StableDiffusion2 Image to Text
1.0.0
Этот репозиторий содержит код Python для моделей с тонкой настройкой, которые могут предсказать подсказки и/или встраивание из сгенерированных изображений. Обычно известный процесс - это генерирование изображений из данного текста, является популярным процессом для инженера по подсказке задания в тренде; Однако это репо. сосредоточен на обратном процессе, который прогнозирует текстовую подсказку, предоставленную для создания изображения. Учитывая набор данных в виде пары приглашенного изображения. Следующие модели точно настроены, чтобы предсказать текстовое или текстовое вставки:
Ниже приведены несколько примеров пары приглашения для SD2. Целью этой работы является предсказание текста приглашения, используемого для генерации изображений. Учитывая набор данных, как ниже, код в этом репо. Может использоваться для тонкой настройки различных моделей для прогнозирования текстовой подсказки при предоставлении сгенерированного изображения.
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


Работа в этом репозитории была частью стабильной диффузии Kaggle - изображение для побуждения конкуренции. Это был код, который я создал во время конкурса, и смог заработать 5% финиша в конкурсе.
Обучение этих моделей и генерация изображений со стабильной диффузией 2 является ресурсным интенсивным и требует графического процессора. Меры могут быть приняты, чтобы помочь ускорить генерацию изображений, такие как:
Используя эти шаги, с RTX 3090 изображение было сгенерировано примерно при 2S/изображение.
Наборы данных Prompt-Image были загружены с помощью URL-адреса с использованием пакета img2dataset. Несколько примеров онлайн -наборов данных URL:
Пользовательские наборы данных Prompt-Image были созданы с использованием стабильной диффузионной версии 2. Я рекомендую пользователям, заинтересованным в создании собственных наборов данных со стабильной диффузией 2, следуйте обще обновленным инструкциям в стабильной диффузионной версии 2.
Парки с приглашенным образом должны быть отформатированы соответствующим образом для модели, которые они будут настраивать. См ./notebooks/data-format-train-val.ipynb
Многие из наборов данных паров в онлайн-обработке содержат подсказки, которые очень похожи, и это может привести к тому, что модель обычно изучает подсказки, а не хорошо выполнять различные текстовые подсказки. Следовательно, аналогичные подсказки их удаляли с помощью GPU с поддержкой индексации сходства косинуса или поиска сходства. См ./utils/filt_embeds.py
Этот процесс был проведен на графическом процессоре, который использовал библиотеку FAISS. Faiss - это библиотека для эффективного поиска сходства и кластеризации плотных векторов. Он содержит алгоритмы, которые ищут в наборах векторов любого размера, вплоть до тех, которые, возможно, не вписываются в ОЗУ.
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) Архитектура Coca-это новый подход кодера-декодера, который одновременно производит выровненные унимодальные изображения и текстовые вставки и совместные мультимодальные представления, что делает ее достаточно гибким, чтобы быть непосредственно применимым для всех типов нижестоящих задач. В частности, Coca достигает самых современных результатов по серии задач зрения и языка зрения, охватывающих распознавание зрения, межмодальное выравнивание и мультимодальное понимание. Кроме того, он изучает очень общие представления, так что он может работать так же хорошо или лучше, чем полностью настраиваемые модели с нулевым обучением или замороженными кодерами. Точная настройка была проведена по рекомендациям отсюда. Архитектура коки показана ниже и была взята из источника. 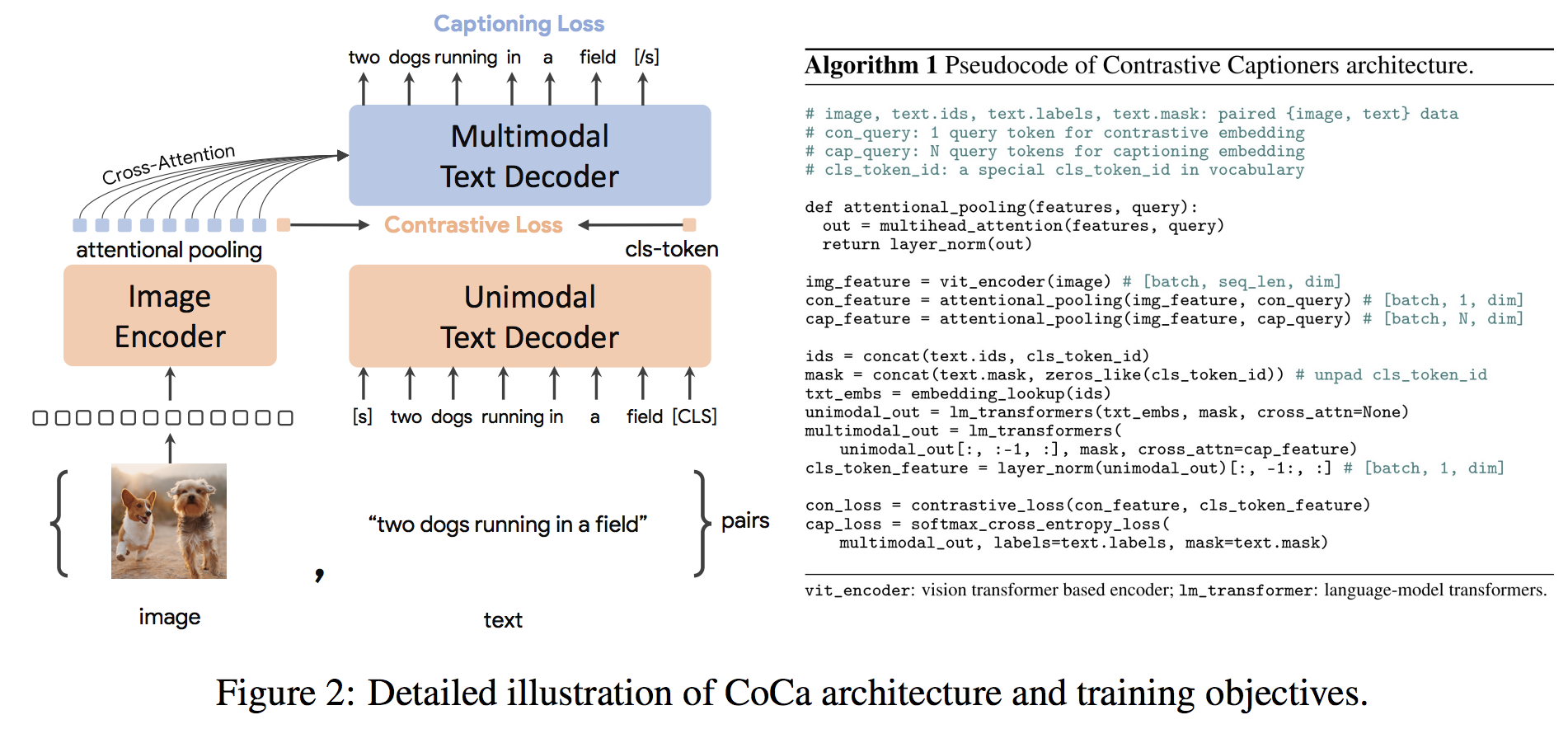
Код Python для точной настройки Coca находится в ./scripts/train_COCA.py , и приведена команда Bash ниже:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 Клип (контрастное воспроизведение языкового изображения) представляет собой нейронную сеть, обучаемую различным парам (изображение, текст). На естественном языке его можно проинструктировать, чтобы предсказать наиболее релевантный фрагмент текста, с учетом изображения, без непосредственной оптимизации для этой задачи, аналогично возможностям нулевого выстрела GPT-2 и 3. Архитектура клипа показана на изображении ниже и была взята из источника. 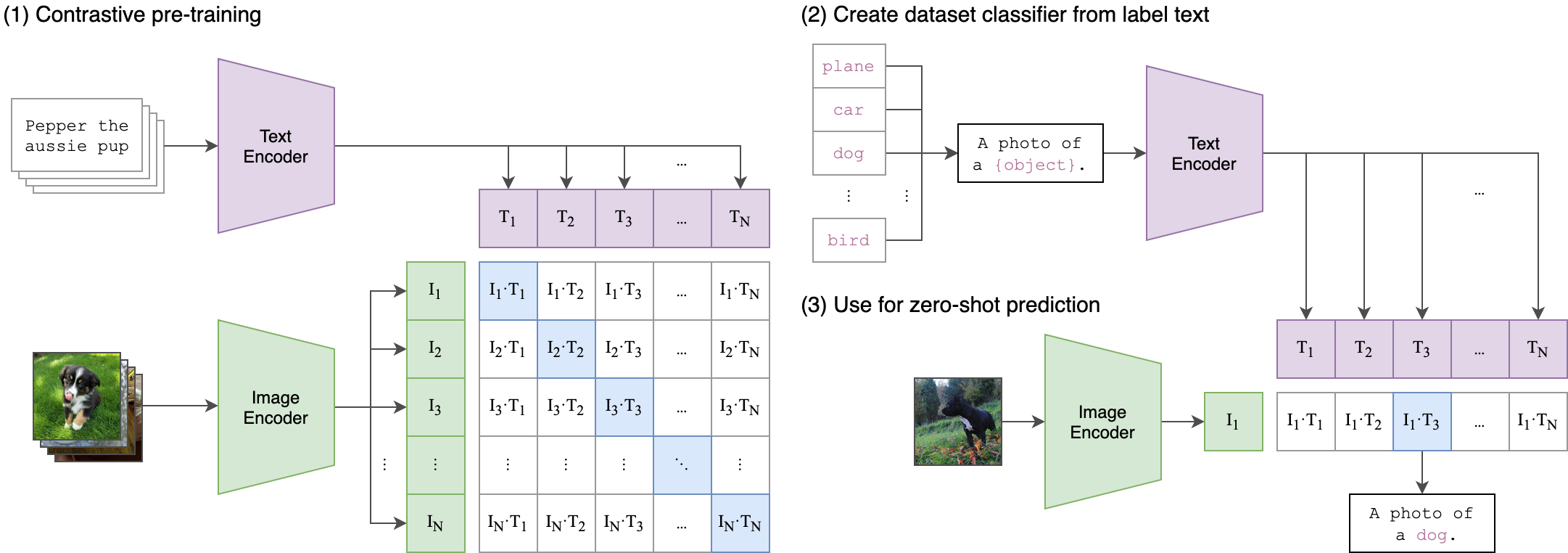
Энкодер изображения Vision Transformer (Vit) из клипа был оштрафован в этом хранилище. Следующие сценарии Python демонстрируют, как настроить Vit:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

