StableDiffusion2 Image to Text
1.0.0
Repositori ini berisi kode Python untuk menyempurnakan model yang dapat memprediksi petunjuk dan/atau embedding dari gambar yang dihasilkan. Proses yang umum diketahui adalah menghasilkan gambar dari teks yang diberikan adalah proses yang populer untuk insinyur prompt judul pekerjaan tren yang cepat; Namun, repo ini. difokuskan pada proses terbalik yang memprediksi prompt teks yang diberikan untuk menghasilkan gambar. Diberikan satu set data sebagai pasangan citra cepat. Model-model berikut disesuaikan untuk memprediksi teks atau teks embeddings:
Di bawah ini adalah beberapa contoh pasangan citra cepat untuk SD2. Tujuan dari pekerjaan ini adalah untuk memprediksi teks cepat yang digunakan untuk menghasilkan gambar. Diberikan dataset, seperti yang di bawah ini, kode dalam repo ini. dapat digunakan untuk menyempurnakan berbagai model untuk memprediksi prompt teks saat diberikan gambar yang dihasilkan.
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


Pekerjaan dalam repositori ini adalah bagian dari difusi stabil Kaggle - gambar untuk mendorong persaingan. Ini adalah kode yang saya buat selama kompetisi dan mampu mendapatkan finis 5% teratas dalam kompetisi.
Melatih model -model ini dan menghasilkan gambar dengan difusi stabil 2 adalah sumber daya yang intensif dan mengamanatkan GPU. Langkah -langkah dapat diambil untuk membantu mempercepat pembuatan gambar seperti:
Dengan menggunakan langkah -langkah ini, dengan RTX 3090, gambar dihasilkan sekitar 2s/gambar.
Kumpulan data pasangan prompt-image diunduh melalui URL menggunakan paket IMG2DataSet. Beberapa contoh dataset URL online adalah:
Kumpulan data pasangan prompt-image kustom dibuat menggunakan versi difusi stabil 2. Saya sarankan pengguna yang tertarik untuk membuat kumpulan data mereka sendiri dengan difusi stabil 2 mengikuti instruksi yang umum diperbarui pada versi difusi stabil 2.
Pasangan prompt-image perlu diformat sesuai untuk model yang akan disempurnakan. Lihat ./notebooks/data-format-train-val.ipynb yang menunjukkan cara memformat berbagai dataset.
Banyak dataset pasangan prompt-image online berisi petunjuk yang sangat mirip dan ini dapat menyebabkan model mempelajari permintaan yang umum terjadi dan tidak berkinerja baik pada petunjuk teks yang beragam. Oleh karena itu, petunjuk serupa mereka dihapus menggunakan pengindeksan kesamaan kosinus yang diaktifkan GPU atau pencarian kesamaan. Lihat ./utils/filt_embeds.py yang berisi kode untuk dengan cepat mengindeks dan memfilter embeddings teks.
Proses ini dilakukan pada GPU yang memanfaatkan Perpustakaan Faiss. FAISS adalah perpustakaan untuk pencarian kesamaan yang efisien dan pengelompokan vektor padat. Ini berisi algoritma yang mencari di set vektor dengan ukuran apa pun, hingga yang mungkin tidak muat di RAM.
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) Coca Architecture adalah pendekatan novel encoder-decoder yang secara bersamaan menghasilkan gambar unimodal dan embeddings teks dan representasi multimodal bersama, membuatnya cukup fleksibel untuk langsung berlaku untuk semua jenis tugas hilir. Secara khusus, Coca mencapai hasil canggih pada serangkaian tugas penglihatan dan bahasa penglihatan yang mencakup pengakuan penglihatan, penyelarasan lintas-modal, dan pemahaman multimodal. Selain itu, ia belajar representasi yang sangat umum sehingga dapat berkinerja baik atau lebih baik daripada model yang sepenuhnya disempurnakan dengan pembelajaran nol-shot atau encoder beku. Fine-tuning dilakukan mengikuti rekomendasi dari sini. Arsitektur Coca ditunjukkan di bawah ini dan diambil dari sumber. 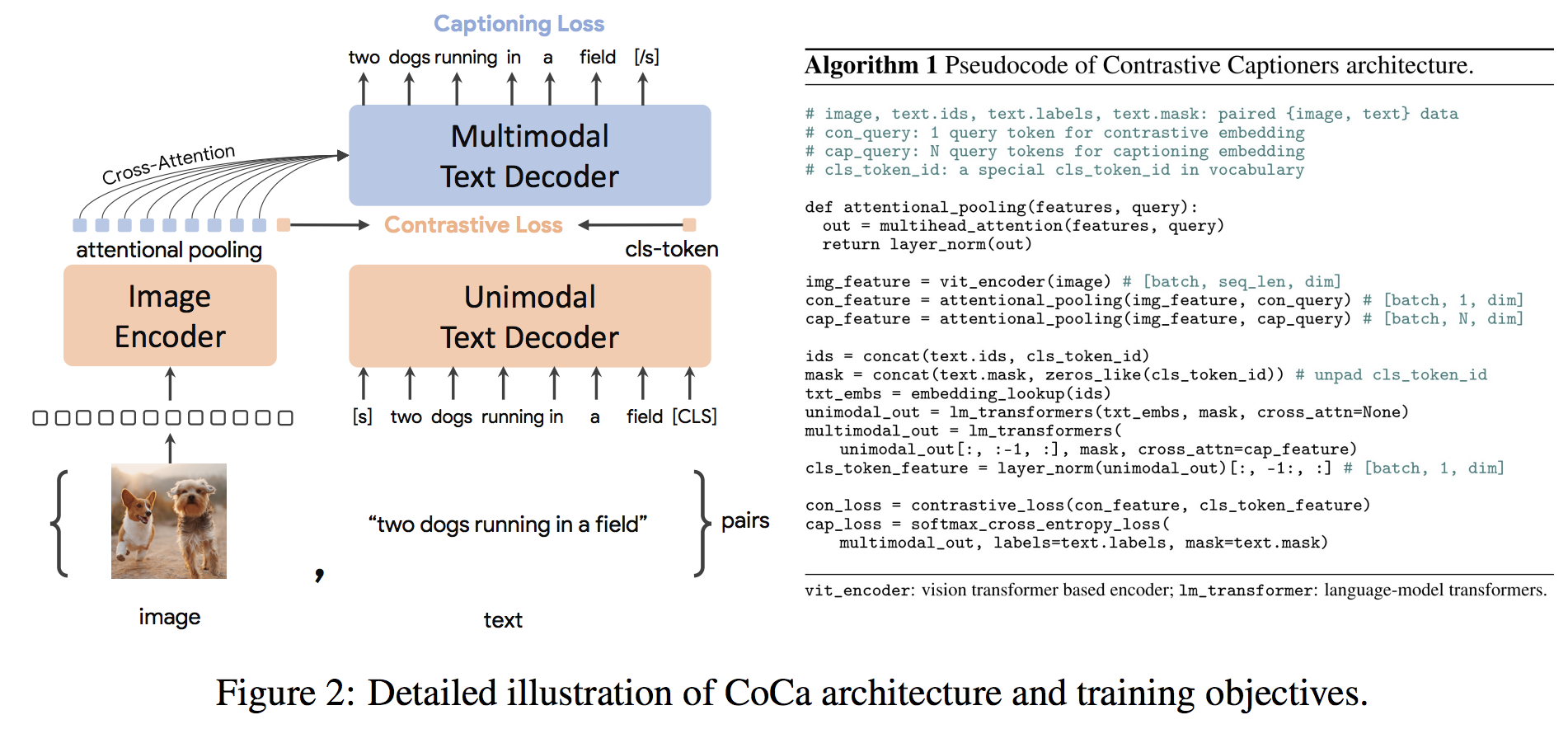
Kode Python untuk menyempurnakan koka ada di ./scripts/train_COCA.py dan perintah bash diberikan di bawah ini:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 Klip (pra-citra-citra kontras pra-pelatihan) adalah jaringan saraf yang dilatih pada berbagai pasangan (gambar, teks). Ini dapat diinstruksikan dalam bahasa alami untuk memprediksi cuplikan teks yang paling relevan, diberi gambar, tanpa secara langsung mengoptimalkan tugas, mirip dengan kemampuan zero-shot GPT-2 dan 3. Arsitektur klip ditunjukkan pada gambar di bawah dan diambil dari sumber. 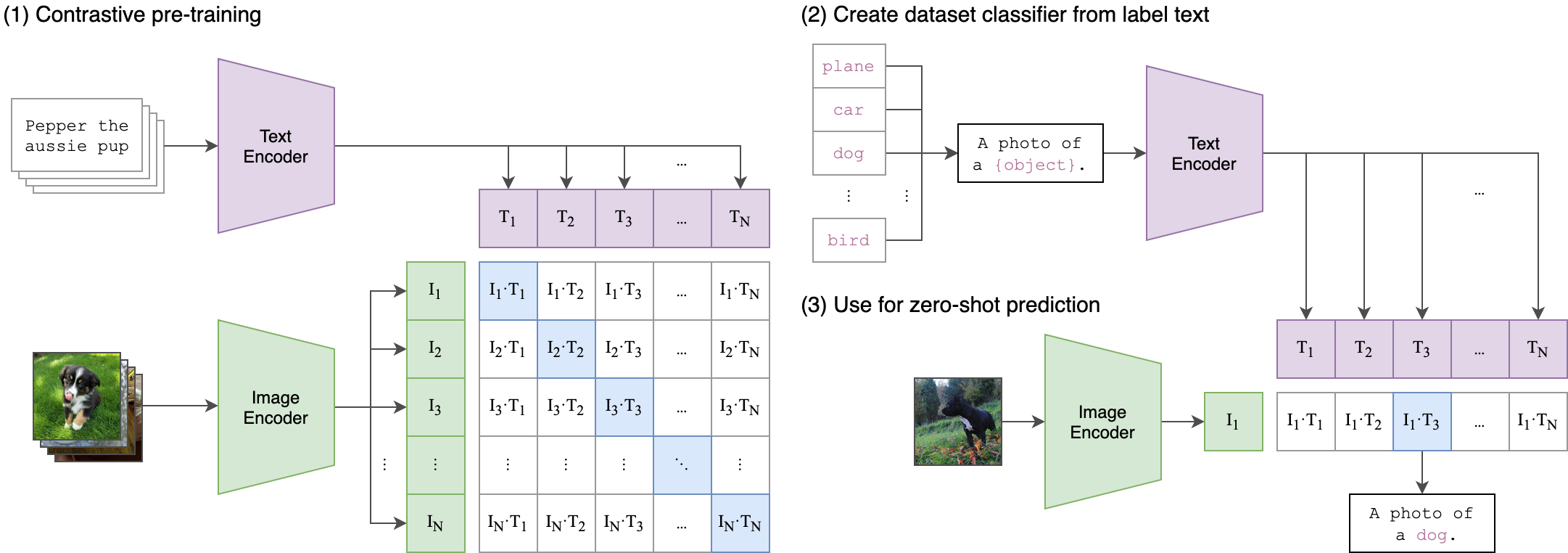
Encoder gambar Transformer Vision (VIT) dari klip didenda disetel di repositori ini. Skrip python berikut menunjukkan cara menyetel vit:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

