Fengshenbang LM
1.0.0
الصينية | إنجليزي
Fengshenbang 1.0 : يهدف الاستثمار في الخطة المفتوحة المصدر 1.0 إلى الورقة الثنائية الصينية والإنجليزية إلى أن تصبح البنية التحتية للذكاء المعرفي الصيني.
Biobart : نموذج اللغة التوليدي لمجال الطب الحيوي الذي توفره جامعة Tsinghua ومعهد أبحاث الأفكار. (
BioNLP 2022)
UNIMC : نموذج موحد يعتمد على مجموعات بيانات الملصقات في سيناريوهات الصفر. (
EMNLP 2022)
FMIT : نموذج التعرف على الكيان المسمى Tower MultimDal يعتمد على ترميز الموضع النسبي. (
COLING 2022)
UNIEX : نموذج لفهم اللغة الطبيعية لمهام الاستخراج الموحدة. (
ACL 2023)
حل مشاكل الكلمات الرياضية عبر نماذج اللغة التي يسببها التفكير التعاوني : حل المشكلات الرياضية باستخدام إطار تفكير تعاوني لنماذج اللغة. (
ACL 2023)
MVP-Tuning : معلمة سؤال وسائل استفادة من الحس السليم كفاءة بناء على استرجاع المعرفة متعددة المنظور. (
ACL 2023)
| اسم السلسلة | يحتاج | المهام المعمول بها | مقياس المعلمة | ملاحظة |
|---|---|---|---|---|
| جيانغ زيا | عام | النموذج العام | > 7 مليارات المعلمات | يتمتع سلسلة النموذج العام "Jiang Ziya" بالقدرة على الترجمة والبرمجة وتصنيف النص واستخراج المعلومات والملخص وتوليد كتابة النصوص والسؤال والإجابة والحسابات الرياضية. |
| تايي | محدد | متعدد الوسائط | 80 مليون إلى 1 مليار معلمة | تم تطبيقه على المشاهد عبر الوسائط ، بما في ذلك توليد الصور النصية ، والتنبؤ ببنية البروتين ، وتمثيل نص الكلام ، إلخ. |
| إرلانج شين | عام | فهم اللغة | 90 مليون إلى 3.9 مليار معلمة | التعامل مع مهام فهم ، والحصول على أكبر نموذج رهان صيني عند المصدر المفتوح ، وصلت إلى أعلى عدد قليل من التوصيلات و Zeroclue في عام 2021 |
| ون تشونغ | عام | توليد اللغة | 100 مليون إلى 3.5 مليار معلمة | التركيز على مهام التوليد ، وتوفير نماذج توليد متعددة بمعلمات مختلفة ، مثل GPT2 ، إلخ. |
| إضاءة | عام | تحويل اللغة | من 70 مليون إلى 5 مليار معلمة | التعامل مع المهام المختلفة التي تتحول من النص المصدر إلى نوع النص المستهدف ، مثل ترجمة الآلة ، ملخص النص ، إلخ. |
| يو يوان | محدد | مجال | 100 مليون إلى 3.5 مليار معلمة | يتم تطبيقه على مجالات مثل الطبية والتمويل والقانون والبرمجة وما إلى ذلك ، ولديه أكبر نموذج طبي مفتوح المصادر GPT2 |
| -التحديد- | محدد | يستكشف | -مجهول- | نأمل في تطوير نماذج تجريبية تتعلق بـ NLP مع مختلف شركات التكنولوجيا والجامعات. حاليا: الملك ون من تشو |
تنزيل رابط نموذج استثمار الآلهة
استثمار التدريب النموذجي للآلهة والبرامج النصية لتصنيع الرموز
دليل التدريب على نموذج الآلهة
أنتجت التطورات الكبيرة في الذكاء الاصطناعي العديد من النماذج الرائعة ، وخاصة النماذج الأساسية القائمة على التدريب المسبق أصبحت نموذجًا ناشئًا. يجب تدريب نماذج الذكاء الاصطناعى التقليدية على مجموعة بيانات ضخمة مخصصة لمجموعة أو عدة سيناريوهات محدودة ، على النقيض من ذلك ، يمكن أن تتكيف النماذج الأساسية مع مجموعة واسعة من المهام المصب. النموذج الأساسي يخلق إمكانية هبوط الذكاء الاصطناعي في سيناريوهات الموارد المنخفضة.
نلاحظ أن كمية المعلمات في هذه النماذج تنمو بمعدل 10 مرات في السنة. في عام 2018 ، كان BERT 100 مليون فقط في حجم المعلمة ، ولكن بحلول عام 2020 ، وصل حجم المعلمة من GPT-3 إلى 10 مليارات. نظرًا لهذا الاتجاه الملهم ، أصبحت العديد من التحديات المتطورة في الذكاء الاصطناعي ، وخاصة قدرات التعميم القوية ، ممكنة تدريجياً.
يهيمن على النماذج الأساسية اليوم ، وخاصة نماذج اللغة ، من قبل المجتمع الإنجليزي. في الوقت نفسه ، كأكبر لغة منطوقة في العالم (بين المتحدثين الأصليين) ، يفتقر الصينيون إلى موارد بحثية منهجية ، مما يجعل تقدم البحث في المجال الصيني قليلاً مقارنةً باللغة الإنجليزية.
هذا العالم يحتاج إلى إجابة.
من أجل حل مشاكل التقدم البحثي المتأخر في المجال الصيني ونقص خطير في موارد البحث ، في 22 نوفمبر 2021 ، تم الإعلان عن شين شيانجيانج ، رئيس معهد المعهد المؤسس لأبحاث الأفكار ، رسميًا في مؤتمر Idea الذي يتم إطلاقه "لتصميمات" ، وتصنيفات مخططة ، وتصنيفات محددة ؛ هدفنا هو بناء نظام إيكولوجي شامل وموحد يركز على المستخدم. 
سيفتح "Fengshen Bang Model" مصدر سلسلة من النماذج الكبيرة التي تم تدريبها مسبقًا مرتبطة بـ NLP في جميع الجوانب. هناك مهام بحثية مكثفة في مجتمع NLP ، والتي يمكن تقسيمها إلى فئتين: المهام العامة والخاصة. السابق يشمل فهم اللغة الطبيعية (NLU) وتوليد اللغة الطبيعية (NLG) وتحويل اللغة الطبيعية (NLT). يغطي هذا الأخير مهام مثل الوسائط المتعددة ، الخاصة بالمجال ، وما إلى ذلك. نحن نعتبر كل هذه المهام ونوفر النماذج ذات الصلة التي يتم ضبطها بشكل جيد على مهام المصب ، مما يجعل من السهل على المستخدمين الحصول على موارد حوسبة محدودة لاستخدام نموذجنا الأساسي. ونعدنا بمواصلة ترقية هذه النماذج ودمج أحدث البيانات باستمرار وأحدث خوارزميات التدريب. من خلال جهود معهد أبحاث الأفكار ، سنقوم ببناء بنية تحتية عامة للذكاء المعرفي الصيني ، وتجنب البناء المكرر ، وتوفير قوة الحوسبة للمجتمع بأكمله.
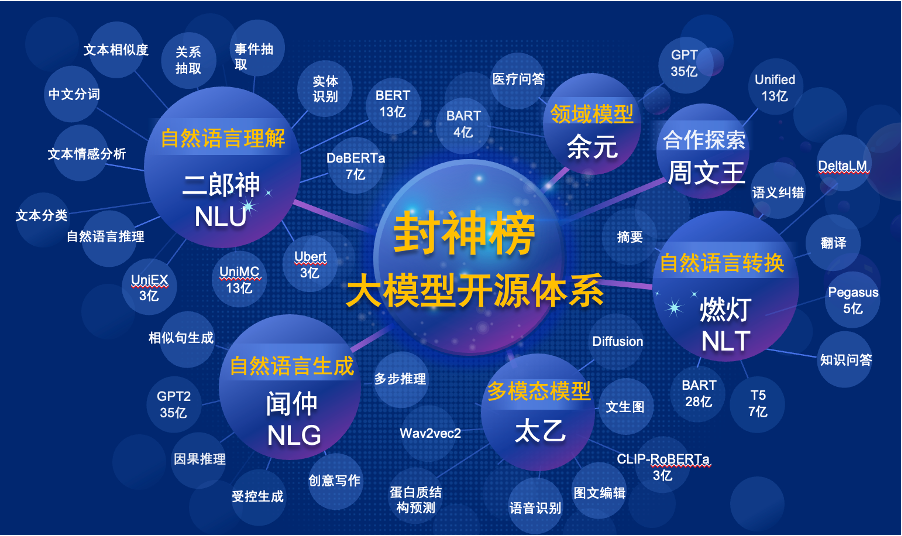
في الوقت نفسه ، تأمل "Fengshen Bang" أيضًا أن تنضم العديد من الشركات والجامعات والمؤسسات إلى هذه الخطة المفتوحة المصدر وبناء نظام مصدر مفتوح واسع النطاق. في المستقبل ، عندما نحتاج إلى نموذج جديد تم تدريبه مسبقًا ، يجب علينا أولاً تحديد الأقرب من هذه النماذج المفتوحة المصدر ، ومواصلة التدريب ، ثم مفتوحًا للنموذج الجديد مرة أخرى إلى هذا النظام. وبهذه الطريقة ، يمكن للجميع الحصول على طراز خاص بهم بأقل قوة حوسبة ، ويمكن أيضًا أن يصبح نظام النماذج الكبيرة مفتوح المصدر أكبر وأكبر.

من أجل الحصول على تجربة أفضل ، احتضان مجتمع المصادر المفتوحة ، يتم تحويل جميع نماذج التحقيق في الآلهة ومزامنة مع مجتمع Huggingface. يمكنك بسهولة استخدام جميع نماذج التحقيق في الآلهة مع بضعة أسطر من التعليمات البرمجية. مرحبًا بك في مجتمع Huggingface لـ Idea-CCNL للتنزيل.
يتمتع سلسلة النموذج العام "Jiang Ziya" بالقدرة على الترجمة والبرمجة وتصنيف النص واستخراج المعلومات والملخص وتوليد كتابة النصوص والأسئلة والإجابة المنطقية والحساب الرياضي. في الوقت الحاضر ، أكمل نموذج Jiang Ziya العام (V1/V1.1) ثلاث مراحل من التدريب: على نطاق واسع قبل التدريب ، والمهام متعددة المهام ، التعلم الخاضع للإشراف والتعلم البشري. تتضمن نماذج سلسلة Jiang Ziya النماذج التالية:
مرجع Ziya-llama-13b-V1
مرجع Ziya_fineneTune
مرجع ziya_inference
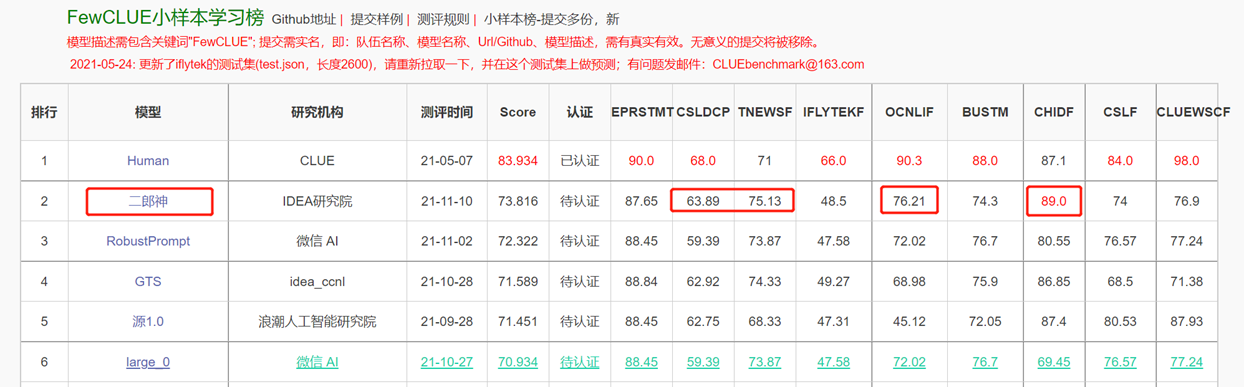
يركز نموذج اللغة ثنائي الاتجاه مع بنية التشفير على حل مختلف مهام فهم اللغة الطبيعية. يستخدم طراز Erlang Shen-1.3b الكبير الذي يحتوي على 1.3 مليار معلمة بيانات 280 جرام ويتم تدريب 32 A100 لمدة 14 يومًا. إنه أكبر نموذج صيني كبير بيرت الصيني. في 10 نوفمبر 2021 ، تصدرت قائمة المعيار الموثوق للتقييم لفهم اللغة الصينية. من بينها ، تفوقت chid (تعبئة التعبئة في الفراغ) ، وتجاوز TNEWS (تصنيف الأخبار) البشر ، و chid (تعبئة التعبئة في الفراغ) ، و CSLDCP (تصنيف الأدب الانضباط) ، و Ocnli (منطق اللغة الطبيعية) لهما المركز الأول في المهام الفردية ، ويتم تحديث سجل التعلم العينة الصغيرة. ستستمر سلسلة Erlang Shen في التحسين من حيث النموذج ، وتكامل المعرفة ، ومساعدة مهمة الإشراف ، وما إلى ذلك.
في 24 كانون الثاني (يناير) 2022 ، تصدرت إرلانج شين-ماركية قائمة Zeroclue في تقييم اللغة الصينية Zeroclue. من بينها ، CSLDCP (تصنيف الأدب الانضباط) ، TNEWS (تصنيف الأخبار) ، Iflytek (تصنيف وصف التطبيق) ، CSL (التعرف على الكلمات الرئيسية التجريدية) ، و CLUEWSC (تشير إلى الهضم) كلها الأولى. 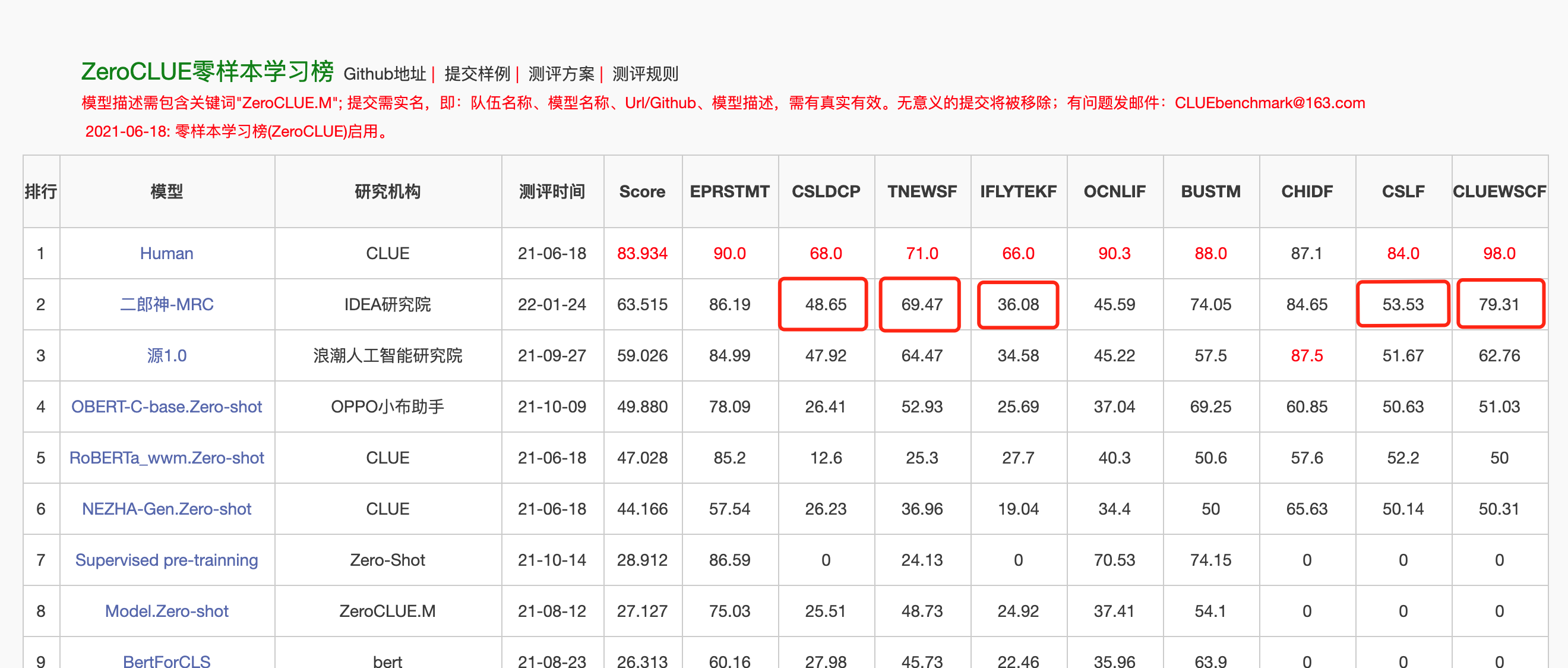
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )من أجل تسهيل المطورين لاستخدام نموذج Open Source الخاص بنا بسرعة ، إليك برنامج نصي عينة Finetune لمهام المصب ، باستخدام بيانات مهمة تصنيف الأخبار TNEWS على دليل ، ويتم تشغيل البرنامج النصي على النحو التالي. عندما يكون Data_Path مسار البيانات وعنوان تنزيل بيانات مهمة TNEWS.
1. أولاً قم بتعديل معلمات Model_type و pretRained_Model_Path في برنامج Finetune Sample Finetune_Classification.sh. يمكن تعديل المعلمات الأخرى مثل batch_size ، data_dir ، وما إلى ذلك وفقًا لجهازك الخاص.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. ثم قم بتشغيل:
sh finetune_classification.sh| نموذج | AFQMC | tnews | Iflytek | Ocnli | cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| روبرتا-ووي إم سي | 0.7514 | 0.5872 | 0.6152 | 0.777 | 0.814 | 0.8914 | 0.86 |
| Erlangshen-megatronbert-1.3b | 0.7608 | 0.5996 | 0.6234 | 0.7917 | 0.81 | 0.9243 | 0.872 |
تُستخدم سلسلة النماذج Taiyi بشكل أساسي في السيناريوهات عبر الوسائط ، بما في ذلك توليد الصور النصية ، والتنبؤ ببنية البروتين ، وتمثيل نص الكلام ، وما إلى ذلك في 1 نوفمبر 2022 ، فتح استثمار الآلهة مصدر النسخة الصينية الأولى من نموذج الانتشار المستقر "Taiyi Scable Scable".
تايي مستقر الانتشار النسخة الصينية النقية
Taiyi مستقر الانتشار الصيني والإنجليزية ثنائية اللغة
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| الحصان الحديدي ونهر الجليد يأتي إلى الحلم ، اللوحة ثلاثية الأبعاد. | يتدفق الطيران لأسفل ثلاثة آلاف قدم ، وهي لوحة زيتية. | ظهر الفتاة ، غروب الشمس ، توضيح جميل. |
|---|---|---|
 |  |  |
موجه متقدم
| يأتي نهر Iron Horse Ice إلى الحلم ، والرسم المفاهيم ، والخيال العلمي ، والخيال ، والثلاثي الأبعاد | المدينة الساحلية الصينية ، الخيال العلمي ، الشعور المستقبلي ، الجمال ، التوضيح. | كان الرجل في الأضواء الخافتة ، بألوان زاهية وأسلوب قديم ، يعمل من قبل كبار الرسامين ، وخلفيات HD على سطح المكتب. |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
من أجل السماح للجميع بالاستفادة الجيدة من نموذج Fengshen Bang Big والمشاركة في التدريب المستمر للنموذج الكبير والتطبيقات المصب ، نفتح في وقت واحد مصدر إطار Fengshen المتمحور حول المستخدم. للحصول على تفاصيل ، يرجى الاطلاع على: Fringshen (Fengshen) Framework.
نشير إلى أطر عمل ممتازة مفتوحة المصدر مثل Huggingface و Megatron-LM و Pytorch-Lightning و Deepspeed. إلى جانب خصائص حقل NLP ، أعادت Pytorch-Lightning تصميم Fengshen لخط الأنابيب مع Pytorch باعتبارها الإطار الأساسي. يمكن استخدام Fengshen لتدريب نماذج كبيرة مسبقًا (معلمات ذات مستوى 10 مليارات) استنادًا إلى بيانات ضخمة (بيانات على مستوى السل) وضبط مختلف مهام المصب. يمكن للمستخدمين بسهولة تنفيذ التدريب الموزع وحفظ ذاكرة الفيديو من خلال التكوين ، مع التركيز أكثر على تنفيذ النموذج والابتكار. في الوقت نفسه ، يمكن لـ Fengshen أيضًا استخدام بنية النموذج مباشرة في Luggingface للتدريب المستمر ، مما يسهل المستخدمين إلى ترحيل نماذج المجال. يوفر Fengshen رمز المصدر الغني والحقيقي وأمثلة لتطبيق النماذج ونماذج المصدر المفتوح في Fengshen Bang. مع تدريب وتطبيق نموذج Fengshen Bang ، سنواصل تحسين إطار Fengshen ، لذلك ترقبوا.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .نحن نقدم Docker بسيط يتضمن بيئات Torch و CUDA لتشغيل إطار عملنا.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦يتم تكييف إطار الاستثمار حاليًا مع خط أنابيب لمختلف مهام المصب ، ويدعم بداية النقر بزر المادة واحدة للتنبؤ والتعبير على سطر الأوامر. خذ تصنيف النص كمثال
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpابدأ في ثلاث دقائق
يبدأ استثمار سلسلة الآلهة بالتوازي البيانات
إن استثمار سلسلة الآلهة هو الوقت المناسب لتسريع تدريبك
ما قبل تدريب نموذج بيجاسوس الصيني في سلسلة استثمار الآلهة
سلسلة قائمة الآلهة: فاز Finetune Erlang Shen بطريق الخطأ بالمركز الأول
سلسلة استثمار الآلهة: سرعان ما بناء خوارزمية العرض التوضيحي
2022 مسابقة Aiwin World للابتكار الذكاء الاصطناعي: حلول بطولة تعدد المهام الصغيرة
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
أنشأ الفريق الفني CCNL لمعهد أبحاث الأفكار مجموعة مناقشة مفتوحة المصدر لاستثمار الآلهة. سنقوم بتحديث ونطلق نماذج جديدة وسلسلة من المقالات في مجموعة المناقشة من وقت لآخر. يرجى مسح رمز الاستجابة السريعة أدناه أو البحث عن "Fengshenbang-LM" على WeChat لإضافة مساعد إلى Fengshen Space للانضمام إلى المجموعة للتواصل!

نحن نستمر أيضًا في تجنيد أشخاص ، مرحبًا بك لتقديم سيرتنا الذاتية!

ترخيص Apache 2.0


