comme suit. Où DATA_PATH est le chemin de données et l'adresse de téléchargement des données de la tâche TNEWS.
1. Modifiez d'abord les paramètres Model_Type et Pretrained_Model_Path dans l'exemple de script Finetune fineTune_classification.sh. D'autres paramètres tels que Batch_size, Data_Dir, etc. peuvent être modifiés en fonction de votre propre appareil.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. Ensuite, courez:
sh finetune_classification.sh| Modèle | afqmc | tnews | iflytek | ocnli | cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| ROBERTA-WWM-EXT-GARD | 0,7514 | 0,5872 | 0,6152 | 0,777 | 0,814 | 0,8914 | 0,86 |
| Erlangshen-mégatronbert-1.3b | 0,7608 | 0,5996 | 0,6234 | 0,7917 | 0,81 | 0,9243 | 0,872 |
La série de modèles de Taiyi est principalement utilisée dans les scénarios intermodaux, notamment la génération d'images texte, la prédiction de la structure des protéines, la représentation de texte de la parole, etc. Le 1er novembre 2022, l'investiture des dieux a ouvert la source de la première version chinoise du modèle de diffusion stable "Taiyi Stable Diffusion".
Taiyi STABLE Diffusion Pure Chine
Taiyi STABLE DIFUSION Version bilingue chinoise et anglaise
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| Iron Horse et Ice River arrivent au rêve, peinture 3D. | Le vol circule de trois mille pieds, une peinture à l'huile. | Back de fille, coucher de soleil, belle illustration. |
|---|---|---|
 |  |  |
Invite avancée
| Iron Horse Ice River arrive au rêve, à la peinture conceptuelle, à la science-fiction, à la fantaisie, 3D | La ville balnéaire de la Chine, la science-fiction, le sens futuriste, la beauté, l'illustration. | L'homme était dans les lumières sombres, avec des couleurs vives et un style ancien, des œuvres d'illustrateurs seniors et des fonds d'écran HD de bureau. |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
Afin de permettre à chacun de faire bon usage du modèle Big Big Fengshen et de participer à la formation continue du grand modèle et des applications en aval, nous opensons simultanément le cadre Fengshen centré sur l'utilisateur. Pour plus de détails, veuillez consulter: Fengshen (Fengshen) Framework.
Nous nous référons à d'excellents cadres open source tels que HuggingFace, Megatron-LM, Pytorch-Lightning et Deeppeed. Combiné avec les caractéristiques du champ NLP, le Fengshen redessiné par Pytorch est redessiné pour le pipeline avec Pytorch comme cadre de base. Fengshen peut être utilisé pour pré-formation de grands modèles (10 milliards de paramètres de niveau) sur la base de données massives (données de niveau TB) et de réglage fin de diverses tâches en aval. Les utilisateurs peuvent facilement effectuer une formation distribuée et enregistrer la mémoire vidéo via la configuration, en se concentrant davantage sur la mise en œuvre et l'innovation du modèle. Dans le même temps, Fengshen peut également utiliser directement la structure du modèle dans Huggingface pour une formation continue, ce qui facilite les utilisateurs à migrer les modèles de domaine. Fengshen fournit un code source riche et réel et des exemples pour l'application de modèles open source et de modèles de Fengshen Bang. Avec la formation et l'application du modèle Fengshen Bang, nous continuerons d'optimiser le cadre Fengshen, alors restez à l'écoute.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .Nous fournissons un Docker simple qui inclut les environnements Torch et Cuda pour exécuter notre cadre.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦Le cadre d'investiture est actuellement adapté à Pipeline pour diverses tâches en aval, et prend en charge le début en un clic de la prédire et de la finalité sur la ligne de commande. Prenez la classification du texte comme exemple
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpCommencez dans trois minutes
L'investiture de la série Gods commence par le parallélisme des données
L'investiture de la série Gods est le temps d'accélérer votre formation
Pré-formation du modèle chinois Pegasus dans la série Investiture of the Gods
The Gods List Series: Finetune Erlang Shen a accidentellement remporté la première place
Série d'investiture des dieux: Construire rapidement votre démonstration d'algorithme
2022 Concours d'innovation de l'intelligence artificielle du monde Aiwin: Solution de championnat de piste multitâche
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
L'équipe technique du CCNL de Idea Research Institute a créé un groupe de discussion open source pour l'investiture des dieux. Nous mettrons à jour et publierons de nouveaux modèles et séries d'articles dans le groupe de discussion de temps à autre. Veuillez scanner le code QR ci-dessous ou rechercher "Fengshenbang-LM" sur WeChat pour ajouter l'assistant à l'espace Fengshen pour rejoindre le groupe pour communiquer!

Nous continuons également de recruter des gens, bienvenue pour soumettre nos CV!

Licence Apache 2.0


