StableDiffusion2 Image to Text
1.0.0
Este repositorio contiene el código de Python para ajustar los modelos que pueden predecir las indicaciones y/o incrustaciones de las imágenes generadas. El proceso de conocimiento común es generar imágenes de un texto dado que es un proceso popular para el ingeniero indicador de título de trabajo de tendencia currenlty; Sin embargo, este repositorio. se centra en el proceso inverso que predice el indicador de texto dado para generar una imagen. Dado un conjunto de datos como pares de imagen de inmediato, los siguientes modelos están ajustados para predecir el texto o los incrustaciones de texto:
A continuación se presentan algunos pares de imagen de inmediato para SD2. El objetivo de este trabajo es predecir el texto rápido utilizado para generar las imágenes. Dado un conjunto de datos, como el siguiente, el código dentro de este repositorio. Se puede usar para ajustar varios modelos para predecir el mensaje de texto cuando se le da la imagen generada.
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


El trabajo en este repositorio fue parte de la imagen de difusión estable de Kaggle, imagen para impulsar la competencia. Este fue el código que creé durante la competencia y pude obtener un top 5% en la competencia.
Entrenar estos modelos y generar imágenes con difusión estable 2 es intensiva en recursos y exige una GPU. Se pueden tomar medidas para ayudar a acelerar la generación de imágenes como:
Usando estos pasos, con un RTX 3090, la imagen se generó a aproximadamente 2s/imagen.
Los conjuntos de datos de pares de imagen de inmediato se descargaron a través de URL utilizando el paquete IMG2Dataset. Algunos ejemplos de conjuntos de datos de URL en línea son:
Se crearon conjuntos de datos de pares de imágenes de aviso personalizados utilizando la versión de difusión estable 2. Recomiendo a los usuarios interesados en crear sus propios conjuntos de datos con difusión estable 2 Siga las instrucciones comúnmente actualizadas en la versión de difusión estable 2.
Los pares de imagen rápida debían formatearse en consecuencia para el modelo que ajustarán. Consulte ./notebooks/data-format-train-val.ipynb que muestra cómo formatear varios conjuntos de datos.
Muchos de los conjuntos de datos de pares de imágenes de inmediato en línea contienen indicaciones que son muy similares y esto puede hacer que el modelo aprenda las indicaciones que ocurren y no funcionen tan bien en diversas indicaciones de texto. Por lo tanto, las indicaciones similares se eliminaron utilizando una GPU habilitada para la indexación de similitud o la búsqueda de similitud. Consulte ./utils/filt_embeds.py que contiene el código para indexar y filtrar rápidamente las incrustaciones de texto.
Este proceso se realizó en una GPU que aprovechó la biblioteca FAISS. FAISS es una biblioteca para una búsqueda de similitud eficiente y agrupación de vectores densos. Contiene algoritmos que buscan en conjuntos de vectores de cualquier tamaño, hasta los que posiblemente no encajen en la RAM.
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) La arquitectura CocaS es un nuevo enfoque de codificador codificador que produce simultáneamente una imagen unimodal y incrustaciones de texto y representaciones multimodales conjuntas, lo que lo hace lo suficientemente flexible como para ser directamente aplicable para todo tipo de tareas posteriores. Específicamente, Coca logra resultados de última generación en una serie de tareas en el idioma de visión y visión que abarcan el reconocimiento de la visión, la alineación intermodal y la comprensión multimodal. Además, aprende representaciones altamente genéricas para que pueda funcionar tan bien o mejor que los modelos completamente ajustados con aprendizaje de disparo cero o codificadores congelados. El ajuste fino se realizó siguiendo las recomendaciones de aquí. La arquitectura de coca se muestra a continuación y se tomó de la fuente. 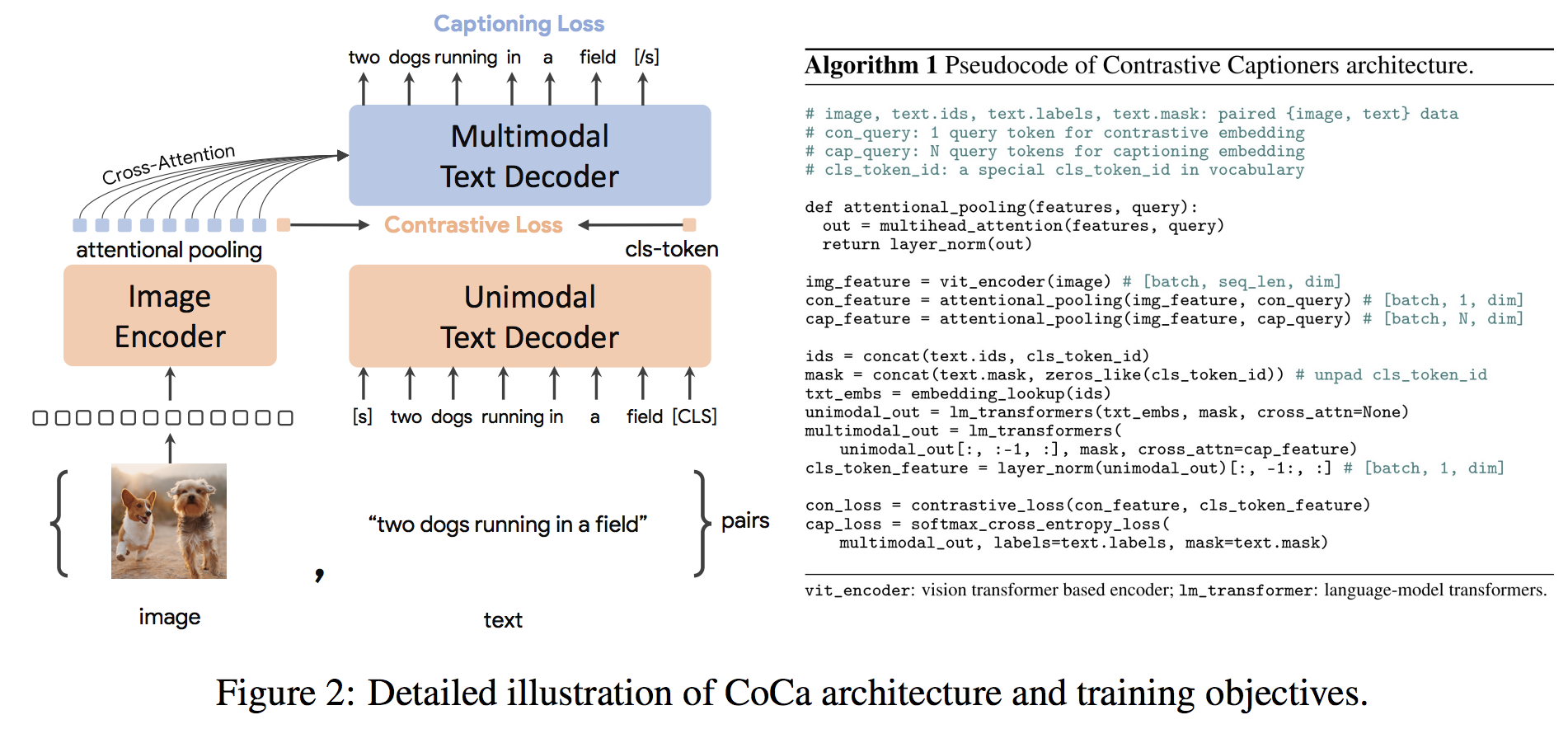
El código de Python a Fine-Tune Coca está en ./scripts/train_COCA.py y se proporciona un comando bash a continuación:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 El clip (pre-entrenamiento de imagen del lenguaje contrastante) es una red neuronal entrenada en una variedad de pares (de imagen, texto). Se puede instruir en el lenguaje natural para predecir el fragmento de texto más relevante, dada una imagen, sin optimizar directamente la tarea, de manera similar a las capacidades de disparo cero de GPT-2 y 3. La arquitectura del clip se muestra en la imagen a continuación y se tomó de la fuente. 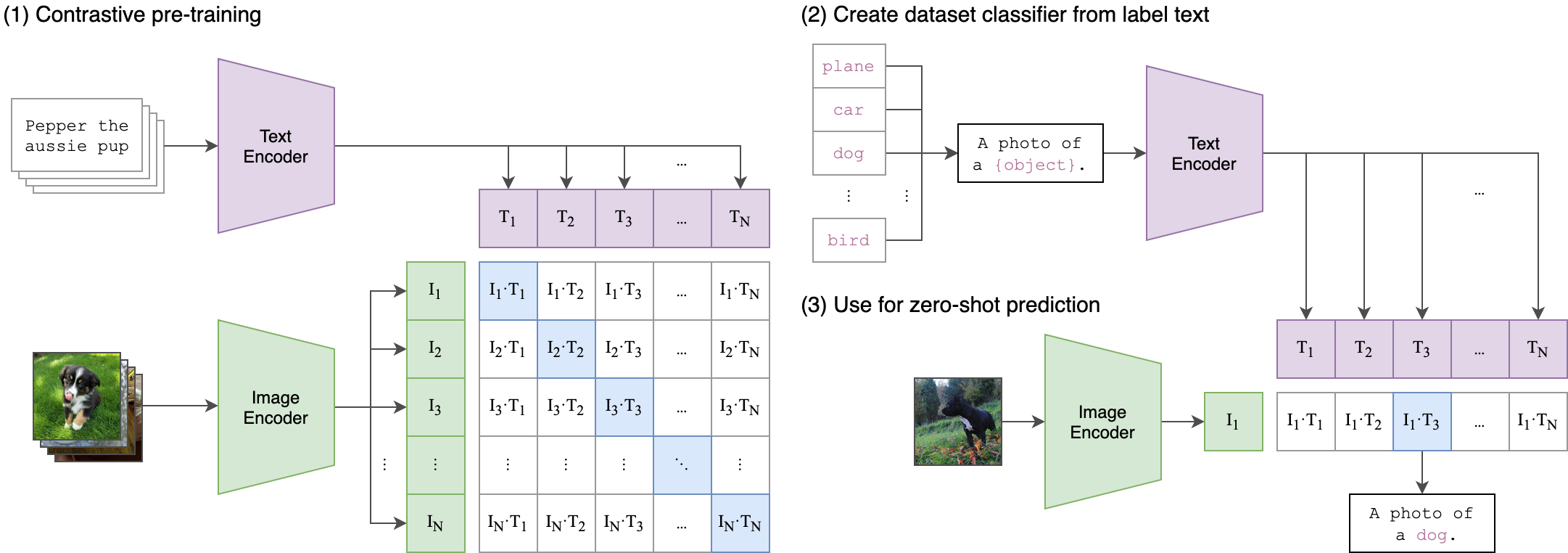
El codificador de imagen del transformador de visión (VIT) del clip fue multado en este repositorio. Los siguientes guiones de Python demuestran cómo sintonizar Vit:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

