StableDiffusion2 Image to Text
1.0.0
このリポジトリには、生成された画像からプロンプトや埋め込みを予測できるモデルを微調整するPythonコードが含まれています。一般的に知っているプロセスは、特定のテキストから画像を生成することです。ただし、このリポジトリ。画像を生成するために与えられたテキストプロンプトを予測している逆プロセスに焦点を当てています。プロンプトイメージのペアとしての一連のデータが与えられると、次のモデルは、テキストまたはテキストの埋め込みを予測するために微調整されています。
以下は、SD2のいくつかの例のプロンプトイメージペアです。この作業の目的は、画像を生成するために使用されるプロンプトテキストを予測することです。以下のように、データセットが与えられた場合、このレポのコード。生成された画像が与えられたときにテキストプロンプトを予測するために、さまざまなモデルを微調整するために使用できます。
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


このリポジトリの作業は、Kaggle Stable拡散の一部でした - 競争を促す画像。これは私が競技中に作成したコードであり、競技でトップ5%のフィニッシュを獲得することができました。
これらのモデルをトレーニングし、安定した拡散2を使用して画像を生成することはリソース集中であり、GPUを義務付けています。次のような画像生成を加速するのに役立つ対策を講じることができます。
これらの手順を使用して、RTX 3090を使用して、画像が約2秒/画像で生成されました。
IMG2Datasetパッケージを使用して、URLを介してプロンプトイメージペアデータセットをダウンロードしました。オンラインURLデータセットのいくつかの例は次のとおりです。
カスタムプロンプトイメージペアデータセットは、安定した拡散バージョン2を使用して作成されました。安定した拡散を使用した独自のデータセットを作成することに興味があるユーザーは、安定した拡散バージョン2の一般的に更新される命令に従ってください。
プロンプトイメージペアは、微調整されるモデルのためにそれに応じてフォーマットする必要がありました。 ./notebooks/data-format-train-val.ipynbを参照してください。
オンラインプロンプトイメージペアデータセットの多くには、非常に類似したプロンプトが含まれており、これによりモデルが一般的に発生するプロンプトを学習し、多様なテキストプロンプトではあまり実行されない可能性があります。したがって、同様のプロンプトは、GPU対応のコサイン類似性インデックスまたは類似性検索を使用して削除されました。 ./utils/filt_embeds.pyを参照してください。テキストの埋め込みを迅速にインデックスおよびフィルタリングするコードを含む。
このプロセスは、FAISSライブラリを活用したGPUで実施されました。 FAISSは、密なベクトルの効率的な類似性検索とクラスタリングのライブラリです。これには、RAMに収まらない可能性のあるサイズのベクトルのセットで検索するアルゴリズムが含まれています。
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ())コカアーキテクチャは、アラインドされたユニモーダル画像とテキストの埋め込みとジョイントマルチモーダル表現を同時に生成する新しいエンコーダーデコーダーアプローチであり、あらゆる種類のダウンストリームタスクに直接適用できるほど柔軟になります。具体的には、コカは、ビジョン認識、クロスモーダルアライメント、マルチモーダル理解にまたがる一連のビジョンとビジョン言語のタスクで最新の結果を達成します。さらに、ゼロショット学習またはフローズンエンコーダーを使用して、完全に微調整されたモデルよりも順番にパフォーマンスまたはそれ以上にパフォーマンスできるように、非常に一般的な表現を学習します。微調整は、ここからの推奨事項に従って実施されました。コカアーキテクチャは以下に示されており、ソースから取得されました。 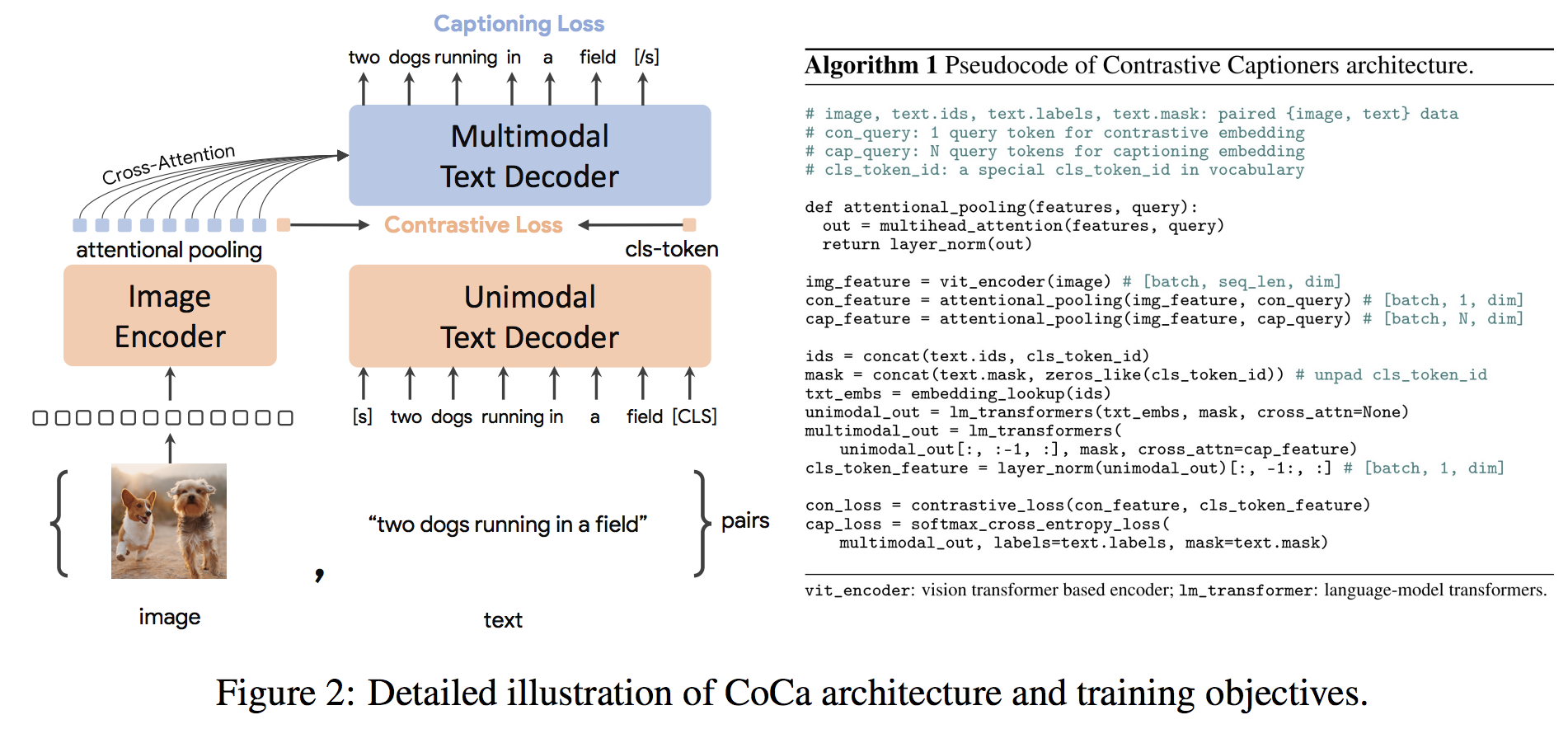
微調整コカのパイソンコードは./scripts/train_COCA.pyにあり、bashコマンドを以下に示します。
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 クリップ(コントラストのある言語イメージのプリトレーニング)は、さまざまな(画像、テキスト)ペアでトレーニングされたニューラルネットワークです。 GPT-2と3のゼロショット機能と同様に、タスクに直接最適化することなく、画像を考慮して、最も関連性の高いテキストスニペットを予測するように自然言語で指示することができます。クリップアーキテクチャは、以下の画像に表示され、ソースから取得されました。 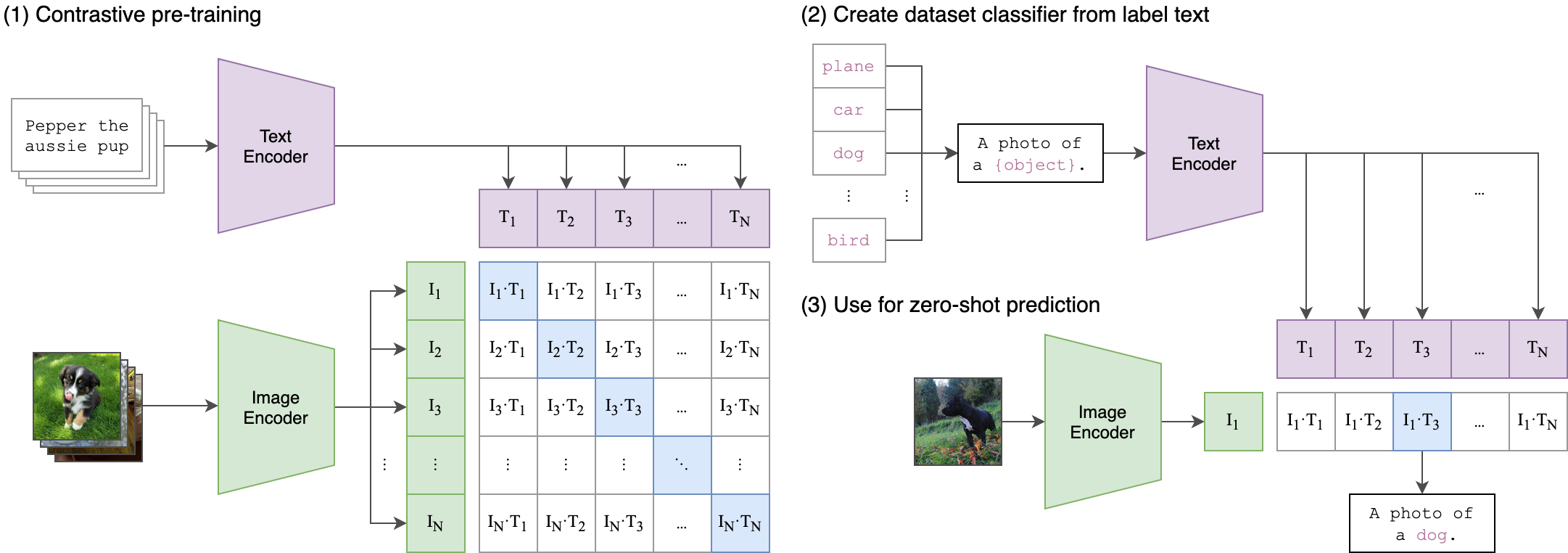
クリップからのVision Transformer(VIT)画像エンコーダーには、このリポジトリで罰金が科されました。次のPythonスクリプトは、VITを調整する方法を示しています。
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

