StableDiffusion2 Image to Text
1.0.0
Ce référentiel contient du code Python pour affiner les modèles qui peuvent prédire les invites et / ou les incorporations à partir d'images générées. Le processus communément connu est de générer des images à partir d'un texte donné est un processus populaire pour l'ingénieur invite de title de travail à tendance Currenlty; Cependant, ce repo. est axé sur le processus inverse qui prédit l'invite de texte donnée pour générer une image. Étant donné un ensemble de données comme paires d'image rapide, les modèles suivants sont affinés pour prédire le texte ou le texte incorporces:
Vous trouverez ci-dessous quelques exemples de paires d'image invite pour SD2. L'objectif de ce travail est de prédire le texte rapide utilisé pour générer les images. Compte tenu d'un ensemble de données, comme ci-dessous, le code de ce dépôt. Peut être utilisé pour affiner divers modèles pour prédire l'invite de texte lorsqu'il est donné l'image générée.
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


Le travail dans ce référentiel faisait partie de la diffusion stable de Kaggle - Image pour inviter la concurrence. C'était le code que j'ai créé pendant la compétition et j'ai pu obtenir un top 5% dans la compétition.
La formation de ces modèles et la génération d'images avec une diffusion stable 2 est à forte intensité de ressources et oblige un GPU. Des mesures peuvent être prises pour aider à accélérer la génération d'images telle que:
En utilisant ces étapes, avec un RTX 3090, l'image a été générée à environ 2 s / image.
Les ensembles de données de paires d'image d'invite ont été téléchargés via URL à l'aide du package IMG2DATASET. Quelques exemples d'ensembles de données URL en ligne sont:
Les ensembles de données de paires d'image d'invite personnalisés ont été créés à l'aide de la diffusion stable version 2. Je recommande aux utilisateurs intéressés à créer leurs propres ensembles de données avec une diffusion stable 2 suivent les instructions couramment mises à jour à la diffusion stable version 2.
Les paires d'images rapides devaient être formatées en conséquence pour le modèle, ils seront affinés. Reportez-vous à ./notebooks/data-format-train-val.ipynb qui montre comment formater divers ensembles de données.
De nombreux ensembles de données de paires d'images invites en ligne contiennent des invites très similaires et cela peut entraîner l'apprentissage des invites courantes et ne pas fonctionner également sur diverses invites de texte. Par conséquent, des invites similaires ont été supprimées à l'aide d'un indexation de similitude de cosinus compatible GPU ou de recherche de similitude. Reportez-vous à ./utils/filt_embeds.py qui contient le code pour indexer et filtrer rapidement les intégres du texte.
Ce processus a été conduit sur un GPU qui a exploité la bibliothèque FAISS. FAISS est une bibliothèque pour une recherche et un regroupement de similitudes efficaces de vecteurs denses. Il contient des algorithmes qui recherchent dans des ensembles de vecteurs de n'importe quelle taille, jusqu'à ceux qui ne rentrent peut-être pas dans la RAM.
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) L'architecture COCA est une nouvelle approche de coder-codeur qui produit simultanément des incorporations d'images et de texte unimomodales alignées et des représentations multimodales conjointes, ce qui le rend suffisamment flexible pour être directement applicable à tous les types de tâches en aval. Plus précisément, Coca obtient des résultats de pointe sur une série de tâches de vision et de vision en matière de reconnaissance visuelle, d'alignement intermodal et de compréhension multimodale. De plus, il apprend des représentations très génériques afin qu'elle puisse fonctionner aussi bien ou mieux que des modèles entièrement affinés avec des encodeurs d'apprentissage ou de gels zéro. Le réglage fin a été mené à la suite des recommandations d'ici. L'architecture COCA est présentée ci-dessous et a été tirée de la source. 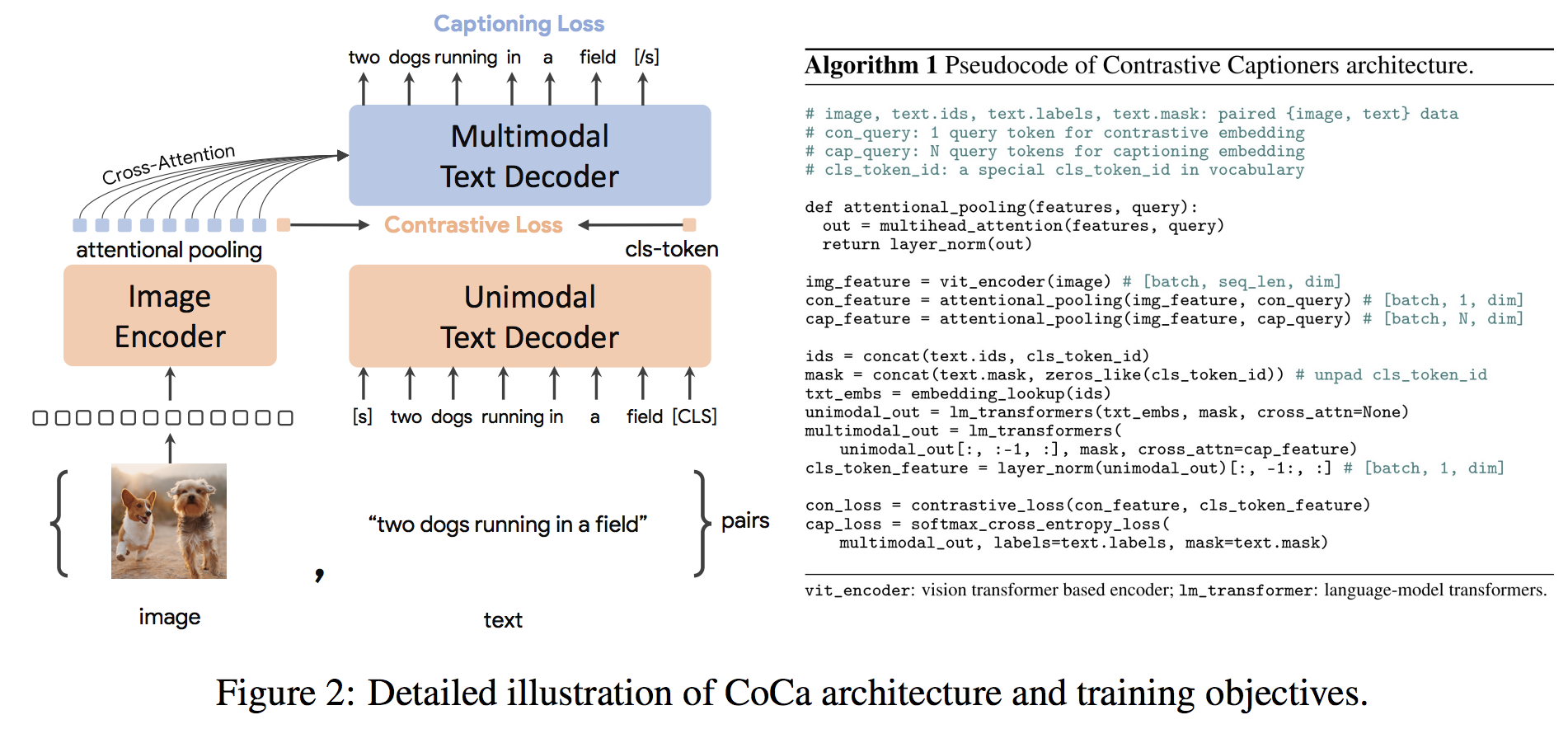
Le code python à fine-tune Coca est dans ./scripts/train_COCA.py et une commande bash est donnée ci-dessous:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 Le clip (pré-formation d'image linguistique contrasté) est un réseau neuronal formé sur une variété de paires (image, texte). Il peut être informé du langage naturel de prédire l'extrait de texte le plus pertinent, étant donné une image, sans optimiser directement pour la tâche, de la même manière que les capacités zéro-tir de GPT-2 et 3. L'architecture clip est indiquée dans l'image ci-dessous et a été tirée de la source. 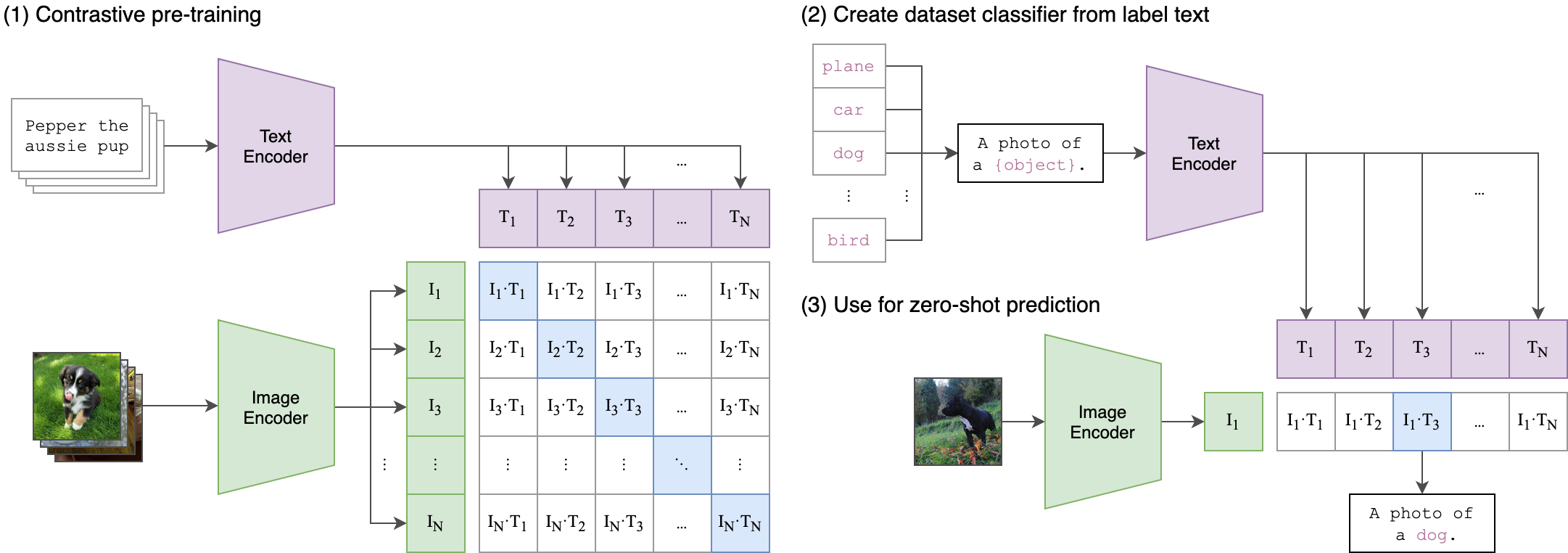
L'encodeur d'image du transformateur de vision (VIT) de CLIP a été amendé dans ce référentiel. Les scripts Python suivants montrent comment régler Vit:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

