StableDiffusion2 Image to Text
1.0.0
이 저장소에는 생성 된 이미지로부터 프롬프트 및/또는 임베딩을 예측할 수있는 모델을 미세 조정하기위한 파이썬 코드가 포함되어 있습니다. 일반적으로 알고있는 프로세스는 주어진 텍스트에서 이미지를 생성하는 것이 Currenlty Trending Job Prompt Engineer에게 인기있는 프로세스입니다. 그러나이 repo. 이미지를 생성하기 위해 주어진 텍스트 프롬프트를 예측하는 역 프로세스에 중점을 둡니다. 프롬프트 이미지 쌍으로서의 데이터 세트가 주어지면 다음 모델은 텍스트 또는 텍스트 임베딩을 예측하도록 미세 조정됩니다.
다음은 SD2의 프롬프트 이미지 쌍의 몇 가지 예입니다. 이 작업의 목적은 이미지를 생성하는 데 사용되는 프롬프트 텍스트를 예측하는 것입니다. 아래와 같은 데이터 세트가 주어지면이 repo 내의 코드가 있습니다. 생성 된 이미지가 주어지면 텍스트 프롬프트를 예측하기 위해 다양한 모델을 미세 조정하는 데 사용될 수 있습니다.
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


이 저장소의 작업은 Kaggle 안정적인 확산 - 경쟁을위한 이미지의 일부였습니다. 이것은 내가 경쟁 중에 만든 코드였으며 경쟁에서 5%의 마무리를 얻을 수있었습니다.
이러한 모델을 훈련시키고 안정적인 확산 2로 이미지를 생성하는 것은 리소스 집약적이며 GPU를 의무화합니다. 다음과 같은 이미지 생성을 가속화하는 데 도움이되는 조치를 취할 수 있습니다.
RTX 3090과 함께이 단계를 사용하여 이미지가 약 2S/이미지에서 생성되었습니다.
프롬프트 이미지 쌍 데이터 세트는 IMG2Dataset 패키지를 사용하여 URL을 통해 다운로드되었습니다. 온라인 URL 데이터 세트의 몇 가지 예는 다음과 같습니다.
사용자 정의 프롬프트-이미지 쌍 데이터 세트는 안정적인 확산 버전 2를 사용하여 작성되었습니다. 안정적인 확산으로 자체 데이터 세트를 작성하는 데 관심이있는 사용자를 권장합니다.
프롬프트 이미지 쌍은 미세 조정이 될 모델에 따라 포맷해야했습니다. 다양한 데이터 세트를 포맷하는 방법을 보여주는 ./notebooks/data-format-train-val.ipynb 를 참조하십시오.
많은 온라인 프롬프트 이미지 쌍 데이터 세트에는 매우 유사한 프롬프트가 포함되어 있으며 모델이 일반적으로 발생하는 프롬프트를 배우고 다양한 텍스트 프롬프트에서는 잘 수행되지 않을 수 있습니다. 따라서, GPU 활성화 코사인 유사성 인덱싱 또는 유사성 검색을 사용하여 제거 된 유사한 프롬프트. 빠르게 인덱싱하고 필터 텍스트 임베딩을위한 코드가 포함 된 ./utils/filt_embeds.py 를 참조하십시오.
이 프로세스는 FAISS 라이브러리를 활용 한 GPU에서 수행되었습니다. Faiss는 밀도가 높은 벡터의 효율적인 유사성 검색 및 클러스터링을위한 라이브러리입니다. 여기에는 모든 크기의 벡터 세트에서 RAM에 맞지 않는 벡터 세트에서 검색하는 알고리즘이 포함되어 있습니다.
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) Coca Architecture는 정렬 된 단일 모드 이미지 및 텍스트 임베딩 및 공동 멀티 모드 표현을 동시에 생성하는 새로운 인코더 디코더 접근 방식으로 모든 유형의 다운 스트림 작업에 직접 적용 할 수있을 정도로 유연하게 만듭니다. 구체적으로, Coca는 비전 인식, 교차 모달 정렬 및 멀티 모달 이해에 걸친 일련의 비전 및 비전 언어 작업에 대한 최첨단 결과를 달성합니다. 또한, 제로 샷 학습 또는 냉동 인코더를 사용하여 완전히 미세 조정 된 모델보다 잘 수행 할 수 있거나 더 잘 수행 할 수 있도록 매우 일반적인 표현을 학습합니다. 여기에서 권장 사항에 따라 미세 조정이 수행되었습니다. 코카 건축은 아래에 나와 소스에서 가져 왔습니다. 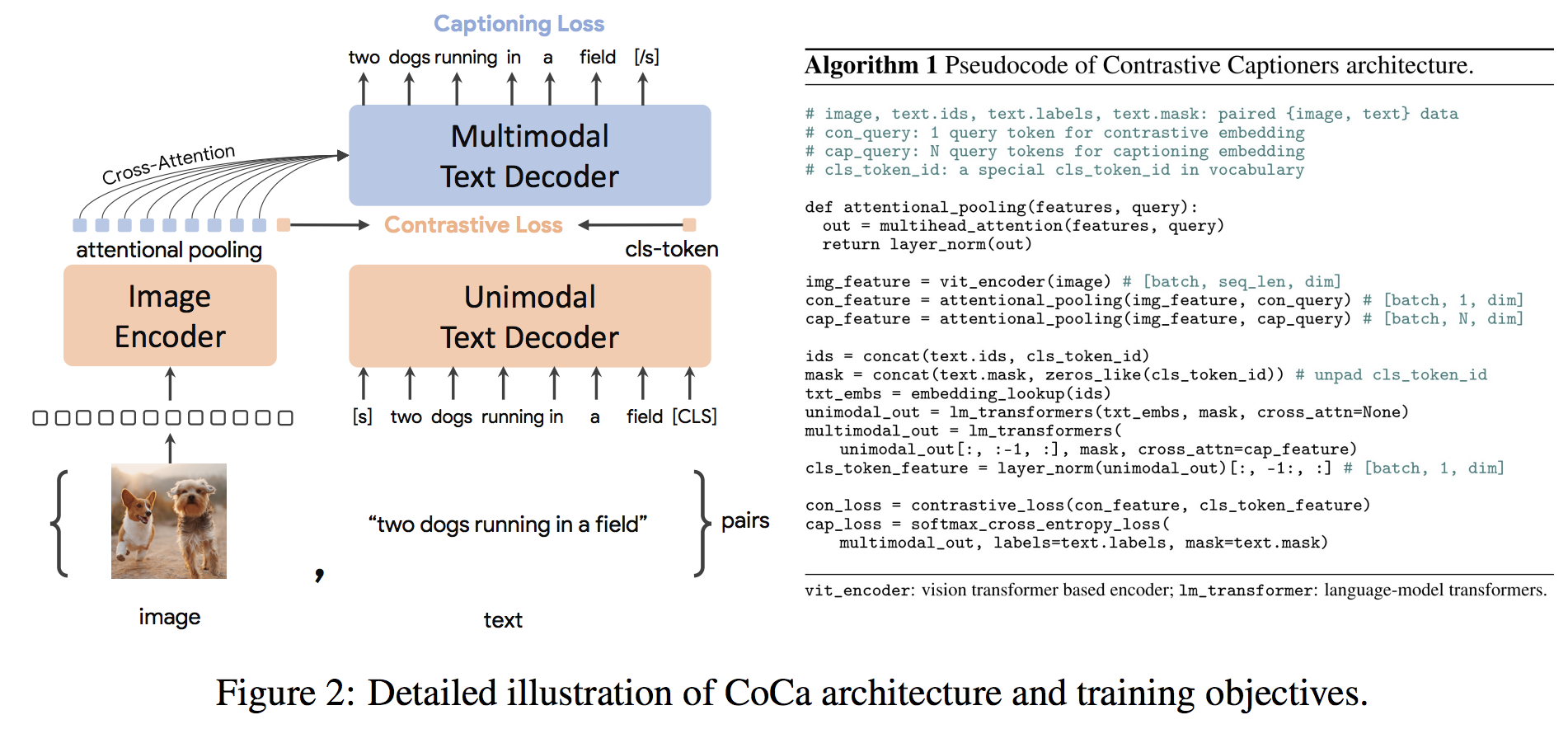
Coca를 미세 조정하는 Python 코드는 ./scripts/train_COCA.py 에 있으며 Bash 명령은 다음과 같습니다.
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 클립 (대비 언어 이미지 사전 훈련)은 다양한 (이미지, 텍스트) 쌍으로 훈련 된 신경망입니다. GPT-2 및 3의 제로 샷 기능과 마찬가지로 작업을 직접 최적화하지 않고 이미지가 주어진 이미지가 주어진 가장 관련성이 높은 텍스트 스 니펫을 예측하도록 자연 언어로 지시받을 수 있습니다. 클립 아키텍처는 아래 이미지에 표시되며 소스에서 가져 왔습니다. 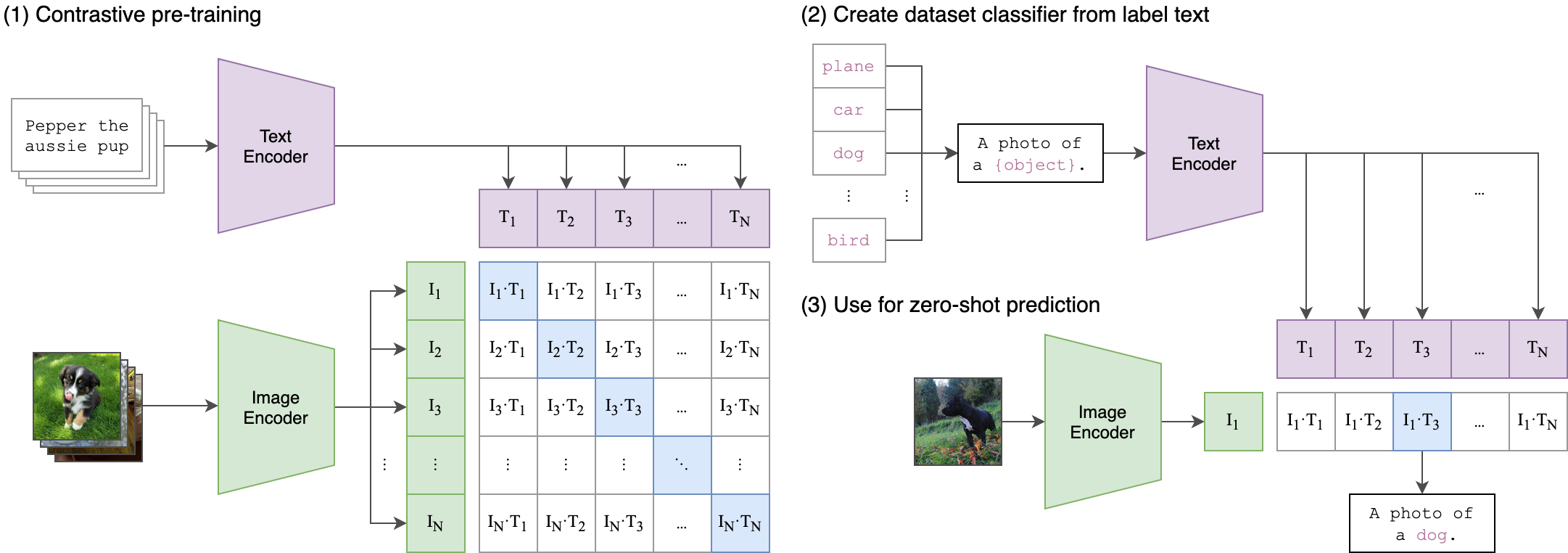
클립의 Vision Transformer (VIT) 이미지 엔코더는이 저장소에서 벌금을 조정했습니다. 다음 파이썬 스크립트는 VIT를 조정하는 방법을 보여줍니다.
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

