Fengshenbang LM
1.0.0
中国語|英語
Fengshenbang 1.0 :オープンソースプランの投資1.0中国と英語のバイリンガルペーパーは、中国の認知インテリジェンスのインフラストラクチャになることを目指しています。
Biobart :Tsinghua UniversityおよびIdea Research Instituteが提供する生物医学の分野の生成言語モデル。 (
BioNLP 2022)
UNIMC :ゼロショットシナリオのラベルデータセットに基づく統一モデル。 (
EMNLP 2022)
fmit :相対位置コーディングに基づいたシングルタワーマルチモーダル名前付きエンティティ認識モデル。 (
COLING 2022)
Uniex :統一された抽出タスクの自然言語理解モデル。 (
ACL 2023)
協力的な推論による数学の問題の解決誘導言語モデル:言語モデルの共同推論フレームワークを使用して数学的問題を解決します。 (
ACL 2023)
MVP-Tuning :マルチパリスペクティブナレッジトレイバルに基づくパラメーター効率的な常識的な質問および回答システム。 (
ACL 2023)
| シリーズ名 | 必要 | 適用されるタスク | パラメータースケール | 述べる |
|---|---|---|---|---|
| 江Ziya | 一般的な | 一般モデル | 70億パラメーター | 一般的なモデル「Jiang Ziya」シリーズには、翻訳、プログラミング、テキスト分類、情報抽出、抽象、コピーライティングの生成、常識的な質問と回答、数学の計算を翻訳する機能があります。 |
| 台湾 | 特定の | マルチモーダル | 8000万から10億パラメーター | テキスト画像生成、タンパク質構造予測、音声テキスト表現などを含むクロスモーダルシーンに適用されます。 |
| エルラン・シェン | 一般的な | 言語理解 | 9000万から39億パラメーター | タスクの理解を処理し、オープンソースのときに最大の中国の賭けモデルを持っている、2021年に数え切れないようにゼロクルーの頂点に到達する |
| ウェン・チャン | 一般的な | 言語生成 | 1億から35億のパラメーター | 生成タスクに焦点を当て、GPT2など、さまざまなパラメーターを備えた複数の生成モデルを提供します。 |
| 点灯 | 一般的な | 言語変換 | 7000万から50億のパラメーター | 機械翻訳、テキストの概要など、ソーステキストからターゲットテキストタイプに変換するさまざまなタスクを処理します。 |
| Yu Yuan | 特定の | 分野 | 1億から35億のパラメーター | 医療、金融、法律、プログラミングなどの分野に適用されています。現在、最大のオープンソースGPT2医療モデルを持っています |
| - 決心することを試してみてください - | 特定の | 探検する | -未知- | さまざまなテクノロジー企業や大学とともに、NLPに関連する実験モデルを開発したいと考えています。現在:ZhouのWen王 |
Gods of Godsモデルのリンクをダウンロードします
神々のモデルトレーニングと微調整コードスクリプトの投資
Gods Model Training ManualのInvestiture
人工知能の大幅な進歩により、多くの優れたモデルが生み出されました。特に、トレーニング前に基づく基本モデルが新興のパラダイムになりました。従来のAIモデルは、1つまたは複数の限定シナリオ用に専用の巨大なデータセットでトレーニングする必要があります。対照的に、基礎となるモデルは、さまざまなダウンストリームタスクに適応できます。基本モデルは、低リソースシナリオにAIが着陸する可能性を生み出します。
これらのモデルのパラメーターの量は、年間10回の割合で成長していることがわかります。 2018年、Bertはパラメーターボリュームでわずか1億人でしたが、2020年までにGPT-3のパラメーター量が100億オーダーに達しました。この刺激的な傾向により、人工知能、特に強力な一般化能力の多くの最先端の課題が徐々に可能になりました。
今日の基本モデル、特に言語モデルは、英語コミュニティに支配されています。同時に、世界最大の音声言語(ネイティブスピーカーの間)と同時に、中国語には体系的な研究リソースがありません。
この世界には答えが必要です。
2021年11月22日に、中国の分野での研究の進捗状況と研究リソースの深刻な不足の問題を解決するために、アイデア研究所の設立研究所の議長であるシェン・Xiangyangは、「フェンシェンバング」のオープンソースシステムが開始されることを正式に発表しました。セットなど。私たちの目標は、包括的な、標準化された、ユーザー中心のエコシステムを構築することです。 
「Fengshen Bang Model」は、あらゆる面で一連のNLP関連の事前訓練を受けた大型モデルをオープンします。 NLPコミュニティには、一般的なタスクと特別なタスクの2つのカテゴリに分けることができる広範な研究タスクがあります。前者には、自然言語理解(NLU)、自然言語生成(NLG)、自然言語変換(NLT)タスクが含まれます。後者は、マルチモーダル、ドメイン固有などのタスクをカバーしています。これらのタスクをすべて検討し、下流タスクで微調整された関連モデルを提供するため、コンピューティングリソースが限られているユーザーが基本モデルを簡単に使用できます。また、これらのモデルを引き続きアップグレードし、最新のデータと最新のトレーニングアルゴリズムを継続的に統合することを約束します。 Idea Research Instituteの努力を通じて、中国の認知インテリジェンスのための一般的なインフラストラクチャを構築し、構造の重複を避け、社会全体のコンピューティングパワーを節約します。
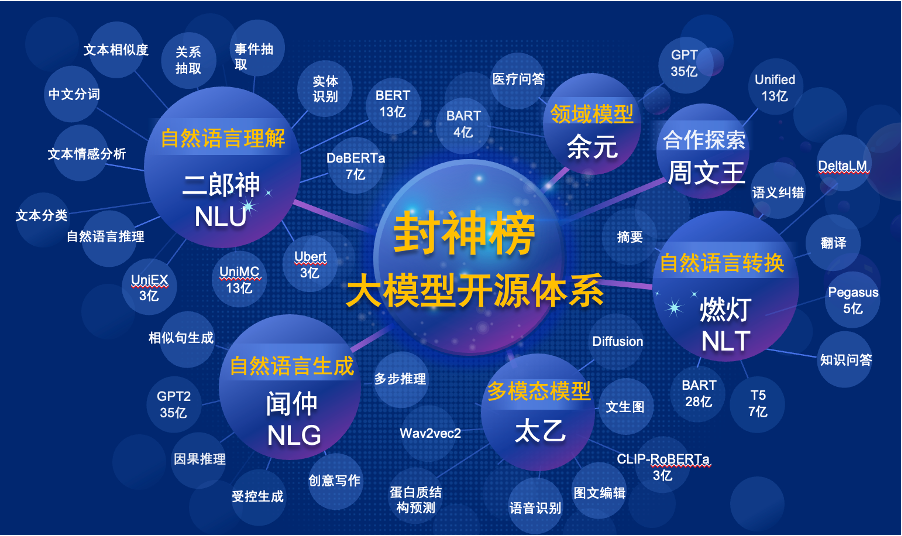
同時に、「Fengshen Bang」は、さまざまな企業、大学、機関がこのオープンソース計画に参加し、共同で大規模なオープンソースシステムを構築することを望んでいます。将来的には、新しい訓練を受けた新しいモデルが必要な場合は、まずこれらのオープンソースモデルから最も近いモデルを選択し、トレーニングを継続し、新しいモデルをこのシステムに戻す必要があります。このように、誰もが最小のコンピューティング能力で独自のモデルを取得することができ、オープンソースの大きなモデルシステムもより大きくなります。

より良い体験をするために、オープンソースコミュニティを受け入れるために、神の調査のすべてのモデルが転換され、ハギングフェイスコミュニティに同期されます。数行のコードを使用して、神々の調査のすべてのモデルを簡単に使用できます。ダウンロードするためにIdea-CCNLのHuggingfaceコミュニティへようこそ。
一般的なモデル「Jiang Ziya」シリーズには、翻訳、プログラミング、テキスト分類、情報抽出、抽象、コピーライティングの生成、常識的な質問と回答、数学的計算を翻訳する機能があります。現在、Jiang Ziyaの一般モデル(V1/V1.1)は、大規模なトレーニング、マルチタスク監視微調整、人間のフィードバック学習の3つの段階のトレーニングを完了しました。 Jiang Ziyaシリーズモデルには、次のモデルが含まれています。
参照Ziya-llama-13b-v1
参照Ziya_fineneTune
参照Ziya_inference
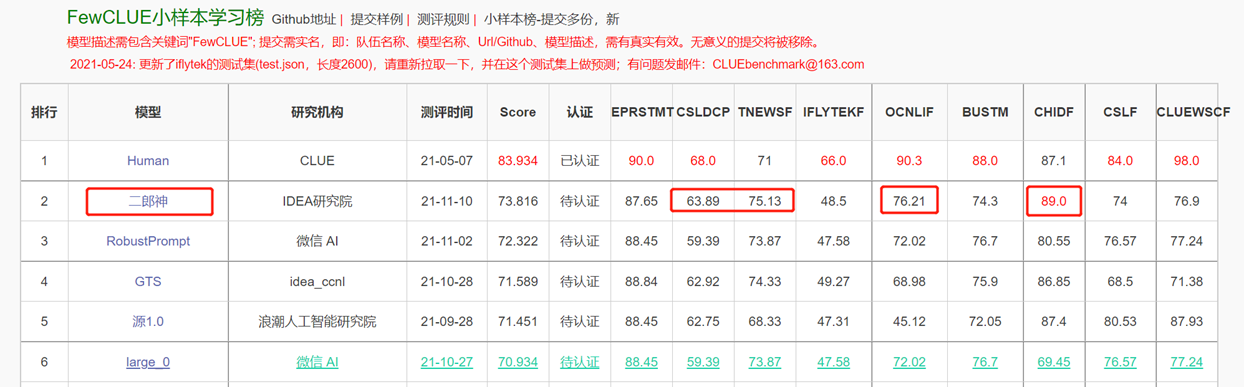
エンコーダー構造を備えた双方向言語モデルは、さまざまな自然言語理解タスクの解決に焦点を当てています。 13億パラメーターを備えたErlang Shen-1.3Bのビッグモデルでは、280gのデータを使用し、32 A100が14日間トレーニングされています。これは、最大のオープンソース中国のバートビッグモデルです。 2021年11月10日に、中国語の理解のための権威ある評価ベンチマークのリストのトップになりました。その中で、Chid(Idiom Fill-in the-Blanks)、Tnews(ニュース分類)は人間を超え、Chid(Idiom Fill-in the Blanks)、CSLDCP(規律文献分類)、およびOcnli(自然言語の推論)は、単一のタスクで最初の位置を持ち、小さなサンプルの学習記録はリフレッシュされます。 Erlang Shenシリーズは、モデルスケール、知識統合、監督タスク支援などの観点から引き続き最適化されます。
2022年1月24日、Erlang Shen-MRCは、中国語理解評価ZeroclueのZeroclueリストのトップになりました。その中で、CSLDCP(規律文献分類)、TNEWS(ニュース分類)、Iflytek(アプリケーション説明分類)、CSL(要約キーワード認識)、およびClueWSC(消化を参照)はすべて最初です。 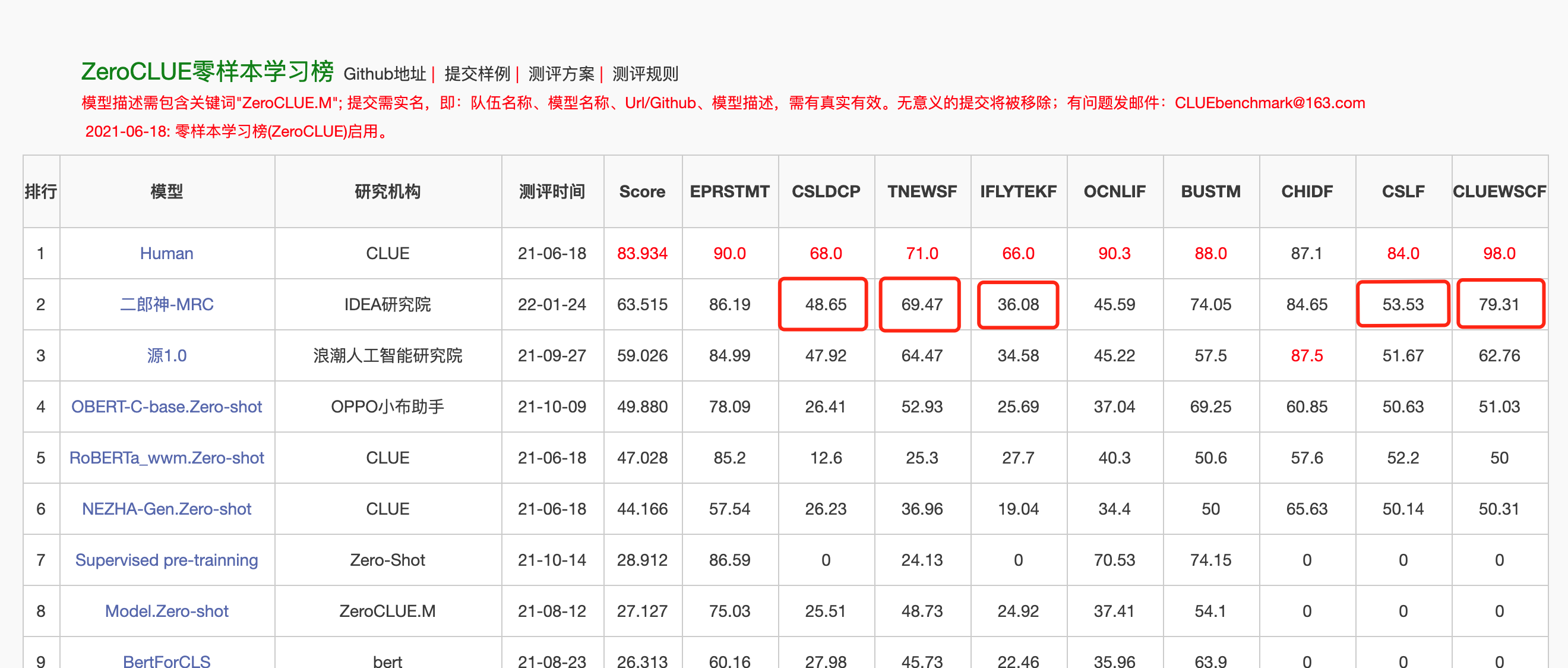
Huggingface Erlang Shen-1.3b
from transformers import MegatronBertConfig , MegatronBertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
config = MegatronBertConfig . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )
model = MegatronBertModel . from_pretrained ( "IDEA-CCNL/Erlangshen-MegatronBert-1.3B" )開発者がオープンソースモデルをすばやく使用できるようにするために、TNEWSニュース分類タスクデータをClueで使用して、下流タスクのFinetuneサンプルスクリプトを以下に示し、スクリプトは次のように実行されます。ここで、data_pathはデータパスであり、tnewsタスクデータのダウンロードアドレスです。
1. FinetuneサンプルスクリプトFinetune_Classification.shのModel_TypeおよびPretrained_Model_Pathパラメーターを最初に変更します。 batch_size、data_dirなどの他のパラメーターは、独自のデバイスに従って変更できます。
MODEL_TYPE=huggingface-megatron_bert
PRETRAINED_MODEL_PATH=IDEA-CCNL/Erlangshen-MegatronBert-1.3B2。その後、実行します:
sh finetune_classification.sh| モデル | AFQMC | tnews | iflytek | ocnli | cmnli | WSC | CSL |
|---|---|---|---|---|---|---|---|
| roberta-wwm-ext-large | 0.7514 | 0.5872 | 0.6152 | 0.777 | 0.814 | 0.8914 | 0.86 |
| erlangshen-megatronbert-1.3b | 0.7608 | 0.5996 | 0.6234 | 0.7917 | 0.81 | 0.9243 | 0.872 |
一連のモデルは、主にテキスト画像生成、タンパク質の予測、音声テキスト表現などを含むクロスモーダルシナリオで使用されています。
Taiyi安定拡散純粋な中国語版
Taiyi安定した拡散中国語および英語のバイリンガルバージョン
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained ( "IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1" ). to ( "cuda" )
prompt = '飞流直下三千尺,油画'
image = pipe ( prompt , guidance_scale = 7.5 ). images [ 0 ]
image . save ( "飞流.png" )| アイアンホースとアイスリバーは、3D絵画、ドリームに来ます。 | 空飛ぶ流れは3000フィート、油絵。 | 女の子の背中、日没、美しいイラスト。 |
|---|---|---|
 |  |  |
高度なプロンプト
| アイアンホースアイスリバーが夢、コンセプトペインティング、サイエンスフィクション、ファンタジー、3Dにやってくる | 中国の海辺の都市、サイエンスフィクション、未来的な感覚、美しさ、イラスト。 | 男は明るい色と古代のスタイルで薄暗い光の中にいて、シニアイラストレーターとデスクトップHDの壁紙によって作品をしていました。 |
|---|---|---|
 |  |  |
https://github.com/idea-ccnl/fengshenbang-lm/blob/main/fengshen/examples/stable_diffusion_chinese/taiyi_handbook.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/finetune_taiyi_stable_diffusion
https://github.com/idea-ccnl/stable-diffusion-webuui/blob/master/readme.md
https://github.com/idea-ccnl/fengshenbang-lm/tree/main/fengshen/examples/stable_diffusion_dreambooth
全員がFengshen Bang Bigモデルをうまく利用し、ビッグモデルおよびダウンストリームアプリケーションの継続的なトレーニングに参加できるようにするために、ユーザー中心のFengshenフレームワークを同時にオープンします。詳細については、Fengshen(Fengshen)フレームワークをご覧ください。
Huggingface、Megatron-LM、Pytorch-Lightning、DeepSpeedなどの優れたオープンソースフレームワークを参照してください。 NLPフィールドの特性と組み合わされて、Pytorch-Lightningは基本的なフレームワークとしてPytorchを使用したパイプラインのためにFengshenを再設計しました。 Fengshenは、大規模なデータ(TBレベルのデータ)とさまざまなダウンストリームタスクの微調整に基づいて、大規模なモデル(100億レベルのパラメーター)を事前にトレーニングするために使用できます。ユーザーは、分散トレーニングを簡単に実行し、構成を通じてビデオメモリを保存し、モデルの実装とイノベーションに重点を置いています。同時に、Fengshenは、継続的なトレーニングのためにHuggingfaceでモデル構造を直接使用することもできます。これにより、ユーザーはドメインモデルを移行します。 Fengshenは、Fengshen Bangのオープンソースモデルとモデルを適用するためのリッチでリアルソースコードと例を提供します。 Fengshen Bangモデルのトレーニングと適用により、Fengshenフレームワークを最適化し続けるため、ご期待ください。
git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
cd Fengshenbang-LM
git submodule init
git submodule update
# submodule是我们用来管理数据集的fs_datasets,通过ssh的方式拉取,如果用户没有在机器上配置ssh-key的话可能会拉取失败。
# 如果拉取失败,需要到.gitmodules文件中把ssh地址改为https地址即可。
pip install --editable .フレームワークを実行するためのトーチ環境とCUDA環境を含むシンプルなDockerを提供します。
sudo docker run --runtime=nvidia --rm -itd --ipc=host --name fengshen fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel
sudo docker exec -it fengshen bash
cd Fengshenbang-LM
# 更新代码 docker内的代码可能不是最新的
git pull
git submodule foreach ' git pull origin master '
# 即可快速的在docker中使用我们的框架啦Investiture Frameworkは現在、さまざまなダウンストリームタスクのパイプラインに適合しており、コマンドラインでの予測と微調整のワンクリック開始をサポートしています。例としてテキスト分類を取得します
# predict
❯ fengshen - pipeline text_classification predict - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - text = '今天心情不好[SEP]今天很开心'
[{ 'label' : 'not similar' , 'score' : 0.9988130331039429 }]
# train
fengshen - pipeline text_classification train - - model = 'IDEA-CCNL/Erlangshen-Roberta-110M-Similarity' - - datasets = 'IDEA-CCNL/AFQMC' - - gpus = 0 - - texta_name = sentence1 - - strategy = ddp3分で始めましょう
Godsシリーズの投資は、データの並列性から始まります
Godsシリーズの投資はあなたのトレーニングをスピードアップする時です
投資の神々シリーズにおける中国のペガサスモデルの事前訓練
Gods Listシリーズ:Finetune Erlang Shenが誤って1位を獲得しました
Investiture of Godsシリーズ:アルゴリズムのデモをすばやく構築します
2022 AIWIN WORLD人工知能イノベーションコンペティション:小型サンプルマルチタスクトラックチャンピオンシップソリューション
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
也可以引用我们的网站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
Idea Research InstituteのCCNLテクニカルチームは、神々の投資のためのオープンソースディスカッショングループを設立しました。ディスカッショングループの新しいモデルと一連の記事を時々更新およびリリースします。以下のQRコードをスキャンするか、WeChatで「Fengshenbang-LM」を検索して、アシスタントをFengshen Spaceに追加してグループに参加してコミュニケーションを取ります。

また、私たちは人々を募集し続けています。履歴書を提出してください!

Apacheライセンス2.0


