StableDiffusion2 Image to Text
1.0.0
該存儲庫包含用於微調模型的Python代碼,這些模型可以預測生成圖像中的提示和/或嵌入。通常知道的過程是從給定文本中生成圖像是彎曲趨勢的作業提示工程師的流行過程;但是,這個存儲庫。專注於反向過程,該過程預測了給出的文本提示以生成圖像。給定一組數據作為及時圖像對,以下模型進行了微調以預測文本或文本嵌入:
以下是SD2的一些示例提示圖。這項工作的目的是預測用於生成圖像的及時文本。給定一個數據集,如下所示,該存儲庫中的代碼。可以用來微調各種模型,以預測給出生成的圖像時的文本提示。
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


該存儲庫中的工作是Kaggle穩定擴散的一部分 - 提示競爭的圖像。這是我在比賽中創建的代碼,並能夠在比賽中獲得前5%的成績。
訓練這些模型並以穩定的擴散2生成圖像是資源密集型的,並要求GPU。可以採取措施來幫助加速圖像產生,例如:
使用這些步驟,具有RTX 3090,以大約2s/圖像生成圖像。
使用IMG2DATASET軟件包通過URL下載了及時圖像對數據集。在線URL數據集的一些示例是:
使用穩定的擴散版本2創建自定義提示圖對數據集。我建議用戶有興趣使用穩定擴散2創建自己的數據集2的用戶,請遵循穩定擴散版2的常用說明。
需要對其進行微調的模型進行相應格式化及時圖像對。請參閱./notebooks/data-format-train-val.ipynb其中顯示瞭如何格式化各種數據集。
許多在線及時圖像對數據集都包含高度相似的提示,這可能會導致模型通常會出現提示,並且在各種文本提示上的表現不佳。因此,使用啟用GPU的餘弦相似性索引或相似性搜索將它們刪除相似的提示。請參閱./utils/filt_embeds.py ,其中包含代碼快速索引和過濾文本嵌入。
此過程是在利用Faiss圖書館的GPU上進行的。 Faiss是一個庫,用於有效的相似性搜索和密集向量的聚類。它包含在任何大小的向量集中搜索的算法,最多可能不適合RAM。
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ())COCA體系結構是一種新穎的編碼器方法,同時產生了對齊的單峰圖像和文本嵌入和聯合多模式表示形式,使其足夠靈活,可以直接適用於所有類型的下游任務。具體而言,可口可樂在一系列視覺識別,跨模式對準和多模式理解的一系列視覺和視覺任務上取得了最新的結果。此外,它學習了高通用表示形式,因此它可以比具有零拍學習或冷凍編碼器的完全微調模型表現出色或更好。根據此處的建議進行了微調。可口可樂體系結構如下所示,並取自來源。 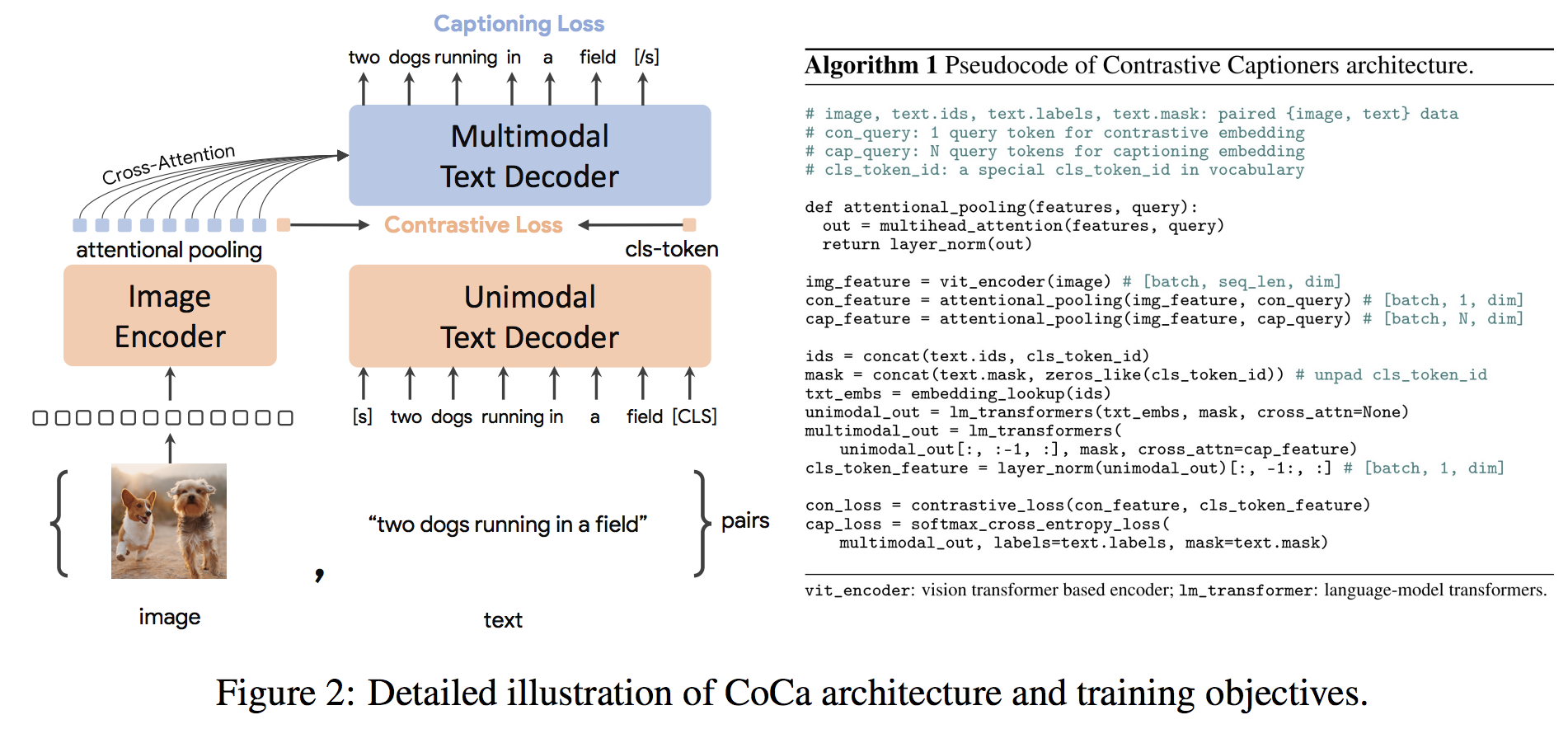
python代碼到微調可可coca在./scripts/train_COCA.py中,下面給出了bash命令:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 剪輯(對比性語言圖像預訓練)是一個在各種(圖像,文本)對的神經網絡。可以用自然語言指示它,以預測給定圖像的最相關的文本段,而無需直接對任務進行優化,類似於GPT-2和3的零拍功能。剪輯體系結構如下圖所示,並從源中獲取。 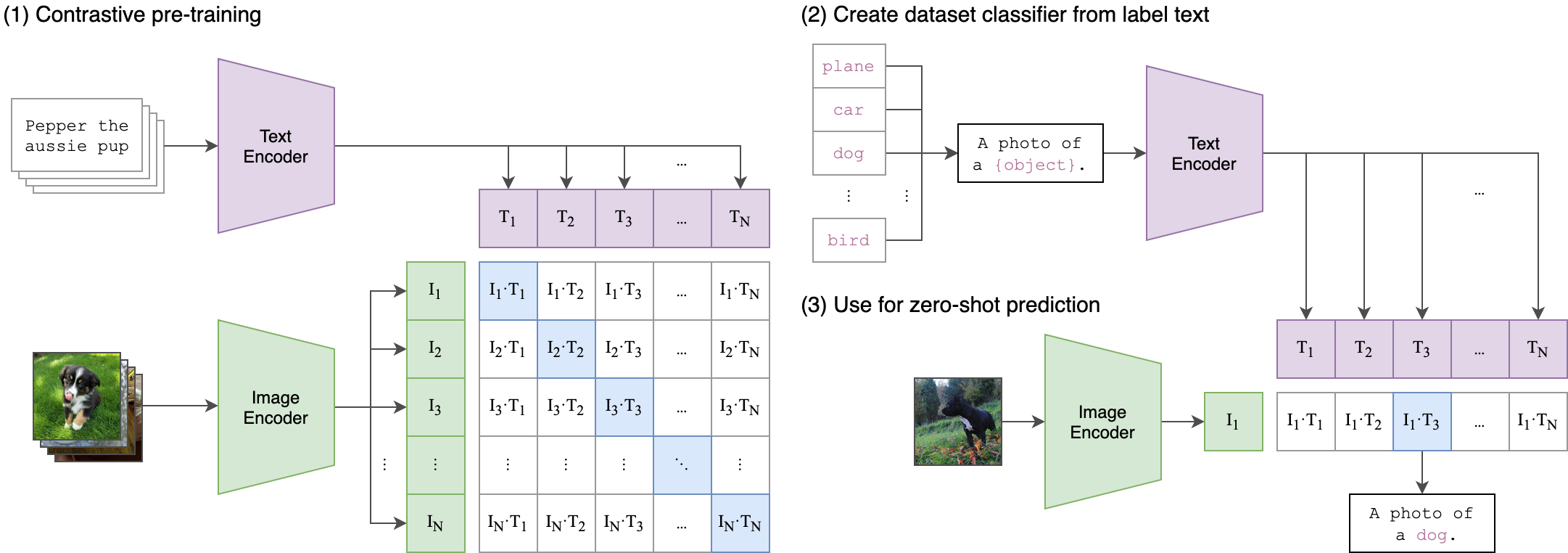
在此存儲庫中對夾子的視覺變壓器(VIT)圖像編碼器進行了罰款。以下Python腳本演示瞭如何調整Vit:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

