StableDiffusion2 Image to Text
1.0.0
Dieses Repository enthält Python-Code zu Feinabstimmung Modellen, mit denen Eingabeaufforderungen und/oder Einbettungen von generierten Bildern vorhersagen können. Der allgemein wissen, dass das Generieren von Bildern aus einem bestimmten Text ein beliebter Prozess für den Currumty Trending -Berufsbezeichnungs -Umlauf -Ingenieur ist. Dieses Repo. konzentriert sich auf den umgekehrten Prozess, der die Textaufforderung vorhersagt, ein Bild zu erzeugen. Bei einer Reihe von Daten als Eingabeaufforderungspaare sind die folgenden Modelle fein abgestimmt, um entweder den Text oder die Texteinbettungen vorherzusagen:
Im Folgenden finden Sie einige Beispiele für SD2 Eingabeaufforderungspaare. Ziel dieser Arbeit ist es, den Eingabeaufforderungstext vorherzusagen, mit dem die Bilder generiert werden. Bei einem Datensatz wie dem folgenden Code in diesem Repo. Kann verwendet werden, um verschiedene Modelle zu optimieren, um die Textaufforderung beim Angeben des generierten Bildes vorherzusagen.
fat rabbits with oranges, photograph iphone, trendinga hyper realistic oil painting of Yoda eating cheese, 4Ka pencil drawing portrait of an anthropomorphic mouse adventurer holding a sword. by pen tacular 


Die Arbeiten in diesem Repository waren Teil des Kaggle Stable Diffusion - Image, um den Wettbewerb aufzufordern. Dies war Code, den ich während des Wettbewerbs erstellt habe, und konnte im Wettbewerb ein Top -5% -Bestnätiger erzielen.
Das Training dieser Modelle und das Erzeugen von Bildern mit stabiler Diffusion 2 ist ressourcenintensiv und meist eine GPU. Es können Maßnahmen ergriffen werden, um die Bildung von Bild zu beschleunigen, wie z. B.:
Mit diesen Schritten wurden mit einem RTX 3090 das Bild bei ungefähr 2s/Bild erzeugt.
Eingabeaufforderungspaardatensätze wurden über die URL mit dem IMG2Dataset-Paket heruntergeladen. Einige Beispiele für Online -URL -Datensätze sind:
Benutzerdefinierte Datensätze mit Eingabeaufforderungspaaren wurden unter Verwendung stabiler Diffusion Version 2 erstellt. Ich empfehle Benutzer, ihre eigenen Datensätze mit stabilen Diffusion 2 zu erstellen. Befolgen Sie die häufig aktualisierten Anweisungen unter stabiler Diffusion Version 2.
Eingabeaufforderungspaare mussten für das Modell entsprechend formatiert werden, dass sie eine Feinabstimmung sein werden. Siehe ./notebooks/data-format-train-val.ipynb
Viele der Online-Datensätze mit Eingabeaufforderungspaarpaaren enthalten Eingabeaufforderungen, die sehr ähnlich sind. Dies kann dazu führen, dass das Modell häufig auf Angaben erfährt und nicht auch bei verschiedenen Textaufforderungen funktioniert. Daher wurden ähnliche Eingabeaufforderungen sie unter Verwendung einer GPU -fähigen Cosinus -Ähnlichkeitsindexierung oder einer Ähnlichkeitssuche entfernt. Siehe ./utils/filt_embeds.py
Dieser Prozess wurde auf einer GPU durchgeführt, die die FAISS -Bibliothek nutzte. Faiss ist eine Bibliothek für eine effiziente Ähnlichkeitssuche und Clusterbildung dichter Vektoren. Es enthält Algorithmen, die in Vektorensätzen in jeder Größe suchen, bis zu solchen, die möglicherweise nicht in RAM passen.
# Create an IndexFlatIP index using the Faiss library
# The term 'IP' represents the Inner Product,
# which is equivalent to cosine similarity as it involves taking the dot product of normalized vectors.
resources = faiss . StandardGpuResources ()
index = faiss . IndexIVFFlat ( faiss . IndexFlatIP ( 384 ), 384 , 5 , faiss . METRIC_INNER_PRODUCT )
gpu_index = faiss . index_cpu_to_gpu ( resources , 0 , index )
# Normalize the input vector and add it to the IndexFlatIP
gpu_index . train ( F . normalize ( vector ). cpu (). numpy ())
gpu_index . add ( F . normalize ( vector ). cpu (). numpy ()) Die Coca-Architektur ist ein neuartiger Encoder-Decoder-Ansatz, der gleichzeitig ausgerichtete unimodale Bild- und Text-Einbettungen und gemeinsame multimodale Darstellungen erzeugt, wodurch sie flexibel genug ist, um direkt für alle Arten von nachgeschalteten Aufgaben anwendbar zu sein. Insbesondere erzielt Coca hochmoderne Ergebnisse zu einer Reihe von Seh- und Visionsprachenaufgaben, die sich über die Erkennung von Visionen, die modale Ausrichtung und das multimodale Verständnis erstrecken. Darüber hinaus lernt es hoch generische Darstellungen, so dass es sich auch so gut oder besser als vollständig fein abgestimmte Modelle mit Null-Shot-Lernen oder gefrorenen Encodern auswirken kann. Die Feinabstimmung wurde nach den Empfehlungen von hier durchgeführt. Die Coca -Architektur ist unten gezeigt und wurde aus der Quelle entnommen. 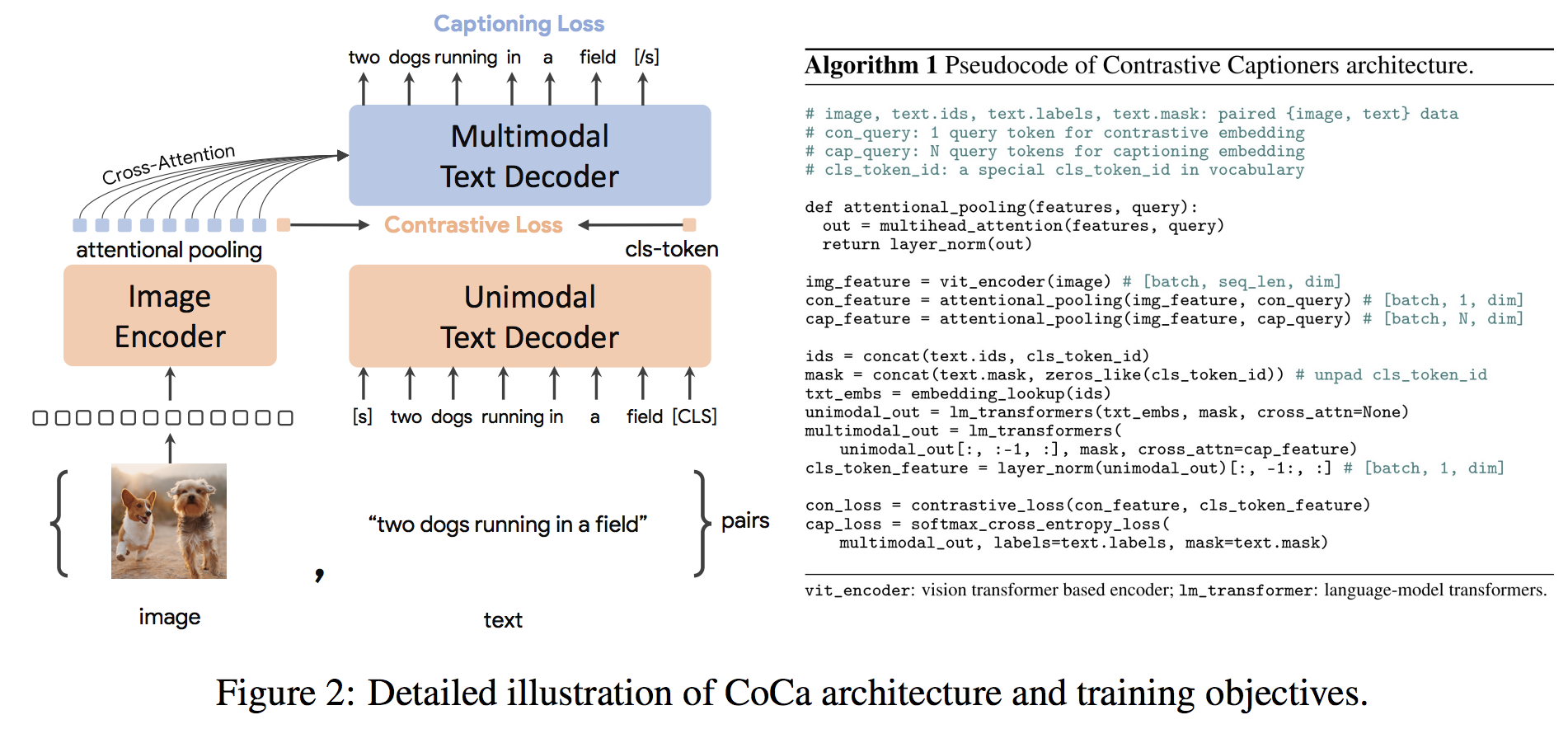
Python Code to Fine-Tune Coca ist in ./scripts/train_COCA.py und ein Bash-Befehl finden Sie unten:
python3 -m training.main
--dataset-type " csv "
--train-data " ./kaggle/diffusiondb_ds2_ds3-2000_Train_TRUNNone_filts_COCA.csv "
--warmup 10000
--batch-size 16
--lr 1e-05
--wd 0.1
--epochs 1
--workers 8
--model coca_ViT-L-14
--pretrained " ./kaggle/input/open-clip-models/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k.bin "
--report-to " wandb "
--wandb-project-name " StableDiffusion "
--coca-contrastive-loss-weight 0
--coca-caption-loss-weight 1
--log-every-n-steps 1000
--seed 42 Der Clip (kontrastive Sprachbild vor dem Training) ist ein neuronales Netzwerk, das auf einer Vielzahl von (Bild, Text) ausgebildet ist. Es kann in der natürlichen Sprache angewiesen werden, das relevanteste Textausschnitt mit einem Bild vorherzusagen, ohne direkt für die Aufgabe zu optimieren, ähnlich wie die Null-Shot-Funktionen von GPT-2 und 3. Die Cliparchitektur ist im folgenden Bild angezeigt und wurde von der Quelle entnommen. 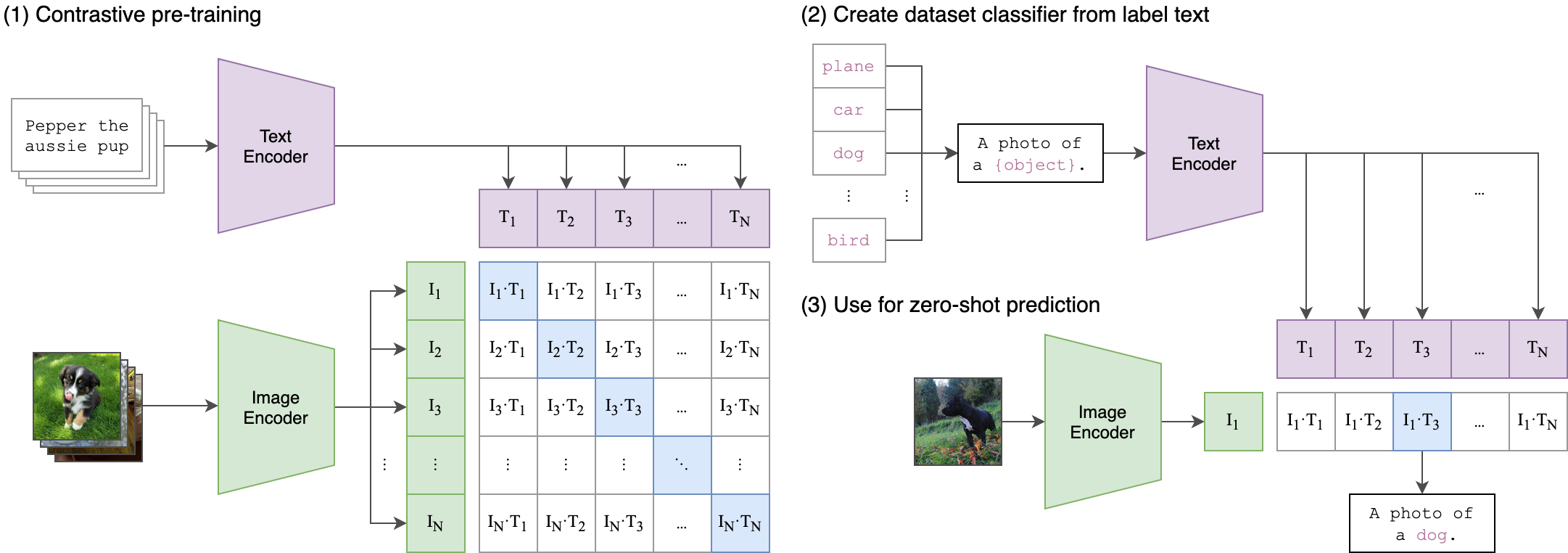
Der Bild-Encoder des Vision Transformator (VIT) von Clip wurde in diesem Repository mit einer Geldstrafe abgestimmt. Die folgenden Python -Skripte zeigen, wie man Vit stimmt:
class Net ( nn . Module ):
def __init__ ( self , model_name ):
super ( Net , self ). __init__ ()
clip = AutoModel . from_pretrained ( model_name )
self . vision = clip . vision_model
self . fc = nn . Linear ( 1024 , 384 )
self . dropout = nn . Dropout ( 0.25 )
def forward ( self , x ):
out = self . vision ( x )[ 'pooler_output' ]
return self . fc ( out )

