Fengshenbang LM
1.0.0
Chinês | Inglês
Fengshenbang 1.0 : A investidura do Plano de código aberto 1.0 Papel bilíngue chinês e inglês visa se tornar a infraestrutura da inteligência cognitiva chinesa.
BioBart : Modelo de linguagem generativa para o campo da biomedicina fornecida pela Universidade de Tsinghua e pelo Instituto de Pesquisa de Idéias. (
BioNLP 2022)
Unimc : um modelo unificado com base nos conjuntos de dados de etiquetas em cenários de tiro zero. (
EMNLP 2022)
FMIT : Modelo de reconhecimento de entidade nomeado de torre única de torre única com base na codificação de posição relativa. (
COLING 2022)
UNIEX : Um modelo de compreensão de linguagem natural para tarefas de extração unificada. (
ACL 2023)
Resolvendo problemas de palavras matemáticas por meio de modelos de idiomas induzidos por raciocínio cooperativo : resolvendo problemas matemáticos usando uma estrutura de raciocínio colaborativo para modelos de idiomas. (
ACL 2023)
Tuneamento MVP : um sistema de perguntas e respostas de senso comum com eficiência de parâmetro com base na recuperação de conhecimento com várias perspectivas. (
ACL 2023)
| Nome da série | precisar | Tarefas aplicáveis | Escala de parâmetros | Observação |
|---|---|---|---|---|
| Jiang Ziya | Em geral | Modelo Geral | > 7 bilhões de parâmetros | A série Geral Model "Jiang Ziya" tem a capacidade de traduzir, programação, classificação de texto, extração de informações, abstrato, geração de redação, pergunta e resposta do senso comum e cálculos matemáticos. |
| Taiyi | específico | Multimodal | 80 a 1 bilhão de parâmetros | Aplicado a cenas cruzadas, incluindo geração de imagens de texto, previsão da estrutura de proteínas, representação de texto de fala, etc. |
| Erlang Shen | Em geral | Compreensão da linguagem | 90 milhões a 3,9 bilhões de parâmetros | Lidar com as tarefas de compreensão, tenha o maior modelo de apostas chinesas quando o código aberto, chegue ao topo de FewClue e Zeroclue em 2021 |
| Wen Zhong | Em geral | Geração de idiomas | 100 milhões a 3,5 bilhões de parâmetros | Focando em tarefas de geração, fornecendo vários modelos de geração com diferentes parâmetros, como GPT2, etc. |
| Iluminação | Em geral | Conversão de idiomas | 70 milhões a 5 bilhões de parâmetros | Lidar com várias tarefas que convertem do texto de origem para o tipo de texto de destino, como tradução para a máquina, resumo do texto, etc. |
| Yu yuan | específico | campo | 100 milhões a 3,5 bilhões de parâmetros | É aplicado a campos como médico, finanças, direito, programação etc. Tenha o maior modelo médico de código aberto GPT2 atualmente |
| -Trinar a ser determinado- | específico | explorar | -desconhecido- | Esperamos desenvolver modelos experimentais relacionados à PNL com várias empresas de tecnologia e universidades. Atualmente: rei Wen de Zhou |
Baixe o link do modelo de investimento dos deuses
Investrito do modelo de treinamento modelo dos deuses e scripts de código de ajuste fino
Manual de Treinamento para Modelo de Investrito de Gods
Avanços significativos na inteligência artificial produziram muitos grandes modelos, especialmente os modelos básicos baseados no pré-treinamento, tornaram-se um paradigma emergente. Os modelos tradicionais de IA devem ser treinados em um conjunto de dados enorme dedicado para um ou vários cenários limitados, por outro lado, os modelos subjacentes podem se adaptar a uma ampla gama de tarefas a jusante. O modelo básico cria a possibilidade de o pouso de IA em cenários de baixo recurso.
Observamos que a quantidade de parâmetros nesses modelos está crescendo a uma taxa de 10 vezes por ano. Em 2018, o BERT foi de apenas 100 milhões no volume de parâmetros, mas até 2020, o volume de parâmetros do GPT-3 atingiu a ordem de 10 bilhões. Devido a essa tendência inspiradora, muitos desafios de ponta na inteligência artificial, especialmente as poderosas capacidades de generalização, se tornaram gradualmente possíveis.
Os modelos básicos de hoje, especialmente os modelos de idiomas, estão sendo dominados pela comunidade inglesa. Ao mesmo tempo, como o maior idioma falado do mundo (entre falantes nativos), os chineses carecem de recursos sistemáticos de pesquisa, o que faz o progresso da pesquisa no campo chinês um pouco em comparação com o inglês.
Este mundo precisa de uma resposta.
In order to solve the problems of lagging research progress in the Chinese field and serious shortage of research resources, on November 22, 2021, Shen Xiangyang, chairman of the founding institute of IDEA Research Institute, officially announced at the IDEA conference that the "Fengshen Bang" open source system will be launched - a basic ecosystem driven by Chinese, including pre-trained large models, fine-tuning applications for specific tasks, benchmarks and data sets, etc. Nosso objetivo é criar um ecossistema abrangente, padronizado e centrado no usuário. 
O "Fengshen Bang Model" abrirá uma série de uma série de modelos grandes pré-treinados relacionados ao NLP em todos os aspectos. Existem extensas tarefas de pesquisa na comunidade da PNL, que podem ser divididas em duas categorias: tarefas gerais e especiais. O primeiro inclui tarefas de entendimento da linguagem natural (NLU), geração de linguagem natural (NLG) e conversão de linguagem natural (NLT). O último abrange tarefas como multimodais, específicos de domínio, etc. Consideramos todas essas tarefas e fornecemos modelos relacionados ajustados a tarefas a jusante, o que facilita para usuários com recursos de computação limitados para usar nosso modelo básico. E prometemos continuar atualizando esses modelos e integram continuamente os dados mais recentes e os mais recentes algoritmos de treinamento. Através dos esforços do Idea Research Institute, construiremos uma infraestrutura geral para a inteligência cognitiva chinesa, evitaremos a construção duplicada e economizaremos poder de computação para toda a sociedade.
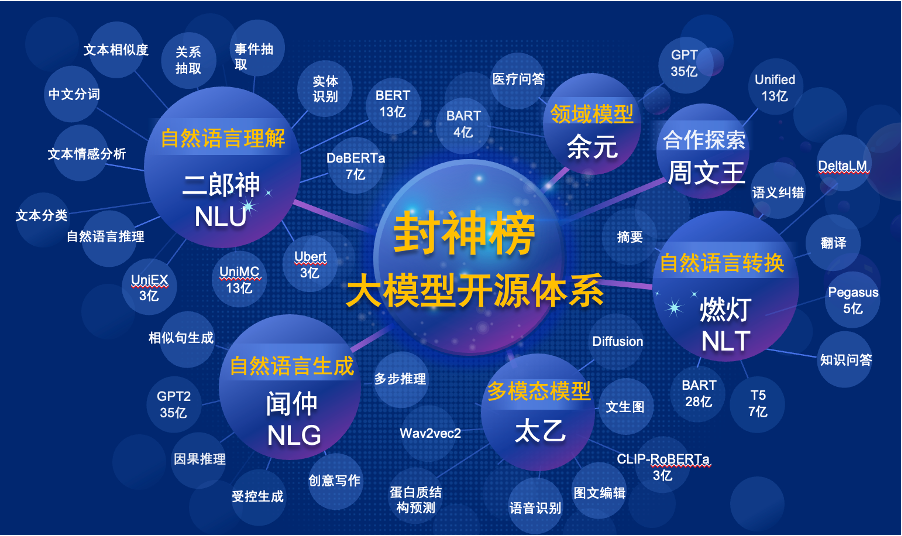
Ao mesmo tempo, o "Fengshen Bang" também espera que várias empresas, universidades e instituições se juntem a esse plano de código aberto e construam em conjunto um sistema de código aberto em larga escala. No futuro, quando precisamos de um novo modelo pré-treinado, devemos primeiro selecionar o mais próximo desses modelos de código aberto, continuar treinando e depois o código aberto o novo modelo de volta a este sistema. Dessa forma, todos podem obter seu próprio modelo com o menor poder de computação, e o sistema de modelo grande de código aberto também pode se tornar cada vez maior.

Para ter uma experiência melhor, abraçar a comunidade de código aberto, todos os modelos da investigação dos deuses são convertidos e sincronizados à comunidade Huggingface. Você pode usar facilmente todos os modelos de investigação dos deuses com algumas linhas de código. Bem-vindo à comunidade Huggingface do Idea-CCNL para baixar.
A série Geral Model "Jiang Ziya" tem a capacidade de traduzir, programação, classificação de texto, extração de informações, abstrato, geração de redação, pergunta e resposta do senso comum e cálculo matemático. Atualmente, o Modelo Geral de Jiang Ziya (V1/V1.1) concluiu três estágios de treinamento: pré-treinamento em larga escala, ajuste supervisionado com várias tarefas e aprendizado de feedback humano. Os modelos da série Jiang Ziya incluem os seguintes modelos:
Referência Ziya-llama-13b-V1
Referência ziya_fineneTune
Referência Ziya_inference
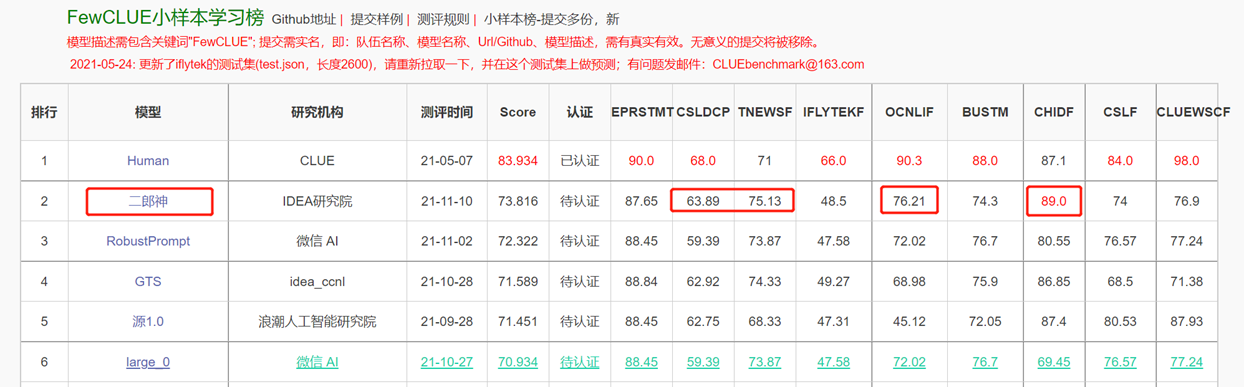
O modelo de linguagem bidirecional com estrutura do codificador está focada na solução de várias tarefas de compreensão de linguagem natural. O modelo Erlang Shen-1.3b com 1,3 bilhão de parâmetros usa dados 280g e 32 A100s são treinados por 14 dias. É o maior modelo Bert Bert Chinese de código aberto. Em 10 de novembro de 2021, liderou a lista da referência de avaliação autorizada para a compreensão do idioma chinês. Entre eles, o PHID (IDIOM preenchem asenasceis), o TNEWS (Classificação de Notícias) superou os seres humanos, o PHID (Idiom preenchendo as quentes), o CSLDCP (classificação da literatura disciplina) e o OCNLI (raciocínio de linguagem natural) têm o primeiro lugar em tarefas únicas, e o pequeno registro de amostra é atualizado. A série Erlang Shen continuará otimizando em termos de escala de modelo, integração de conhecimento, assistência à tarefa de supervisão etc.
Em 24 de janeiro de 2022, o Erlang Shen-MRC liderou a lista de zeroclue na avaliação do idioma chinês Zeroclue. Entre eles, o CSLDCP (Classificação da Literatura da Disciplina), TNEWS (Classificação de Notícias), IFLYTEK (Classificação da Descrição do Aplicativo), CSL (Reconhecimento de palavras -chave abstratas) e ClueWSC (referindo -se à digestão) são todos os primeiros. 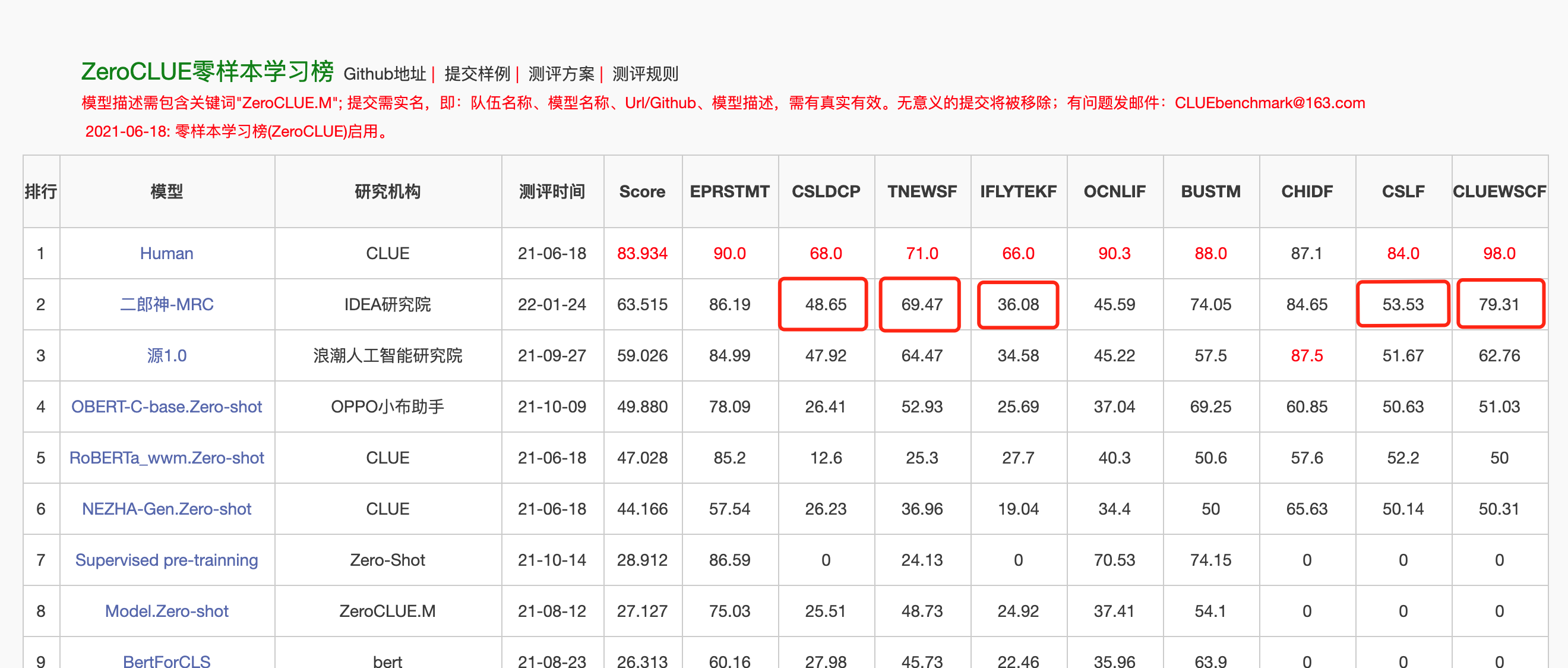
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )Para facilitar os desenvolvedores a usar rapidamente nosso modelo de código aberto, aqui está um script de amostra FineTune para tarefas a jusante, usando os dados da tarefa de classificação de notícias do TNEWS sobre pista, e o script é executado da seguinte forma. Onde data_path é o caminho dos dados e o endereço de download dos dados da tarefa TNEWS.
1. Primeiro modifique os parâmetros Model_Type e Pretreden_Model_Path no script de amostra Finetune FineTune_classification.sh. Outros parâmetros como Batch_size, Data_Dir, etc. podem ser modificados de acordo com seu próprio dispositivo.
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2. Em seguida, corra:
sh finetune_classification.sh| Modelo | AFQMC | tnews | iflytek | Ocnli | cmnli | WSC | csl |
|---|---|---|---|---|---|---|---|
| Roberta-Wwm-Ext-Large | 0,7514 | 0,5872 | 0,6152 | 0,777 | 0,814 | 0,8914 | 0,86 |
| Erlangshen-megatronbert-1.3b | 0,7608 | 0,5996 | 0,6234 | 0,7917 | 0,81 | 0,9243 | 0,872 |
A série de modelos de Taiyi é usada principalmente em cenários cruzados, incluindo geração de imagens de texto, previsão da estrutura de proteínas, representação de texto da fala, etc. Em 1º de novembro de 2022, a investimento dos deuses abriu a fonte da primeira versão chinesa do modelo de difusão estável "Taiyi estável".
Taiyi Difusão estável Versão chinesa pura
Taiyi Difusão estável Versão bilíngue chinesa e inglesa
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| O cavalo de ferro e o rio Ice chega ao sonho, pintura em 3D. | O fluxo voador por três mil pés, uma pintura a óleo. | Garota de volta, pôr do sol, bela ilustração. |
|---|---|---|
 |  |  |
Prompt avançado
| Iron Horse Ice River chega a sonho, pintura conceitual, ficção científica, fantasia, 3d | Cidade litorânea da China, ficção científica, senso futurista, beleza, ilustração. | O homem estava nas luzes fracas, com cores brilhantes e estilo antigo, funciona de ilustradores seniores e papéis de parede HD de mesa. |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
Para permitir que todos façam bom uso do Fengshen Bang Big Model e participem do treinamento contínuo do Big Model e a jusante de aplicativos, abrimos simultaneamente a estrutura do Fengshen centrada no usuário. Para obter detalhes, consulte: estrutura de fengshen (fengshen).
Nós nos referimos a excelentes estruturas de código aberto, como Huggingface, Megatron-LM, Pytorch-Lightning e DeepSpeed. Combinado com as características do campo PNL, o Fengshen redesenhado de Pytorch, com Pytorch, para Pytorch como a estrutura básica. O fengshen pode ser usado para pré-treinamento de grandes modelos (parâmetros de 10 bilhões de níveis) com base em dados maciços (dados no nível da TB) e ajuste fino de várias tarefas a jusante. Os usuários podem executar facilmente treinamento distribuído e salvar a memória de vídeo através da configuração, concentrando -se mais na implementação e inovação do modelo. Ao mesmo tempo, o fengshen também pode usar diretamente a estrutura do modelo no HuggingFace para o treinamento contínuo, o que facilita os usuários a migrar os modelos de domínio. O Fengshen fornece código -fonte rico e real e exemplos para a aplicação de modelos de código aberto e modelos de fengshen bang. Com o treinamento e a aplicação do modelo Fengshen Bang, continuaremos a otimizar a estrutura do Fengshen, portanto, fique atento.
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .Fornecemos um Docker simples que inclui ambientes de tocha e CUDA para executar nossa estrutura.
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦Atualmente, a estrutura de investimento está adaptada ao pipeline para várias tarefas a jusante e suporta o início de um clique do previsão e finetuning na linha de comando. Tome a classificação de texto como exemplo
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddpComece em três minutos
A investimento da série Gods começa com o paralelismo de dados
A série de investimentos da Gods é hora de acelerar seu treinamento
Pré-treinamento do modelo chinês de Pegasus na série de investimentos da Gods
A série Lista de Deus: Finetune Erlang Shen acidentalmente conquistou o primeiro lugar
Série Investituta de Gods: Construindo rapidamente sua demonstração de algoritmo
2022 Aiwin World Artificial Intelligence Innovation Competition: amostra de amostra de solução de trilhas multitarefa
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
A equipe técnica do CCNL do Idea Research Institute criou um grupo de discussão de código aberto para a investigação dos deuses. Atualizaremos e lançaremos novos modelos e séries de artigos no grupo de discussão de tempos em tempos. Digitalize o código QR abaixo ou pesquise "Fengshenbang-lm" no WeChat para adicionar o assistente ao espaço do Fengshen para se juntar ao grupo para se comunicar!

Também continuamos a recrutar pessoas, bem -vindo a enviar nossos currículos!

Licença Apache 2.0


