StableDiffusion2 Image to Text
1.0.0
يحتوي هذا المستودع على رمز Python لضبط النماذج التي يمكن أن تتنبأ بالمطالبات و/أو التضمينات من الصور التي تم إنشاؤها. إن عملية المعرفة الشائعة تقوم بإنشاء صور من نص معين هي عملية شائعة لمهندس موجه المسمى الوظيفي Trending Currenlty ؛ ومع ذلك ، هذا الريبو. يركز على العملية العكسية التي تتنبأ بمطالبة النص المعطاة لإنشاء صورة. بالنظر إلى مجموعة من البيانات كأزواج في الصورة السريعة ، يتم ضبط النماذج التالية بشكل جيد للتنبؤ بالنص أو التضمينات النصية:
فيما يلي بعض الأزواج على الصورة السريعة لـ SD2. الهدف من هذا العمل هو التنبؤ بالنص السريع المستخدم لإنشاء الصور. بالنظر إلى مجموعة بيانات ، مثل أدناه ، الرمز داخل هذا الريبو. يمكن استخدامها لضبط النماذج المختلفة للتنبؤ بمطالبة النص عند إعطاء الصورة التي تم إنشاؤها.
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


كان العمل في هذا المستودع جزءًا من انتشار Kaggle المستقر - الصورة إلى المطالبة بالمنافسة. كان هذا رمزًا قمت بإنشائه خلال المسابقة وتمكنت من الحصول على أعلى 5 ٪ في المنافسة.
تدريب هذه النماذج وتوليد الصور مع الانتشار المستقر 2 هو المكثف على الموارد ويفضل وحدة معالجة الرسومات. يمكن اتخاذ تدابير للمساعدة في تسريع توليد الصور مثل:
باستخدام هذه الخطوات ، مع RTX 3090 ، تم إنشاء الصورة في حوالي 2s/صورة.
تم تنزيل مجموعات بيانات زوج السلاح السريع عبر عنوان URL باستخدام حزمة IMG2DATASET. بعض الأمثلة على مجموعات بيانات عنوان URL عبر الإنترنت هي:
تم إنشاء مجموعات بيانات الزوج المخصصة للبيانات المخصصة باستخدام الإصدار 2 من الانتشار المستقر.
هناك حاجة إلى تنسيق أزواج الصور الفورية وفقًا لذلك للنموذج الذي سيتم ضبطه. ارجع إلى ./notebooks/data-format-train-val.ipynb الذي يوضح كيفية تنسيق مجموعات البيانات المختلفة.
تحتوي العديد من مجموعات بيانات زوجات الصور السريعة عبر الإنترنت على مطالبات متشابهة للغاية ، وقد يتسبب ذلك في تعلم النموذج عادةً ما يحدث بشكل شائع وعدم الأداء على مطالبات النص المتنوعة. لذلك ، تمت إزالة مطالبات مماثلة باستخدام فهرسة تشابه جيب التمام GPU أو البحث عن التشابه. ارجع إلى ./utils/filt_embeds.py الذي يحتوي على الكود لفهرسة وتصفية النصوص السريعة.
تم توجيه هذه العملية على وحدة معالجة الرسومات التي استفادت من مكتبة Faiss. FAISS هي مكتبة للبحث الفعال في التشابه وتجميع المتجهات الكثيفة. أنه يحتوي على خوارزميات تبحث في مجموعات من المتجهات من أي حجم ، حتى تلك التي ربما لا تتناسب مع ذاكرة الوصول العشوائي.
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) الهندسة المعمارية COCA هي نهج جديد للتشفير والتشفير الذي ينتج في وقت واحد في وقت واحد الصورة غير الواضحة والأصوات النصية والتمثيلات متعددة الوسائط المشتركة ، مما يجعلها مرنة بما يكفي لتكون قابلة للتطبيق مباشرة على جميع أنواع المهام المصب. على وجه التحديد ، تحقق COCA النتائج الحديثة على سلسلة من مهام الرؤية واللغة التي تمتد إلى التعرف على الرؤية ، والمحاذاة عبر الوسائط ، والتفاهم متعدد الوسائط. علاوة على ذلك ، فإنه يتعلم تمثيلات عامة للغاية بحيث يمكن أن تؤدي بشكل جيد أو أفضل من النماذج التي يتم ضبطها بالكامل مع التعلم الصفري أو المشفرات المجمدة. تم إجراء عملية النحافة بعد توصيات من هنا. يظهر بنية COCA أدناه وتم أخذها من المصدر. 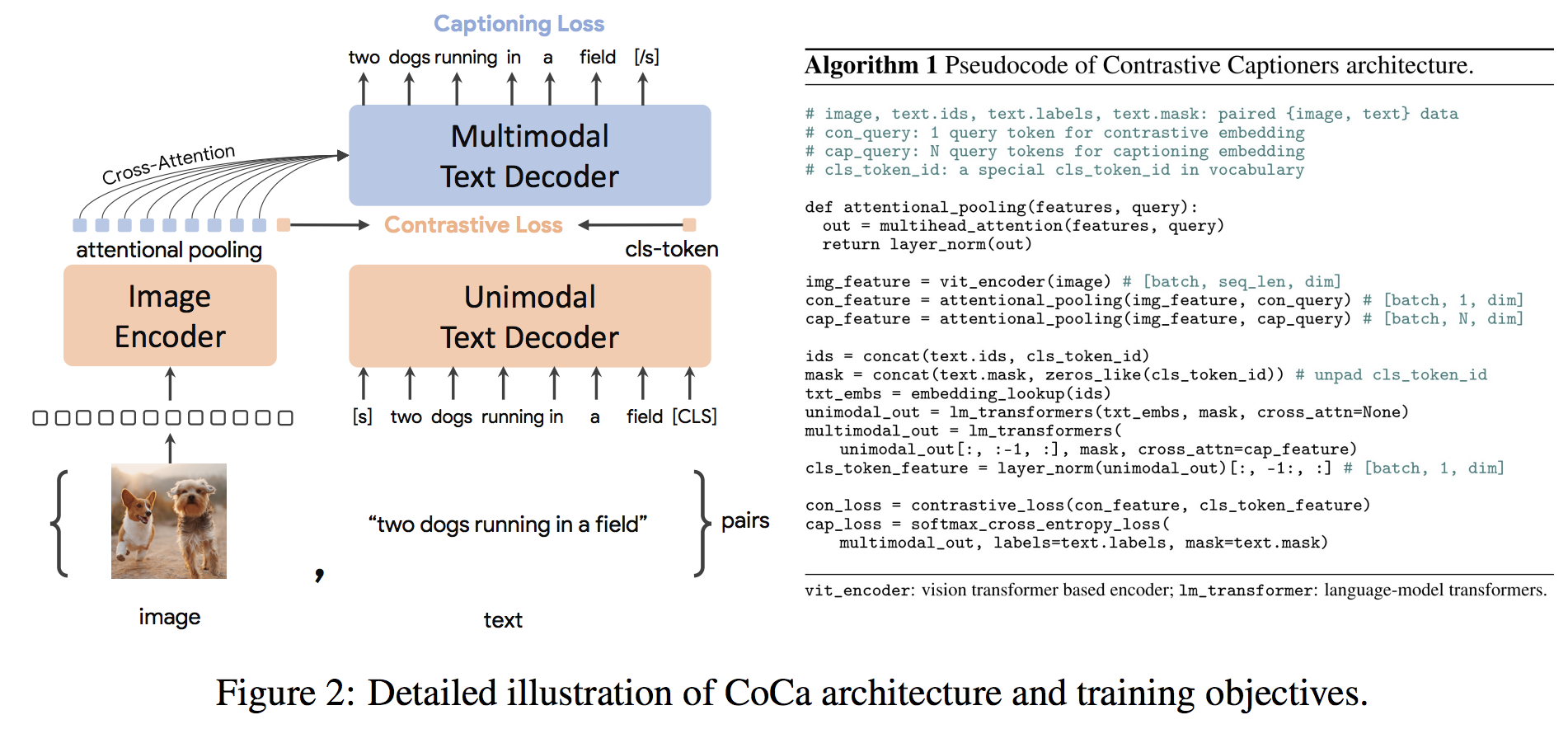
رمز Python لضبط الكوكا هو ./scripts/train_COCA.py ويرد أدناه:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 مقطع (صورة اللغة المسبقة للغة المسبقة) هو شبكة عصبية مدربة على مجموعة متنوعة من أزواج (الصورة والنص). يمكن توجيهه باللغة الطبيعية للتنبؤ بمقتطف النص الأكثر صلة ، بالنظر إلى صورة ، دون تحسين المباشر للمهمة ، على غرار إمكانيات اللقطات الصفرية لـ GPT-2 و 3. يتم عرض بنية المقطع في الصورة أدناه وتم أخذها من المصدر.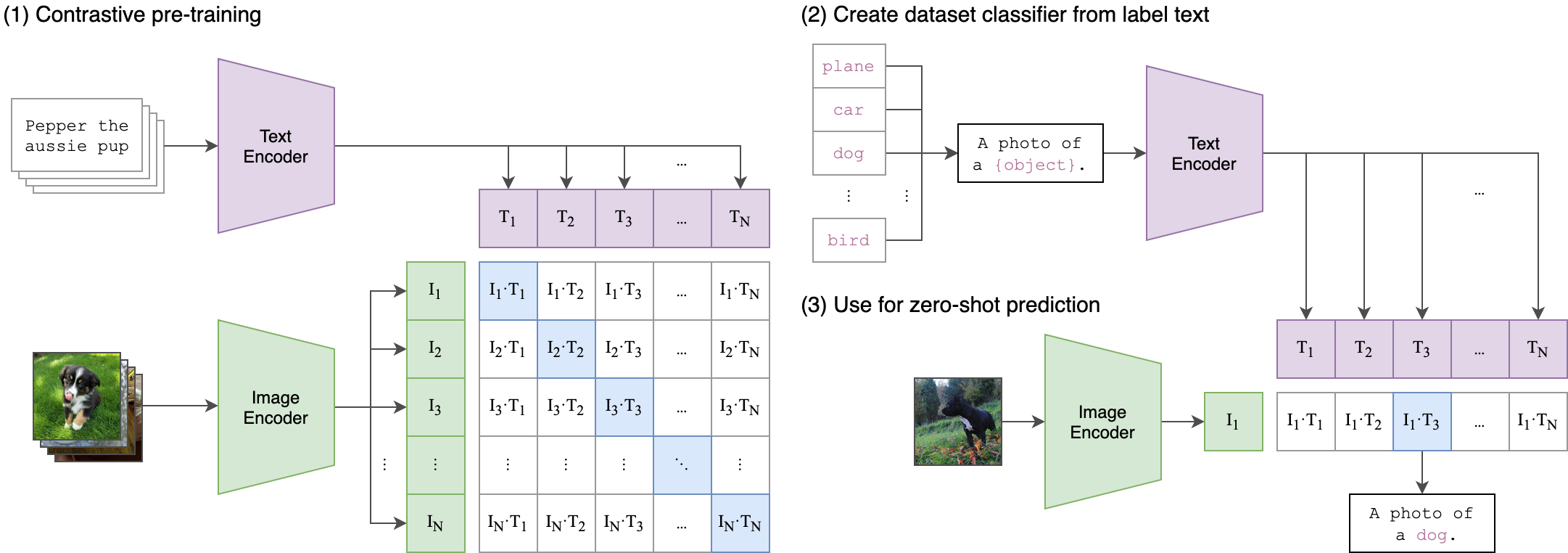
تم تغريم تشفير الصور محول الرؤية (VIT) من مقطع في هذا المستودع. توضح البرامج النصية للثعبان التالية كيفية ضبط VIT:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

