StableDiffusion2 Image to Text
1.0.0
该存储库包含用于微调模型的Python代码,这些模型可以预测生成图像中的提示和/或嵌入。通常知道的过程是从给定文本中生成图像是弯曲趋势的作业提示工程师的流行过程;但是,这个存储库。专注于反向过程,该过程预测了给出的文本提示以生成图像。给定一组数据作为及时图像对,以下模型进行了微调以预测文本或文本嵌入:
以下是SD2的一些示例提示图。这项工作的目的是预测用于生成图像的及时文本。给定一个数据集,如下所示,该存储库中的代码。可以用来微调各种模型,以预测给出生成的图像时的文本提示。
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


该存储库中的工作是Kaggle稳定扩散的一部分 - 提示竞争的图像。这是我在比赛中创建的代码,并能够在比赛中获得前5%的成绩。
训练这些模型并以稳定的扩散2生成图像是资源密集型的,并要求GPU。可以采取措施来帮助加速图像产生,例如:
使用这些步骤,具有RTX 3090,以大约2s/图像生成图像。
使用IMG2DATASET软件包通过URL下载了及时图像对数据集。在线URL数据集的一些示例是:
使用稳定的扩散版本2创建自定义提示图对数据集。我建议用户有兴趣使用稳定扩散2创建自己的数据集2的用户,请遵循稳定扩散版2的常用说明。
需要对其进行微调的模型进行相应格式化及时图像对。请参阅./notebooks/data-format-train-val.ipynb其中显示了如何格式化各种数据集。
许多在线及时图像对数据集都包含高度相似的提示,这可能会导致模型通常会出现提示,并且在各种文本提示上的表现不佳。因此,使用启用GPU的余弦相似性索引或相似性搜索将它们删除相似的提示。请参阅./utils/filt_embeds.py ,其中包含代码快速索引和过滤文本嵌入。
此过程是在利用Faiss图书馆的GPU上进行的。 Faiss是一个库,用于有效的相似性搜索和密集向量的聚类。它包含在任何大小的向量集中搜索的算法,最多可能不适合RAM。
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ())COCA体系结构是一种新颖的编码器方法,同时产生了对齐的单峰图像和文本嵌入和联合多模式表示形式,使其足够灵活,可以直接适用于所有类型的下游任务。具体而言,可口可乐在一系列视觉识别,跨模式对准和多模式理解的一系列视觉和视觉任务上取得了最新的结果。此外,它学习了高通用表示形式,因此它可以比具有零拍学习或冷冻编码器的完全微调模型表现出色或更好。根据此处的建议进行了微调。可口可乐体系结构如下所示,并取自来源。 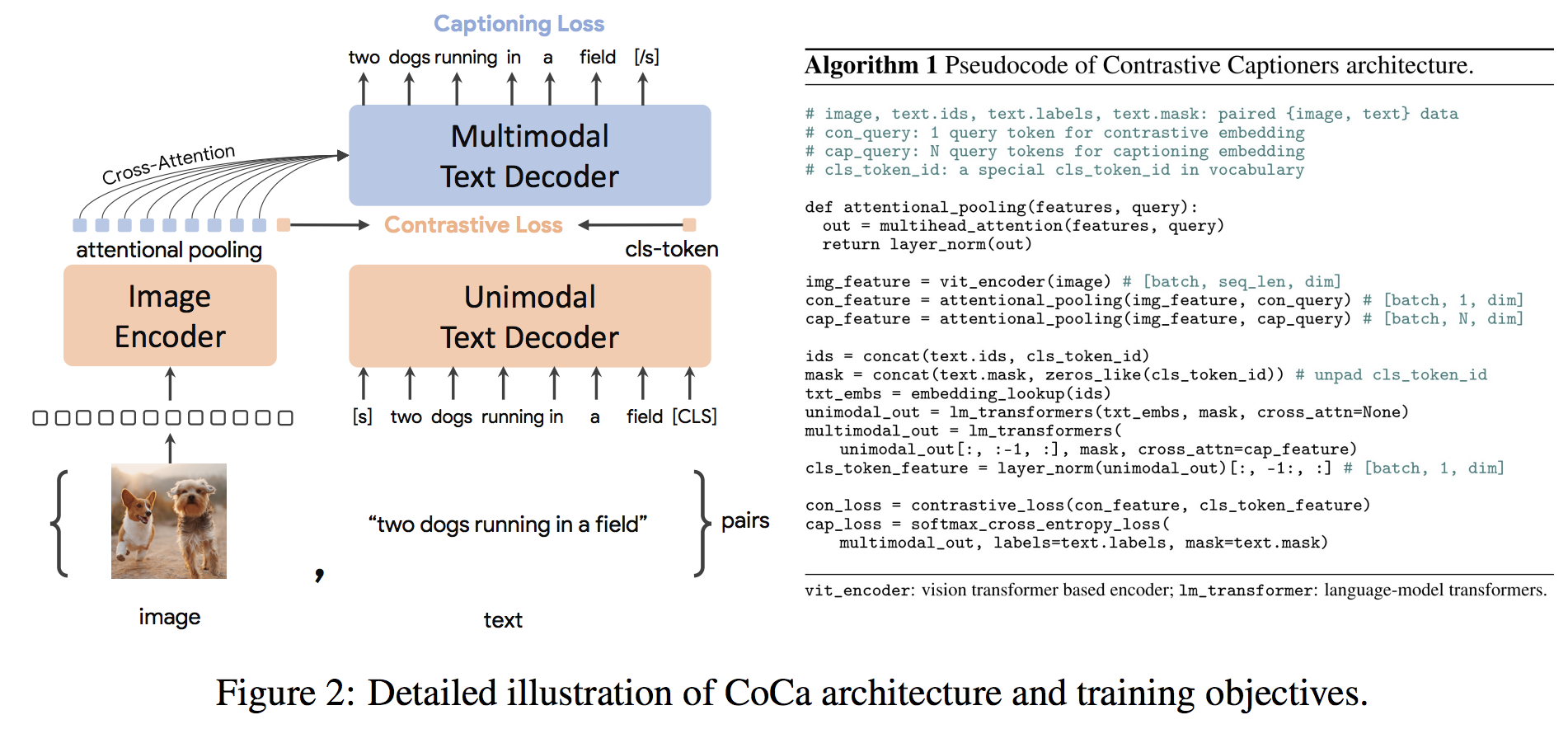
python代码到微调可可coca在./scripts/train_COCA.py中,下面给出了bash命令:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 剪辑(对比性语言图像预训练)是一个在各种(图像,文本)对的神经网络。可以用自然语言指示它,以预测给定图像的最相关的文本段,而无需直接对任务进行优化,类似于GPT-2和3的零拍功能。剪辑体系结构如下图所示,并从源中获取。 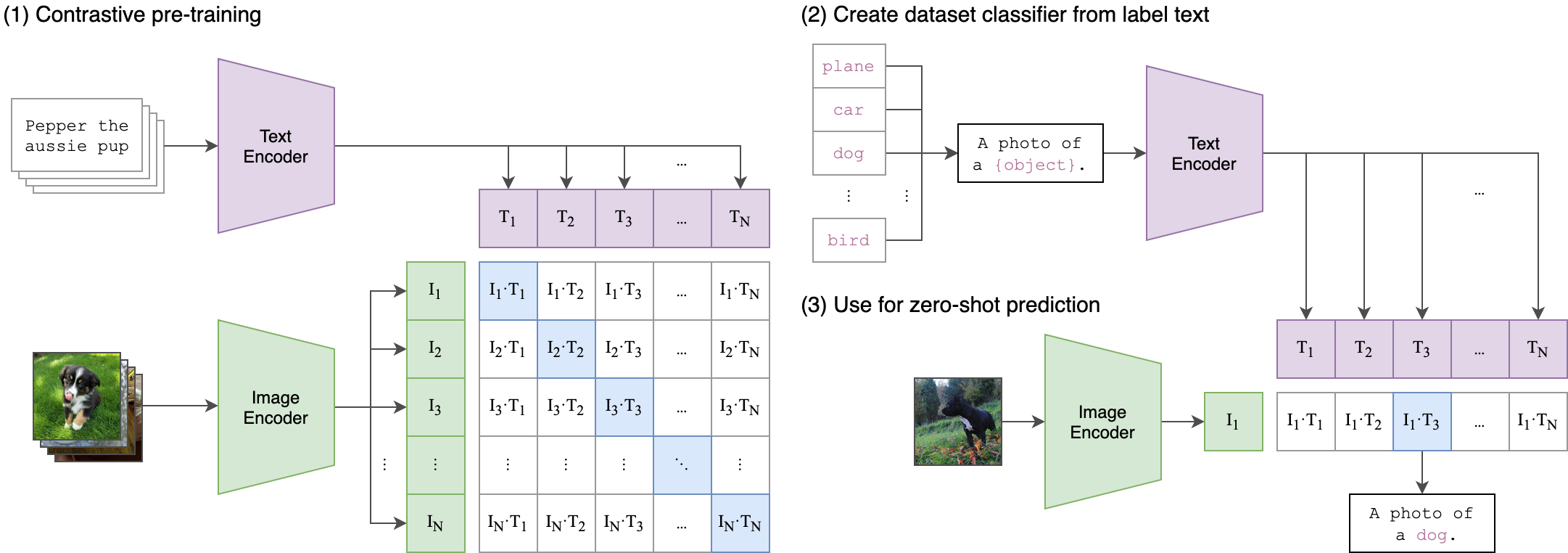
在此存储库中对夹子的视觉变压器(VIT)图像编码器进行了罚款。以下Python脚本演示了如何调整Vit:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

