StableDiffusion2 Image to Text
1.0.0
Esse repositório contém código Python para ajustar modelos que podem prever instruções e/ou incorporações de imagens geradas. O processo comumente conhecido está gerando imagens de um determinado texto é um processo popular para o engenheiro prompt de título de cargo Currenlty Trending; No entanto, este repo. está focado no processo reverso que está prevendo o prompt de texto fornecido para gerar uma imagem. Dado um conjunto de dados como pares de imagem rápida, os seguintes modelos são ajustados para prever o texto ou o texto incorporando:
Abaixo estão alguns exemplos de pares de imagem rápida para SD2. O objetivo deste trabalho é prever o texto rápido usado para gerar as imagens. Dado um conjunto de dados, como o abaixo, o código dentro deste repo. Pode ser usado para ajustar vários modelos para prever o prompt de texto quando recebeu a imagem gerada.
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


O trabalho neste repositório fazia parte da imagem estável de Kaggle - imagem para solicitar a concorrência. Esse foi o código que eu criei durante a competição e consegui conquistar os 5% dos 5% na competição.
Treinar esses modelos e gerar imagens com difusão estável 2 é intensiva em recursos e exige uma GPU. Medidas podem ser tomadas para ajudar a acelerar a geração de imagens, como:
Usando essas etapas, com um RTX 3090, a imagem foi gerada em aproximadamente 2s/imagem.
Os conjuntos de dados de pares de impressão foram baixados via URL usando o pacote img2dataSet. Alguns exemplos de conjuntos de dados de URL online são:
Os conjuntos de dados de pares de impressão de prompt personalizados foram criados usando a versão estável da versão 2. Eu recomendo usuários interessados em criar seus próprios conjuntos de dados com difusão estável 2 siga as instruções comumente atualizadas na versão estável da versão 2.
Os pares de imposição de imagem precisavam ser formatados de acordo com o modelo que eles serão ajustados. Consulte ./notebooks/data-format-train-val.ipynb que mostra como formatar vários conjuntos de dados.
Muitos dos conjuntos de dados de pares de imagem de prompt on-line contêm instruções altamente semelhantes e isso pode fazer com que o modelo aprenda com os avisos de ocorrência comum e não funcionando tão bem em diversos avisos de texto. Portanto, instruções semelhantes foram removidas usando uma indexação de similaridade de cosseno ativada por GPU ou pesquisa de similaridade. Consulte ./utils/filt_embeds.py que contém o código para indexar e filtrar rapidamente incorporados textos.
Esse processo foi conduzido em uma GPU que alavancou a Biblioteca FAISS. O FAISS é uma biblioteca para pesquisa eficiente de similaridade e agrupamento de vetores densos. Ele contém algoritmos que pesquisam em conjuntos de vetores de qualquer tamanho, até aqueles que possivelmente não se encaixam na RAM.
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) A Arquitetura da Coca é uma nova abordagem do codificador decodificador que produz simultaneamente imagens unimodais alinhadas e incorporações de texto e representações multimodais articulares, tornando-a flexível o suficiente para ser diretamente aplicável a todos os tipos de tarefas a jusante. Especificamente, a Coca alcança resultados de ponta em uma série de tarefas de visão e linguagem da visão que abrangem reconhecimento de visão, alinhamento cruzado e entendimento multimodal. Além disso, aprende representações altamente genéricas para que possa ter um desempenho tão bom ou melhor do que os modelos totalmente ajustados com aprendizado com tiro zero ou codificadores congelados. O ajuste fino foi realizado seguindo as recomendações daqui. A arquitetura da Coca é mostrada abaixo e foi retirada da fonte. 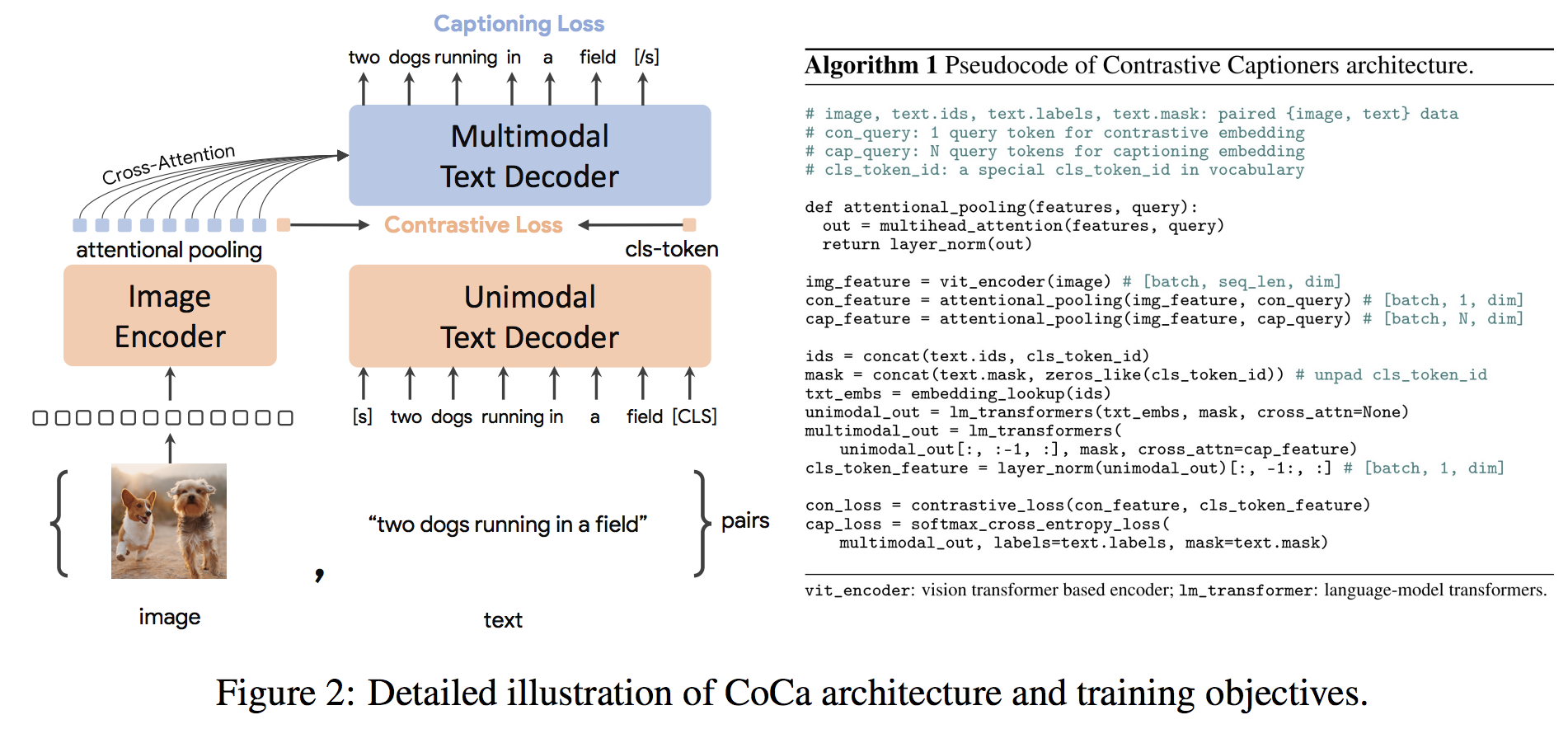
O código python para tune tune coca está em ./scripts/train_COCA.py e um comando bash é fornecido abaixo:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 O clipe (pré-treinamento em imagem contrastiva) é uma rede neural treinada em uma variedade de pares (imagem, texto). Pode ser instruído na linguagem natural a prever o trecho de texto mais relevante, dada uma imagem, sem otimizar diretamente a tarefa, da mesma forma que os recursos de tiro zero do GPT-2 e 3. A arquitetura do clipe é mostrada na imagem abaixo e foi retirada da fonte. 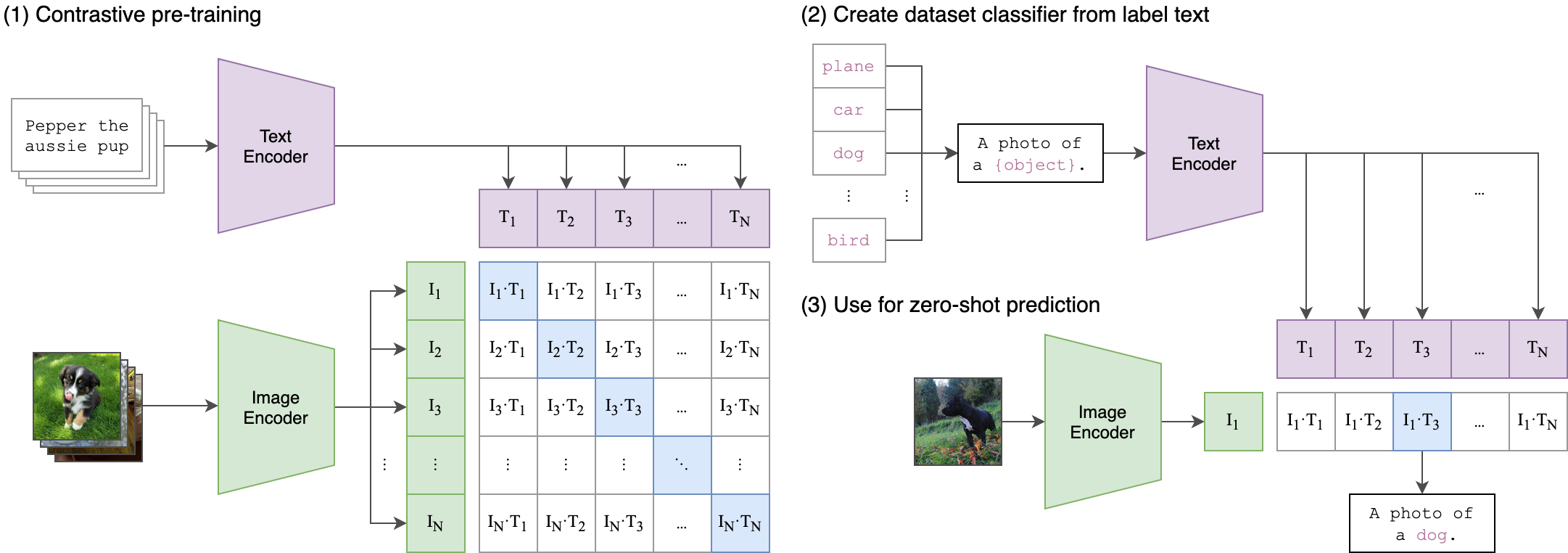
O codificador de imagem do transformador de visão (Vit) do clipe foi multado neste repositório. Os seguintes scripts Python demonstram como ajustar o VIT:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

